-
Vision Transformer(ViT)论文解读与代码实践(Pytorch)
Vision Transformer
Vision Transformer(ViT)是一种基于Transformer架构的神经网络模型,用于处理计算机视觉任务。传统的计算机视觉模型如卷积神经网络(CNN)在处理图像任务时取得了很大的成功,但CNN存在一些局限,例如对于长距离依赖的建模能力较弱。ViT通过引入Transformer的注意力机制来解决这些问题,并在一些视觉任务上取得了优秀的结果。
与传统的CNN不同,ViT将图像分割为一系列的图像块(或称为图像补丁),并将每个图像块作为输入序列。然后,ViT使用Transformer的编码器来对这些输入序列进行处理。每个图像块被展平为一个向量,并与位置编码向量相结合,形成输入序列。这样,ViT能够对整个图像进行全局的建模,而不仅仅是局部区域。
ViT的核心思想是利用Transformer的注意力机制来对图像块之间的关系进行建模。注意力机制允许模型根据输入序列中的不同元素之间的关联性来分配不同的权重。通过多层的自注意力机制,ViT能够对图像块之间的关系进行编码和捕捉,从而实现对图像的全局理解。
注意:如果您还不清楚什么是Transformer和BERT,请先看这两篇文章了解:Transformer \ BERT
Vision Transformer论文解读
论文名称: An Image Is Worth 16x16 Words: Transformers For Image Recognition At Scale
论文链接:https://arxiv.org/abs/2010.11929引言
虽然 Transformer 架构已成为自然语言处理任务事实上的标准,但其在计算机视觉中的应用仍然有限。在视觉中,注意力要么与卷积网络结合应用,要么用于替换卷积网络的某些组件,同时保持其整体结构不变。论文证明了,这种对 CNN 的依赖是不必要的,直接应用于图像块序列的纯 Transformer 可以在图像分类任务上表现良好。当对大量数据进行预训练并转移到多个中型或小型图像识别基准(ImageNet、CIFAR-100、VTAB 等)时,Vision Transformer (ViT) 与现有技术相比取得了优异的结果艺术卷积网络,同时需要更少的计算资源来训练。
模型
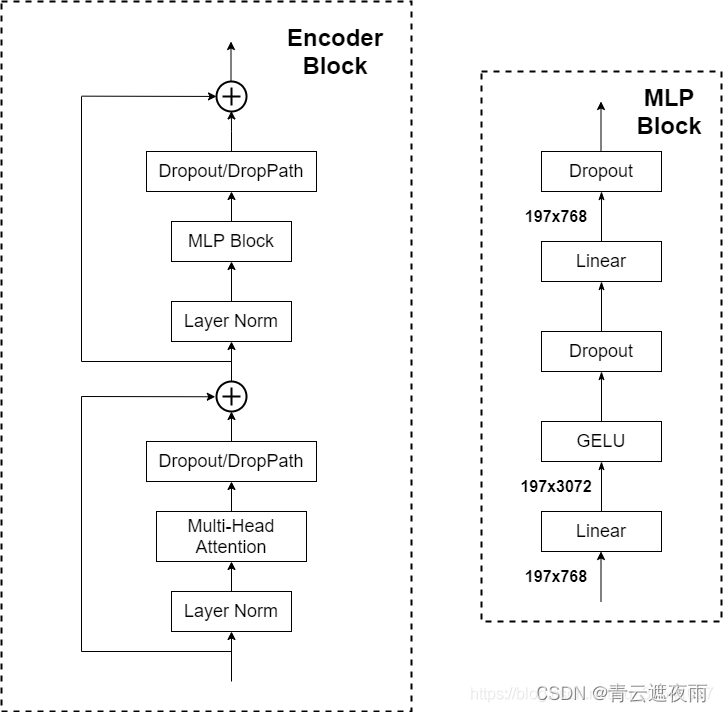
Vision Transformer的模型结构相比于Transformer来说更简单,在Transformer模型中,主要包含Encoder和Decoder结构,而ViT(Vision Transformer)仅借鉴了Encoder结构。
模型结构如下:
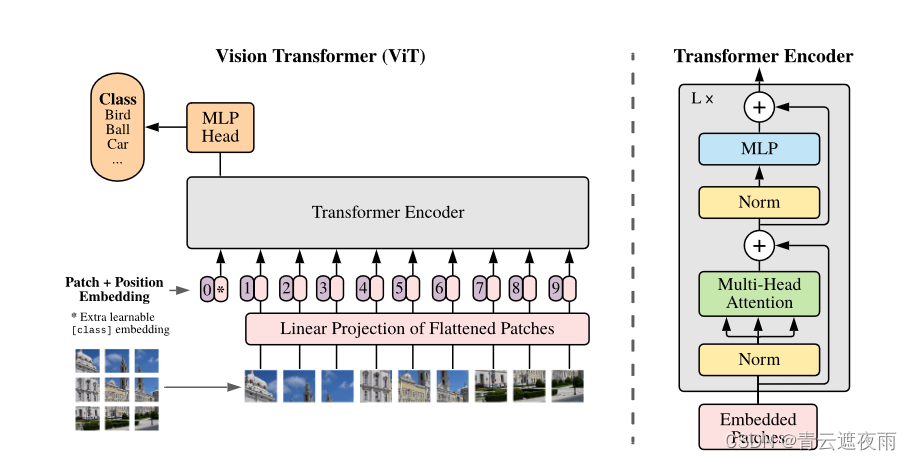
ViT的处理流程大致可以分为以下几个步骤:1. 对输入图片的预处理(Embedding)
正常来说,我们使用的数据集中的图片为224 × \times × 224 × \times × 3,本文以此为例子进行讲解
1.1 图片分割(Patch Embedding)
论文的目的是对Transformer模型尽可能小的改动将其直接应用于视觉领域,这样做的好处是可以将其他以Transformer为baseline的NLP领域的改进直接搬到CV领域来。
那么我们如何将一个图片这样2D甚至3D维度的数据变为像文本一样一维的数据呢?朴素的做法是直接将图片拉平,那么输入的大小将变为 224 × 224 = 50176 224\times 224 =50176 224×224=50176,如果你读过Transformer这篇论文的话你就知道Transformer设置的最大长度为512,很明显50176远远大于最大长度,这样带来了巨大的计算负载。
论文提出了将图片分割为若干块的策略。将 224 × 224 × 3 224\times224\times3 224×224×3的图片分割为 14 × 14 14\times14 14×14个16 × \times × 16 × 3 \times 3 ×3的Patch,这样将图片分为196个Patch,每个Patch相当于一个Token,,每个Patch有 16 × 16 × 3 = 768 16\times16\times3=768 16×16×3=768个维度,可以类比于Transformer中的词嵌入。这样我们得到了 196 × 768 196\times768 196×768的输入,和Transformer基本一致
1.2 添加
token 和Transformer类似的,论文也添加了一个
Token用来代表全局(整个图片)的特征向量,和BERT类似,当我们做图片分类任务时,我们可以使用对这个特征向量进行MLP,得到分类结果,他的形状是 1 × 768 1\times768 1×768,我们将其和上述的输入做合并,输入矩阵形状为 197 × 768 197\times768 197×768 1.3 位置编码(Position Embedding)
在Transformer中,位置编码的作用是为了记忆输入的语序信息。ViT中,同样需要位置编码来记录各图像块之间的位置信息。
论文使用的是1-D的位置编码,即和Transformer论文中使用的位置编码一致,使用了正弦和余弦函数生成位置编码向量:
PE ( pos , 2 i ) = sin ( pos 1000 0 ( 2 i / d model ) ) PE ( pos , 2 i + 1 ) = cos ( pos 1000 0 ( 2 i / d model ) ) \text{{PE}}(\text{{pos}}, 2i) = \sin\left(\frac{{\text{{pos}}}}{{10000^{(2i/d_{\text{{model}}})}}}\right) \\ \text{{PE}}(\text{{pos}}, 2i+1) = \cos\left(\frac{{\text{{pos}}}}{{10000^{(2i/d_{\text{{model}}})}}}\right) PE(pos,2i)=sin(10000(2i/dmodel)pos)PE(pos,2i+1)=cos(10000(2i/dmodel)pos)
其中, ( pos ) (\text{{pos}}) (pos)表示位置, ( i ) (i) (i)表示维度, ( d model ) (d_{\text{{model}}}) (dmodel)表示嵌入向量的维度。这些公式用于计算位置编码向量的值。我们将编码后的结果直接加到输入对应元素中,所以输入矩阵仍然为 197 × 768 197\times 768 197×768。
当然也许有读者会有疑问:为什么图片这种具有二维位置信息的数据仍然使用一维的位置编码,我们先介绍一下其他两种位置编码,再来解释论文为什么使用一维位置编码。
2维位置编码:将输入视为二维网格中的Patch。在这种情况下,学习两组嵌入,分别用于X轴和Y轴,即X嵌入和Y嵌入,每个大小为D/2。然后,根据输入路径上的坐标,我们将X和Y嵌入连接起来,得到该补丁的最终位置编码。
假设我们有一个图像分类任务,需要对一组图像进行分类。每个图像的大小为224x224像素,我们将其划分为16x16个相等大小的Patch。对于2维位置编码,我们可以学习两组嵌入向量:X嵌入和Y嵌入,每个嵌入向量的维度为D/2。假设我们选择的嵌入向量维度为256,那么X嵌入和Y嵌入的维度将分别为128。对于输入图像中的每个补丁,我们根据其在输入中的坐标计算其X和Y坐标,例如,对于第(i, j)个Patch,其X坐标为i,Y坐标为j。然后,我们将X坐标对应的X嵌入和Y坐标对应的Y嵌入连接起来,形成一个维度为256的位置编码向量。这个位置编码向量将与该Patch的特征向量进行拼接或相加,形成最终的输入特征向量。通过这种方式,我们能够为每个补丁引入位置信息,使模型能够区分不同位置的特征。例如,位于图像左上角的Patch和位于图像右下角的Patch可能具有不同的语义含义,位置编码能够帮助模型捕捉到这种位置差异。
相对位置嵌入:考虑块之间的相对距离来编码空间信息,而不是它们的绝对位置。为此,我们使用一维相对注意力,其中我们定义所有可能的补丁对的相对距离。因此,对于每个给定的对(一个作为查询,另一个作为注意机制中的键/值),我们有一个偏移量 p q − p k p_q - p_k pq−pk,其中每个偏移量都与一个嵌入相关联。然后,我们简单地运行额外的注意力,我们使用原始查询(查询的内容),但使用相对位置嵌入作为键。然后,我们使用相对注意力的 logits 作为偏差项,并将其添加到主注意力(基于内容的注意力)的 logits,然后再应用 softmax。
那么为什么不使用符合直觉的2维位置编码呢,其实答案非常简单,论文作者在经过大量实验后证明在这个任务上使用三种编码方式几乎没有任何区别,网络都能很好的学习到位置信息。
使用结果如下:
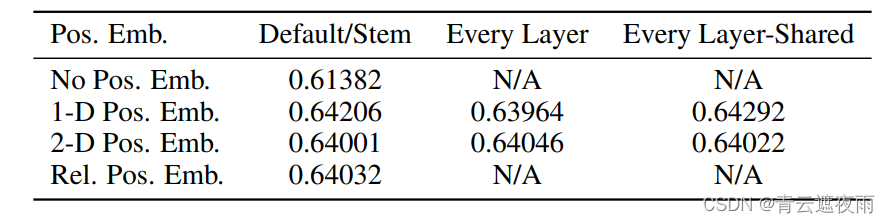
我们看的使用三种位置编码得到的结果几乎一致,证明在此任务上三种编码都可以,我们使用最简单的一种。作者随后也对一维位置编码的结果进行了可视化,结果如下图所示:
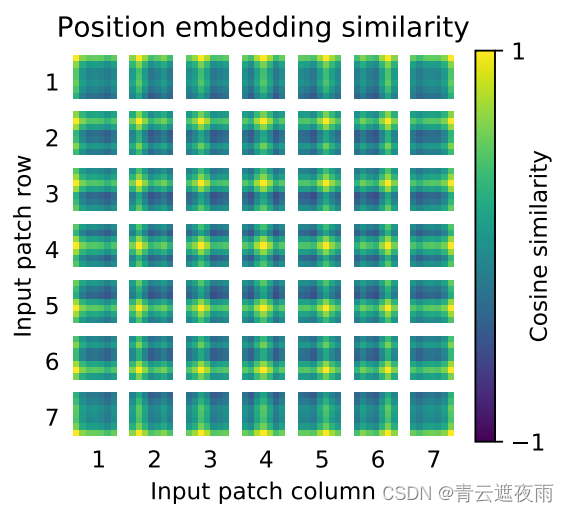
上图中是每一个Patch中各位置的位置编码相似性度量,越接近黄色的位置代表越靠近位置编码的中心位置,可以看到,即使是一维位置编码,同样可以比较好地记录二维信息。2. Transformer Encoder
这部分模型和Transformer Encoder几乎没有区别,我们默认读者理解Transformer架构,所以不做太具体的分析。
模型的设计如下:

我们可以看到和Transformer模型大体上一致,不同的是ViT先进行了层标准化然后才进行多头注意力或者多层感知机。论文给出了Vision Transformer Encoder流程的公式:

其中 z 0 z_0 z0是刚才说的对图片预处理的到的Embedding, M S A MSA MSA代表多头注意力, M L P MLP MLP代表多层感知机, L N LN LN代表层标准化2.1 层标准化
层标准化(Layer Normalization)是一种用于神经网络的归一化技术,用于增强模型的训练和泛化能力。它类似于批量归一化(Batch Normalization),但在不同的维度上进行归一化。
在传统的批量归一化中,归一化是在每个批次的训练样本上进行的,即在批次维度上进行归一化。而在层标准化中,归一化是在每个样本的特征维度上进行的,即在特征维度上进行归一化。
具体来说,对于一层的输入,层标准化通过以下步骤进行:
- 对于每个样本,计算其在特征维度上的均值和方差。
- 使用计算得到的均值和方差对样本进行归一化。
- 应用缩放和偏移操作,以学习适当的缩放因子和偏移量,从而保留网络的表达能力。
与批量归一化相比,层标准化具有以下特点:
- 不依赖于批次大小:批量归一化的归一化操作是在每个批次上进行的,因此对于较小的批次大小可能会引入噪声。而层标准化是在每个样本上进行归一化,因此不受批次大小的影响。
- 更适用于循环神经网络(RNN):由于RNN的序列长度可能不同,批量归一化在序列长度变化时会面临困难。层标准化在每个样本上进行归一化,因此适用于处理变长序列。
- 提供更强的表达能力:层标准化允许每个特征维度上的自适应归一化,可以更好地保留模型的表达能力。
2.2 多头注意力
多头注意力(Multi-head Attention)是一种在自注意力机制(Self-Attention)基础上扩展的注意力机制。它在深度学习中广泛应用于自然语言处理(NLP)和计算机视觉(CV)任务中,特别是在Transformer模型中。
自注意力机制是一种用于序列数据的注意力机制,可以用于建模序列中不同位置之间的依赖关系。它通过计算每个位置与其他所有位置之间的注意力权重,来学习位置之间的关联性,进而生成具有上下文感知的表示。
多头注意力通过并行地使用多个注意力头来增强自注意力的表示能力。每个注意力头都有自己的权重矩阵(查询、键和值),并生成一个注意力权重矩阵。通过将多个注意力头的输出进行拼接或加权求和,可以得到最终的多头注意力表示。
具体来说,多头注意力的计算过程如下:
- 输入包括查询(Q)、键(K)和值(V)的特征矩阵。
- 对于每个注意力头,计算注意力权重:
- 使用查询矩阵Q和键矩阵K计算注意力分数。
- 将注意力分数进行缩放和softmax操作,得到注意力权重。
- 使用注意力权重对值矩阵V进行加权求和,得到每个注意力头的注意力输出。
- 对于所有注意力头的输出,进行拼接或加权求和,得到多头注意力的最终表示。
多头注意力的优势在于它能够捕捉不同的注意力集中模式,从而提高模型对于不同关系和特征的建模能力。每个注意力头可以关注序列中不同的上下文信息,从而提供更全面的表示。此外,多头注意力还可以提高模型的并行计算能力,加速训练和推理过程。
2.3 MLP层
MLP层的结构如下:
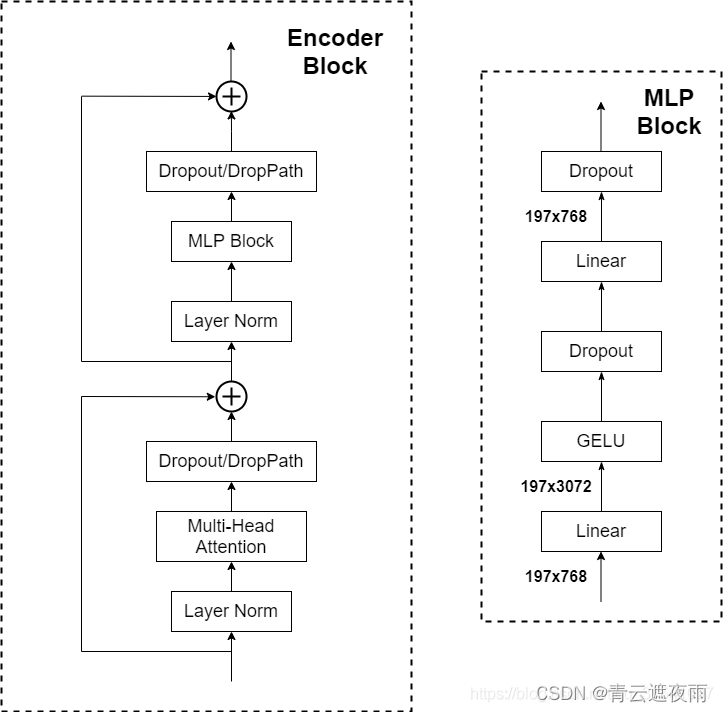
这个多层感知机并不复杂,就是两个线性层和GELU激活函数和Dropout用于增强模型泛化性。3. MLP Head
此时我们获得了Transformer Encoder的输出。
我们需要的是整个图片的特征来进行图像分类,我们刚才添加的
标签就代表了整个图片的特征,所以我们将其提取出来,输入到MLP层中进行分类。 在论文中,作者先是在ImageNet21K上进行预训练,MLP Head结构由Linear+tanh激活函数+Linear组成,但是迁移到其它数据集训练时,只需要用一个一个Linear即可。
输出结果之后,再和真实标签做交叉熵损失,这样就可以完成ViT的训练过程。
结果展示
论文中作者将ViT和之前视觉领域最优秀的架构BiT(以ResNet为baseline)做对比,发现在数据集较大时,模型表现和计算耗时都比BiT优秀。
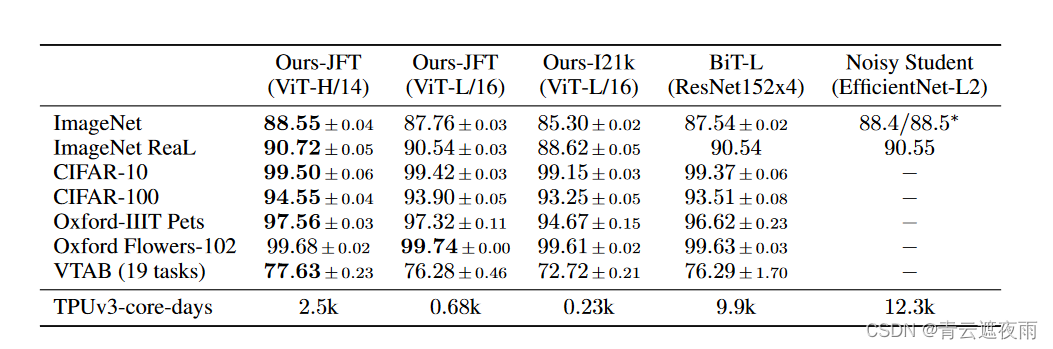
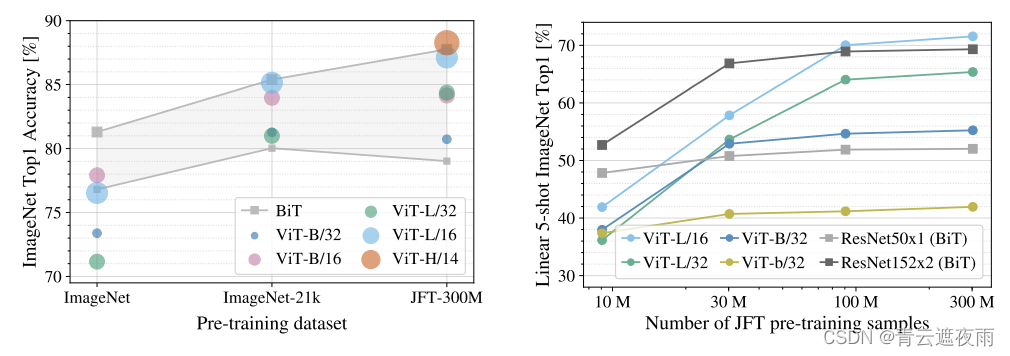
可以看到,右图中,作者使用了谷歌制作的JFT-300M数据集,当数据量小于30M时,ViT的效果表现不如ResNet,但是当数据量逐渐增大时,ViT才会慢慢超越ResNet。由此可见ViT工作的局限性,它必须要在超大数据集上进行预训练,然后再拿到其它数据集上做迁移学习,才会有好的效果。模型版本
论文给出的模型版本如下:

模型缺陷分析
我们从上图可以看出,在数据集不够大的时候,其实ViT的效果其实远远小于BiT,那么为什么会导致这种情况呢?论文也解释了这种情况的可预料性:
因为Transformer和卷积神经网络对比少了两个归纳偏置。所谓归纳偏置,在这里指的是先验知识的引入(算法可以利用领域知识或人类专家的经验,将先验知识编码为模型的先验概率分布或约束条件。这些先验知识可以帮助模型更快地收敛,更准确地进行预测。)
归纳偏置(Inductive bias)是指机器学习算法在学习过程中对模型的预设或偏好,它对于模型的学习和泛化能力起着重要的影响。归纳偏置可以是人为设定的,也可以是算法本身的设计所固有的。
归纳偏置的存在使得算法在学习任务中更有针对性,更容易找到合理的解。它可以帮助算法从数据中提取有用的特征、选择合适的模型结构,并对可能的假设空间进行限制,从而降低学习任务的复杂性。卷积神经网络存在的第一个归纳偏置是"locality",意思是说在图片上相邻的区域很有相近的特征。第二个是平移等变性,意思是 f ( g ( x ) ) = g ( f ( x ) ) f(g(x))=g(f(x)) f(g(x))=g(f(x)),这里的 f f f指的是卷积, g g g指的是平移,无论先做平移还是卷积,最后的结果是一样的。有了这两个归纳偏置,相当于卷积神经网络有了更多的先验信息,能使用较少的数据获得较好的结果。
