-
一次ES检索的性能优化经验记录
优化功能: 统一检索能力,为各服务所调用。
该接口并发压力大,压测效果不理想。
初步2k线程两台压测机预发环境压测结果两pod下为400qps左右,单pod 平均qps200,响应时间在五分钟之后达到了峰值,平响达到几十秒开外。- 压测环境:内网环境,过网关压测,压测链路:网关→后台服务。
一、优化初期
出现这样的情况,是意想之外的,考虑到,现有的压测环境,在之前已预估es集群资源规划,并提交运维部署,es本身有多种缓存机制, 包括角色划分等,使得集群具有一定的健壮性。已当前的数据,应该被es集群当作热点数据缓存到文件缓存中,除去给到es主节点的4g堆内存与其他data节点的堆内存开外,文件缓存完全够用。

由于考虑到es集群性能应该还是可以的,碰到这样的性能问题,首先考虑到的是网络io及磁盘io等,因此首先验证io问题,经询问压测同事并经其验证,内网环境下,且压测机性能足够的情况下,在压测几分钟之后的确出现了访问及其缓慢的情况。
此时方向转向磁盘io,经询问运维得知,预发布环境es集群并未按照预想的,进行角色划分,分配资源等,且日志使用相同的es集群

上图中可以看到es集群的三个节点并未划分角色,同时ram内存占用有两个data数据节点较高,es内存除本身程序的jvm堆内存占用之外,剩余的内存可以被Lucene占用,理论上留给Lucene的内存越多,查询性能越好.
经查看该集群的索引情况,发现日志相关的索引,有的单索引都已经达到了7G之多。
因此可以猜测:在压测过程中,es集群负载较高,在内存未达百分百之前,es查询性能并未明显下降,但当内存占用达到百分百后,性能开始明显下降。
由于猜测无法验证,集群资源都不在自己这,只能与运维沟通,按照我给的es集群配置,来增强正式环境es集群的健壮性。二、旁敲侧击
在得知无法验证自己的猜想后,转而正好被同事告知,在项目代码中,配置es客户端所连接的集群节点时,只配置了其中一个节点,这让我想起,代码层可能还有优化的余地。
首先来说,只配置一个节点,并不会影响程序的查询效果,这得益于es集群内但节点的多角色性,默认情况下,每个节点都是候选主节点,都有可能成为主节点,同时每个节点又默认都是协调节点,这就导致,只配置了一个节点,但通过协调节点的特性,可以路由到其他节点进行shard查询,并归并结果。
这带来了第一个问题: 由于没有客户端的负载,路由压力虽然很小,但都打到了该节点上,其次是如果真的出现主节点宕机且正好为配置的该节点,则会出现长时间的不可用。
在同事修改完代码配置后添加其余节点后,再次审视之前的代码,发现所有的检索请求,无一例外进行了es聚类分析(聚合),这首先会对es集群带来更高的cpu和内存消耗,因此首先对代码进行一波调优:
拆分es查询条件,细化粒度,只对需要聚合分析的场景进行聚合,避免不必要的性能消耗。再次进行一波模拟压测。依旧不尽人意,最终考虑到:
- es查询时效性要求不高
- 数据一致性要求不高
- 本身具有多种缓存机制
因此考虑添加caffeine本地缓存,进行有限容量下,无限缓存+主动刷新缓存的策略,来实现性能的第一波跨越
@Configuration @Slf4j @EnableCaching public class CaffeineCacheConfig { private static final ExecutorService TASK_EXECUTOR = new ThreadPoolExecutor(30, 50, 5, TimeUnit.SECONDS, new ArrayBlockingQueue<>(1000, false), new ThreadFactoryBuilder().setNamePrefix("refreshSearchResThread-").build(), new ThreadPoolExecutor.AbortPolicy()); @Bean public Caffeine<Object, Object> caffeineCache() { return Caffeine.newBuilder() .refreshAfterWrite(5, TimeUnit.SECONDS) .softValues() // 初始的缓存空间大小 .initialCapacity(1000) // 使用自定义线程池 .executor(TASK_EXECUTOR) .removalListener(((key, value, cause) -> log.info("key:{} removed, removalCause:{}.", key, cause.name()))) // 缓存的最大条数 .maximumSize(100000); } @Bean public CacheManager cacheManager() { CaffeineCacheManager caffeineCacheManager = new