-
现代数据架构-湖仓一体
当前的数据架构已经从数据库、数据仓库,发展到了数据湖、湖仓一体架构,本篇文章从头梳理了一下数据行业发展的脉络。
上世纪,最早出现了关系型数据库,也就是DBMS,有商业的Oracle、 IBM的DB2、Sybase、Informix、 微软的SQL Server等等,这些都是OLTP类型,transactional processing, 特点是保障ACID事务,低延时,CRUD操作,作用于少量数据(非大量/全量数据)。
随着关系型数据库里的数据增长,数据分析的需求越来越多,数据仓库 data warehouse随即诞生,DW是面向集成的数据,通过ETL、ELT加载不同数据源的数据入仓,面向分析OLAP, 针对大量或者全量数据做分析,存储历史数据,支持time travel,时间旅行,可回溯到数据的早前版本,代表的有teradata,snowflake, greenplum , clickhouse,数据仓库多为MPP架构,share nothing,云时代的数据仓库如 AWS Redshift、GCP Bigquery 、 Snowflake,几乎都支持存算分离。
数据仓库中的数据通常需要经过数仓建模形成 ODS DWD DWS ADS DM等不同数据层,每层都需要进行相应的清洗加工整合等数据开发,数据工程师大量工作就聚焦在数据仓库中的数据开发方向。
随着数据量的增长,商业的数据库,数据仓库也无法应对海量数据的存储和计算,Google发表了三篇论文,业内称之为三驾马车 GFS, BigTable, Map/Reduce , 基于理论慢慢形成了Hadoop ecosystem, hdfs,hbase,hive, spark,flink...越来越多的组件构成了Hadoop生态。
Apache Hadoop开源, 但安装运维成本高,各组件间版本兼容复杂,商业发行版,Cloudera/Hortonworks 有CDH, HDP 发行版,曾经有免费的社区版,目前两家公司合并,社区版停止更新和支持,如想使用整合好的Hadoop版本,则需要付费按年订购。
再后来,随着数据的增长,非结构化数据的比重越来越大,数据湖概念被提出。
