-
Llama2-Chinese项目:2.1-Atom-7B预训练
虽然Llama2的预训练数据相对于第一代LLaMA扩大了一倍,但是中文预训练数据的比例依然非常少,仅占0.13%,这也导致了原始Llama2的中文能力较弱。为了能够提升模型的中文能力,可以采用微调和预训练两种路径,其中:
- 微调需要的算力资源少,能够快速实现一个中文Llama的雏形。但缺点也显而易见,只能激发基座模型已有的中文能力,由于Llama2的中文训练数据本身较少,所以能够激发的能力也有限,治标不治本。
- 基于大规模中文语料进行预训练,成本高,不仅需要大规模高质量的中文数据,也需要大规模的算力资源。但是优点也显而易见,就是能从模型底层优化中文能力,真正达到治本的效果,从内核为大模型注入强大的中文能力。
下面从主要目标、训练数据、权重更新、数据转换和预处理、任务类型、示例应用和典型场景7个方面进行比较,如下所示(ChatGPT):
特征 Pretraining(预训练) Continuous Pretraining(继续预训练) Fine-tuning(微调) Post-Pretrain(预训练之后) 主要目标 学习通用的表示 在通用表示上继续学习 在特定任务上调整模型 在预训练之后的额外学习和任务 训练数据 大规模文本数据集 额外的文本数据集 特定任务的数据集 额外的优化、领域适应或任务迁移 权重更新 权重更新 继续更新模型参数 在任务数据上进行权重更新 针对特定需求进行权重更新 数据转换和预处理 通常包括数据标准化、掩码预测等 与预训练相似的预处理 根据任务需求进行调整 针对特定需求进行数据处理和优化 任务类型 无监督学习、自监督学习 通常是自监督学习 监督学习 可以包括优化、领域适应、任务迁移等多种任务 示例应用 BERT、GPT等 额外的预训练 文本分类、命名实体识别等 模型优化、领域适应、多任务学习等 典型场景 语言理解和生成 继续模型学习 特定文本任务 后续步骤和任务,用于定制和优化模型 说明:本文环境为Windows10,Python3.10,CUDA 11.8,GTX 3090(24G),内存24G。
一.模型预训练脚本
模型预训练脚本中的参数较多,只能在实践中来消化了。因为用的Windows10系统,所以运行shell脚本较麻烦,这部分不做过多介绍。如下所示:train/pretrain/pretrain.sh output_model=/mnt/data1/atomgpt # output_model:输出模型路径 if [ ! -d ${output_model} ];then # -d:判断是否为目录,如果不是目录则创建 mkdir ${output_model} # mkdir:创建目录 fi cp ./pretrain.sh ${output_model} # cp:复制文件pretrain.sh到output_model目录下 cp ./ds_config_zero*.json ${output_model} # cp:复制文件ds_config_zero*.json到output_model目录下 deepspeed --num_gpus 1 pretrain_clm.py \ # deepspeed:分布式训练,num_gpus:使用的gpu数量,pretrain_clm.py:训练脚本 --model_name_or_path L:/20230903_Llama2/Llama-2-7b-hf \ # model_name_or_path:模型名称或路径 --train_files ../../data/train_sft.csv \ # train_files:训练数据集路径 ../../data/train_sft_sharegpt.csv \ --validation_files ../../data/dev_sft.csv \ # validation_files:验证数据集路径 ../../data/dev_sft_sharegpt.csv \ --per_device_train_batch_size 10 \ # per_device_train_batch_size:每个设备的训练批次大小 --per_device_eval_batch_size 10 \ # per_device_eval_batch_size:每个设备的验证批次大小 --do_train \ # do_train:是否进行训练 --output_dir ${output_model} \ # output_dir:输出路径 --evaluation_strategy steps \ # evaluation_strategy:评估策略,steps:每隔多少步评估一次 --use_fast_tokenizer false \ # use_fast_tokenizer:是否使用快速分词器 --max_eval_samples 500 \ # max_eval_samples:最大评估样本数,500:每次评估500个样本 --learning_rate 3e-5 \ # learning_rate:学习率 --gradient_accumulation_steps 4 \ # gradient_accumulation_steps:梯度累积步数 --num_train_epochs 3 \ # num_train_epochs:训练轮数 --warmup_steps 10000 \ # warmup_steps:预热步数 --logging_dir ${output_model}/logs \ # logging_dir:日志路径 --logging_strategy steps \ # logging_strategy:日志策略,steps:每隔多少步记录一次日志 --logging_steps 2 \ # logging_steps:日志步数,2:每隔2步记录一次日志 --save_strategy steps \ # save_strategy:保存策略,steps:每隔多少步保存一次 --preprocessing_num_workers 10 \ # preprocessing_num_workers:预处理工作数 --save_steps 500 \ # save_steps:保存步数,500:每隔500步保存一次 --eval_steps 500 \ # eval_steps:评估步数,500:每隔500步评估一次 --save_total_limit 2000 \ # save_total_limit:保存总数,2000:最多保存2000个 --seed 42 \ # seed:随机种子 --disable_tqdm false \ # disable_tqdm:是否禁用tqdm --ddp_find_unused_parameters false \ # ddp_find_unused_parameters:是否找到未使用的参数 --block_size 4096 \ # block_size:块大小 --overwrite_output_dir \ # overwrite_output_dir:是否覆盖输出目录 --report_to tensorboard \ # report_to:报告给tensorboard --run_name ${output_model} \ # run_name:运行名称 --bf16 \ # bf16:是否使用bf16 --bf16_full_eval \ # bf16_full_eval:是否使用bf16进行完整评估 --gradient_checkpointing \ # gradient_checkpointing:是否使用梯度检查点 --deepspeed ./ds_config_zero3.json \ # deepspeed:分布式训练配置文件 --ignore_data_skip true \ # ignore_data_skip:是否忽略数据跳过 --ddp_timeout 18000000 \ # ddp_timeout:ddp超时时间,18000000:18000000毫秒 | tee -a ${output_model}/train.log # tee:将标准输出重定向到文件,-a:追加到文件末尾 # --resume_from_checkpoint ${output_model}/checkpoint-20400 \# resume_from_checkpoint:从检查点恢复训练- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
二.预训练实现代码
Llama中文社区供了Llama模型的预训练代码,以及中文语料(参考第六部分)。本文在meta发布的Llama-2-7b基础上进行预训练,pretrain_clm.py代码的中文注释参考[0],执行脚本如下所示:python pretrain_clm.py --output_dir ./output_model --model_name_or_path L:/20230903_Llama2/Llama-2-7b-hf --train_files ../../data/train_sft.csv ../../data/train_sft_sharegpt.csv --validation_files ../../data/dev_sft.csv ../../data/dev_sft_sharegpt.csv --do_train --overwrite_output_dir- 1
说明:使用GTX 3090 24G显卡,还是报了OOM错误,但是并不影响调试学习,输出日志参考[2]。
1.代码结构

(1)ModelArguments:模型参数类
(2)DataTrainingArguments:数据训练参数类
(3)TrainingArguments:训练参数类
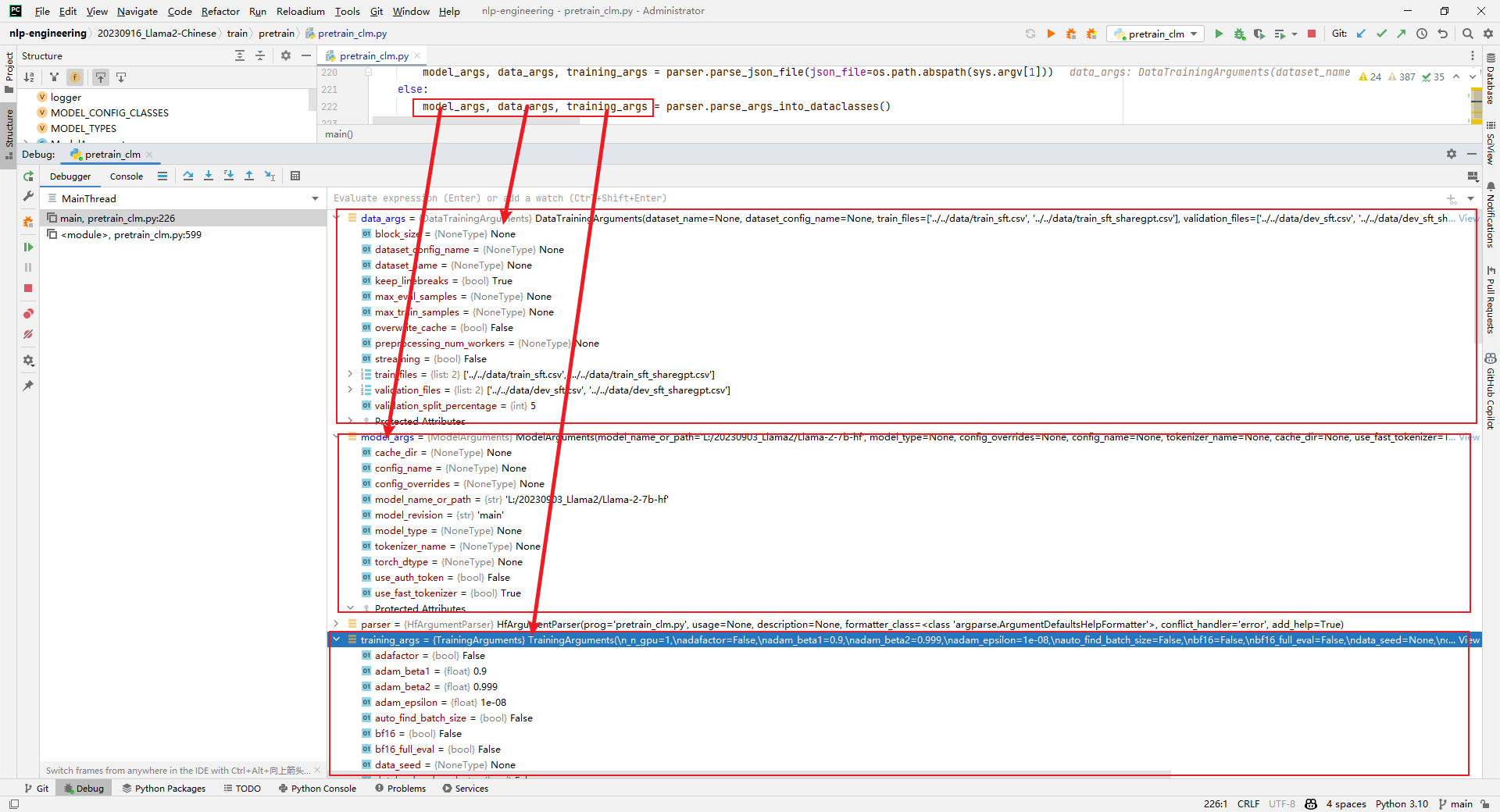
2.model_args, data_args, training_args = parser.parse_args_into_dataclasses()
解析:加载模型参数、数据训练参数和训练参数,如下所示:
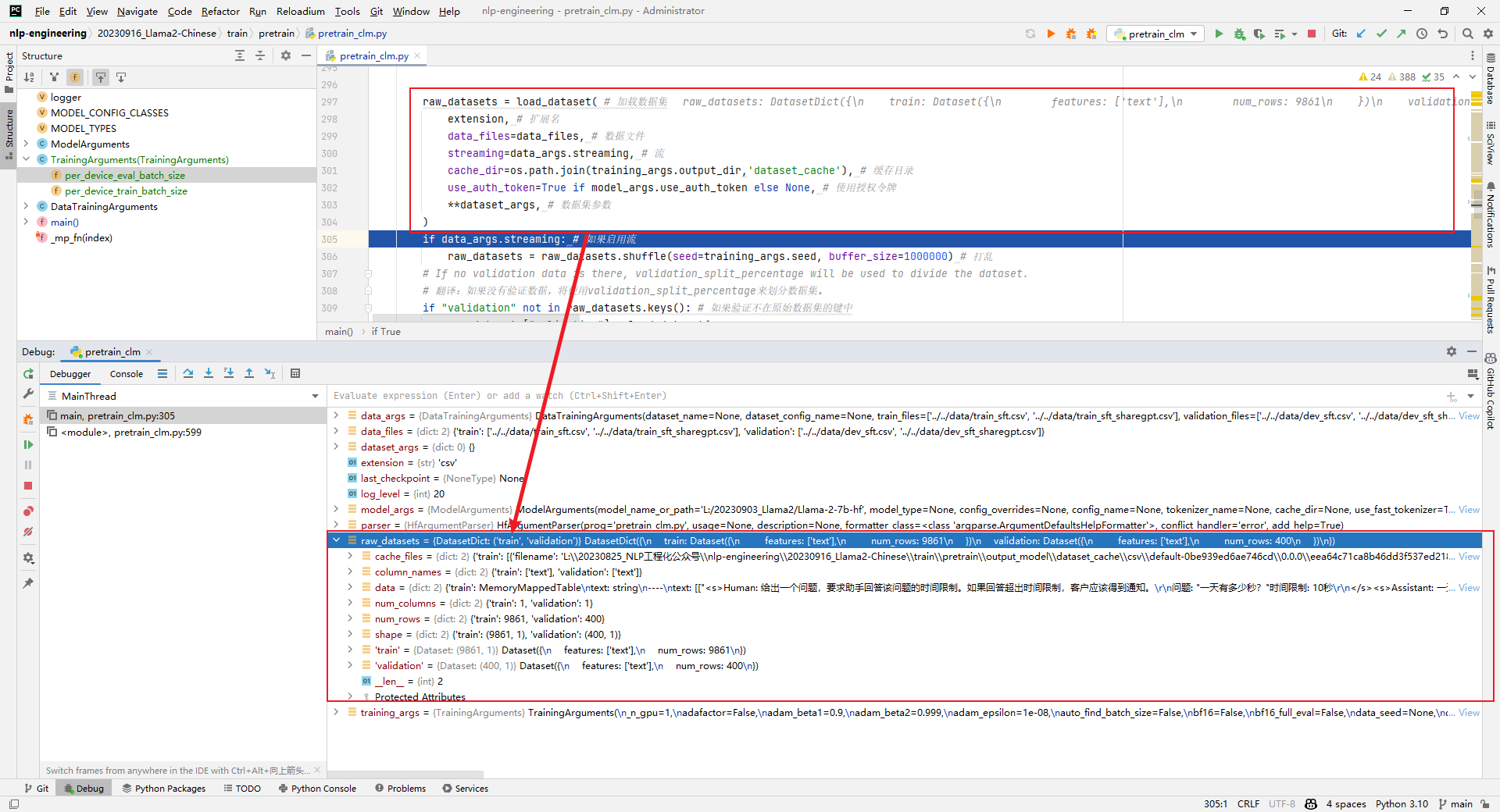
3.raw_datasets = load_dataset(...)