而Transformer需要大量的数据训练,才能学习到这些信息。
混合模型探索
在最后作者探索了将CNN和Transformer结合起来的可行性。
作为原始图像块的替代方案,输入序列可以由 CNN 的特征图形成。在此混合模型中,Patch嵌入投影应用于从 CNN 特征图提取的Patch。作为一种特殊情况,Patch可以具有 1x1 的空间大小,这意味着输入序列是通过简单地展平特征图的空间维度并投影到 Transformer 维度来获得的。如上所述添加分类输入嵌入和位置嵌入。
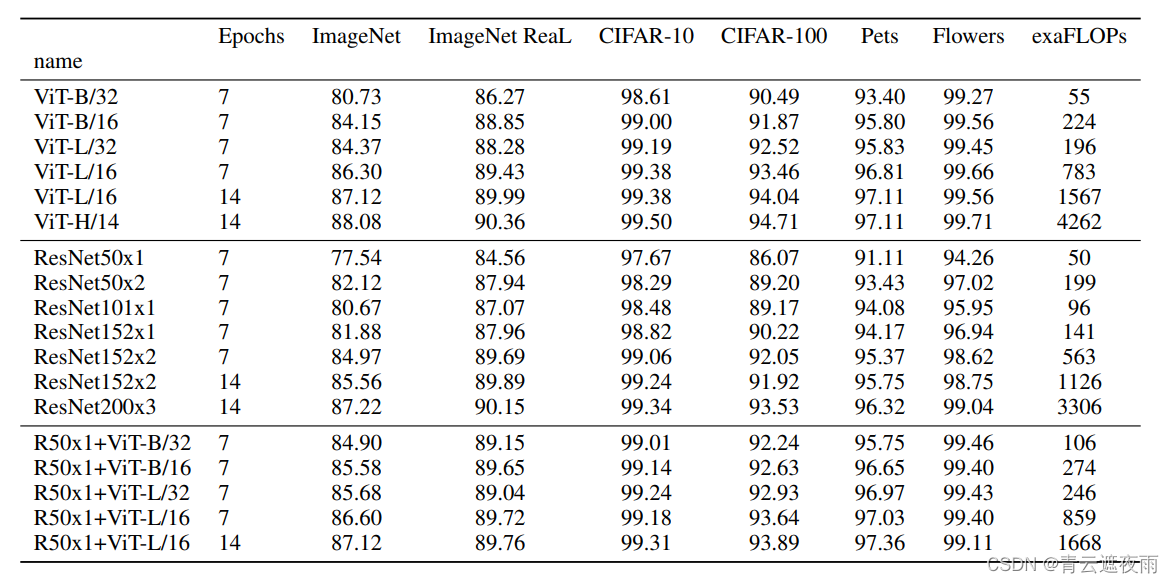
下表中对比了ViT、ResNet和混合模型在不同图像分类数据集上的测试结果,可以看到当Epochs增大时,ResNet和混合模型的效果均不如ViT模型。
模型复现和代码实践
下面就来尝试使用ViT做一个简单的分类任务。代码思路来源于此处。
实验采用的是花蕊数据集,共5个类别,约4000多个样本。
数据集下载:https://pan.baidu.com/s/1vpB3s78bV4Xxowfpe07tdw?pwd=8888
默认使用的是ViT-B/16这个模型,整体结构图如下:
数据集
数据集的格式如下:

读取数据集
这里我们定义了一个获取数据集中所有图片的路径和对应的标签的函数
def read_split_data(root:str,val_rate:float=0.2): random.seed(0) assert os.path.exists(root), "dataset root: {} does not exist.".format(root) # 遍历文件夹,一个文件夹对应一个类别 flower_class = [cla for cla in os.listdir(root) if os.path.isdir(os.path.join(root, cla))] # 排序,保证各平台顺序一致 flower_class.sort() # 生成类别名称以及对应的数字索引 class_indices = dict((k, v) for v, k in enumerate(flower_class)) json_str = json.dumps(dict((val, key) for key, val in class_indices.items()), indent=4) with open('class_indices.json', 'w') as json_file: json_file.write(json_str) train_images_path = [] # 存储训练集的所有图片路径 train_images_label = [] # 存储训练集图片对应索引信息 val_images_path = [] # 存储验证集的所有图片路径 val_images_label = [] # 存储验证集图片对应索引信息 every_class_num = [] # 存储每个类别的样本总数 supported = [".jpg", ".JPG", ".png", ".PNG"] # 支持的文件后缀类型 # 遍历每个文件夹下的文件 for cla in flower_class: cla_path=os.path.join(root,cla) # 遍历获取supported支持的所有文件路径 images = [os.path.join(root, cla, i) for i in os.listdir(cla_path) if os.path.splitext(i)[-1] in supported] # 排序,保证各平台顺序一致 images.sort() # 获取该类别对应的索引 image_class = class_indices[cla] # 记录该类别的样本数量 every_class_num.append(len(images)) # 按比例随机采样验证样本 val_path = random.sample(images, k=int(len(images) * val_rate)) for img_path in images: if img_path in val_path: # 如果该路径在采样的验证集样本中则存入验证集 val_images_path.append(img_path) val_images_label.append(image_class) else: # 否则存入训练集 train_images_path.append(img_path) train_images_label.append(image_class) print("{} images were found in the dataset.".format(sum(every_class_num))) print("{} images for training.".format(len(train_images_path))) print("{} images for validation.".format(len(val_images_path))) assert len(train_images_path) > 0, "number of training images must greater than 0." assert len(val_images_path) > 0, "number of validation images must greater than 0." return train_images_path, train_images_label, val_images_path, val_images_label- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
调用代码:
train_images_path, train_images_label, val_images_path, val_images_label = read_split_data(args.data_path)- 1
自定义数据集
当我们获取到所有数据的路径后,我们定义一个数据集存放数据:
from PIL import Image import torch from torch.utils.data import Dataset class ViTDataSet(Dataset): def __init__(self, images_path: list, images_class: list, transform=None): self.images_path = images_path self.images_class = images_class self.transform = transform def __len__(self): return len(self.images_path) def __getitem__(self, item): img=Image.open(self.images_path[item]) # RGB为彩色图片,L为灰度图片 if img.mode != 'RGB': raise ValueError("image: {} isn't RGB mode.".format(self.images_path[item])) label = self.images_class[item] if self.transform is not None: img=self.transform(img) return img,label @staticmethod def collate_fn(batch): images, labels = tuple(zip(*batch)) images = torch.stack(images, dim=0) labels = torch.as_tensor(labels) return images, labels- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
这里解释一下collate_fn这个静态方法:
collate_fn方法的作用是定义数据加载时的批处理操作。在PyTorch中,数据加载器(DataLoader)将数据集按照指定的批次大小(batch size)加载到模型中进行训练或推断。当数据集中的样本具有不同的大小或形状时,需要对每个批次进行适当的处理,以便能够对其进行批处理计算。
在这段代码中,collate_fn方法接收一个批次(batch)的数据样本作为输入,其中每个样本是通过__getitem__方法返回的图片和标签。它的主要任务是将这些样本组装成一个批次,并对批次中的图片进行堆叠和标签的转换,以便能够输入到神经网络中进行处理。
具体而言,collate_fn方法通过zip(*batch)将批次中的图片和标签分别组成两个元组images和labels。然后使用torch.stack方法将图片堆叠成一个张量,这对于需要输入固定大小的张量的模型非常重要。最后,将标签转换为torch.Tensor张量,并将最终的图片张量和标签张量作为结果返回。
通过自定义collate_fn方法,可以根据数据集的特点和模型的需求来灵活处理数据批次,以提高训练效率并满足模型的输入要求。
图片预处理
我们需要将图片处理为指定的 224 × 224 × 3 224\times224\times3 224×224×3的大小,并进行其他预处理,代码如下:
data_transform = { "train": transforms.Compose([transforms.RandomResizedCrop(224), transforms.RandomHorizontalFlip(), transforms.ToTensor(), transforms.Normalize([0.5, 0.5, 0.5], [0.5, 0.5, 0.5])]), "val": transforms.Compose([transforms.Resize(256), transforms.CenterCrop(224), transforms.ToTensor(), transforms.Normalize([0.5, 0.5, 0.5], [0.5, 0.5, 0.5])])}- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
实例化数据集
# 实例化训练数据集 train_dataset = ViTDataSet(images_path=train_images_path, images_class=train_images_label, transform=data_transform["train"]) # 实例化验证数据集 val_dataset = ViTDataSet(images_path=val_images_path, images_class=val_images_label, transform=data_transform["val"])- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
batch_size = args.batch_size nw = min([os.cpu_count(), batch_size if batch_size > 1 else 0, 8]) # number of workers print('Using {} dataloader workers every process'.format(nw)) train_loader = torch.utils.data.DataLoader(train_dataset, batch_size=batch_size, shuffle=True, pin_memory=True, num_workers=nw, collate_fn=train_dataset.collate_fn) val_loader = torch.utils.data.DataLoader(val_dataset, batch_size=batch_size, shuffle=False, pin_memory=True, num_workers=nw, collate_fn=val_dataset.collate_fn)- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
模型
1. PatchEmbedding
通过卷积,将图片转成一个个Patch。
class PatchEmbed(nn.Module): """ 2D Image to Patch Embedding """ def __init__(self, img_size=224, patch_size=16, in_c=3, embed_dim=768, norm_layer=None): super().__init__() img_size = (img_size, img_size) patch_size = (patch_size, patch_size) self.img_size = img_size self.patch_size = patch_size self.grid_size = (img_size[0] // patch_size[0], img_size[1] // patch_size[1]) self.num_patches = self.grid_size[0] * self.grid_size[1] self.proj = nn.Conv2d(in_c, embed_dim, kernel_size=patch_size, stride=patch_size) self.norm = norm_layer(embed_dim) if norm_layer else nn.Identity() def forward(self, x): B, C, H, W = x.shape assert H == self.img_size[0] and W == self.img_size[1], \ f"Input image size ({H}*{W}) doesn't match model ({self.img_size[0]}*{self.img_size[1]})." # flatten: [B, C, H, W] -> [B, C, HW] # transpose: [B, C, HW] -> [B, HW, C] x = self.proj(x).flatten(2).transpose(1, 2) x = self.norm(x) return x- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
代码将2D图像转换为patch序列的嵌入表示。
img_size表示输入图像的大小,默认为224。
patch_size表示每个patch的大小,默认为16。
in_c表示输入图像的通道数,默认为3。
embed_dim表示每个patch的嵌入维度,默认为768。
norm_layer是一个用于对嵌入向量进行归一化的层,可以是任意归一化层的类型,默认为None,表示不进行归一化。在构造函数中,首先将img_size和patch_size转化为元组的形式。然后计算grid_size,即图像被划分为多少个网格,以及num_patches,表示总共有多少个patch。