AWS对数据湖的定义:数据湖是一个集中式存储库,允许您以任意规模存储所有结构化和非结构化数据。您可以按原样存储数据(无需先对数据进行结构化处理),并运行不同类型的分析 – 从控制面板和可视化到大数据处理、实时分析和机器学习,以指导做出更好的决策。
WIKIPEDIA:数据湖是一类存储数据自然/原始格式的系统或存储,通常是对象块或者文件。数据湖通常是企业中全量数据的单一存储。全量数据包括原始系统所产生的原始数据拷贝以及为了各类任务而产生的转换数据,各类任务包括报表、可视化、高级分析和机器学习。数据湖中包括来自于关系型数据库中的结构化数据(行和列)、半结构化数据(如CSV、日志、XML、JSON)、非结构化数据(如email、文档、PDF等)和二进制数据(如图像、音频、视频)。
数据仓库和数据湖各有擅长的点,也互相有借鉴和融合,目前数仓产品大多对数据湖里的数据可以实现联邦查询,数据湖的分析引擎,通过连接器也可以查询数据仓库里的数据。
数据湖治理起来比较难,需要有完善的管理工具、管理流程和制度保障,一旦缺乏治理,容易形成数据沼泽,数据沼泽是一种退化的、缺乏管理的数据湖,数据沼泽对于用户来说要么是不可访问的要么就是无法提供足够的价值。
主流的开源数据湖平台有Delta Lake、Iceberg和Hudi,主要提供对数据湖中数据的Table定义,实现upsert/delete 、ACID 、管理 Schema Evolution等等。
数据湖有两种处理并发的两种机制。
COW(copy on write) 写时复制,读性能好,写性能差,针对多读少写场景
MOR(merge on read) 读时合并 ,写性能好,读性能略差,针对高频更新场景
Databricks的白皮书:「Lakehouse: A New Generation of Open Platforms that Unify Data Warehousing and Advanced Analytics」中最早提出了湖仓一体这个概念。Lakehouse 是一种全新的开放式架构,结合了数据湖和数据仓库的最佳元素。Lakehouses 由一个新的系统设计实现:在开放格式的低成本云存储之上直接实现与数据仓库中类似的数据结构和数据管理功能。