-
2023华为杯研究生数学建模竞赛选题建议+初步分析
如下为C君的2023华为杯研究生数学建模竞赛(研赛)选题建议+初步分析
2023华为杯研究生数学建模竞赛(研赛)选题建议
提示:DS C君认为的难度:C=E
华为专项的题目(A、B题)暂不进行选题分析,不太建议大多数同学选择,对自己专业技能有很大自信的可以选择华为专项的题目。后续团队会直接更新A、B题思路,以下为CDEF题选题建议及初步分析:
C题:大规模创新类竞赛评审方案研究
C题是建模+评价类题目。题目需要按照给定的规则对大规模的竞赛做优良的评审方案。
C君觉得这道题不算难,之前训练过大数据、数据分析类题目的同学都可以做。这里简单提一下第一问,第一问需要建立数学模型确定最优的“交叉分发”方案,并讨论该方案的有关指标(自己定义)和实施细节。
这里方案考虑的因素尽量越多越好,有关指标的定义是关键,大家可以一开始想尽量多的指标,然后在后面可以进行相关性分析等算法,对很多的指标进行降重。
这里推荐的算法为拟合类算法和评价类算法。拟合类推荐:
最小二乘法(Least Squares Method):通过最小化观测值与拟合曲线之间的差距来进行拟合,适用于线性和非线性问题。
多项式拟合(Polynomial Fitting):将数据拟合为一个多项式函数,可以通过最小二乘法或牛顿插值法等方法实现。
线性回归(Linear Regression):通过拟合一个线性模型来描述观测值与预测变量之间的关系,可以使用最小二乘法来求解模型参数。
非线性回归(Nonlinear Regression):通过拟合一个非线性模型来描述观测值与预测变量之间的关系,通常需要使用迭代优化算法进行求解,如Levenberg-Marquardt算法。
曲线拟合(Curve Fitting):将数据拟合为一条曲线,可以使用多种拟合函数,如指数函数、对数函数、幂函数等。
插值法(Interpolation):通过已知数据点之间的插值来估计未知数据点的值,常见的插值方法有拉格朗日插值、牛顿插值、样条插值等。
核函数回归(Kernel Regression):通过使用核函数对数据进行加权平滑处理,来实现对非线性关系的拟合。
非参数回归(Nonparametric Regression):不依赖于事先设定的函数形式,而是根据数据的分布进行拟合,常见的方法有局部加权回归、核密度估计等。评价类算法,比如灰色综合评价法、模糊综合评价法对各个指标建立联系。
这道题建议统计学、数学等相关专业同学选择,难度适中,开放度较高。
D题:区域双碳目标与路径规划研究
D题是常见的建模+政策类问题。对于这种问题,建模比赛中经常会遇到,大家可以多去参考往年的其他比赛的相关赛题,很多都是有优秀论文的。
本题需要分析、评价和预测能效提升、产业(产品)升级、能源脱碳和能源消费电气化等重点工程对碳排放的影响。这道题目重点就是如何去找指标,建立对应数学建模,其中题目给了很多限制条件,相对而言这道题目也不算难。
所有专业的同学应该都可以选择这道题目,开放度较高,后续我们也会持续更新思路、代码等的。
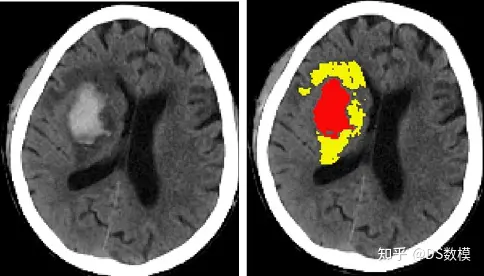
E题:出血性脑卒中临床智能诊疗建模
这道题就是很多同学在训练的时候经常做的题目类型了,属于大数据、数据分析类题目,同时也是团队擅长的题目。需要一定的建模能力,和其他赛事赛题类型类似,建议大家(各个专业均可)进行选择。
题目需要通过对真实临床数据的分析,研究出血性脑卒中患者血肿扩张风险、血肿周围水肿发生及演进规律,最终结合临床和影像信息,预测出血性脑卒中患者的临床预后。建立数学模型,大家可以使用评价类算法,比如灰色综合评价法、模糊综合评价法对各个指标建立联系。
第一问前大家需要对数据进行分析和数值化处理,也就是EDA(探索性数据分析)。对于数值型数据,大家用归一化、去除异常值等方式就可以进行数据预处理。而对于非数值型数据进行量化,大家可以使用以下方法:
1标签编码
标签编码是将一组可能的取值转换成整数,从而对非数值型数据进行量化的一种方法。例如,在机器学习领域中,对于一个具有多个类别的变量,我们可以给每个类别赋予一个唯一的整数值,这样就可以将其转换为数值型数据。
2独热编码onehot
独热编码是将多个可能的取值转换成二进制数组的一种方法。在独热编码中,每个可能取值对应一个长度为总共可能取值个数的二进制数组,其中只有一个元素为1,其余元素均为0。例如,对于一个性别变量,可以采用独热编码将“男”和“女”分别转换为[1, 0]和[0, 1]。
3分类计数
分类计数是将非数值型数据转换为数值型数据的一种简单方法。在分类计数中,我们根据某些特定属性(比如学历、职业等)来对数据进行分类,然后统计每个类别的数量或频率。例如,在调查问卷中,我们可以对某个问题的回答按照“是”、“否”和“不确定”三个类别进行分类,并计算每个类别的数量或频率。
4主成分分析
主成分分析是将多维数据转换为低维度表示的一种方法。在主成分分析中,我们通过找到最能解释数据变异的主成分来对原始数据进行降维处理。这样就可以将非数值型数据转换为数值型数据。
而第一问建议大家使用一些可视化方法,可以使用常见的EDA可视化方法:
l 直方图和密度图:展示数值变量的分布情况。
l 散点图:展示两个连续变量之间的关系。
l 箱线图:展示数值变量的分布情况和异常值。
l 条形图和饼图:展示分类变量的分布情况。
l 折线图:展示随时间或顺序变化的趋势。
l 热力图:展示不同变量之间的相关性。
l 散点矩阵图:展示多个变量之间的散点图矩阵。
l 地理图:展示地理位置数据和空间分布信息。
由于和时间序列相关,所以推荐大家使用一些时间序列算法,比如ARIMA等。
由于这篇是选题建议,详细思路可以看我的后续文章/视频。就不赘述了。数据集怎么分析,可视化代码什么的,后续会更新。这道题目开放度较高,难度较易,是本次比赛获奖的首选题目。推荐所有专业同学选择门槛较低且开放度也相对较高。
F题:强对流降水临近预报
F题是数模类赛事很常见的物理类赛题,需要学习不少相关知识。一些数值计算的部分,应该还需要用到运筹学的多目标规划和一些专业相关的算式。
另外题目中提到了一类基于卷积神经网络(Convolutional Neural Networks, CNNs),如U-Net等模型[3];另一类基于循环神经网络(Recurrent Neural Networks, RNNs),如ConvLSTM、DGMR等模型[4, 5]。
代表可能需要用到深度学习的相关知识。另外,建议大家重点关注题目中给到的这些参考文献,建议大家都去阅读检索一下,把能用的都提炼出来。
这道题目建议物理、电气、数学等相关专业同学选择,相对而言门槛较高,小白/非相关专业同学谨慎选择。C君建议在最后对对答案,答案的正确与否会对最终成绩产生较大影响。
其中各题目思路、代码、讲解视频、论文及其他相关内容,可以点击下方群名片哦!
-
相关阅读:
LeetCode --- 2068. Check Whether Two Strings are Almost Equivalent 解题报告
软考 - 系统架构设计师 - ESB(企业服务总线)例题
树莓派4B简单使用内容(以移植QT应用为例)
力扣第257题 二叉树的所有路径 c++ 树 深度优先搜索 字符串 回溯 二叉树
每日五问(java)
数据清洗:相似重复记录检测算法SNM及其Python实现
【尾篇】《信息资源管理》第7章 | 企业与政府信息资源管理
艾体宝案例 | 使用Redis和Spring Ai构建rag应用程序
木犀草素修饰人血清白蛋白(Luteolin-HSA),山柰酚修饰人血清白蛋白(Kaempferol-HSA)
Java多线程总结
- 原文地址:https://blog.csdn.net/weixin_43345535/article/details/133157199