接下来,定义了一个proj变量,它是一个nn.Conv2d层,用于将输入图像进行卷积操作,将每个patch编码为嵌入向量。这里的卷积核大小为patch_size,步幅也为patch_size,这样可以确保每个卷积操作只处理一个patch。输出的通道数为embed_dim,表示每个patch的嵌入向量维度。
然后,定义了一个norm变量,它是一个归一化层,用于对嵌入向量进行归一化。如果提供了norm_layer,则使用提供的归一化层类型创建norm层,否则使用nn.Identity()作为默认的归一化层。
在forward方法中,输入x是一个图像张量,其形状为[B, C, H, W],其中B表示批量大小,C表示通道数,H和W表示图像的高度和宽度。
首先,通过断言语句检查输入图像的大小是否与模型期望的图像大小一致。如果不一致,将抛出一个错误。
然后,将输入图像x传递给proj层进行卷积操作。卷积操作会将图像划分为一系列的patch,并将每个patch编码为一个嵌入向量。输出的形状为[B, embed_dim, grid_size[0], grid_size[1]]。
接下来,通过flatten操作将嵌入向量的维度从[B, embed_dim,grid_size[0], grid_size[1]]转换为[B, embed_dim, num_patches],即将每个patch展平为一个向量。
然后,通过transpose操作将维度从[B, embed_dim, num_patches]转换为[B, num_patches, embed_dim],即将嵌入向量的维度放在第二个维度上。
最后,将嵌入向量传递给归一化层norm进行归一化处理,并将结果返回。
2.多头注意力
class Attention(nn.Module): def __init__(self, dim, # 输入token的dim num_heads=8, qkv_bias=False, qk_scale=None, attn_drop_ratio=0., proj_drop_ratio=0.): super(Attention, self).__init__() self.num_heads = num_heads head_dim = dim // num_heads self.scale = qk_scale or head_dim ** -0.5 self.qkv = nn.Linear(dim, dim * 3, bias=qkv_bias) self.attn_drop = nn.Dropout(attn_drop_ratio) self.proj = nn.Linear(dim, dim) self.proj_drop = nn.Dropout(proj_drop_ratio) def forward(self, x): # [batch_size, num_patches + 1, total_embed_dim] B, N, C = x.shape # qkv(): -> [batch_size, num_patches + 1, 3 * total_embed_dim] # reshape: -> [batch_size, num_patches + 1, 3, num_heads, embed_dim_per_head] # permute: -> [3, batch_size, num_heads, num_patches + 1, embed_dim_per_head] qkv = self.qkv(x).reshape(B, N, 3, self.num_heads, C // self.num_heads).permute(2, 0, 3, 1, 4) # [batch_size, num_heads, num_patches + 1, embed_dim_per_head] q, k, v = qkv[0], qkv[1], qkv[2] # make torchscript happy (cannot use tensor as tuple) # transpose: -> [batch_size, num_heads, embed_dim_per_head, num_patches + 1] # @: multiply -> [batch_size, num_heads, num_patches + 1, num_patches + 1] attn = (q @ k.transpose(-2, -1)) * self.scale attn = attn.softmax(dim=-1) attn = self.attn_drop(attn) # @: multiply -> [batch_size, num_heads, num_patches + 1, embed_dim_per_head] # transpose: -> [batch_size, num_patches + 1, num_heads, embed_dim_per_head] # reshape: -> [batch_size, num_patches + 1, total_embed_dim] x = (attn @ v).transpose(1, 2).reshape(B, N, C) x = self.proj(x) x = self.proj_drop(x) return x- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
这部分代码定义了一个名为Attention的类,它是多头注意力机制的实现。它接收以下参数:
dim:输入token的维度。
num_heads:注意力头的数量,默认为8。
qkv_bias:控制是否在查询、键、值投影中使用偏置,默认为False。
qk_scale:缩放因子,用于缩放查询和键的点积,默认为None,如果为None,则将其设置为head_dim的倒数平方。attn_drop_ratio:注意力权重的dropout比例,默认为0,表示不使用dropout。
proj_drop_ratio:注意力输出的投影层的dropout比例,默认为0,表示不使用dropout。在构造函数中,首先计算每个注意力头的维度head_dim,即dim除以num_heads。然后,根据qkv_bias的值决定是否在查询、键、值投影中使用偏置。接下来,定义了一个线性层qkv,用于将输入进行查询、键、值的投影。投影后的维度为dim * 3,即每个注意力头需要dim的空间。然后,定义了一个dropout层attn_drop,用于在注意力权重上应用dropout。接着,定义了一个线性层proj,用于将多头注意力的输出进行投影。最后,定义了一个dropout层proj_drop,用于在投影输出上应用dropout。
在forward方法中,输入x是一个表示序列的张量,其形状为[B, N, C],其中B表示批量大小,N表示序列长度(例如图像的总patch数),C表示每个token的维度。
首先,根据输入的形状,获取批量大小B、序列长度N和每个token的维度C。
然后,通过线性层qkv对输入进行查询、键、值的投影。这里使用了一个reshape操作将输出的张量形状从[B, N, 3, num_heads, C // num_heads]转换为[B, N, 3, num_heads, embed_dim_per_head],其中embed_dim_per_head表示每个注意力头的维度。接着,通过permute操作将维度顺序变为[3, B, num_heads, N, embed_dim_per_head],以便后续的注意力计算。
接下来,分别提取查询(q)、键(k)和值(v)的张量。这里使用了索引0、1、2来获取qkv张量中对应的部分,以满足TorchScript的要求。
然后,计算注意力权重。首先,通过点积操作计算q和k的相似度。注意力权重的计算公式为 (q @ k.transpose(-2, -1)) * self.scale,其中@表示矩阵乘法,q和k的维度为[B, num_heads, N, embed_dim_per_head]。在计算之前,通过乘以缩放因子self.scale对相似度进行缩放。
接下来,对注意力权重进行softmax归一化,以获得注意力权重的概率分布。归一化操作是在最后一个维度上进行的,即dim=-1。
然后,通过self.attn_drop对注意力权重应用dropout,以减少过拟合风险。
接着,将注意力权重与值v相乘,得到注意力加权的结果。这里使用@操作符表示矩阵乘法,得到的结果的维度为[B, num_heads, N, embed_dim_per_head]。
接下来,通过转置操作将注意力加权结果的维度变为[B, N, num_heads, embed_dim_per_head],以便后续的合并操作。
然后,通过reshape操作将多头注意力的输出形状从[B, N, num_heads, embed_dim_per_head]转换为[B, N, C],其中C表示每个token的维度。
接着,通过线性层self.proj将多头注意力的输出进行投影。投影操作的目的是将维度从C变为C,即保持维度不变。
最后,通过self.proj_drop对投影输出应用dropout,以减少过拟合风险。
最终,返回多头注意力的输出张量。
3.Mlp层
class Mlp(nn.Module): """ MLP as used in Vision Transformer, MLP-Mixer and related networks """ def __init__(self, in_features, hidden_features=None, out_features=None, act_layer=nn.GELU, drop=0.): super().__init__() out_features = out_features or in_features hidden_features = hidden_features or in_features self.fc1 = nn.Linear(in_features, hidden_features) self.act = act_layer() self.fc2 = nn.Linear(hidden_features, out_features) self.drop = nn.Dropout(drop) def forward(self, x): x = self.fc1(x) x = self.act(x) x = self.drop(x) x = self.fc2(x) x = self.drop(x) return x- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
4.Transformer Block
class Block(nn.Module): def __init__(self, dim, num_heads, mlp_ratio=4., qkv_bias=False, qk_scale=None, drop_ratio=0., attn_drop_ratio=0., drop_path_ratio=0., act_layer=nn.GELU, norm_layer=nn.LayerNorm): super(Block, self).__init__() self.norm1 = norm_layer(dim) self.attn = Attention(dim, num_heads=num_heads, qkv_bias=qkv_bias, qk_scale=qk_scale, attn_drop_ratio=attn_drop_ratio, proj_drop_ratio=drop_ratio) # NOTE: drop path for stochastic depth, we shall see if this is better than dropout here self.drop_path = DropPath(drop_path_ratio) if drop_path_ratio > 0. else nn.Identity() self.norm2 = norm_layer(dim) mlp_hidden_dim = int(dim * mlp_ratio) self.mlp = Mlp(in_features=dim, hidden_features=mlp_hidden_dim, act_layer=act_layer, drop=drop_ratio) def forward(self, x): x = x + self.drop_path(self.attn(self.norm1(x))) x = x + self.drop_path(self.mlp(self.norm2(x))) return x- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
5. Vison Transformer
class VisionTransformer(nn.Module): def __init__(self, img_size=224, patch_size=16, in_c=3, num_classes=1000, embed_dim=768, depth=12, num_heads=12, mlp_ratio=4.0, qkv_bias=True, qk_scale=None, representation_size=None, distilled=False, drop_ratio=0., attn_drop_ratio=0., drop_path_ratio=0., embed_layer=PatchEmbed, norm_layer=None, act_layer=None): """ Args: img_size (int, tuple): input image size patch_size (int, tuple): patch size in_c (int): number of input channels num_classes (int): number of classes for classification head embed_dim (int): embedding dimension depth (int): depth of transformer num_heads (int): number of attention heads mlp_ratio (int): ratio of mlp hidden dim to embedding dim qkv_bias (bool): enable bias for qkv if True qk_scale (float): override default qk scale of head_dim ** -0.5 if set representation_size (Optional[int]): enable and set representation layer (pre-logits) to this value if set distilled (bool): model includes a distillation token and head as in DeiT models drop_ratio (float): dropout rate attn_drop_ratio (float): attention dropout rate drop_path_ratio (float): stochastic depth rate embed_layer (nn.Module): patch embedding layer norm_layer: (nn.Module): normalization layer """ super(VisionTransformer, self).