从下图可以看到,实际目前的发展阶段如中间的架构图所示,湖仓并存,各自负责一部分自己优势的工作负载。但是从第三个架构图可以看出Databricks的雄心,它希望用低廉的存储和上面的治理层,统一实现数据湖和数据仓库的所有功能需求,简而言之,不再需要Teradata、Redshift、Snowflake这些云上云下数仓产品,任重道远。
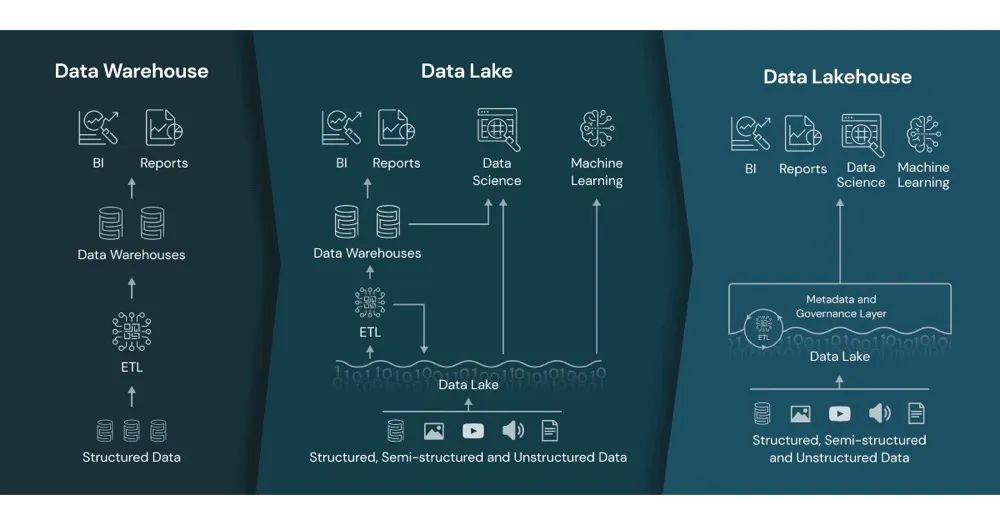
下面我们看看经常提到的术语,数据平台和数据中台。
数据平台:提供的是数据加工处理的能力,从计算和存储等技术角度看
数据中台:是一套可持续“让企业的数据用起来”的机制,一种战略选择和组织形式,是依据企业特有的业务模式和组织架构,通过有形的产品和实施方法论支撑,构建一套持续不断把数据变成资产并服务于业务的机制。
数据中台从技术角度当然包括数据平台的构建,但数据中台的外延还包括企业内部组织和流程上的支撑,目的是数据资产化,资产服务化,数据的生产和应用形成闭环,数据价值得到变现。
接下来我们来看看AWS对现代数据架构的定义:智能湖仓架构,不是简单地将数据湖和数据仓库糅合在一起,而是将数据湖、数据仓库和专用数据存储集成,从而支持统一的监管和轻松的数据移动。借助 AWS 上的现代数据架构,客户可以快速构建可扩展的数据湖,使用丰富且专业的专用数据服务,通过统一的数据访问、安全性和治理确保合规,在不降低性能的前提下以低成本扩展系统,并轻松跨越组织边界共享数据,从而快速、敏捷、大规模地作出决策。
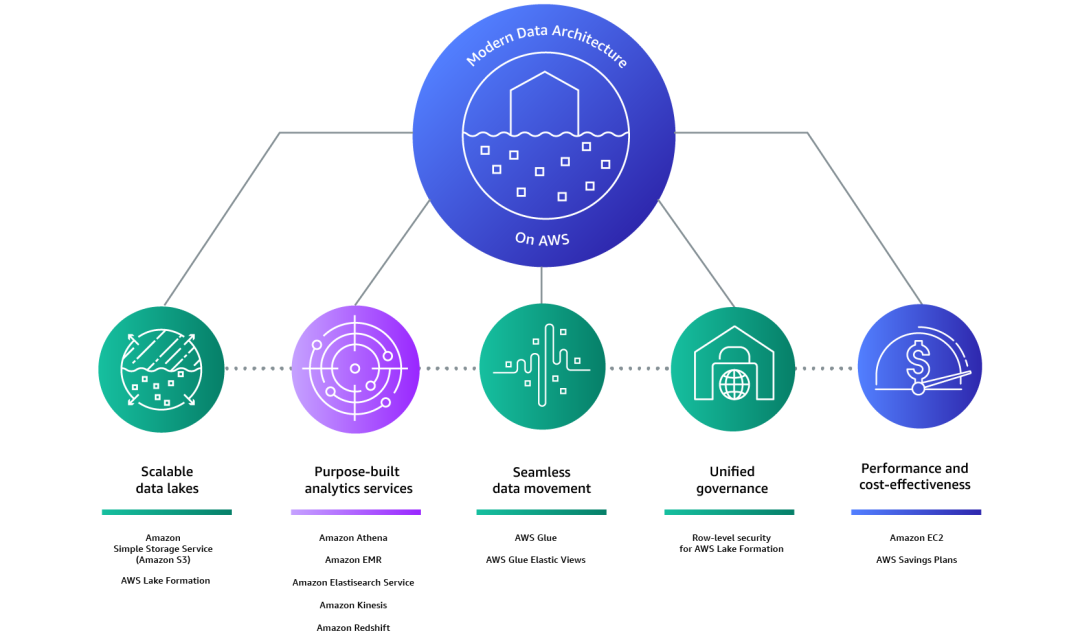
随着这些数据湖和专用存储中的数据量持续增长,由于数据具有重力,移动所有这些数据将变得越来越困难。而确保可以方便地将数据移动到需要的任何位置,具备恰当的控制,以支持分析和获取洞察也同样重要。这种数据的移动方向可能是“由内向外”、“由外向内”、“沿周界”或者“跨界共享”。
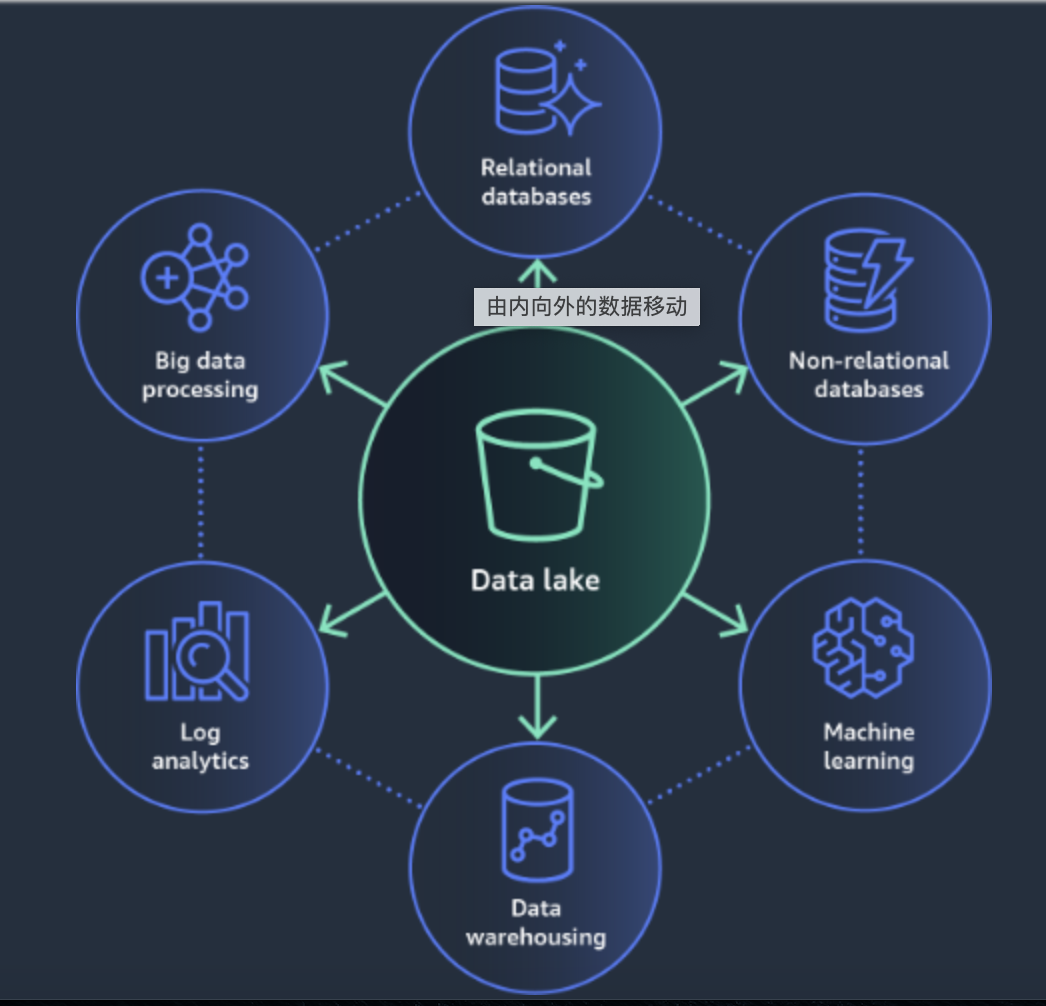
除了AWS对现代数据架构的定义,通用的现代数据架构是这样定义的。
