-
爬虫 — 字体反爬
一、安装字体软件 FontCreator
点击下载字体软件 FontCreator 安装包
1、同意协议,点击 Next;
2、更改存放位置,点击 Next;

3、点击 Next;
4、点击 Next;

5、点击 Inatall;

6、点击 Finish,完成安装;

7、打开软件,点击 Use Evaluation Version;

8、点击 Close,开始使用。

二、百度智能云文字识别
1、点击以下链接进入百度智能云文字识别;
2、登录账号,没有账号可以先注册;

3、选择”产品“ > ”文字识别“ > ”通用文字识别“;

4、点击”立即使用“;

5、点击”公有云服务“ > ”应用列表“ > ”创建应用“;

6、输入应用名称;

7、选择”应用归属“,填写”应用描述“,点击”立即创建“;

8、点击”返回应用列表“;

9、点击”概览“,点击”领取免费资源“;

10、点击“全部”,点击“0元领取”;
11、点击“技术文档”;

12、选择“API文档”,选择“通用场景文字识别”,选择“通用文字识别(标准版)”,选中“Python”;

# encoding:utf-8 import requests import base64 ''' 通用文字识别 ''' request_url = "https://aip.baidubce.com/rest/2.0/ocr/v1/general_basic" # 二进制方式打开图片文件 f = open('[本地文件]', 'rb') img = base64.b64encode(f.read()) params = {"image":img} access_token = '[调用鉴权接口获取的token]' request_url = request_url + "?access_token=" + access_token headers = {'content-type': 'application/x-www-form-urlencoded'} response = requests.post(request_url, data=params, headers=headers) if response: print (response.json())- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
13、需要获取 token 值,向上滑动,找到“Access Token获取”,点击;

14、复制代码;

import requests import json def main(): url = "https://aip.baidubce.com/oauth/2.0/token?grant_type=client_credentials&client_id=xxxxxx&client_secret=xxxxx" payload = "" headers = { 'Content-Type': 'application/json', 'Accept': 'application/json' } response = requests.request("POST", url, headers=headers, data=payload) print(response.text) if __name__ == '__main__': main()- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
15、在“应用列表”中找到“API Key”和“Secret Key”值;
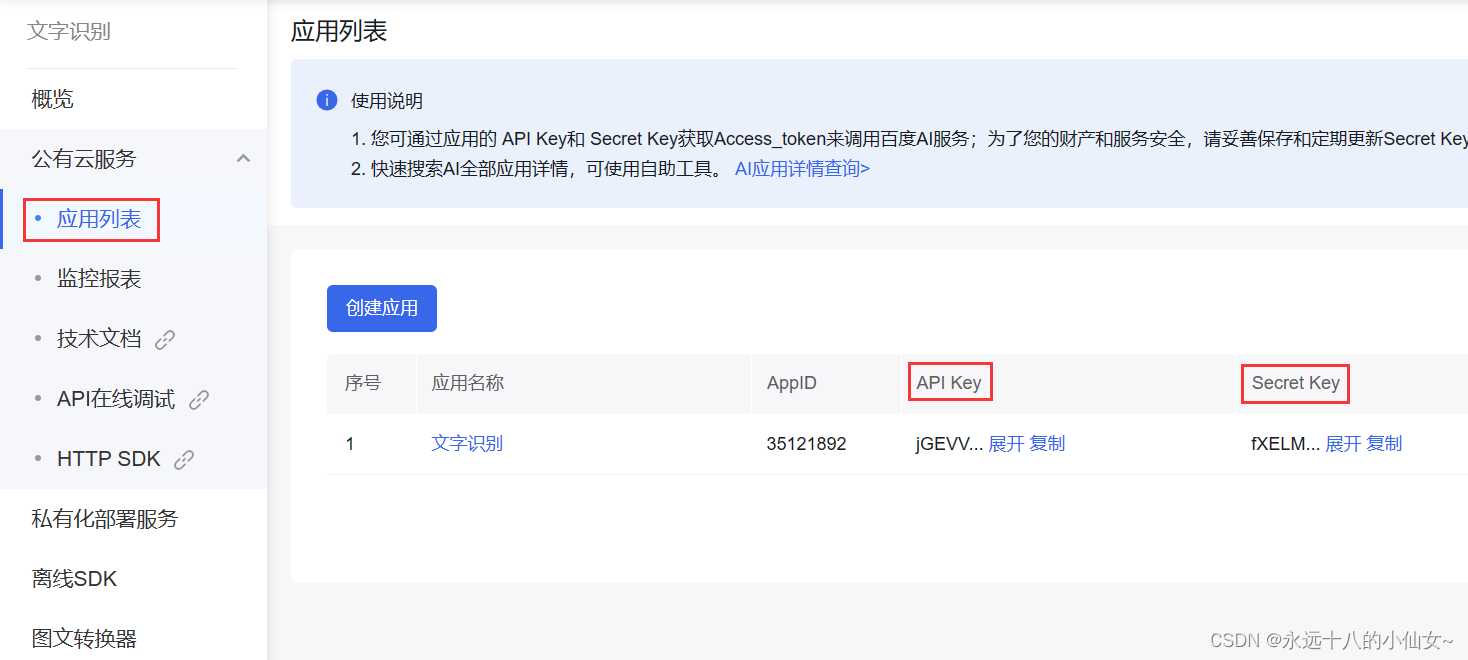
16、将两个值复制到上面代码中的“xxxxxx”位置;