__init__() self.num_classes = num_classes self.num_features = self.embed_dim = embed_dim # num_features for consistency with other models self.num_tokens = 2 if distilled else 1 norm_layer = norm_layer or partial(nn.LayerNorm, eps=1e-6) act_layer = act_layer or nn.GELU self.patch_embed = embed_layer(img_size=img_size, patch_size=patch_size, in_c=in_c, embed_dim=embed_dim) num_patches = self.patch_embed.num_patches self.cls_token = nn.Parameter(torch.zeros(1, 1, embed_dim)) self.dist_token = nn.Parameter(torch.zeros(1, 1, embed_dim)) if distilled else None self.pos_embed = nn.Parameter(torch.zeros(1, num_patches + self.num_tokens, embed_dim)) self.pos_drop = nn.Dropout(p=drop_ratio) dpr = [x.item() for x in torch.linspace(0, drop_path_ratio, depth)] # stochastic depth decay rule self.blocks = nn.Sequential(*[ Block(dim=embed_dim, num_heads=num_heads, mlp_ratio=mlp_ratio, qkv_bias=qkv_bias, qk_scale=qk_scale, drop_ratio=drop_ratio, attn_drop_ratio=attn_drop_ratio, drop_path_ratio=dpr[i], norm_layer=norm_layer, act_layer=act_layer) for i in range(depth) ]) self.norm = norm_layer(embed_dim) # Representation layer if representation_size and not distilled: self.has_logits = True self.num_features = representation_size self.pre_logits = nn.Sequential(OrderedDict([ ("fc", nn.Linear(embed_dim, representation_size)), ("act", nn.Tanh()) ])) else: self.has_logits = False self.pre_logits = nn.Identity() # Classifier head(s) self.head = nn.Linear(self.num_features, num_classes) if num_classes > 0 else nn.Identity() self.head_dist = None if distilled: self.head_dist = nn.Linear(self.embed_dim, self.num_classes) if num_classes > 0 else nn.Identity() # Weight init nn.init.trunc_normal_(self.pos_embed, std=0.02) if self.dist_token is not None: nn.init.trunc_normal_(self.dist_token, std=0.02) nn.init.trunc_normal_(self.cls_token, std=0.02) self.apply(_init_vit_weights) def forward_features(self, x): # [B, C, H, W] -> [B, num_patches, embed_dim] x = self.patch_embed(x) # [B, 196, 768] # [1, 1, 768] -> [B, 1, 768] cls_token = self.cls_token.expand(x.shape[0], -1, -1) if self.dist_token is None: x = torch.cat((cls_token, x), dim=1) # [B, 197, 768] else: x = torch.cat((cls_token, self.dist_token.expand(x.shape[0], -1, -1), x), dim=1) x = self.pos_drop(x + self.pos_embed) x = self.blocks(x) x = self.norm(x) if self.dist_token is None: return self.pre_logits(x[:, 0]) else: return x[:, 0], x[:, 1] def forward(self, x): x = self.forward_features(x) if self.head_dist is not None: x, x_dist = self.head(x[0]), self.head_dist(x[1]) if self.training and not torch.jit.is_scripting(): # during inference, return the average of both classifier predictions return x, x_dist else: return (x + x_dist) / 2 else: x = self.head(x) return x- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 61
- 62
- 63
- 64
- 65
- 66
- 67
- 68
- 69
- 70
- 71
- 72
- 73
- 74
- 75
- 76
- 77
- 78
- 79
- 80
- 81
- 82
- 83
- 84
- 85
- 86
- 87
- 88
- 89
- 90
- 91
- 92
- 93
- 94
- 95
- 96
- 97
- 98
- 99
- 100
- 101
- 102
- 103
- 104
- 105
- 106
完整代码
代码使用简介:
- 下载好数据集,代码中默认使用的是花分类数据集,下载地址:https://storage.googleapis.com/download.tensorflow.org/example_images/flower_photos.tgz, 如果下载不了的话可以通过百度云链接下载: https://pan.baidu.com/s/1QLCTA4sXnQAw_yvxPj9szg 提取码:58p0
- 在train.py脚本中将–data-path设置成解压后的flower_photos文件夹绝对路径
- 下载预训练权重,在vit_model.py文件中每个模型都有提供预训练权重的下载地址,根据自己使用的模型下载对应预训练权重
- 在train.py脚本中将–weights参数设成下载好的预训练权重路径
- 设置好数据集的路径–data-path以及预训练权重的路径–weights就能使用train.py脚本开始训练了(训练过程中会自动生成class_indices.json文件)
- 在predict.py脚本中导入和训练脚本中同样的模型,并将model_weight_path设置成训练好的模型权重路径(默认保存在weights文件夹下)
- 在predict.py脚本中将img_path设置成你自己需要预测的图片绝对路径
设置好权重路径model_weight_path和预测的图片路径img_path就能使用predict.py脚本进行预测了 - 如果要使用自己的数据集,请按照花分类数据集的文件结构进行摆放(即一个类别对应一个文件夹),并且将训练以及预测脚本中的num_classes设置成你自己数据的类别数
- dataset.py
from PIL import Image import torch from torch.utils.data import Dataset class ViTDataSet(Dataset): def __init__(self, images_path: list, images_class: list, transform=None): self.images_path = images_path self.images_class = images_class self.transform = transform def __len__(self): return len(self.images_path) def __getitem__(self, item): img=Image.open(self.images_path[item]) # RGB为彩色图片,L为灰度图片 if img.mode != 'RGB': raise ValueError("image: {} isn't RGB mode.".format(self.images_path[item])) label = self.images_class[item] if self.transform is not None: img=self.transform(img) return img,label @staticmethod def collate_fn(batch): images, labels = tuple(zip(*batch)) images = torch.stack(images, dim=0) labels = torch.as_tensor(labels) return images, labels- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- utils.py
import os import sys import json import pickle import random import torch from tqdm import tqdm import matplotlib.pyplot as plt def read_split_data(root: str, val_rate: float = 0.2): random.seed(0) # 保证随机结果可复现 assert os.path.exists(root), "dataset root: {} does not exist.".format(root) # 遍历文件夹,一个文件夹对应一个类别 flower_class = [cla for cla in os.listdir(root) if os.path.isdir(os.path.join(root, cla))] # 排序,保证各平台顺序一致 flower_class.sort() # 生成类别名称以及对应的数字索引 class_indices = dict((k, v) for v, k in enumerate(flower_class)) json_str = json.dumps(dict((val, key) for key, val in class_indices.items()), indent=4) with open('class_indices.json', 'w') as json_file: json_file.write(json_str) train_images_path = [] # 存储训练集的所有图片路径 train_images_label = [] # 存储训练集图片对应索引信息 val_images_path = [] # 存储验证集的所有图片路径 val_images_label = [] # 存储验证集图片对应索引信息 every_class_num = [] # 存储每个类别的样本总数 supported = [".jpg", ".JPG", ".png", ".PNG"] # 支持的文件后缀类型 # 遍历每个文件夹下的文件 for cla in flower_class: cla_path = os.path.join(root, cla) # 遍历获取supported支持的所有文件路径 images = [os.path.join(root, cla, i) for i in os.listdir(cla_path) if os.path.splitext(i)[-1] in supported] # 排序,保证各平台顺序一致 images.sort() # 获取该类别对应的索引 image_class = class_indices[cla] # 记录该类别的样本数量 every_class_num.append(len(images)) # 按比例随机采样验证样本 val_path = random.sample(images, k=int(len(images) * val_rate)) for img_path in images: if img_path in val_path: # 如果该路径在采样的验证集样本中则存入验证集 val_images_path.append(img_path) val_images_label.append(image_class) else: # 否则存入训练集 train_images_path.append(img_path) train_images_label.append(image_class) print("{} images were found in the dataset.".format(sum(every_class_num))) print("{} images for training.".format(len(train_images_path))) print("{} images for validation.".format(len(val_images_path))) assert len(train_images_path) > 0, "number of training images must greater than 0." assert len(val_images_path) > 0, "number of validation images must greater than 0." plot_image = False if plot_image: # 绘制每种类别个数柱状图 plt.bar(range(len(flower_class)), every_class_num, align='center') # 