CaffeineCacheManager(); caffeineCacheManager.setCaffeine(caffeineCache()); caffeineCacheManager.setAllowNullValues(true); caffeineCacheManager.setCacheLoader(new CacheLoader<Object, Object>() { @Override public Object load(Object key) { log.info("载入缓存key:{}", key); return null; } @Override public Object reload(Object key, Object oldValue) { log.info("刷新缓存key:{},oldValue{}", key, oldValue); return null; } }); return caffeineCacheManager; } }- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
@Cacheable(cacheNames = {"search:req:hash"}, key = "#searchParamVO.hashCode()", sync = true)- 1
以上采用集成springboot cache注解的方式,采用缓存失效同步刷新,仅一个线程抢锁进入刷新缓存,防止缓存击穿,使用入参的hashCode作为缓存key来实现本地缓存机制。
在修改完代码后,再次进行一波模拟压测,效果显著提升。

但出于对性能的严苛追求,在观察模拟压测qps情况,以及平响之后发现,平响虽较之前有了明显优化,进入到了个位数的秒级,即六秒多,深感不应该出现这样的问题,仔细观察曲线发现,曲线波动比较频繁,下意识考虑到程序的jvm波动及线程阻塞情况。
此时通过jprofile检测正在运行的jvm,再次进行一波模拟压测,查看线程实时状态(可通过jstack或jconsole查看),发现存在线程hang住的情况,再次观察,发现是logback日志输出时的ASYNC-ALL appender 相关的线程出现了阻塞。
当时出问题的配置:
<appender name="ASYNC-ERROR" class="ch.qos.logback.classic.AsyncAppender"> <discardingThreshold>0discardingThreshold> <appender-ref ref="FILE-ERROR"/> appender> <appender name="ASYNC-WARN" class="ch.qos.logback.classic.AsyncAppender"> <discardingThreshold>0discardingThreshold> <appender-ref ref="FILE-WARN"/> appender> <appender name="ASYNC-ALL" class="ch.qos.logback.classic.AsyncAppender"> <discardingThreshold>0discardingThreshold> <appender-ref ref="FILE-ALL"/> appender> <appender name="ASYNC-DEBUG" class="ch.qos.logback.classic.AsyncAppender"> <appender-ref ref="FILE-DEBUG"/> appender> <appender name="ASYNC-STDOUT" class="ch.qos.logback.classic.AsyncAppender"> <appender-ref ref="STDOUT"/> appender>- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
由于当时新加了all日志,即不配置filter过滤日志级别的日志appender,直接copy了上方的warn及error日志的配置,忘了修改其discardingThreshold参数。
discardingThreshold参数的含义为: 队列剩余容量少于discardingThreshold的配置就会丢弃<=INFO级别的日志,warn与error日志的appender为了防止日志丢失,配置了值为0,及阻塞线程直到输出完毕。