import requests import json def main(): # client_id:API Key # client_secret:Secret Key url = "https://aip.baidubce.com/oauth/2.0/token?grant_type=client_credentials&client_id=替换API Key&client_secret=替换Secret Key" payload = "" headers = { 'Content-Type': 'application/json', 'Accept': 'application/json' } response = requests.request("POST", url, headers=headers, data=payload) # print(response.text) # 返回的数据格式是字符串 access_token = response.json()['access_token'] return access_token if __name__ == '__main__': main()- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
17、将“ token 值”文件引入到“通用文字识别”文件中
# encoding:utf-8 import requests import base64 from get_token import main # 引入 main 函数 ''' 通用文字识别 ''' request_url = "https://aip.baidubce.com/rest/2.0/ocr/v1/general_basic" # 二进制方式打开图片文件 f = open('文字.png', 'rb') img = base64.b64encode(f.read()) params = {"image":img} access_token = main() # 获取 token 值 request_url = request_url + "?access_token=" + access_token headers = {'content-type': 'application/x-www-form-urlencoded'} response = requests.post(request_url, data=params, headers=headers) # if response: # print (response.json()) lst = response.json()['words_result'] words_lst = [] # 存放识别出的字体 for l in lst: # print(l['words']) words_lst += list(l['words']) print(words_lst)- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
三、案例一
目标网站:https://fanqienovel.com/reader/7081837085425926656?enter_from=reader
需求:爬取当页的小说内容
页面分析
1、静态加载
import requests # 导入 requests 库,用于发送 HTTP 请求和处理 HTTP 响应 from lxml import etree # 导入 lxml 库中的 etree 模块,用于解析 HTML 文档 # 目标 url url = 'https://fanqienovel.com/reader/7081837085425926656?enter_from=reader' # 请求头信息,模拟浏览器发送请求 head = { 'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/116.0.0.0 Safari/537.36' } # 发送 get 请求,获取目标网页的响应对象 res = requests.get(url, headers=head) # 打印响应内容 print(res.text) # 使用 lxml 库中的 etree 模块解析 HTML 响应内容 html = etree.HTML(res.text) # 使用 XPath 定位到目标元素,并提取其中的文本内容 contents = html.xpath('//div[@class="muye-reader-content noselect"]//text()') # 打印提取的内容 print(contents)- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
获取到的数据文字,有正常的,有编码的,要考虑字体加密。
2、分析字体文件
先确定加密的字体。