将横坐标0,1,2,3,4替换为相应的类别名称 plt.xticks(range(len(flower_class)), flower_class) # 在柱状图上添加数值标签 for i, v in enumerate(every_class_num): plt.text(x=i, y=v + 5, s=str(v), ha='center') # 设置x坐标 plt.xlabel('image class') # 设置y坐标 plt.ylabel('number of images') # 设置柱状图的标题 plt.title('flower class distribution') plt.show() return train_images_path, train_images_label, val_images_path, val_images_label def plot_data_loader_image(data_loader): batch_size = data_loader.batch_size plot_num = min(batch_size, 4) json_path = './class_indices.json' assert os.path.exists(json_path), json_path + " does not exist." json_file = open(json_path, 'r') class_indices = json.load(json_file) for data in data_loader: images, labels = data for i in range(plot_num): # [C, H, W] -> [H, W, C] img = images[i].numpy().transpose(1, 2, 0) # 反Normalize操作 img = (img * [0.229, 0.224, 0.225] + [0.485, 0.456, 0.406]) * 255 label = labels[i].item() plt.subplot(1, plot_num, i+1) plt.xlabel(class_indices[str(label)]) plt.xticks([]) # 去掉x轴的刻度 plt.yticks([]) # 去掉y轴的刻度 plt.imshow(img.astype('uint8')) plt.show() def write_pickle(list_info: list, file_name: str): with open(file_name, 'wb') as f: pickle.dump(list_info, f) def read_pickle(file_name: str) -> list: with open(file_name, 'rb') as f: info_list = pickle.load(f) return info_list def train_one_epoch(model, optimizer, data_loader, device, epoch): model.train() loss_function = torch.nn.CrossEntropyLoss() accu_loss = torch.zeros(1).to(device) # 累计损失 accu_num = torch.zeros(1).to(device) # 累计预测正确的样本数 optimizer.zero_grad() sample_num = 0 data_loader = tqdm(data_loader, file=sys.stdout) for step, data in enumerate(data_loader): images, labels = data sample_num += images.shape[0] pred = model(images.to(device)) pred_classes = torch.max(pred, dim=1)[1] accu_num += torch.eq(pred_classes, labels.to(device)).sum() loss = loss_function(pred, labels.to(device)) loss.backward() accu_loss += loss.detach() data_loader.desc = "[train epoch {}] loss: {:.3f}, acc: {:.3f}".format(epoch, accu_loss.item() / (step + 1), accu_num.item() / sample_num) if not torch.isfinite(loss): print('WARNING: non-finite loss, ending training ', loss) sys.exit(1) optimizer.step() optimizer.zero_grad() return accu_loss.item() / (step + 1), accu_num.item() / sample_num @torch.no_grad() def evaluate(model, data_loader, device, epoch): loss_function = torch.nn.CrossEntropyLoss() model.eval() accu_num = torch.zeros(1).to(device) # 累计预测正确的样本数 accu_loss = torch.zeros(1).to(device) # 累计损失 sample_num = 0 data_loader = tqdm(data_loader, file=sys.stdout) for step, data in enumerate(data_loader): images, labels = data sample_num += images.shape[0] pred = model(images.to(device)) pred_classes = torch.max(pred, dim=1)[1] accu_num += torch.eq(pred_classes, labels.to(device)).sum() loss = loss_function(pred, labels.to(device)) accu_loss += loss data_loader.desc = "[valid epoch {}] loss: {:.3f}, acc: {:.3f}".format(epoch, accu_loss.item() / (step + 1), accu_num.item() / sample_num) return accu_loss.item() / (step + 1), accu_num.item() / sample_num- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 61
- 62
- 63
- 64
- 65
- 66
- 67
- 68
- 69
- 70
- 71
- 72
- 73
- 74
- 75
- 76
- 77
- 78
- 79
- 80
- 81
- 82
- 83
- 84
- 85
- 86
- 87
- 88
- 89
- 90
- 91
- 92
- 93
- 94
- 95
- 96
- 97
- 98
- 99
- 100
- 101
- 102
- 103
- 104
- 105
- 106
- 107
- 108
- 109
- 110
- 111
- 112
- 113
- 114
- 115
- 116
- 117
- 118
- 119
- 120
- 121
- 122
- 123
- 124
- 125
- 126
- 127
- 128
- 129
- 130
- 131
- 132
- 133
- 134
- 135
- 136
- 137
- 138
- 139
- 140
- 141
- 142
- 143
- 144
- 145
- 146
- 147
- 148
- 149
- 150
- 151
- 152
- 153
- 154
- 155
- 156
- 157
- 158
- 159
- 160
- 161
- 162
- 163
- 164
- 165
- 166
- 167
- 168
- 169
- 170
- 171
- 172
- 173
- 174
- 175
- 176
- 177
- 178
- 179
- vit_model.py
from functools import partial from collections import OrderedDict import torch import torch.nn as nn def drop_path(x, drop_prob: float = 0., training: bool = False): """ Drop paths (Stochastic Depth) per sample (when applied in main path of residual blocks). This is the same as the DropConnect impl I created for EfficientNet, etc networks, however, the original name is misleading as 'Drop Connect' is a different form of dropout in a separate paper... See discussion: https://github.com/tensorflow/tpu/issues/494#issuecomment-532968956 ... I've opted for changing the layer and argument names to 'drop path' rather than mix DropConnect as a layer name and use 'survival rate' as the argument. """ if drop_prob == 0. or not training: return x keep_prob = 1 - drop_prob shape = (x.shape[0],) + (1,) * (x.ndim - 1) # work with diff dim tensors, not just 2D ConvNets random_tensor = keep_prob + torch.rand(shape, dtype=x.dtype, device=x.device) random_tensor.floor_() # binarize output = x.div(keep_prob) * random_tensor return output class DropPath(nn.Module): """ Drop paths (Stochastic Depth) per sample (when applied in main path of residual blocks). """ def __init__(self, drop_prob=None): super(DropPath, self).__init__() self.drop_prob = drop_prob def forward(self, x): return drop_path(x, self.drop_prob, self.training) class PatchEmbed(nn.Module): """ 2D Image to Patch Embedding """ def __init__(self, img_size=224, patch_size=16, in_c=3, embed_dim=768, norm_layer=None): super().__init__() img_size = (img_size, img_size) patch_size = (patch_size, patch_size) self.img_size = img_size self.patch_size = patch_size self.grid_size = (img_size[0] // patch_size[0], img_size[1] // patch_size[1]) self.num_patches = self.grid_size[0] * self.grid_size[1] self.proj = nn.Conv2d(in_c, embed_dim, kernel_size=patch_size, stride=patch_size) self.norm = norm_layer(embed_dim) if norm_layer else nn.Identity() def forward(self, x): B, C, H, W = x.shape assert H == self.img_size[0] and W == self.img_size[1], \ f"Input image size ({H}*{W}) doesn't match model ({self.img_size[0]}*{self.img_size[1]})." # flatten: [B, C, H, W] -> [B, C, HW] # transpose: [B, C, HW] -> [B, HW, C] x = self.proj(x).flatten(2).transpose(1, 2) x = self.norm(x) return x class Attention(nn.Module): def __init__(self, dim, # 输入token的dim num_heads=8, qkv_bias=False, qk_scale=None, attn_drop_ratio=0., proj_drop_ratio=0.): super(Attention, self).