解析:加载原始数据集,如下所示:
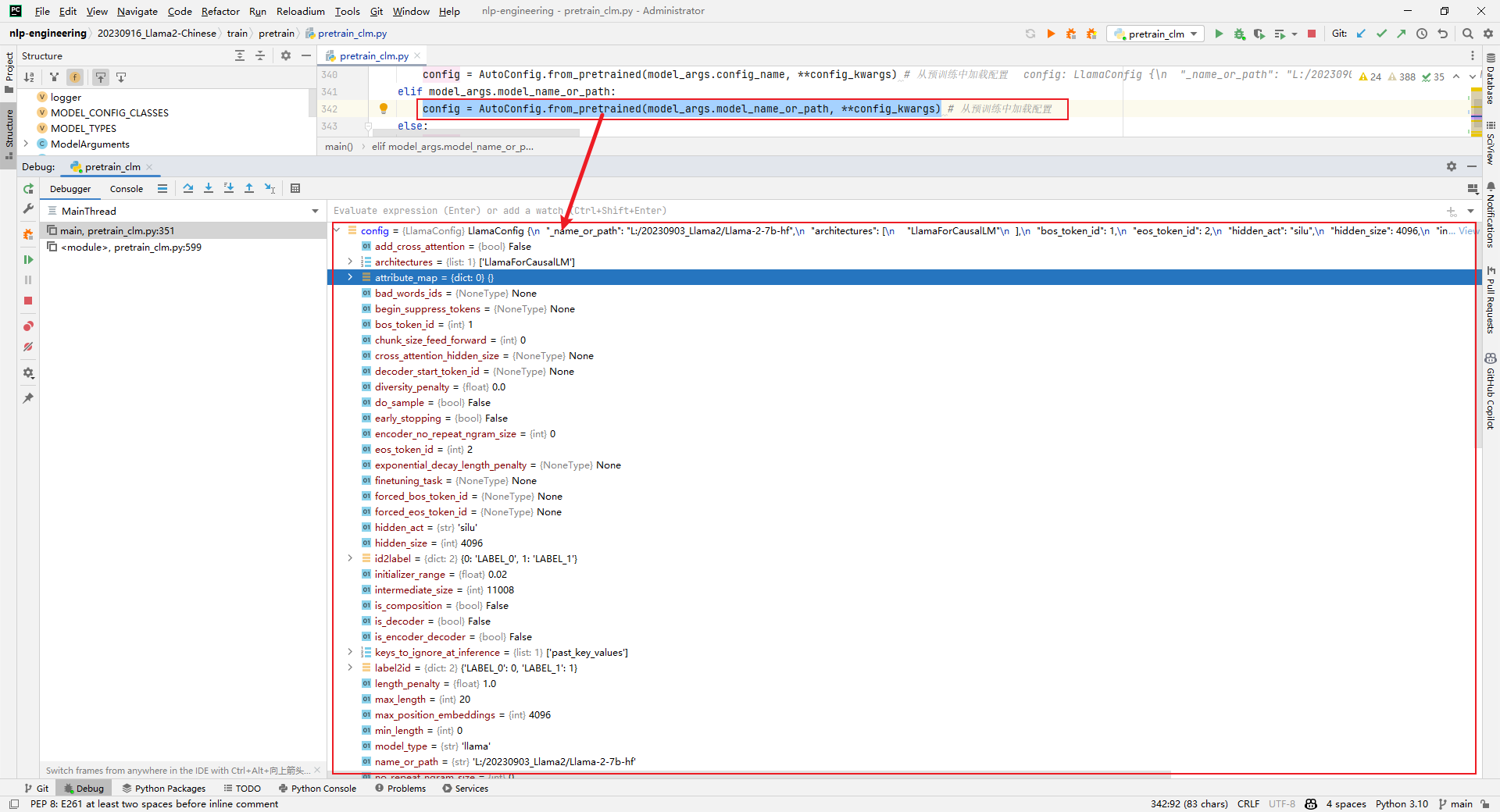
4.config = AutoConfig.from_pretrained(model_args.model_name_or_path, **config_kwargs)
解析:加载config,如下所示:
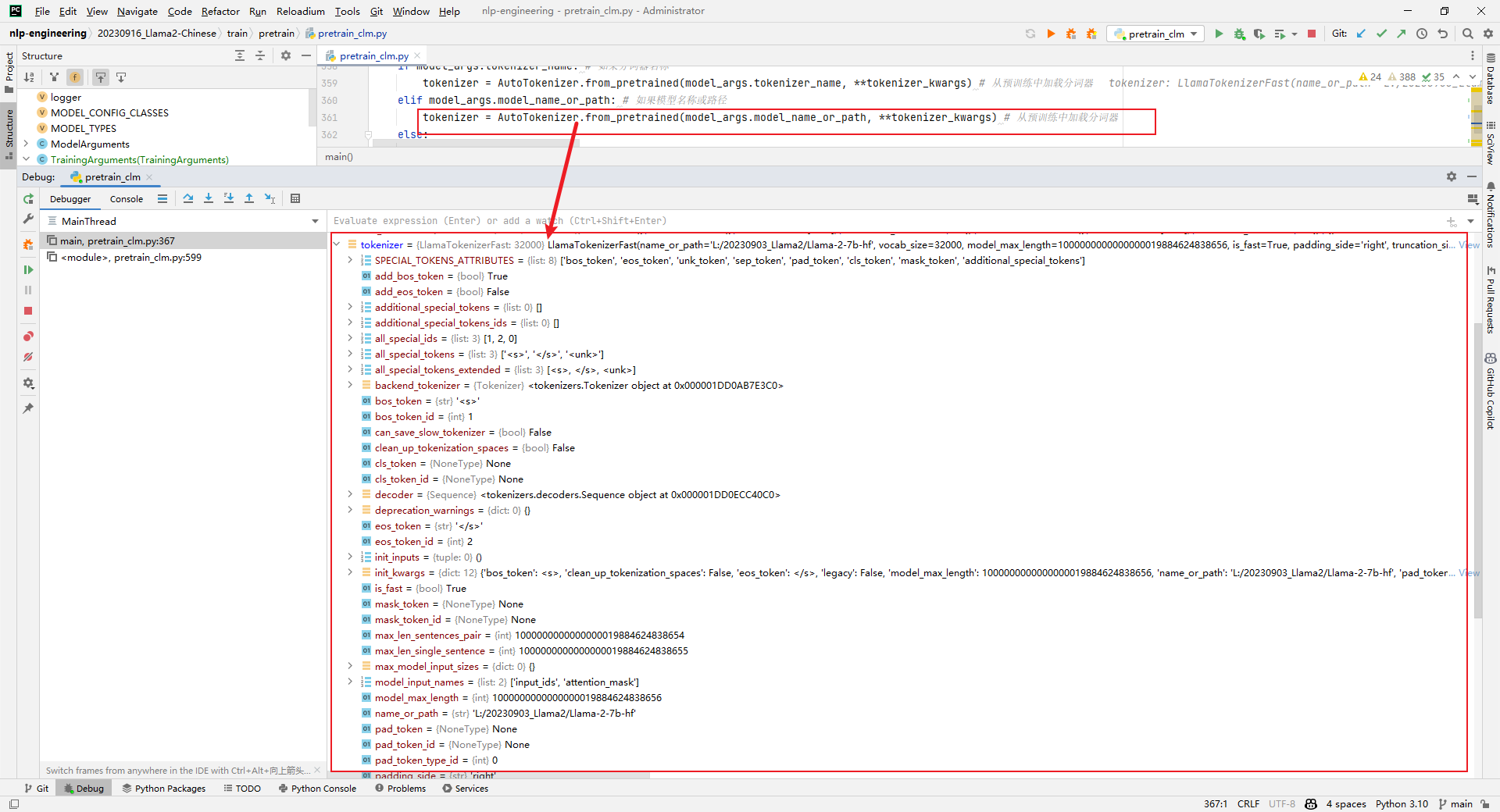
5.tokenizer = AutoTokenizer.from_pretrained(model_args.model_name_or_path, **tokenizer_kwargs)
解析:加载tokenizer,如下所示:
6.
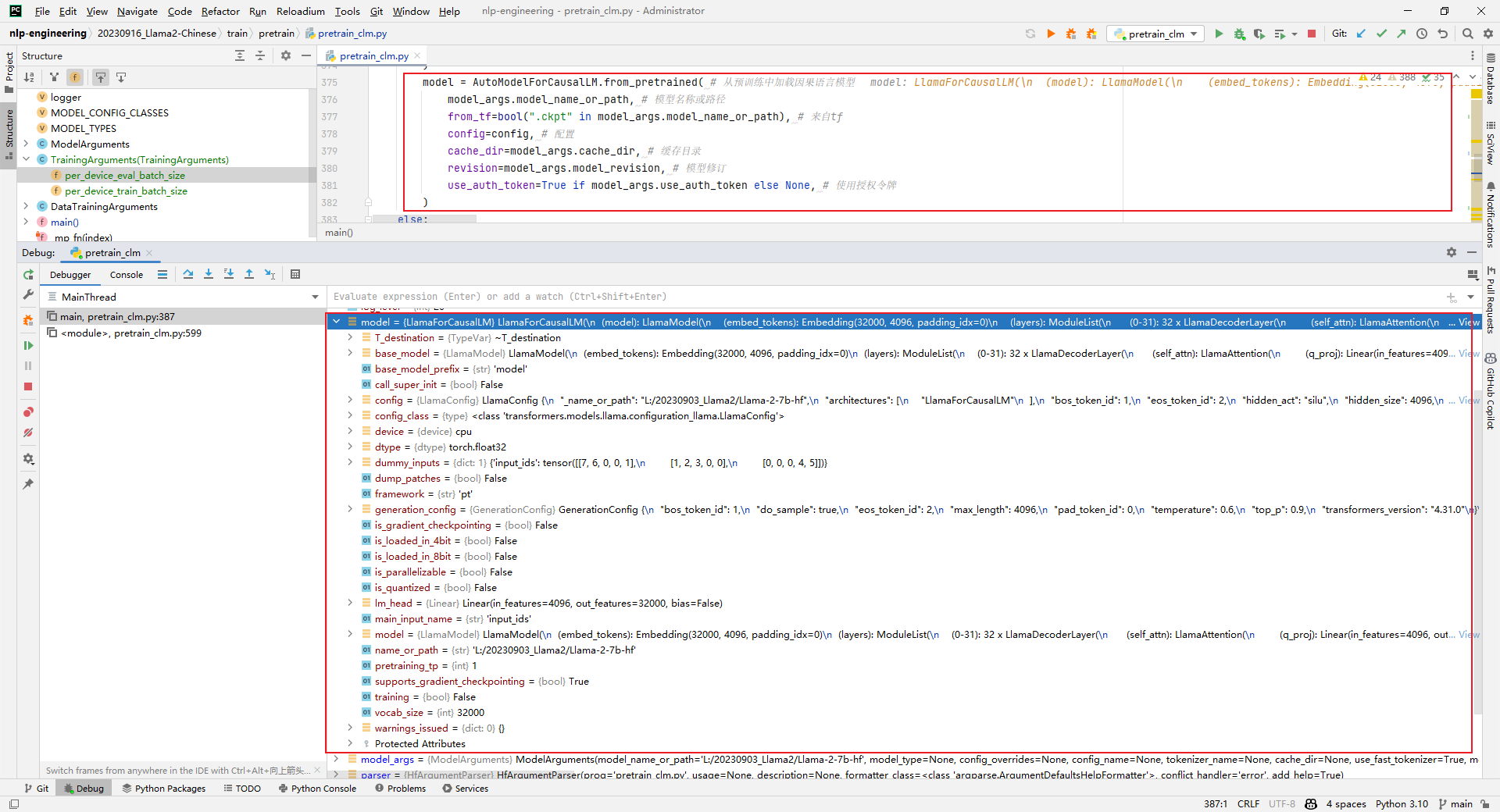
model = AutoModelForCausalLM.from_pretrained()
解析:加载model,这一步非常耗时,如下所示:
7.
