-
排序算法:非比较排序(计数排序)
朋友们、伙计们,我们又见面了,本期来给大家解读一下有关排序算法的相关知识点,如果看完之后对你有一定的启发,那么请留下你的三连,祝大家心想事成!
C 语 言 专 栏:C语言:从入门到精通
数据结构专栏:数据结构
个 人 主 页 :stackY、

目录
1.计数排序
在之前我们接触到的排序算法都是通过两数比较,按需排序,那么本期就来见识一下不需要进行比较就可以排序的一种新的排序算法:计数排序
1.1基本逻辑:
1. 统计一组数组中每个数据出现的次数
2. 根据统计出的次数进行归位
有一组数据,还有一个统计次数的数组CountA(默认里面都是0),在这组数据中从头开始遍历,假设这组数据的第一个元素为6,那么就需要CountA中下标为6的元素加一,依次类推,直到遍历完整个数据。
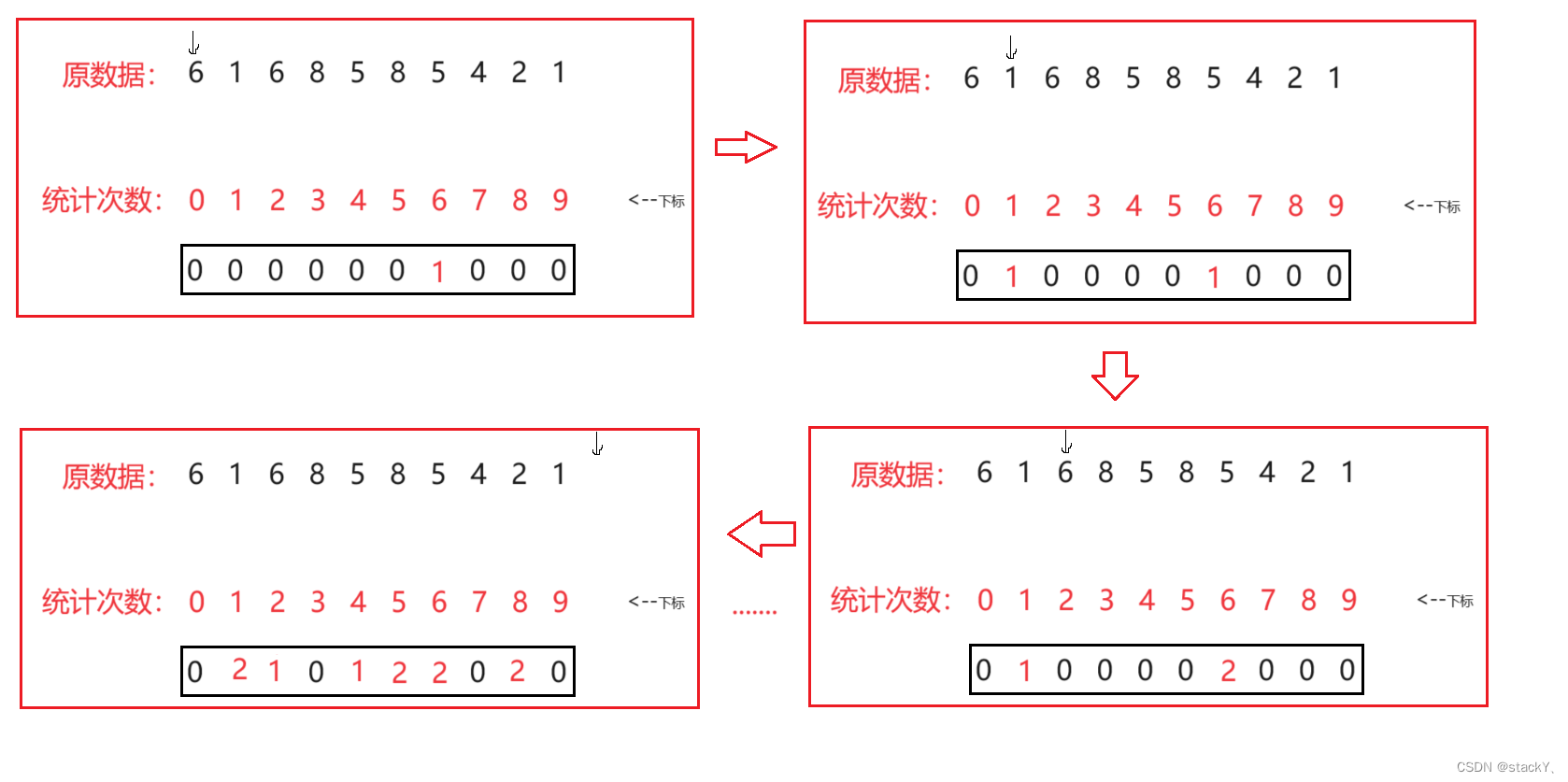
统计出每个数据出现的次数,将不为0的数据按照出现的次数依次拷贝至原数组,这样子就完成了排序。
那么这里就存在一个问题,不是每一次排序都是10以内的数据,那么如果是100~109之间的数据进行排序,我们对应是不是也要开0~109这么大的数组然后只使用100~109这个区间进行数据的统计,这样子也是可以的,但是太浪费空间,所以我们可以进行改进。
1.2改进逻辑:
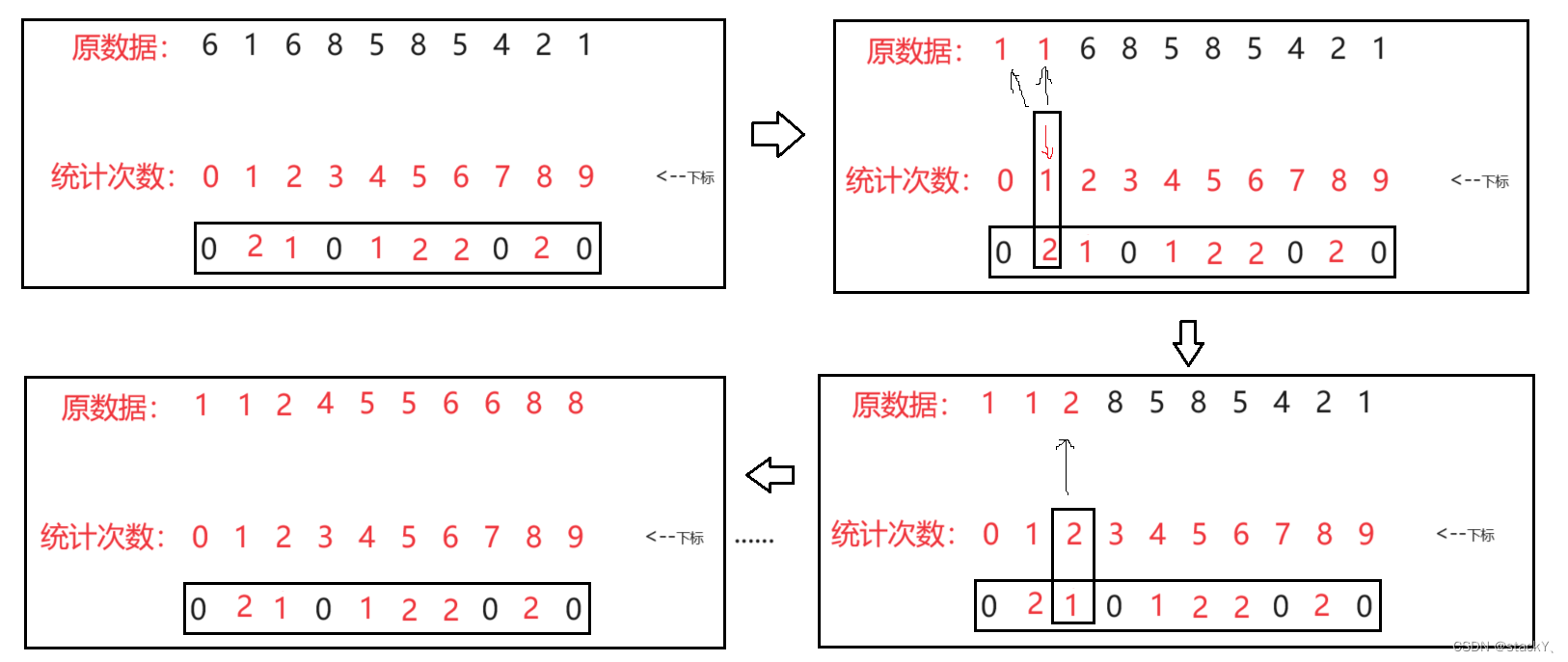
先找出整个数据中的最大值和最小值,求出它们的差值,也就是范围大小,然后创建一个统计次数的数组CountA,将里面的值都置为0,然后就到了统计次数,在统计出现次数时需要将他原来的值减去最小值,然后在创建的数组CountA里面找对应的下标,依次类推,在遍历完整个数据之后,就需要按照对应次数将数据拷贝至原数组,从CountA中往回拷贝时通过对ConutA中下标加上最小值然后拷贝至原数组,这样子即可完成排序。
