-
[论文笔记]Adapter turning
引言
今天带来第一篇大语言模型高效微调的论文Adapter Tuning笔记。
预训练+微调的范式是一种高效的迁移学习机制。然而,当有很多下游任务时,微调参数并不高效:对于每个任务都要有一个全新的模型。
作者提出了基于adapter模块的迁移学习方法,可以产生一个紧凑和可扩展的模型。只需要为每个任务增加少部分可训练参数,而固定原来模型的参数。
作者说Adapter可以获取接近SOTA的表现。
总体介绍
在预训练的模型中进行迁移学习可以在很多NLP任务上得到很好的表现。当下游任务很多时,又不希望为每个下游任务微调一个全新的模型。
作者提出了基于adapter模块的迁移学习方法,可以产生一个紧凑和可扩展的模型。紧凑意味着对于每个任务只需要额外少量的参数。可扩展意味着可以逐步训练以解决新任务,而不会忘记先前的任务。
在NLP中最常用的迁移学习技术有两种,分别是基于特征的迁移和微调。作者提出了基于adapter模块的另一种迁移学习方法。
基于特征的迁移关于预训练实数嵌入向量,这些向量可以为单词、语句或段落级别。然后把这些向量应用到自定义的下游模型。
微调就是从预训练的模型中拷贝权重然后基于下游任务更新它们。最近的工作表面微调通常效果比基于特征要好。
但是这两种方法都需要为每个任务训练一组新的权重,而作者提出的adpater微调方法可以更高效的利用参数。
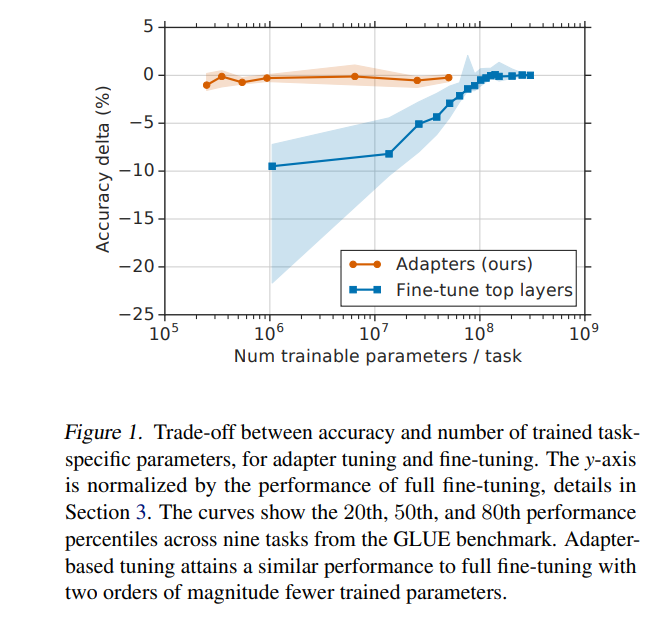
图1的x轴表示每
-
相关阅读:
PPT导出PDF时保持图像高清的方法
技术干货 | 数据处理好难?来看MindSpore提供的解决思路!
Mysql分组查询每组最新的一条数据
Nginx中配置GZIP压缩详解
浅谈一下:Java当中的类和对象
LLVIP数据集下载
FFmpeg 命令:从入门到精通 | ffppeg 命令提取音视频数据
正则表达式:整数
Docker-consul容器服务更新与发现
2024江苏专转本流程与时间节点
- 原文地址:https://blog.csdn.net/yjw123456/article/details/133027362