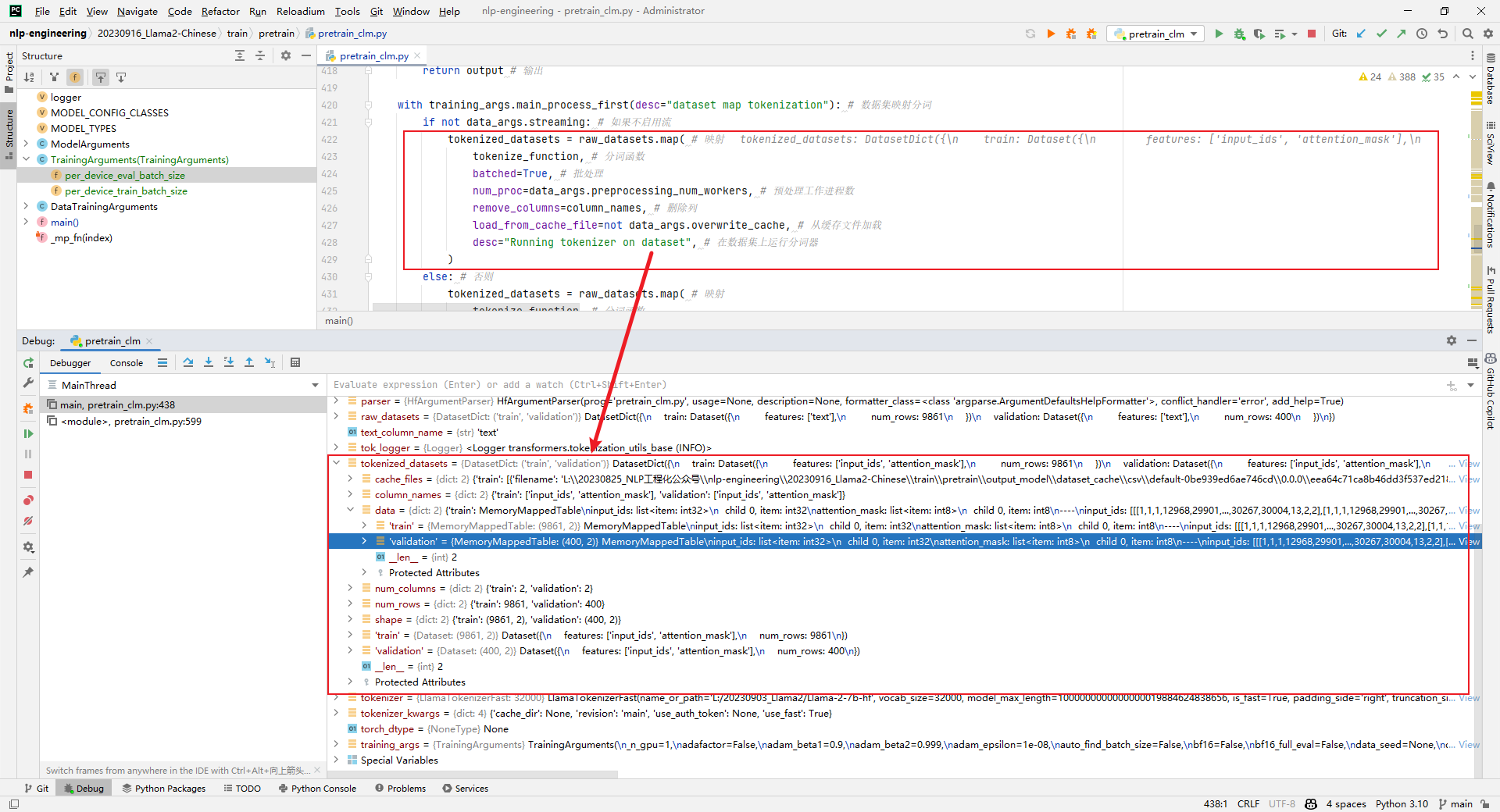
tokenized_datasets = raw_datasets.map()
解析:原始数据集处理,比如编码等,如下所示:
8.
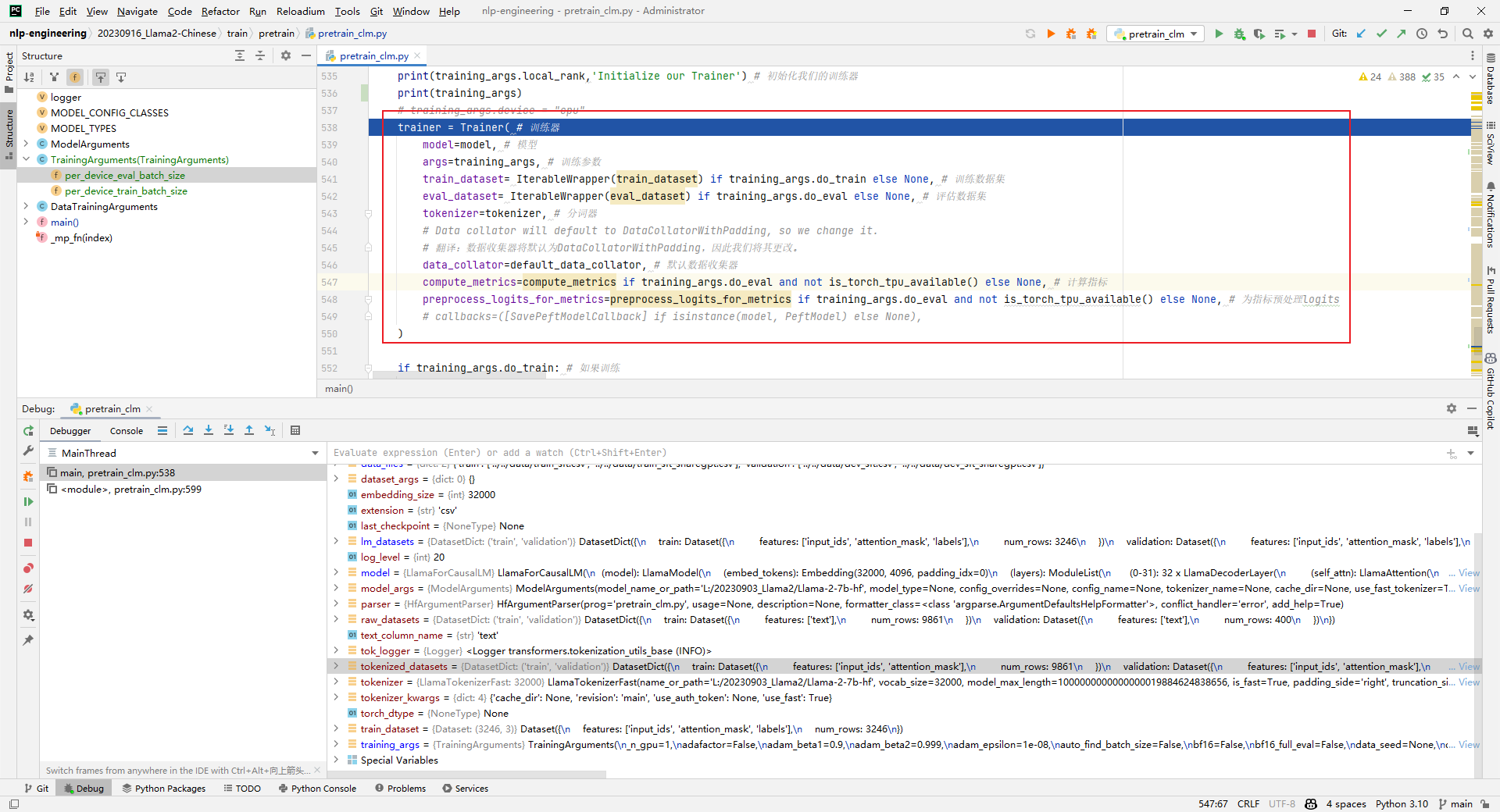
trainer = Trainer()
解析:实例化一个trainer,用于后续的训练或评估。跑到这一步的时候就报OOM了。如下所示:trainer = Trainer( # 训练器 model=model, # 模型 args=training_args, # 训练参数 train_dataset= IterableWrapper(train_dataset) if training_args.do_train else None, # 训练数据集 eval_dataset= IterableWrapper(eval_dataset) if training_args.do_eval else None, # 评估数据集 tokenizer=tokenizer, # 分词器 # Data collator will default to DataCollatorWithPadding, so we change it. # 翻译:数据收集器将默认为DataCollatorWithPadding,因此我们将其更改。 data_collator=default_data_collator, # 默认数据收集器 compute_metrics=compute_metrics if training_args.do_eval and not is_torch_tpu_available() else None, # 计算指标 preprocess_logits_for_metrics=preprocess_logits_for_metrics if training_args.do_eval and not is_torch_tpu_available() else None, # 为指标预处理logits # callbacks=([SavePeftModelCallback] if isinstance(model, PeftModel) else None), )- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
说过:阅读
pretrain_clm.py代码有几个疑问:中文词表是什么扩展的?上下文长度如何扩增?如何预训练text数据?后续再写文章分享。
三.DeepSpeed加速
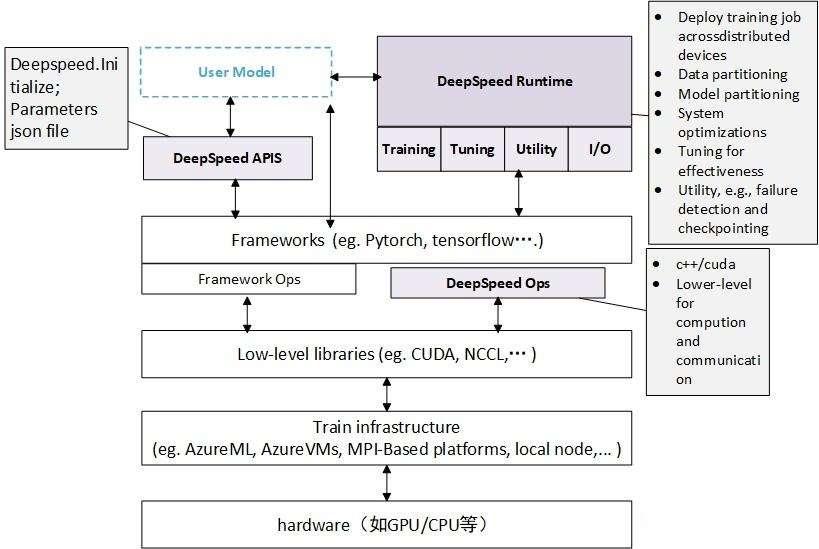
DeepSpeed是一个由微软开发的开源深度学习优化库,旨在提高大规模模型训练的效率和可扩展性。它通过多种技术手段来加速训练,包括模型并行化、梯度累积、动态精度缩放、本地模式混合精度等。DeepSpeed还提供了一些辅助工具,如分布式训练管理、内存优化和模型压缩等,以帮助开发者更好地管理和优化大规模深度学习训练任务。此外,deepspeed基于pytorch构建,只需要简单修改即可迁移。DeepSpeed已经在许多大规模深度学习项目中得到了应用,包括语言模型、图像分类、目标检测等等。
DeepSpeed主要包含三部分:- Apis:提供易用的api接口,训练模型、推理模型只需要简单调用几个接口即可。其中最重要的是initialize接口,用来初始化引擎,参数中配置训练参数及优化技术等。配置参数一般保存在config.json文件中。
- Runtime:运行时组件,是DeepSpeed管理、执行和性能优化的核心组件。比如部署训练任务到分布式设备、数据分区、模型分区、系统优化、微调、故障检测、checkpoints保存和加载等。该组件使用Python语言实现。
