-
LLM(二)| LIMA:在1k高质量数据上微调LLaMA1-65B,性能超越ChatGPT
本文将介绍在Lit-GPT上使用LoRA微调LLaMA模型,并介绍如何自定义数据集进行微调其他开源LLM
监督指令微调(Supervised Instruction Finetuning)
什么是监督指令微调?为什么关注它?
目前大部分LLM都是decoder-only,通常是续写任务,有时候未必符合用户的需求,SFT是通过构造指令输入和期待的输出数据微调LLM,让LLM根据输入的指令输出期待的内容,这样微调好的LLM会输出更符合用户需求或者特点任务,

SFT数据格式一般如下所示:
-
Instruction text
-
Input text (optional)
-
Output text
Input是可选的,下面是SFT数据格式的示例:

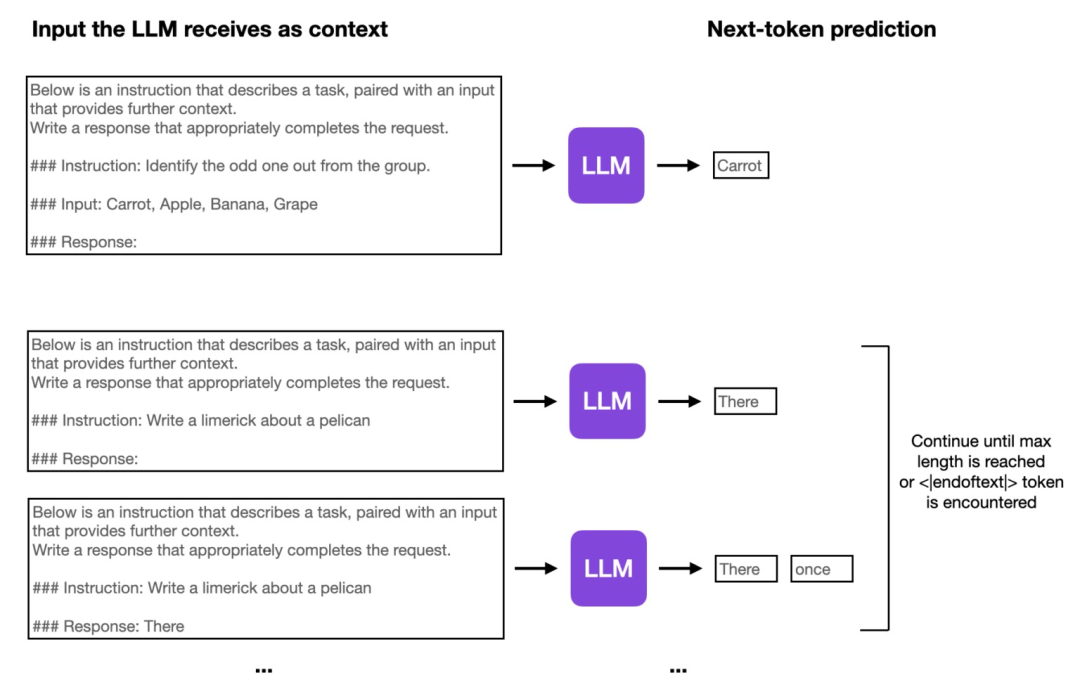
SFT的微调和Pre-training是一样的,也是根据上文预测下一个token,如下图所示:
SFT数据集如何生成?
SFT数据集构建通常有两种方法:人工标注和使用LLM(比如GPT-4)来生成的,人工标注对于构建垂直领域比较合适,可以减少有偏数据,但是成本略高;使用LLM生成,可以在短时间内生成大量数据。
SFT数据集构建以及SFT微调Pipeline如下图所示:

LLM生成SFT数据方法总结
Self-Instruct
Self-Instruct(https://arxiv.org/abs/2212.10560):一个通过预训练语言模型自己引导自己来提高的指令遵循能力的框架。
Self-Instruct有如下四个阶段:
-
步骤1:作者从 175个种子任务中随机抽取 8 条自然语言指令作为示例,并提示InstructGPT生成更多的任务指令。
-
步骤2:作者确定步骤1中生成的指令是否是一个分类任务。如果是,他们要求 InstructGPT 根据给定的指令为输出生成所有可能的选项,并随机选择特定的输出类别,提示 InstructGPT 生成相应的“输入”内容。对于不属于分类任务的指令,应该有无数的“输出”选项。作者提出了“输入优先”策略,首先提示 InstructGPT根据给定的“指令”生成“输入”,然后根据“指令”和生成的“输入”生成“输出”。
-
步骤3:基于第 2 步的结果,作者使用 InstructGPT 生成相应指令任务的“输入”和“输出”,采用“输出优先”或“输入优先”的策略。
-
步骤4:作者对生成的指令任务进行了后处理(例如,过滤类似指令,去除输入输出的重复数据),最终得到52K条英文指令
完整的Self-Instruct流程如下图所示:

Alpaca dataset(https://github.com/gururise/AlpacaDataCleaned)的52K数据就是采用该方法生成的。
Backtranslation
回译在传统的机器学习中是一种数据增强方法,比如从中文翻译成英文,再从英文翻译会中文,这样生成的中文与原来的中文在语义上是一致的,但是文本不同;然而SFT数据生成的回译(https://arxiv.org/abs/2308.06259)则是通过输出来生成指令,具体步骤如下图所示:

LIMA
LIMA来自论文《The LIMA: Less Is More for Alignment》,LIMA是在LLaMA V1 65B模型上使用1k高质量数据进行微调获得的,性能如下:

在Lit-GPT库上微调LLM
Lit-GPT支持的模型如下表所示:
Model and usage Reference Meta AI Llama 2 Touvron et al. 2023 Stability AI FreeWilly2 Stability AI 2023 Stability AI StableCode Stability AI 2023 TII UAE Falcon TII 2023 OpenLM Research OpenLLaMA Geng & Liu 2023 LMSYS Vicuna Li et al. 2023 LMSYS LongChat LongChat Team 2023 Together RedPajama-INCITE Together 2023 EleutherAI Pythia Biderman et al. 2023 StabilityAI StableLM Stability AI 2023 Platypus Lee, Hunter, and Ruiz 2023 NousResearch Nous-Hermes Org page Meta AI Code Llama Rozière et al. 2023 下面以LLaMA2-7B为例说明在 上进行微调的步骤,首先需要clone
Lit-GPT仓库,微调步骤如下:
1)下载、准备模型
export HF_TOKEN=your_tokenpython scripts/download.py \--repo_id meta-llama/Llama-2-7b-hfpython scripts/convert_hf_checkpoint.py \--checkpoint_dir meta-llama/Llama-2-7b-hf2)准备微调数据
python scripts/prepare_lima.py \--checkpoint_dir checkpoints/meta-llama/Llama-2-7b-hf3)使用LoRA进行微调
python finetune/lora.py \--checkpoint_dir checkpoints/meta-llama/Llama-2-7b-hf \--data_dir data/limaTips
官方建议数据的tokens控制在2048之内,可以减少GPU显存消耗,对应的代码也需要增加参数--max_seq_length 2048
python scripts/prepare_lima.py \--checkpoint_dir checkpoints/meta-llama/Llama-2-7b-hf \--max_seq_length 2048或者也可以修改 finetune/lora.py文件中的参数change override_max_seq_length = None调整为 override_max_seq_length = 2048
对于LIMA模型的1k数据进行微调,需要调整max_iters=1000

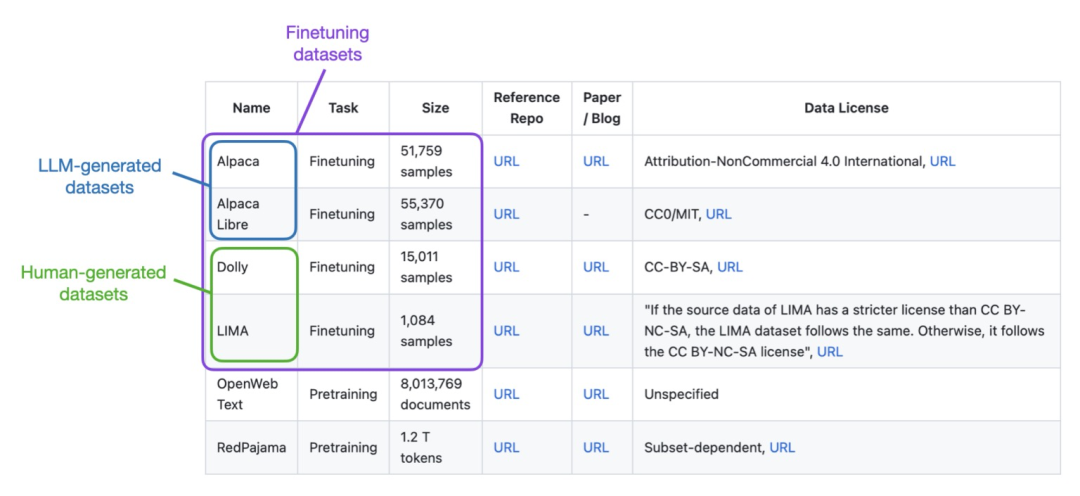
Lit-GPT上支持的数据集
Lit-GPT定义客户化数据集
加载自定义数据集大致需要两步,首先需要准备三列CSV数据,示例如下:

第一步,执行如下脚本:
python scripts/prepare_csv.py \--csv_dir MyDataset.csv \--checkpoint_dir checkpoints/meta-llama/Llama-2-7b-hf第二步,与上述LIMA类似,是执行scripts/prepare_dataset.py脚本
参考文献:
[1] https://lightning.ai/pages/community/tutorial/optimizing-llms-from-a-dataset-perspective/
-
-
相关阅读:
JavaFX开发教程——前后端交互(Controller)
动漫主题dreamweaver作业静态HTML网页设计——仿京东(海贼王)版本
Mybatis-Plus条件构造器学习and方法
八百客、销售易、纷享销客各行其道
利用向日葵和微信/腾讯会议实现LabVIEW远程开发
求告知!该如何解决这个问题
数字孪生车间
Vue 商城项目开发实战
Matlab常用函数(control)
k8s-生产级的k8s高可用(1) 24
- 原文地址:https://blog.csdn.net/wshzd/article/details/133159758