-
【Linux】常用工具(上)
一、Linux 软件包管理器 yum
1. 软件包
- 在Linux下安装软件, 一个通常的办法是下载到程序的源代码, 并进行编译, 得到可执行程序.
- 但是这样太麻烦了,于是有些人把一些常用的软件提前编译好, 做成软件包(可以理解成 windows 上的安装程序)放在一个服务器上,通过包管理器可以很方便的获取到这个编译好的软件包,直接进行安装.
- 软件包和软件包管理器, 就好比 “App” 和 “应用商店” 这样的关系.
2. 查看软件包
通过
yum list命令可以罗列出当前一共有哪些软件包,由于包的数目可能非常之多, 这里我们需要使用 grep 命令只筛选出我们关注的包,例如:
- 软件包名称: 主版本号.次版本号.源程序发行号-软件包的发行号.主机平台.cpu架构.
- “x86_64” 后缀表示 64位 系统的安装包,“i686” 后缀表示 32位 系统安装包. 选择包时要和系统匹配.
- “el7” 表示操作系统发行版的版本. “el7” 表示的是 centos7/redhat7. “el6” 表示 centos6/redhat6.
- 最后一列,updates 表示的是 “软件源” 的名称,类似于 “小米应用商店”,“华为应用商店” 这样的概念
3. 安装/卸载软件
通过 yum,我们可以通过很简单的一条命令完成 sl 命令的安装,
sudo yum install sl;sl 命令是一个有趣的命令,输入 sl 命令回车后屏幕上会有火车开过;我们先安装 sl 命令,因为安装需要 root 权限,所以我们在安装时要在前面加上 sudo,意思是使用 root 权限执行这条命令,如何才能使用 sudo 将会在后面介绍;如下图:
执行这条命令之后可能会让你输入当前用户的密码,我们输入即可,输入之后在短时间内再次使用 sudo 将不会再次输入密码;
随后将会进入安装过程,可能会让你确认是否安装,如下图:

意思是需要多少内存,是否确认安装,我们输入 y (确认)即可,安装好后如下图:

随后我们执行 sl 命令如下:

我们如果需要卸载 sl 命令,在命令行输入
sudo yum remove sl即可,如下图:

如上图,就已经卸载成功了,我们再次执行 sl 命令时如下:

说明已经卸载成功。
同时,我们在进行安装和卸载操作时,可以在后面加上 -y 选项,即
sudo yum install sl -y,默认确认安装,系统就不会再次询问我们是否确认安装。4. yum 其他指令的功能
yum makecache命令的功能是将服务器的软件包信息缓存到本地yum search命令可以在所有软件包中搜索包含有指定关键字的软件包yum clean all命令可以清除缓存中老旧的头文件和软件包yum clean all命令可以清除缓存中老旧的头文件和软件包yum -y upgrade只升级所有包,不升级软件和系统内核,软件和内核保持原样
二、Linux 编辑器 - vim 使用
1. vim 的基本概念
vim 是一款多模式的文本编辑器。
vi/vim 的区别简单点来说,它们都是多模式编辑器,不同的是 vim 是 vi 的升级版本,它不仅兼容 vi 的所有指令,而且还有一些新的特性在里面。例如语法加亮,可视化操作不仅可以在终端运行,也可以运行于x window、 mac os、windows。
我们先来熟悉 vim 的三种常见的模式,分别是命令模式(command mode)、插入模式(Insert mode)和底行模式(last line mode)。
他们之间的转化图如下:
- 正常/普通/命令模式(Normal mode) 控制屏幕光标的移动,字符、字或行的删除,移动复制某区段及进入 Insert mode下,或者到 last line mode
- 插入模式(Insert mode) 只有在 Insert mode下,才可以做文字输入,按「ESC」键可回到命令行模式。该模式是我们后面用的最频繁的编辑模式。
- 底行模式(last line mode) 文件保存或退出,也可以进行文件替换,找字符串,列出行号等操作。在命令模式下,
shift+:即可进入该模式。要查看你的所有模式:打开vim,底行模式直接输入 : help vim-modes
例如我们先 touch 一个 test.c 文件:

再使用 vim 进入 test.c:


其中,我们进入 test.c 之后默认是 命令模式 ,从转换图中可以看见,我们按下 i (或a、o),就可以进入插入模式,在左下角就会显式 insert 这个单词,如下图:

此时我们就可以对 test.c 这个文件进行编辑,例如我们写一个简单的 .c 文件:

此时如果我们想进入底行模式,从转化图可以看出,我们先要按下 Esc 进入命令模式,再按下 shift + ; 就可以进入底行模式了;进入底行模式后左下角会出现一个 : 如下图:

此时输入我们需要的指令即可。
2. vim 的基本操作
我们在上面已经知道,vim 默认打开的模式是命令模式,所以我们先熟悉在命令模式下的操作。
(1)光标移动(命令模式)
首先在命令模式下,我们的光标只能使用键盘的操作移动;我们可以使用键盘的 ↑ ↓ ← → 移动光标,但是我们并不常用箭头的操作移动光标,而是使用 h、j、k、l 移动。
-
h:光标向左移动一个单位
-
j:光标向下移动一个单位
-
k:光标向上移动一个单位
-
l:光标向右移动一个单位
(2)光标定位(命令模式)
除了上下左右移动光标外,我们还可以在文本中进行特定的操作,如下:
- gg:定位到代码的第一行
- shift + g:定位到代码的最后一行(n + shift + g :定位到代码的第n行)
- shift + 6(^) :定位到特定一行的开始
- shift + 4($) :定位到特定一行的结尾
- w:以单词为单位,进行向后移动,支持跨行的
- b:以单词为单位,进行向前移动,支持跨行的
(3)复制粘贴撤销(命令模式)
我们也可以对文本进行复制粘贴等操作:
- yy:复制光标所在的一行(n + yy:复制n行)
- p:粘贴内容到当前行之后(n + p:粘贴n行)
- dd:剪切/删除光标所在行(n + dd)
- u:对刚刚的操作进行撤销(即windows下的ctrl+z)
- ctrl + r:反撤销(windows下的ctrl + y)
(4)其他操作(命令模式)
- shift + `(~):文本大小写相互转换
- r:替换光标所在的字符(n + r:替换n个字符)
- x:向后删除一个字符(n + x:向后删除n个字符)
- shift + x:向前删除一个字符(n + shift + x:向前删除n个字符)
- shift + 3(#):查找同名单词,按n单次跳转
我们简单学完命令模式下的操作之后,我们再学一下底行模式的常见操作。
(5)保存并退出(底行模式)
我们在命令模式下按下 Esc ,再按下 shift + ;,即可切换到底行模式,我们在底行模式下可以执行以下操作:
- w:保存文本(w!:强制保存文本)
- q:退出当前文本(q!:强制退出文本)
- wq:保存并退出(wq!:强制保存并退出)
- set nu/nonu:为文本设置行号
除了我们所学的三个模式之外,我们再简单学两个模式,分别是替换模式、视图模式,他们之间的模式转换图如下:

(6)替换模式
首先介绍替换模式,我们在命令模式下按下 shift + r 后,就进入了替换模式,此时左下角会出现 REPLACE 这个单词,如下图:

此时我们可以直接进行替换单词,替换的是光标所在的单词,每按下一次,就会进行一次单词替换。
(7)视图模式
视图模式是用来帮助我们完成批量化注释的,例如我们需要注释多行代码,就可以使用视图模式。首先我们需要在命令模式下按下 ctrl + v 进入视图模式,进入视图模式后左下角会显示:

例如我们的文本如下,需要注释全部的 printf 函数:
随后我们需要进行批量化注释,按 j/k 两个按键上下选中区域:

随后按下 shift + i,光标会回到初始的位置:

随后我们就在这个位置加上注释符 //,最后按下 Esc:

如上图就完成批量化注释了。
总结:需要完成批量化注释的操作步骤:
- 在命令模式下:ctrl+v 进入视图模式;
- j/k 两个按键上下选中需要注释的区域;
- 按下 shift + i;
- 给当前行加上注释符;
- 按下 Esc
接下来我们进行批量化删除注释;同理我们先要进入视图模式,然后hjkl 选中区域,以上面注释的代码为例,我们删除全部注释的代码,选中区域后如下:

随后按下 d 即可,如下图:

总结:删除批量化注释步骤:
- ctrl + v 进入视图模式
- hjkl 选中区域
- 按下 d 即可
我们在进行选中区域的时候有一个小技巧,可以使用命令模式中的 n + shift + g 快速选中需要的区域。
(8)多文件编辑
vim 也支持多文件编辑, 我们需要先使用 vim 打开一个文本,进入底行模式,在底行模式中输入
vs + 需要打开的文本名字,例如下图:
如下图,就可以进行多文件编辑了:

需要注意的是,我们的光标在哪一个文本,操作的就是哪一个文本,我们可以在命令模式下按下
ctrl + ww可以切换光标到下一个的文本。小技巧:我们在使用 vim 时,打开文本后,光标所停留的地方是我们上一次保存退出后所在的位置,我们可以使用
vim test.c +n打开 test.c 后直接将光标定位到第 n 行;这是为了方便我们编译文件时,出错后可以直接定位到那一行。三、Linux 编译器 - gcc/g++ 使用
1、程序的翻译过程
在学习 gcc/g++ 之前,我们先回忆一下程序的翻译过程,预处理和程序环境;程序的翻译过程包括预处理、编译、汇编、链接。
- 预处理
预处理就是进行头文件的展开、去注释、条件编译、宏替换等操作,我们可以使用 gcc 验证这一过程,假设我们在 test.c 文件中有一段以下代码:

我们只需要执行
gcc -E test.c -o test.i即可生成预处理完后的文件,以 .i 后缀结尾,如下图:
我们使用 vim 进入 test.i 文件查看,如下图:
从图中可以看出,我们的代码已经到800多行了,说明前面的头文件已经展开了,并且注释和宏替换也已经进行了。
在
gcc -E test.c -o test.i这段指令中,其含义是使用 gcc 进行程序的翻译,待处理完预处理后就停下来,并将预处理完的程序生成以 .i 为后缀的文件;其中-E就是对文件进行预处理操作;-o + 文件名就是生成指定文件。- 编译
编译的过程就是将 C语言 转化为汇编语言,我们可以直接从源文件转化为汇编语言,也可以从预处理完后的文件转换为汇编语言;
如果从源文件直接转化为汇编语言,其指令为
gcc -S test.c -o test.s;但是我们上面已经有预处理完的文件,如果直接又从源文件开始,就重复工作了,所以我们直接从 test.i 文件转换为汇编语言,其指令为
gcc -S test.i -o test.s,如下图:
其中
gcc -S test.i -o test.s这段指令中,-S代表开始程序翻译工作,等编译完成后就停下来;其中,编译后的文件应该是以 .s 后缀为结尾的。- 汇编
汇编的过程是将汇编语言转化为可重定位的二进制文件,同上,我们也可以从源文件直接转化为二进制文件,但是我们已经将文件转为汇编文件了,所以可以从汇编文件开始转化为二进制文件,其指令为
gcc -c test.s -o test.o,如下图:
其中
-c选项代表汇编工作完成就停下来,可重定位的二进制文件是以 .o 后缀为结尾的文件,test.o 是一个不可执行的文件。- 链接
链接是将 test.o 文件加上系统库生成可执行程序的过程,其指令为
gcc test.o -o 可执行文件名,如下图: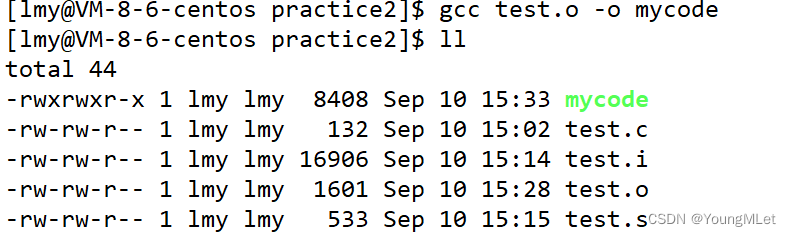
上图中的 mycode 就是一个可执行的程序文件,我们执行它只需输入指令
./mycode,如下图:
如上图就完成了程序的执行。
上面的四个步骤就是我们程序的翻译过程,但是我们平时想要执行一个程序的时候并不需要分别执行上面的步骤,例如我当前的目录下只有一个 .c 文件,如图:

我们当前可以直接将 test.c 文件直接生成可执行文件,只需要执行指令
gcc test.c即可,如下图:系统默认生成的可执行文件的名称为 a.out ,我们想要执行它的时候,只需要在当前目录下找到它直接执行即可,其指令为
./a.out,如图:
这样就完成了我们程序的执行;另外,如果我们想要 test.c 文件生成指定名称的可执行文件,可以带上
-o选项,即执行gcc test.c -o 文件名即可。以上是 gcc 的使用,其实 g++ 的使用和 gcc 的使用类似,可以完全参考 gcc,只是使用的时候将 gcc 改为 g++ 即可。其中 gcc 是编译 C语言 的编译器,而 g++ 可以编译 C语言 和 C++ .
2、动静态库的理解
我们上面的 C程序 中,并没有定义 “printf” 的函数实现,且在预编译中包含的 “stdio.h” 中也只有该函数的声明,而没有定义函数的实现,那么,是在哪里实现 “printf” 函数的呢?
答案是系统把这些函数实现都被做到名为 libc.so.6 的库文件中去了,在没有特别指定时,gcc 会到系统默认的搜索路径 /usr/lib64/libc.so.6 下进行查找,也就是链接到 libc.so.6 库函数中去,这样就能实现函数 “printf” 了,而这也就是链接的作用;我们可以看到这个文件确实存在:

- 静态库
静态库是指编译链接时,把库文件的代码全部加入到可执行文件中,因此生成的文件比较大,但在运行时也就不再需要库文件了。其后缀名一般为 .a
其中,静态库是 C/C++ 或者其他第三方提供的所有方法的集合,被所有程序以拷贝的方式,将需要的代码,拷贝到自己的可执行程序中;
静态链接的优点:无视库,可以独立运行;
静态链接的缺点:体积太大,浪费资源;默认情况下,我们的服务器是没有安装 C 静态库的,只有动态库,如果需要安装C静态库,只需要执行指令
sudo yum install glibc-static;如果需要安装C++静态库,执行指令sudo yum install -y libstdc++-static即可。sudo yum install glibc-static // c 静态库 sudo yum install -y libstdc++-static // c++ 静态库- 1
- 2
- 动态库
动态库与之相反,在编译链接时并没有把库文件的代码加入到可执行文件中,而是在程序执行时由运行时链接文件加载库,这样可以节省系统的开销。动态库一般后缀名为 .so,如前面所述的 libc.so.6 就是动态
库。gcc 在编译时默认使用动态库。完成了链接之后,gcc 就可以生成可执行文件。
动态链接的优点:形成的可执行程序体积比较小,节省资源;
动态链接的缺点:稍慢一些,强依赖动态库,动态库没了,所有依赖这个库的程序都无法运行了; -
相关阅读:
一卷到底,大明哥带你横扫 Netty
PPT制作小技巧分享
响应式数据
AC/DC电源模块工作效率的特点
排序(二分法查找、冒泡排序、选择排序、插入排序以及快速排序)
《迷失岛2》游戏开发框架开发日记:场景切换和淡入淡出效果
使用BigDecimal的坑
SpringBoot:如何优雅地进行响应数据封装、异常处理?
浏览器如何更改定位位置-VMLogin指纹浏览器Geolocation经纬度设置
为什么C++这么复杂还不被淘汰?
- 原文地址:https://blog.csdn.net/YoungMLet/article/details/132756723