- Ops:用C++和CUDA实现底层内核,优化计算和通信,比如ultrafast transformer kernels、fuse LAN kernels、cusomary deals等。
1.Windows10安装DeepSpeed
解析:管理员启动cmd:build_win.bat python setup.py bdist_wheel- 1
- 2
2.安装编译工具
在Visual Studio Installer中勾选"使用C++的桌面开发",如下所示:

3.error C2665: torch::empty: 没有重载函数可以转换所有参数类型
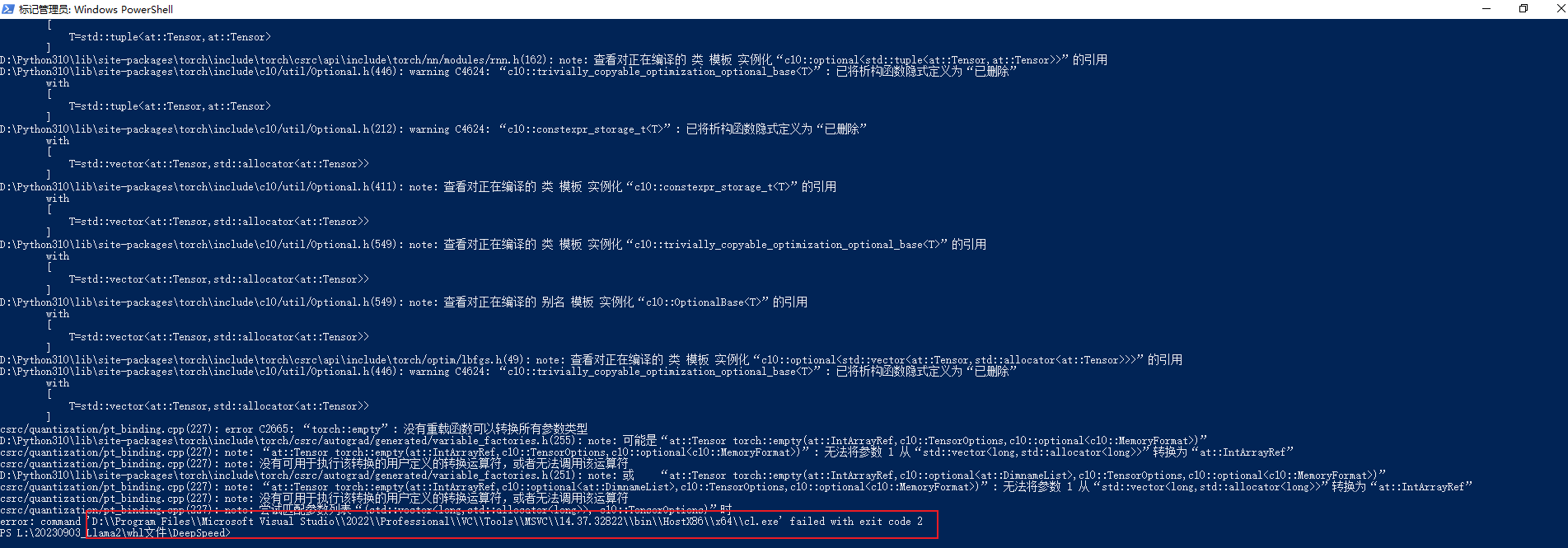
解决办法如下所示:

4.元素"1": 从"size_t"转换为"_Ty"需要收缩转换
解析:具体错误如下所示:csrc/transformer/inference/csrc/pt_binding.cpp(536): error C2398: 元素"1": 从"size_t"转换为"_Ty"需要收缩转换- 1
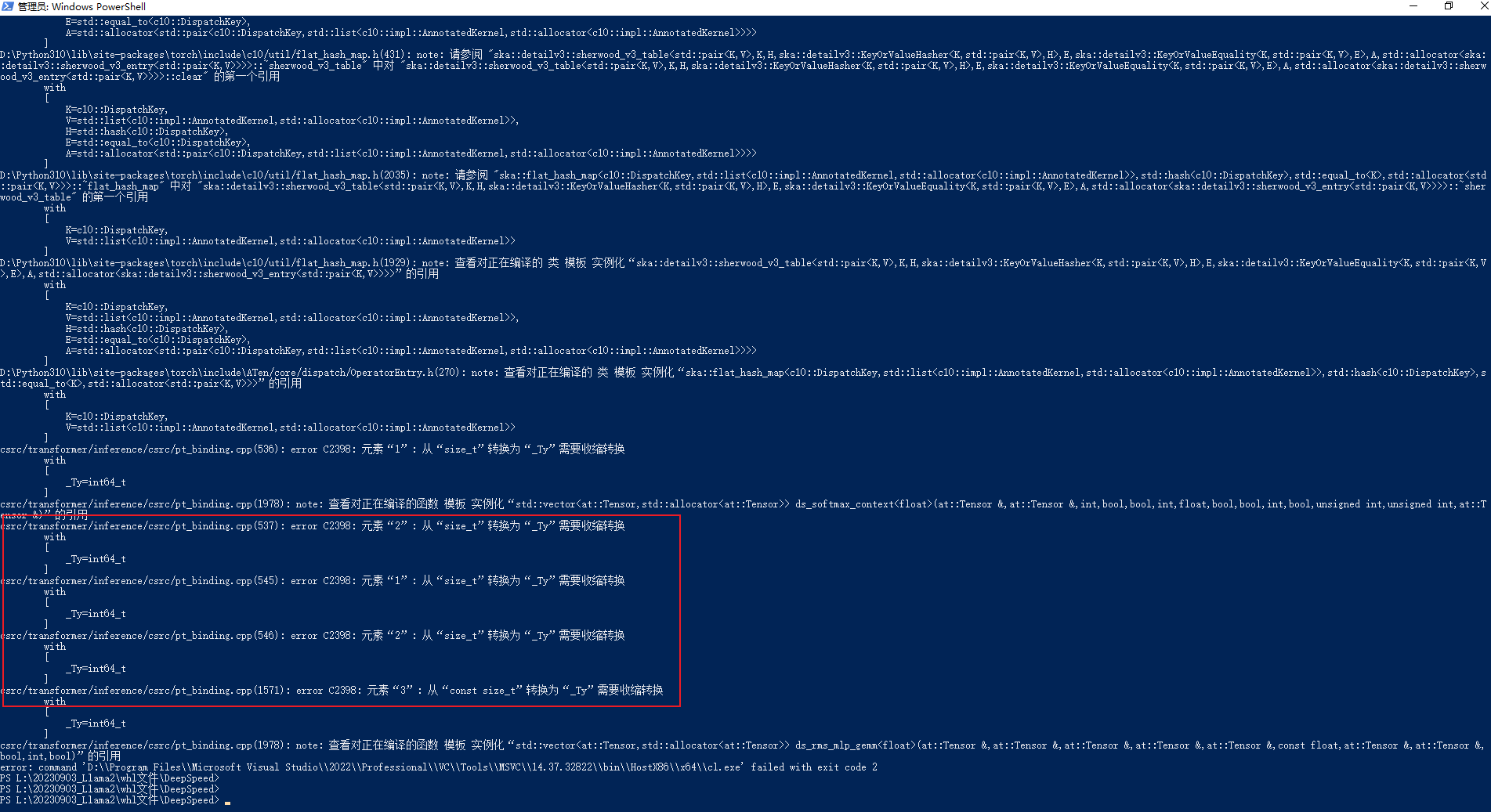
解析方案如下所示:536:hidden_dim * (unsigned)InferenceContext 537:k * (int)InferenceContext 545:hidden_dim * (unsigned)InferenceContext 546:k * (int)InferenceContext 1570: input.size(1), (int)mlp_1_out_neurons- 1
- 2
- 3
- 4
- 5
编译成功如下所示:

5.安装类库PS L:\20230903_Llama2\whl文件\DeepSpeed\dist> pip3 install .\deepspeed-0.10.4+180dd397-cp310-cp310-win_amd64.whl- 1
说明:由于DeepSpeed在Windows操作不友好,这部分只做学习使用。
6.单卡训练和多卡训练
(1)对于单卡训练,可以采用ZeRO-2的方式,参数配置见train/pretrain/ds_config_zero2.json{ "fp16": { // 混合精度训练 "enabled": "auto", // 是否开启混合精度训练 "loss_scale": 0, // 损失缩放 "loss_scale_window": 1000, // 损失缩放窗口 "initial_scale_power": 16, // 初始损失缩放幂 "hysteresis": 2, // 滞后 "min_loss_scale": 1 // 最小损失缩放 }, "optimizer": { // 优化器 "type": "AdamW", // 优化器类型 "params": { // 优化器参数 "lr": "auto", // 学习率 "betas": "auto", // 衰减因子 "eps": "auto", // 除零保护 "weight_decay": "auto" // 权重衰减 } }, "scheduler": { // 学习率调度器 "type": "WarmupDecayLR", // 调度器类型 "params": { // 调度器参数 "last_batch_iteration": -1, // 最后批次迭代 "total_num_steps": "auto", // 总步数 "warmup_min_lr": "auto", // 最小学习率 "warmup_max_lr": "auto", // 最大学习率 "warmup_num_steps": "auto" // 热身步数 } }, "zero_optimization": { // 零优化 "stage": 2, // 零优化阶段 "offload_optimizer": { // 优化器卸载 "device": "cpu", // 设备 "pin_memory": true // 锁页内存 }, "offload_param": { // 参数卸载 "device": "cpu", // 设备 "pin_memory": true // 锁页内存 }, "allgather_partitions": true, // 全收集分区 "allgather_bucket_size": 5e8, // 全收集桶大小 "overlap_comm": true, // 重叠通信 "reduce_scatter": true, // 减少散射 "reduce_bucket_size": 5e8, // 减少桶大小 "contiguous_gradients": true // 连续梯度 }, "activation_checkpointing": { // 激活检查点 "partition_activations": false, // 分区激活 "cpu_checkpointing": false, // CPU检查点 "contiguous_memory_optimization": false, // 连续内存优化 "number_checkpoints": null, // 检查点数量 "synchronize_checkpoint_boundary": false, // 同步检查点边界 "profile": false // 档案 }, "gradient_accumulation_steps": "auto", // 梯度累积步骤 "gradient_clipping": "auto", // 梯度裁剪 "steps_per_print": 2000, // 每次打印步骤 "train_batch_size": "auto", // 训练批次大小 "min_lr": 5e-7, // 最小学习率 "train_micro_batch_size_per_gpu": "auto", // 每个GPU的训练微批次大小 "wall_clock_breakdown": false // 墙上时钟分解 }- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 61
- 62
- 63
(2)对于多卡训练,可以采用ZeRO-3的方式,参数配置见train/pretrain/ds_config_zero3.json
{ "fp16": { // 混合精度训练 "enabled": "auto", // 是否开启混合精度训练 "loss_scale": 0, // 损失缩放 "loss_scale_window": 1000, // 损失缩放窗口 "initial_scale_power": 16, // 初始缩放幂 "hysteresis": 2, // 滞后 "min_loss_scale": 1, // 最小损失缩放 "fp16_opt_level": "O2" // 混合精度优化级别 }, "bf16": { // 混合精度训练 "enabled": "auto" // 是否开启混合精度训练 }, "optimizer": { // 优化器 "type": "AdamW", // 优化器类型 "params": { // 优化器参数 "lr": "auto", // 学习率 "betas": "auto", // 衰减因子 "eps": "auto", // 除零保护 "weight_decay": "auto" // 权重衰减 } }, "scheduler": { // 学习率调度器 "type": "WarmupDecayLR", // 学习率调度器类型 "params": { // 学习率调度器参数 "last_batch_iteration": -1, // 