__init__() self.num_heads = num_heads head_dim = dim // num_heads self.scale = qk_scale or head_dim ** -0.5 self.qkv = nn.Linear(dim, dim * 3, bias=qkv_bias) self.attn_drop = nn.Dropout(attn_drop_ratio) self.proj = nn.Linear(dim, dim) self.proj_drop = nn.Dropout(proj_drop_ratio) def forward(self, x): # [batch_size, num_patches + 1, total_embed_dim] B, N, C = x.shape # qkv(): -> [batch_size, num_patches + 1, 3 * total_embed_dim] # reshape: -> [batch_size, num_patches + 1, 3, num_heads, embed_dim_per_head] # permute: -> [3, batch_size, num_heads, num_patches + 1, embed_dim_per_head] qkv = self.qkv(x).reshape(B, N, 3, self.num_heads, C // self.num_heads).permute(2, 0, 3, 1, 4) # [batch_size, num_heads, num_patches + 1, embed_dim_per_head] q, k, v = qkv[0], qkv[1], qkv[2] # make torchscript happy (cannot use tensor as tuple) # transpose: -> [batch_size, num_heads, embed_dim_per_head, num_patches + 1] # @: multiply -> [batch_size, num_heads, num_patches + 1, num_patches + 1] attn = (q @ k.transpose(-2, -1)) * self.scale attn = attn.softmax(dim=-1) attn = self.attn_drop(attn) # @: multiply -> [batch_size, num_heads, num_patches + 1, embed_dim_per_head] # transpose: -> [batch_size, num_patches + 1, num_heads, embed_dim_per_head] # reshape: -> [batch_size, num_patches + 1, total_embed_dim] x = (attn @ v).transpose(1, 2).reshape(B, N, C) x = self.proj(x) x = self.proj_drop(x) return x class Mlp(nn.Module): """ MLP as used in Vision Transformer, MLP-Mixer and related networks """ def __init__(self, in_features, hidden_features=None, out_features=None, act_layer=nn.GELU, drop=0.): super().__init__() out_features = out_features or in_features hidden_features = hidden_features or in_features self.fc1 = nn.Linear(in_features, hidden_features) self.act = act_layer() self.fc2 = nn.Linear(hidden_features, out_features) self.drop = nn.Dropout(drop) def forward(self, x): x = self.fc1(x) x = self.act(x) x = self.drop(x) x = self.fc2(x) x = self.drop(x) return x class Block(nn.Module): def __init__(self, dim, num_heads, mlp_ratio=4., qkv_bias=False, qk_scale=None, drop_ratio=0., attn_drop_ratio=0., drop_path_ratio=0., act_layer=nn.GELU, norm_layer=nn.LayerNorm): super(Block, self).__init__() self.norm1 = norm_layer(dim) self.attn = Attention(dim, num_heads=num_heads, qkv_bias=qkv_bias, qk_scale=qk_scale, attn_drop_ratio=attn_drop_ratio, proj_drop_ratio=drop_ratio) # NOTE: drop path for stochastic depth, we shall see if this is better than dropout here self.drop_path = DropPath(drop_path_ratio) if drop_path_ratio > 0. else nn.Identity() self.norm2 = norm_layer(dim) mlp_hidden_dim = int(dim * mlp_ratio) self.mlp = Mlp(in_features=dim, hidden_features=mlp_hidden_dim, act_layer=act_layer, drop=drop_ratio) def forward(self, x): x = x + self.drop_path(self.attn(self.norm1(x))) x = x + self.drop_path(self.mlp(self.norm2(x))) return x class VisionTransformer(nn.Module): def __init__(self, img_size=224, patch_size=16, in_c=3, num_classes=1000, embed_dim=768, depth=12, num_heads=12, mlp_ratio=4.0, qkv_bias=True, qk_scale=None, representation_size=None, distilled=False, drop_ratio=0., attn_drop_ratio=0., drop_path_ratio=0., embed_layer=PatchEmbed, norm_layer=None, act_layer=None): """ Args: img_size (int, tuple): input image size patch_size (int, tuple): patch size in_c (int): number of input channels num_classes (int): number of classes for classification head embed_dim (int): embedding dimension depth (int): depth of transformer num_heads (int): number of attention heads mlp_ratio (int): ratio of mlp hidden dim to embedding dim qkv_bias (bool): enable bias for qkv if True qk_scale (float): override default qk scale of head_dim ** -0.5 if set representation_size (Optional[int]): enable and set representation layer (pre-logits) to this value if set distilled (bool): model includes a distillation token and head as in DeiT models drop_ratio (float): dropout rate attn_drop_ratio (float): attention dropout rate drop_path_ratio (float): stochastic depth rate embed_layer (nn.Module): patch embedding layer norm_layer: (nn.Module): normalization layer """ super(VisionTransformer, self).__init__() self.num_classes = num_classes self.num_features = self.embed_dim = embed_dim # num_features for consistency with other models self.num_tokens = 2 if distilled else 1 norm_layer = norm_layer or partial(nn.LayerNorm, eps=1e-6) act_layer = act_layer or nn.GELU self.patch_embed = embed_layer(img_size=img_size, patch_size=patch_size, in_c=in_c, embed_dim=embed_dim) num_patches = self.patch_embed.num_patches self.cls_token = nn.Parameter(torch.zeros(1, 1, embed_dim)) self.dist_token = nn.Parameter(torch.zeros(1, 1, embed_dim)) if distilled else None self.pos_embed = nn.Parameter(torch.zeros(1, num_patches + self.num_tokens, embed_dim)) self.pos_drop = nn.Dropout(p=drop_ratio) dpr = [x.item() for x in torch.linspace(0, drop_path_ratio, depth)] # stochastic depth decay rule self.blocks = nn.Sequential(*[ Block(dim=embed_dim, num_heads=num_heads, mlp_ratio=mlp_ratio, qkv_bias=qkv_bias, qk_scale=qk_scale, drop_ratio=drop_ratio, attn_drop_ratio=attn_drop_ratio, drop_path_ratio=dpr[i], norm_layer=norm_layer, act_layer=act_layer) for i in range(depth) ]) self.norm = norm_layer(embed_dim) # Representation layer if representation_size and not distilled: self.has_logits = True self.num_features = representation_size self.pre_logits = nn.Sequential(OrderedDict([ ("fc", nn.Linear(embed_dim, representation_size)), ("act", nn.Tanh()) ])) else: self.has_logits = False self.pre_logits = nn.Identity() # Classifier head(s) self.head = nn.Linear(self.num_features, num_classes) if num_classes > 0 else nn.Identity() self.head_dist = None if distilled: self.head_dist = nn.Linear(self.embed_dim, self.num_classes) if num_classes > 0 else nn.Identity() # Weight init nn.init.trunc_normal_(self.pos_embed, std=0.02) if self.dist_token is not None: nn.init.trunc_normal_(self.dist_token, std=0.02) nn.init.trunc_normal_(self.cls_token, std=0.02) self.apply(_init_vit_weights) def forward_features(self, x): # [B, C, H, W] -> [B, num_patches, embed_dim] x = self.patch_embed(x) # [B, 196, 768] # [1, 1, 768] -> [B, 1, 768] cls_token = self.cls_token.expand(x.shape[0], -1, -1) if self.dist_token is None: x = torch.cat((cls_token, x), dim=1) # [B, 197, 768] else: x = torch.cat((cls_token, self.dist_token.expand(x.shape[0], -1, -1), x), dim=1) x = self.pos_drop(x + self.pos_embed) x = self.blocks(x) x = self.norm(x) if self.dist_token is None: return self.pre_logits(x[:, 0]) else: return x[:, 0], x[:, 1] def forward(self, x): x = self.forward_features(x) if self.head_dist is not None: x, x_dist = self.head(x[0]), self.head_dist(x[1]) if self.training and not torch.jit.is_scripting(): # during inference, return the average of both classifier predictions return x, x_dist else: return (x + x_dist) / 2 else: x = self.head(x) return x def _init_vit_weights(m): """ ViT weight initialization :param m: module """ if isinstance(m, nn.Linear): nn.init.trunc_normal_(m.weight, std=.01) if m.bias is not None: nn.init.zeros_(m.bias) elif isinstance(m, nn.Conv2d): nn.init.kaiming_normal_(m.weight, mode="fan_out") if m.bias is not None: nn.init.zeros_(m.bias) elif isinstance(m, nn.LayerNorm): nn.init.zeros_(m.bias) nn.init.ones_(m.weight) def vit_base_patch16_224(num_classes: int = 1000): """ ViT-Base model (ViT-B/16) from original paper (https://arxiv.org/abs/2010.11929). ImageNet-1k weights @ 224x224, source https://github.com/google-research/vision_transformer. weights ported from official Google JAX impl: 链接: https://pan.baidu.com/s/1zqb08naP0RPqqfSXfkB2EA 密码: eu9f """ model = VisionTransformer(img_size=224, patch_size=16, embed_dim=768, depth=12, num_heads=12, representation_size=None, num_classes=num_classes) return model def vit_base_patch16_224_in21k(num_classes: int = 21843, has_logits: bool = True): """ ViT-Base model (ViT-B/16) from original paper (https://arxiv.org/abs/2010.11929). ImageNet-21k weights @ 224x224, source https://github.com/google-research/vision_transformer. weights ported from official Google JAX impl: https://github.com/rwightman/pytorch-image-models/releases/download/v0.1-vitjx/jx_vit_base_patch16_224_in21k-e5005f0a.pth """ model = VisionTransformer(img_size=224, patch_size=16, embed_dim=768, depth=12, num_heads=12, representation_size=768 if has_logits else None, num_classes=num_classes) return model def vit_base_patch32_224(num_classes: int = 1000): """ ViT-Base model (ViT-B/32) from original paper (https://arxiv.org/abs/2010.11929). ImageNet-1k weights @ 224x224, source https://github.com/google-research/vision_transformer. weights ported from official Google JAX impl: 链接: https://pan.baidu.com/s/1hCv0U8pQomwAtHBYc4hmZg 密码: s5hl """ model = VisionTransformer(img_size=224, patch_size=32, embed_dim=768, depth=12, num_heads=12, representation_size=None, num_classes=num_classes) return model def vit_base_patch32_224_in21k(num_classes: int = 21843, has_logits: bool = True): """ ViT-Base model (ViT-B/32) from original paper (https://arxiv.org/abs/2010.11929). ImageNet-21k weights @ 224x224, source https://github.com/google-research/vision_transformer. weights ported from official Google JAX impl: https://github.com/rwightman/pytorch-image-models/releases/download/v0.1-vitjx/jx_vit_base_patch32_224_in21k-8db57226.pth """ model = VisionTransformer(img_size=224, patch_size=32, embed_dim=768, depth=12, num_heads=12, representation_size=768 if has_logits else None, num_classes=num_classes) return model def vit_large_patch16_224(num_classes: int = 1000): """ ViT-Large model (ViT-L/16) from original paper (https://arxiv.org/abs/2010.11929). ImageNet-1k weights @ 224x224, source https://github.com/google-research/vision_transformer. weights ported from official Google JAX impl: 链接: https://pan.baidu.com/s/1cxBgZJJ6qUWPSBNcE4TdRQ 密码: qqt8 """ model = VisionTransformer(img_size=224, patch_size=16, embed_dim=1024, depth=24, num_heads=16, representation_size=None, num_classes=num_classes) return model def vit_large_patch16_224_in21k(num_classes: int = 21843, has_logits: bool = True): """ ViT-Large model (ViT-L/16) from original paper (https://arxiv.org/abs/2010.11929). ImageNet-21k weights @ 224x224, source https://github.com/google-research/vision_transformer. weights ported from official Google JAX impl: https://github.com/rwightman/pytorch-image-models/releases/download/v0.1-vitjx/jx_vit_large_patch16_224_in21k-606da67d.pth """ model = VisionTransformer(img_size=224, patch_size=16, embed_dim=1024, depth=24, num_heads=16, representation_size=1024 if has_logits else None, num_classes=num_classes) return model def vit_large_patch32_224_in21k(num_classes: int = 21843, has_logits: bool = True): """ ViT-Large model (ViT-L/32) from original paper (https://arxiv.org/abs/2010.11929). ImageNet-21k weights @ 224x224, source https://github.com/google-research/vision_transformer. weights ported from official Google JAX impl: https://github.com/rwightman/pytorch-image-models/releases/download/v0.1-vitjx/jx_vit_large_patch32_224_in21k-9046d2e7.pth """ model = VisionTransformer(img_size=224, patch_size=32, embed_dim=1024, depth=24, num_heads=16, representation_size=1024 if has_logits else None, num_classes=num_classes) return model def vit_huge_patch14_224_in21k(num_classes: int = 21843, has_logits: bool = True): """ ViT-Huge model (ViT-H/14) from original paper (https://arxiv.org/abs/2010.11929). ImageNet-21k weights @ 224x224, source https://github.com/google-research/vision_transformer. NOTE: converted weights not currently available, too large for github release hosting. """ model = VisionTransformer(img_size=224, patch_size=14, embed_dim=1280, depth=32, num_heads=16, representation_size=1280 if has_logits else None, num_classes=num_classes) return model- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 61
- 62
- 63
- 64
- 65
- 66
- 67
- 68
- 69
- 70
- 71
- 72
- 73
- 74
- 75
- 76
- 77
- 78
- 79
- 80
- 81
- 82
- 83
- 84
- 85
- 86
- 87
- 88
- 89
- 90
- 91
- 92
- 93
- 94
- 95
- 96
- 97
- 98
- 99
- 100
- 101
- 102
- 103
- 104
- 105
- 106
- 107
- 108
- 109
- 110
- 111
- 112
- 113
- 114
- 115
- 116
- 117
- 118
- 119
- 120
- 121
- 122
- 123
- 124
- 125
- 126
- 127
- 128
- 129
- 130
- 131
- 132
- 133
- 134
- 135
- 136
- 137
- 138
- 139
- 140
- 141
- 142
- 143
- 144
- 145
- 146
- 147
- 148
- 149
- 150
- 151
- 152
- 153
- 154
- 155
- 156
- 157
- 158
- 159
- 160
- 161
- 162
- 163
- 164
- 165
- 166
- 167
- 168
- 169
- 170
- 171
- 172
- 173
- 174
- 175
- 176
- 177
- 178
- 179
- 180
- 181
- 182
- 183
- 184
- 185
- 186
- 187
- 188
- 189
- 190
- 191
- 192
- 193
- 194
- 195
- 196
- 197
- 198
- 199
- 200
- 201
- 202
- 203
- 204
- 205
- 206
- 207
- 208
- 209
- 210
- 211
- 212
- 213
- 214
- 215
- 216
- 217
- 218
- 219
- 220
- 221
- 222
- 223
- 224
- 225
- 226
- 227
- 228
- 229
- 230
- 231
- 232
- 233
- 234
- 235
- 236
- 237
- 238
- 239
- 240
- 241
- 242
- 243
- 244
- 245
- 246
- 247
- 248
- 249
- 250
- 251
- 252
- 253
- 254
- 255
- 256
- 257
- 258
- 259
- 260
- 261
- 262
- 263
- 264
- 265
- 266
- 267
- 268
- 269
- 270
- 271
- 272
- 273
- 274
- 275
- 276
- 277
- 278
- 279
- 280
- 281
- 282
- 283
- 284
- 285
- 286
- 287
- 288
- 289
- 290
- 291
- 292
- 293
- 294
- 295
- 296
- 297
- 298
- 299
- 300
- 301
- 302
- 303
- 304
- 305
- 306
- 307
- 308
- 309
- 310
- 311
- 312
- 313
- 314
- 315
- 316
- 317
- 318
- 319
- 320
- 321
- 322
- 323
- 324
- 325
- 326
- 327
- 328
- 329
- 330
- 331
- 332
- 333
- 334
- 335
- 336
- 337
- 338
- 339
- 340
- 341
- 342
- 343
- 344
- 345
- 346
- 347
- 348
- 349
- 350
- 351
- 352
- 353
- 354
- 355
- 356
- 357
- 358
- 359
- 360
- 361
- 362
- 363
- 364
- 365
- 366
- 367
- 368
- 369
- 370
- 371
- 372
- 373
- 374
- 375
- 376
- 377
- 378
- 379
- 380
- 381
- 382
- 383
- 384
- 385
- 386
- 387
- 388
- 389
- 390
- 391
- 392
- 393
- 394
- 395
- 396
- 397
- 398
- 399
- 400
- 401
- 402
- 403
- 404
- 405
- 406
- 407
- 408
- 409
- 410
- 411
- 412
- 413
- 414
- 415
- 416
- 417
- 418
- train.py