但all日志为不分日志级别全都输出,还配置此参数,这就导致了并发压力大的情况下,logback日志线程阻塞队列默认容量256,及queueSize=256,可能会出现的线程阻塞的情况。修改后的参数如下:<appender name="ASYNC-ERROR" class="ch.qos.logback.classic.AsyncAppender"> <discardingThreshold>0discardingThreshold> <appender-ref ref="FILE-ERROR"/> appender> <appender name="ASYNC-WARN" class="ch.qos.logback.classic.AsyncAppender"> <discardingThreshold>0discardingThreshold> <appender-ref ref="FILE-WARN"/> appender> <appender name="ASYNC-ALL" class="ch.qos.logback.classic.AsyncAppender"> <appender-ref ref="FILE-ALL"/> <neverBlock>trueneverBlock> appender> <appender name="ASYNC-DEBUG" class="ch.qos.logback.classic.AsyncAppender"> <appender-ref ref="FILE-DEBUG"/> <neverBlock>trueneverBlock> appender> <appender name="ASYNC-STDOUT" class="ch.qos.logback.classic.AsyncAppender"> <appender-ref ref="STDOUT"/> <neverBlock>trueneverBlock> appender>- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
去除了all日志appender的discardingThreshold参数,添加了neverBlock参数为true。
再次进行模拟压测,平响由6秒提升到了两秒左右,同时波动曲线依旧出现不平稳的情况,此时查看jvm gc情况,在堆内存不足设置过小的情况下,频繁的old gc可能会导致波动曲线不稳的情况,此时对jvm进行参数配置的更改:
-Xms2g -Xmx2g -Xmn512m -XX:MaxMetaspaceSize=256m -XX:SurvivorRatio=8 -XX:+HeapDumpOnOutOfMemoryError -XX:HeapDumpPath=/pid$KaTeX parse error: Expected group after '_' at position 1: _̲(date +%Y-%m-%d_%H:%M:%S)_oom.hprof -Dfile.encoding=UTF-8 -XX:+UseG1GC
再次查看线程情况,发现每隔一段时间,请求的tomcat线程依旧会出现大规模hang住等待的情况,这是由于之前的缓存刷新策略,为了防止缓存击穿,高并发请求下,大量请求在缓存失效的瞬间打到es集群,采用了sync=true的方式。即当缓存失效时,仅有一个抢锁成功的线程,进入业务逻辑,刷新缓存,其他线程阻塞等待缓存刷新完毕。
难道其他线程在此全都等着,这合理吗?
当然不行,我们知道,八股文会告诉你,可以这样搞,但其实生产环境,还真很少有这样做的,如果采用分布式缓存,例如redis,其实可以采取无限缓存+刷新的机制,给到一个逻辑过期时间,当进入的请求获取缓存取到逻辑过期时间判断已过期时,才去抢锁进行刷新缓存,其余的则取旧缓存直接返回。这就避免了线程hang住,高并发下瞬间打爆连接池的情况。
那么我们采用的是本地缓存,有没有什么方法能避免呢?
有,可以通过缓存预热初始化缓存单线程执行,配合定时异步刷新缓存的机制实现,更改后的代码如下:
private static final ExecutorService TASK_EXECUTOR = new ThreadPoolExecutor(30, 50, 5, TimeUnit.SECONDS, new ArrayBlockingQueue<>(1000, false), new ThreadFactoryBuilder().setNamePrefix("refreshSearchResThread-").build(), new ThreadPoolExecutor.AbortPolicy()); @Resource private UnifySearchService unifySearchService; private static final Map<String, Object> map = new ConcurrentHashMap<>(); @Bean public @NonNull LoadingCache<Object, Object> caffeineCache(CacheLoader<Object, Object> cacheLoader) { return Caffeine.newBuilder() .refreshAfterWrite(5, TimeUnit.SECONDS) .softValues() // 初始的缓存空间大小 .initialCapacity(1000) // 使用自定义线程池 .executor(TASK_EXECUTOR) .removalListener(((key, value, cause) -> log.info("key:{} removed, removalCause:{}.", key, cause.name()))) // 缓存的最大条数 .maximumSize(100000) .build(cacheLoader); } @Bean public CacheLoader<Object, Object> cacheLoader() { return new CacheLoader<Object, Object>() { @Override public Object load(Object key) { log.info("载入缓存数据:{}", key); Cache<Object, Object> cache = (Cache<Object, Object>) map.get("search:req"); return cache.getIfPresent(key); } @Override public Object reload(Object key, Object oldValue) { log.info("刷新缓存key:{},oldValue{}", key, oldValue); SearchParamVO searchParamVO = (SearchParamVO) key; return ResponseResult.success(unifySearchService.search(searchParamVO)); } }; } @Bean public CacheManager cacheManager(LoadingCache<Object, Object> caffeineCache) { SimpleCacheManager simpleCacheManager = new SimpleCacheManager(); List<CaffeineCache> caches = new ArrayList<>(); map.put("search:req", caffeineCache); for (String name : map.keySet()) { caches.add(new CaffeineCache(name, (Cache<Object, Object>) map.get(name))); } simpleCacheManager.setCaches(caches); return simpleCacheManager; }- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
@Cacheable(cacheNames = {"search:req"}, key = "#searchParamVO", sync = true)- 1
以上通过重写springboot CacheLoader的load和reload方法,在使用spring cache注解时,缓存会通过改loader进行缓存逻辑的执行,配置caffeine软引用,在内存将要满时,gc之后回收缓存对象,来保证系统稳定,同时配置refreshAfterWrite参数为五秒,该参数的意义是,写入后五秒刷新缓存,且有用户请求命中该缓存key的情况下,就会触发reload方法,进行缓存更新,该刷新操作是异步的,并不会造成线程阻塞,刷新期间,其余请求拿到的是旧缓存。对于没有命中缓存的请求,会执行load方法写入缓存,此方法是同步的。
题外话:很多公司具有多级缓存基础架构建设,可以采用本地缓存无限缓存+redis定时缓存的机制实现。我也自行实现过,详见这篇文章:
最终,在不懈努力下,效果理想,单节点qps破千:
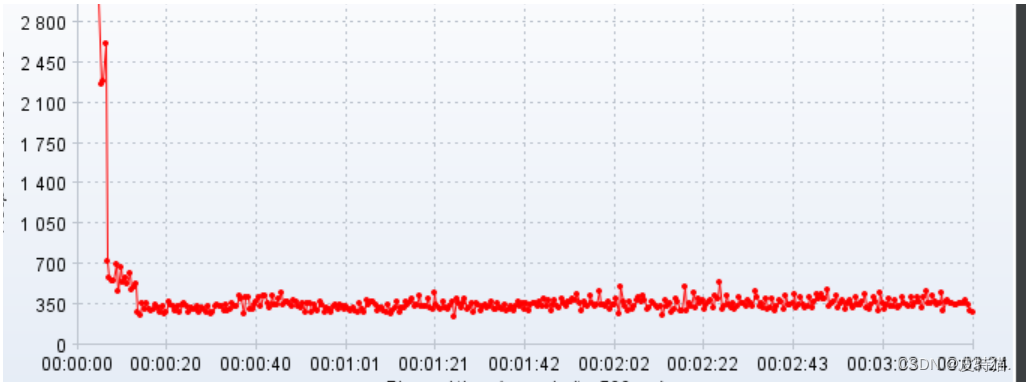

-
相关阅读:
葡聚糖-醛基,Dextran-CHO,aldehyde-葡聚糖|醛基,环氧化物,缬草酸,丙烯酰胺,溴化物,乙烯砜,甲基丙烯酸酯功能化葡聚糖
rtf是什么格式的文件?rtf格式和word的区别是什么?
图解来啦!机器学习工业部署最佳实践!10分钟上手机器学习部署与大规模扩展 ⛵
Android车载应用与手机版Android应用有何不同?
numpy和matlab的多维数组展平:ravel, flatten, reshape, (:)
node js环境与vue变量配置
mybatis-plus异常:dynamic-datasource can not find primary datasource
thonny的汉字编码是UTF-8,如何才能转为GB2312?
目录自动清洗
统一SQL 支持Oracle cast函数转换
- 原文地址:https://blog.csdn.net/qq_41214487/article/details/133134091