最后批次迭代 "total_num_steps": "auto", // 总步数 "warmup_min_lr": "auto", // 最小学习率 "warmup_max_lr": "auto", // 最大学习率 "warmup_num_steps": "auto" // 热身步数 } }, "zero_optimization": { // 零优化 "stage": 3, // 零优化阶段 "overlap_comm": true, // 重叠通信 "contiguous_gradients": true, // 连续梯度 "sub_group_size": 1e9, // 子组大小 "reduce_bucket_size": "auto", // 减少桶大小 "stage3_prefetch_bucket_size": "auto", // 阶段3预取桶大小 "stage3_param_persistence_threshold": "auto", // 阶段3参数持久性阈值 "stage3_max_live_parameters": 1e9, // 阶段3最大活动参数 "stage3_max_reuse_distance": 1e9, // 阶段3最大重用距离 "gather_16bit_weights_on_model_save": true // 在模型保存时收集16位权重 }, "gradient_accumulation_steps": "auto", // 梯度累积步数 "gradient_clipping": "auto", // 梯度裁剪 "steps_per_print": 2000, // 每次打印步数 "train_batch_size": "auto", // 训练批次大小 "train_micro_batch_size_per_gpu": "auto", // 训练每个GPU的微批次大小 "wall_clock_breakdown": false // 墙上时钟分解 }- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
ZeRO-2和ZeRO-3间的比较如下所示(ChatGPT):
特征 Zero2(0.2版本) Zero3(0.3版本) 内存占用优化 是 是 动态计算图支持 不支持 支持 性能优化 一般 更好 模型配置选项 有限 更多 分布式训练支持 是 是 具体应用 非动态计算图模型 动态计算图模型
四.训练效果度量指标
accuracy.py代码的中文注释参考[1],主要在预训练评估的时候用到了该文件,如下所示:train/pretrain/accuracy.py metric = evaluate.load("accuracy.py") # 加载指标- 1
- 2
五.中文测试语料
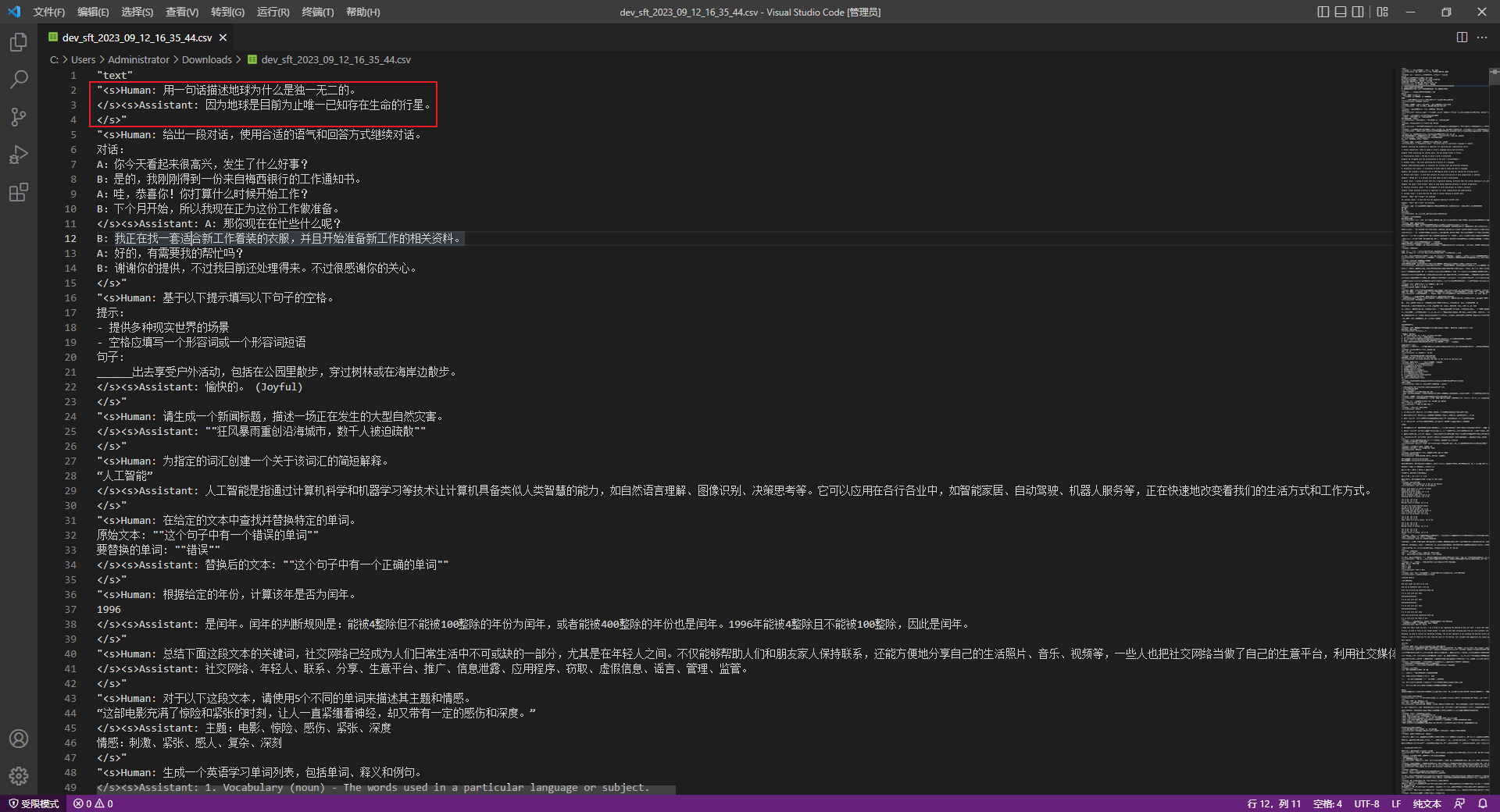
中文测试语料数据格式如下所示:Human: 问题Assistant: 答案- 1
多轮语料将单轮的拼接在一起即可,如下所示:
Human: 内容1\nAssistant: 内容2\nHuman: 内容3\nAssistant: 内容4\n- 1
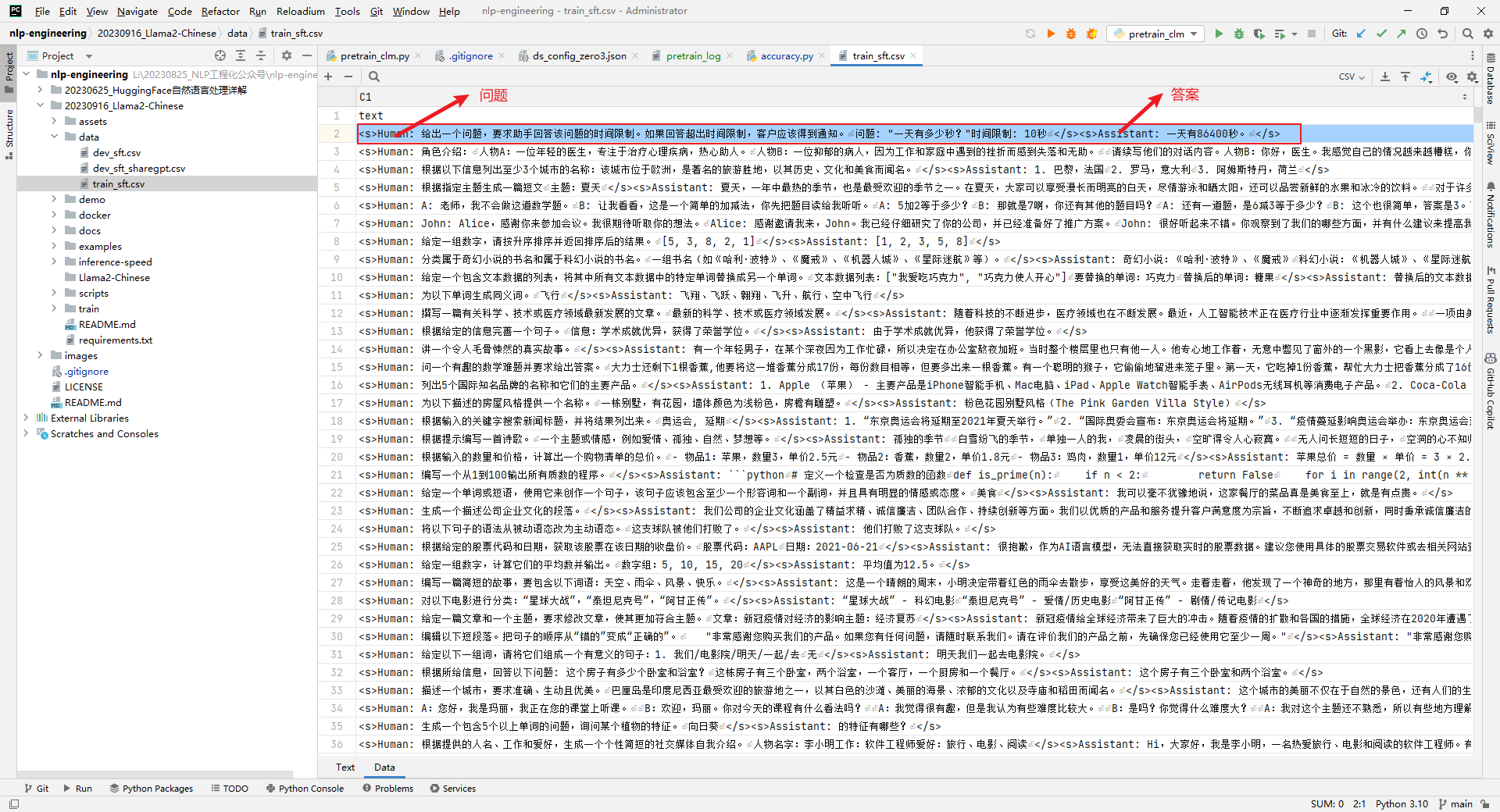
Llama2-Chinese项目中提供的train和dev文件共有3个,如下所示:data\dev_sft.csv data\dev_sft_sharegpt.csv data\train_sft.csv- 1
- 2
- 3
更多的语料可从Llama中文社区(https://llama.family/)链接下载:
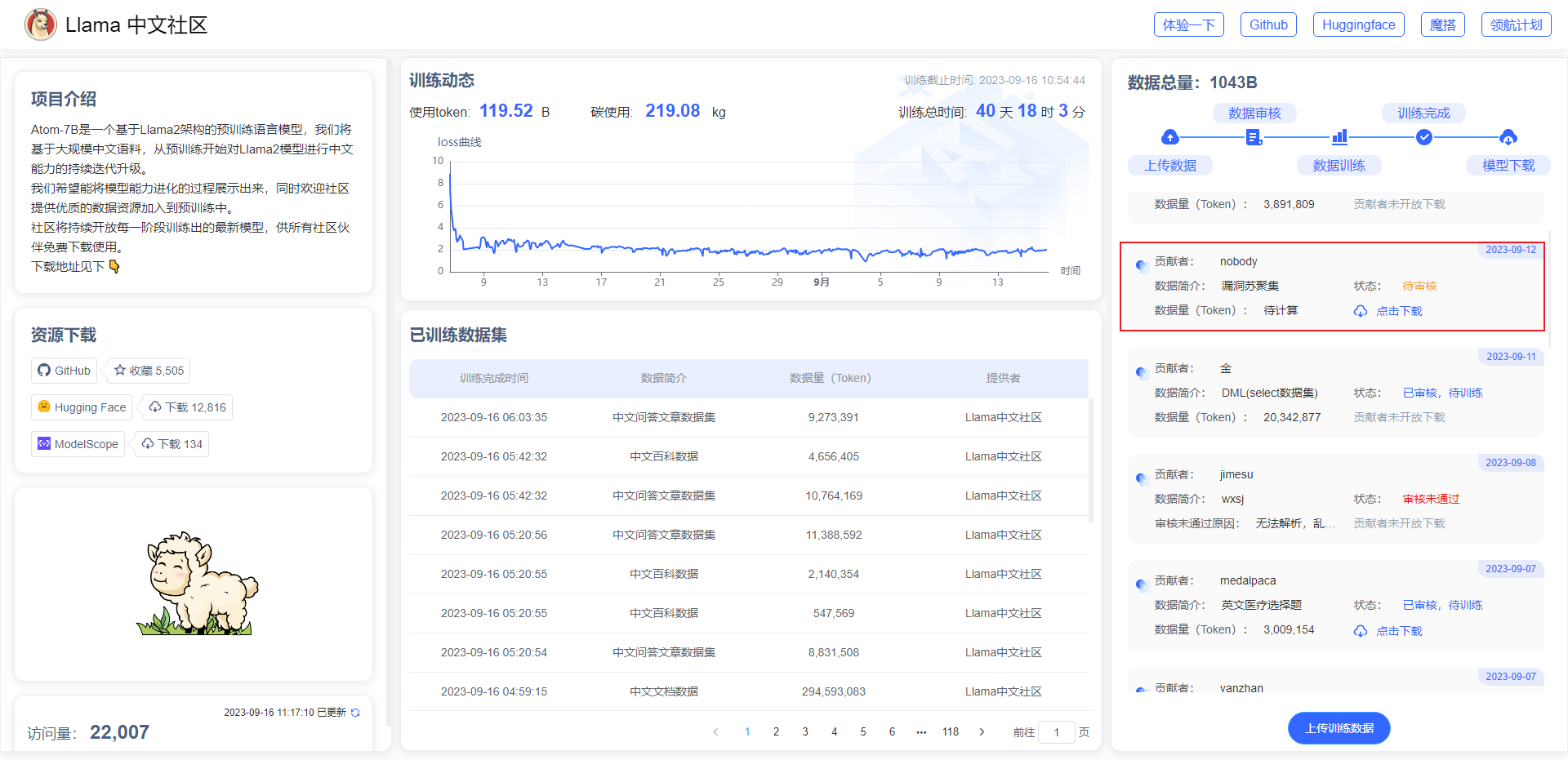
六.中文语料