import os import math import argparse import torch import torch.optim as optim import torch.optim.lr_scheduler as lr_scheduler from torch.utils.tensorboard import SummaryWriter from torchvision import transforms from dataset import ViTDataSet from vit_model import vit_base_patch16_224_in21k as create_model from utils import read_split_data, train_one_epoch, evaluate def main(args): device = torch.device(args.device if torch.cuda.is_available() else "cpu") if os.path.exists("./weights") is False: os.makedirs("./weights") tb_writer = SummaryWriter() train_images_path, train_images_label, val_images_path, val_images_label = read_split_data(args.data_path) data_transform = { "train": transforms.Compose([transforms.RandomResizedCrop(224), transforms.RandomHorizontalFlip(), transforms.ToTensor(), transforms.Normalize([0.5, 0.5, 0.5], [0.5, 0.5, 0.5])]), "val": transforms.Compose([transforms.Resize(256), transforms.CenterCrop(224), transforms.ToTensor(), transforms.Normalize([0.5, 0.5, 0.5], [0.5, 0.5, 0.5])])} # 实例化训练数据集 train_dataset = ViTDataSet(images_path=train_images_path, images_class=train_images_label, transform=data_transform["train"]) # 实例化验证数据集 val_dataset = ViTDataSet(images_path=val_images_path, images_class=val_images_label, transform=data_transform["val"]) batch_size = args.batch_size nw = min([os.cpu_count(), batch_size if batch_size > 1 else 0, 8]) # number of workers print('Using {} dataloader workers every process'.format(nw)) train_loader = torch.utils.data.DataLoader(train_dataset, batch_size=batch_size, shuffle=True, pin_memory=True, num_workers=nw, collate_fn=train_dataset.collate_fn) val_loader = torch.utils.data.DataLoader(val_dataset, batch_size=batch_size, shuffle=False, pin_memory=True, num_workers=nw, collate_fn=val_dataset.collate_fn) model = create_model(num_classes=args.num_classes, has_logits=False).to(device) if args.weights != "": assert os.path.exists(args.weights), "weights file: '{}' not exist.".format(args.weights) weights_dict = torch.load(args.weights, map_location=device) # 删除不需要的权重 del_keys = ['head.weight', 'head.bias'] if model.has_logits \ else ['pre_logits.fc.weight', 'pre_logits.fc.bias', 'head.weight', 'head.bias'] for k in del_keys: del weights_dict[k] print(model.load_state_dict(weights_dict, strict=False)) if args.freeze_layers: for name, para in model.named_parameters(): # 除head, pre_logits外,其他权重全部冻结 if "head" not in name and "pre_logits" not in name: para.requires_grad_(False) else: print("training {}".format(name)) pg = [p for p in model.parameters() if p.requires_grad] optimizer = optim.SGD(pg, lr=args.lr, momentum=0.9, weight_decay=5E-5) # Scheduler https://arxiv.org/pdf/1812.01187.pdf lf = lambda x: ((1 + math.cos(x * math.pi / args.epochs)) / 2) * (1 - args.lrf) + args.lrf # cosine scheduler = lr_scheduler.LambdaLR(optimizer, lr_lambda=lf) for epoch in range(args.epochs): # train train_loss, train_acc = train_one_epoch(model=model, optimizer=optimizer, data_loader=train_loader, device=device, epoch=epoch) scheduler.step() # validate val_loss, val_acc = evaluate(model=model, data_loader=val_loader, device=device, epoch=epoch) tags = ["train_loss", "train_acc", "val_loss", "val_acc", "learning_rate"] tb_writer.add_scalar(tags[0], train_loss, epoch) tb_writer.add_scalar(tags[1], train_acc, epoch) tb_writer.add_scalar(tags[2], val_loss, epoch) tb_writer.add_scalar(tags[3], val_acc, epoch) tb_writer.add_scalar(tags[4], optimizer.param_groups[0]["lr"], epoch) torch.save(model.state_dict(), "./weights/model-{}.pth".format(epoch)) if __name__ == '__main__': parser = argparse.ArgumentParser() parser.add_argument('--num_classes', type=int, default=5) parser.add_argument('--epochs', type=int, default=10) parser.add_argument('--batch-size', type=int, default=8) parser.add_argument('--lr', type=float, default=0.001) parser.add_argument('--lrf', type=float, default=0.01) # 数据集所在根目录 # https://storage.googleapis.com/download.tensorflow.org/example_images/flower_photos.tgz parser.add_argument('--data-path', type=str, default='../data_set/flower_photos') parser.add_argument('--model-name', default='', help='create model name') # 预训练权重路径,如果不想载入就设置为空字符 parser.add_argument('--weights', type=str, default='vit_base_patch16_224_in21k.pth', help='initial weights path') # 是否冻结权重 parser.add_argument('--freeze-layers', type=bool, default=True) parser.add_argument('--device', default='cuda:0', help='device id (i.e. 0 or 0,1 or cpu)') opt = parser.parse_args() main(opt)- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 61
- 62
- 63
- 64
- 65
- 66
- 67
- 68
- 69
- 70
- 71
- 72
- 73
- 74
- 75
- 76
- 77
- 78
- 79
- 80
- 81
- 82
- 83
- 84
- 85
- 86
- 87
- 88
- 89
- 90
- 91
- 92
- 93
- 94
- 95
- 96
- 97
- 98
- 99
- 100
- 101
- 102
- 103
- 104
- 105
- 106
- 107
- 108
- 109
- 110
- 111
- 112
- 113
- 114
- 115
- 116
- 117
- 118
- 119
- 120
- 121
- 122
- 123
- 124
- 125
- 126
- 127
- 128
- 129
- 130
- 131
- 132
- 133
- 134
- 135
- 136
- 137
- 138
- 139
- predict.py
import os import json import torch from PIL import Image from torchvision import transforms import matplotlib.pyplot as plt from vit_model import vit_base_patch16_224_in21k as create_model def main(): device = torch.device("cuda:0" if torch.cuda.is_available() else "cpu") data_transform = transforms.Compose( [transforms.Resize(256), transforms.CenterCrop(224), transforms.ToTensor(), transforms.Normalize([0.5, 0.5, 0.5], [0.5, 0.5, 0.5])]) # load image img_path = "../data_set/flower_photos/daisy/5547758_eea9edfd54_n.jpg" assert os.path.exists(img_path), "file: '{}' dose not exist.".format(img_path) img = Image.open(img_path) plt.imshow(img) # [N, C, H, W] img = data_transform(img) # expand batch dimension img = torch.unsqueeze(img, dim=0) # read class_indict json_path = './class_indices.json' assert os.path.exists(json_path), "file: '{}' dose not exist.".format(json_path) with open(json_path, "r") as f: class_indict = json.load(f) # create model model = create_model(num_classes=5, has_logits=False).to(device) # load model weights model_weight_path = "./weights/model-9.pth" model.load_state_dict(torch.load(model_weight_path, map_location=device)) model.eval() with torch.no_grad(): # predict class output = torch.squeeze(model(img.to(device))).cpu() predict = torch.softmax(output, dim=0) predict_cla = torch.argmax(predict).numpy() print_res = "class: {} prob: {:.3}".format(class_indict[str(predict_cla)], predict[predict_cla].numpy()) plt.title(print_res) for i in range(len(predict)): print("class: {:10} prob: {:.3}".format(class_indict[str(i)], predict[i].numpy())) plt.show() if __name__ == '__main__': main()- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
-
相关阅读:
【计算机网络】如何让客户端构造一个HTTP请求
用CRM系统提高企业销售效率
LIN总线
网络编程套接字 | UDP套接字
【java数据结构】栈和队列
Pythons开发环境搭建(Anaconda+Pycharm+PyQt)安装教程
m4a怎么转换mp3?4个方法包教包会
Github上前十大开源Rust项目
数字塔问题
11.10记录纪要
- 原文地址:https://blog.csdn.net/qq_51957239/article/details/132912677