代码演示:
- //非比较排序
- //计数排序
- void CountSort(int* a, int n)
- {
- //找出最大值和最小值
- int min = a[0], max = a[0];
- for (int i = 0; i < n; i++)
- {
- if (a[i] < min)
- {
- min = a[i];
- }
- if (a[i] > max)
- {
- max = a[i];
- }
- }
- //计算出范围
- int range = max - min + 1;
- //开辟空间
- int* CountA = (int*)malloc(sizeof(int) * range);
- if (CountA == NULL)
- {
- perror("CountA malloc fial");
- exit(-1);
- }
- memset(CountA, 0, sizeof(int) * range);
- //统计次数
- for (int i = 0; i < n; i++)
- {
- CountA[a[i] - min]++;
- }
- //排序
- int k = 0;
- for (int j = 0; j < range; j++)
- {
- //根据出现的次数拷贝几次
- while (CountA[j]--)
- {
- a[k++] = j + min;
- }
- }
- }
测试代码:
- void TestCountSort()
- {
- int a[] = { 6,1,6,8,5,8,5,4,2,1 };
- PrintArry(a, sizeof(a) / sizeof(int));
- CountSort(a, sizeof(a) / sizeof(int));
- PrintArry(a, sizeof(a) / sizeof(int));
- }
- int main()
- {
- TestCountSort();
- return 0;
- }

1.3计数排序的缺陷:
1. 依赖数据范围,适用于范围集中的数组。
2. 只能用于整形。
2.特点总结
1. 计数排序在数据范围集中时,效率很高,但是适用范围及场景有限。2. 时间复杂度:O(MAX(N,range)) (N和range谁大就是谁)3. 空间复杂度:O(range)4. 稳定性:稳定朋友们、伙计们,美好的时光总是短暂的,我们本期的的分享就到此结束,最后看完别忘了留下你们弥足珍贵的三连喔,感谢大家的支持!
-
相关阅读:
Python爬取豆瓣电影+数据可视化,爬虫教程!
《Tree of Thoughts: Deliberate Problem Solving with Large Language Models》中文翻译
数据结构与算法之美 复杂度分析(上)
spring-data-redis操作redis集群出现的错误
Insertion or Heap Sort
shell 各种括号作用总结
打死我也不说(深度优先搜索)
力扣刷题 数据结构与算法(十)
【Leetcode】各结构的时间复杂度
2023高教社杯数学建模国赛A题思路解析+代码+论文
- 原文地址:https://blog.csdn.net/Yikefore/article/details/132869836