Atom-7B是一个基于Llama2架构的预训练语言模型,Llama中文社区将基于大规模中文语料,从预训练开始对Llama2模型进行中文能力的持续迭代升级。通过以下数据来优化Llama2的中文能力:类型 描述 网络数据 互联网上公开的网络数据,挑选出去重后的高质量中文数据,涉及到百科、书籍、博客、新闻、公告、小说等高质量长文本数据。 Wikipedia 中文Wikipedia的数据 悟道 中文悟道开源的200G数据 Clue Clue开放的中文预训练数据,进行清洗后的高质量中文长文本数据 竞赛数据集 近年来中文自然语言处理多任务竞赛数据集,约150个 MNBVC MNBVC 中清洗出来的部分数据集 说明:除了网络数据和竞赛数据集这2个没有提供链接,其它的4个都提供了数据集的链接。
参考文献:
[0]https://github.com/ai408/nlp-engineering/blob/main/20230916_Llama2-Chinese/train/pretrain/pretrain_clm.py
[1]https://github.com/ai408/nlp-engineering/blob/main/20230916_Llama2-Chinese/train/pretrain/accuracy.py
[2]https://github.com/ai408/nlp-engineering/blob/main/20230916_Llama2-Chinese/train/pretrain/pretrain_log/pretrain_log
[3]https://huggingface.co/meta-llama/Llama-2-7b-hf/tree/main
[4]https://huggingface.co/spaces/ysharma/Explore_llamav2_with_TGI
[5]https://huggingface.co/meta-llama/Llama-2-70b-chat-hf
[6]https://huggingface.co/blog/llama2
[7]https://developer.nvidia.com/rdp/cudnn-download
[8]https://github.com/jllllll/bitsandbytes-windows-webui
[9]https://github.com/langchain-ai/langchain
[10]https://github.com/AtomEcho/AtomBulb
[11]https://github.com/huggingface/peft
[12]全参数微调时,报没有target_modules变量:https://github.com/FlagAlpha/Llama2-Chinese/issues/169
[13]https://huggingface.co/FlagAlpha
[14]Win10安装DeepSpeed:https://zhuanlan.zhihu.com/p/636450918 -
相关阅读:
[安卓java毕业设计源码]精品基于Uniapp+SSM实现的记账app[包运行成功]
小样本相关论文复现—2-全局印象
P2622 关灯问题II(状态压缩 搜索)
MySQL数据库备份全攻略:从基础到高级,一文掌握所有备份技巧
springboot集成Elasticsearch7.16,使用https方式连接并忽略SSL证书
c# .net+香橙派orangepi 200块多打造自家 浇花助手 系统
Python 如何使用装饰器(decorators)
沃通签名验签服务器:保护关键业务信息真实可信
远程桌面控制组件封装使用的microsoft terminal services active 1.0
SLAM用到的矩阵论知识
- 原文地址:https://blog.csdn.net/shengshengwang/article/details/132926802