现代数据架构是一种基于云计算、大数据和人工智能技术的数据管理和分析架构,旨在帮助企业更好地处理和分析大数据,并从中获得更多商业价值。现代数据架构通常由以下组件组成:
数据采集层:数据采集层用于从各种数据源中收集数据,并将其传输到数据存储层。数据采集层可以使用多种数据采集工具和技术,包括ETL、ELT、流数据处理等。
数据存储层:数据存储层用于存储和管理各种类型和格式的数据,包括结构化、半结构化和非结构化数据。数据存储层可以使用多种存储服务和技术,包括数据湖、数据仓库、NoSQL数据库等。
数据处理层:数据处理层用于处理和分析存储在数据存储层中的数据,以提取有价值的信息和洞察力。数据处理层可以使用多种处理和分析工具和技术,包括ApacheSpark、Hadoop、SQL Server等。
数据可视化和报表层:数据可视化和报告层用于呈现处理和分析后的数据,以便用户可以更好地理解和使用数据。数据可视化和报告层可以使用多种可视化工具和技术,包括Tableau、Power BI、Excel等。
机器学习和人工智能层:机器学习和人工智能层用于应用机器学习和人工智能技术,以提高数据处理和分析的效率和准确性。机器学习和人工智能层可以使用多种机器学习框架和技术,包括TensorFlow、PyTorch、Scikit-learn等。
现代数据架构可以帮助企业更好地管理和分析大数据,并从中获得更多商业价值。企业可以根据自身业务需求和数据特点,选择适当的组件和技术,构建适合自己的现代数据架构。
-
相关阅读:
Unity的碰撞检测(三)
3主3从redis集群配置(docker中)
微信小程序开发之路④
TensorFlow搭建LSTM实现多变量输入多变量输出时间序列预测(多任务学习)
从0开始python学习-22.selenium 常见键盘的操作
分布式运用之rsync远程同步
Makefile 介绍
Android 串口通讯
【路由交换技术】Cisco Packet Tracer基础入门教程(四)
【paddle】Vision Transformer(attention)
- 原文地址:https://blog.csdn.net/ladofwind/article/details/133235593