再找到加密字体的链接,下载下来。

下载后用字体软件打开。
通过百度智能云文字识别时,可隐藏 name。

3、Python 操作字体文件
# pip install fontTools 安装 fontTools 库,用于处理字体文件 # pip install Brotli 用于解码 WOFF2 字体文件 from fontTools.ttLib import TTFont # 导入 fontTools 库中的 TTFont 模块,用于处理 TrueType 字体文件 # 加载字体文件 fq = TTFont('dc027189e0ba4cd.woff2') # 借助 xml 格式,查看字体之间的映射关系 fq.saveXML('fq.xml')- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
4、查找文字对应规律
软件当中“的”:name——gid58611,code-points——$E4F3
网页源码“的”:\ue4f3
xml 文件 “的”:
new_dic={“gid58670”: ‘0’ , ‘gid58611’: ‘的’}
dic={‘4f3’:’ gid58611’}
遍历 dic 这个字典,依次得到数据
for key,value in dic.items():——4f3, value
new_dic[value]——的
再获取 new_dic 里的文字
replace(‘4f3’ , 的)
import requests # 导入 requests 库,用于发送 HTTP 请求和处理 HTTP 响应 from lxml import etree # 导入 lxml 库中的 etree 模块,用于解析 HTML 文档 from fontTools.ttLib import TTFont # 导入 fontTools 库中的 TTFont 模块,用于处理 TrueType 字体文件 # 目标 url url = 'https://fanqienovel.com/reader/7081837085425926656?enter_from=reader' # 请求头信息,模拟浏览器发送请求 head = { 'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/116.0.0.0 Safari/537.36' } # 发送 get 请求,获取目标网页的响应对象 res = requests.get(url, headers=head) # 打印响应内容 # print(res.text) # 使用 lxml 库中的 etree 模块解析 HTML 响应内容 html = etree.HTML(res.text) # 使用 XPath 定位到目标元素,并提取其中的文本内容 contents = html.xpath('//div[@class="muye-reader-content noselect"]//text()') # 打印提取的内容 # print(contents) # 加载字体文件 fq = TTFont('dc027189e0ba4cd.woff2') # 借助 xml 格式,查看字体之间的映射关系 fq.saveXML('fq.xml') # 获取 fq 对象的最佳字符映射表 name = fq.getBestCmap() # 返回的是字典格式,数据显示不一样。得到的 key 显示的是10进制,需要转换成16进制 # print(name) # 创建一个空字典用于存储转换后的字符映射表 dic = {} # 遍历原字符映射表的键值对 for k, v in name.items(): # 将键转换为十六进制表示形式 k = hex(k) # 去除十六进制表示中的前缀"0x" new_key = str(k)[3:] # 将转换后的键值对存储到字典中 dic[new_key] = v # 打印转换后的字符映射表 # print(dic) # 通过百度智能云文字识别,将所有文字识别出来后,组合成列表 lst = [ '0', '1', '2', '3', '4', '5', '6', '7', '8', '9', 'a', 'b', 'c', 'd', 'e', 'f', 'g', 'h', 'i', 'j', 'k', 'l', 'm', 'n', 'o', 'p', 'q', 'r', 's', 't', 'u', 'v', 'w', 'x', 'y', 'z', 'A', 'B', 'C', 'D', 'E', 'F', 'G', 'H', 'I', 'J', 'K', 'L', 'M', 'N', 'O', 'P', 'Q', 'R', 'S', 'T', 'U', 'V', 'W', 'X', 'Y', 'Z', '的', '一', '是', '了', '我', '不', '人', '在', '他', '有', '这', '个', '上', '们', '来', '到', '时', '大', '地', '为', '子', '中', '你', '说', '生', '国', '年', '着', '就', '那', '和', '要', '她', '出', '也', '得', '里', '后', '自', '以', '会', '家', '可', '下', '而', '过', '天', '去', '能', '对', '小', '多', '然', '于', '心', '学', '么', '之', '都', '好', '看', '起', '发', '当', '没', '成', '只', '如', '事', '把', '还', '用', '第', '样', '道', '想', '作', '种', '开', '美', '总', '从', '无', '情', '已', '面', '最', '女', '但', '现', '前', '些', '所', '同', '日', '手', '又', '行', '意', '动', '方', '期', '它', '头', '经', '长', '儿', '回', '位', '分', '爱', '老', '因', '很', '给', '名', '法', '间', '斯', '知', '世', '什', '两', '次', '使', '身', '者', '被', '高', '已', '亲', '其', '进', '此', '话', '常', '与', '活', '正', '感', '见', '明', '问', '力', '理', '尔', '点', '文', '几', '定', '本', '公', '特', '做', '外', '孩', '相', '西', '果', '走', '将', '月', '十', '实', '向', '声', '车', '全', '信', '重', '三', '机', '工', '物', '气', '每', '并', '别', '真', '打', '太', '新', '比', '才', '便', '夫', '再', '书', '部', '水', '像', '眼', '等', '体', '却', '加', '电', '主', '界', '门', '利', '海', '受', '听', '表', '德', '少', '克', '代', '员', '许', '陵', '先', '口', '由', '死', '安', '写', '性', '马', '光', '白', '或', '住', '难', '望', '教', '命', '花', '结', '乐', '色', '更', '拉', '东', '神', '记', '处', '让', '母', '父', '应', '直', '字', '场', '平', '报', '友', '关', '放', '至', '张', '认', '接', '告', '入', '笑', '内', '英', '军', '候', '民', '岁', '往', '何', '度', '山', '觉', '路', '带', '万', '男', '边', '风', '解', '叫', '任', '金', '快', '原', '吃', '妈', '变', '通', '师', '立', '象', '数', '四', '失', '满', '战', '远', '格', '士', '音', '轻', '目', '条', '呢' ] # 获取字体文件中的字形顺序,去除第一个列表里面的空值 order = fq.getGlyphOrder()[1:] # 打印字形顺序 # print(order) # 使用字形顺序和给定列表 lst 创建一个新的字典 new_dic = dict(zip(order, lst)) # 打印新的字典 # print(new_dic) # 在替换之前,将列表里面的数据转成字符串类型的数据 content_str = str(contents) # 遍历字典 dic 的键值对 for k, v in dic.items(): # 根据字典 value 的值在新字典 new_dic 中获取对应的字体值 value = new_dic[v] # 打印键和对应的 value # print(k, value) # 将加密文字替换成对应文字 content_str = content_str.replace(k, value) # 去除数据中所有的 \ue content_str1 = content_str.replace(r'\ue', '') # 打印最终处理后的字符串 print(content_str1)- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 61
- 62
- 63
- 64
- 65
- 66
- 67
- 68
- 69
- 70
- 71
- 72
- 73
- 74
- 75
- 76
- 77
- 78
- 79
- 80
- 81
- 82
- 83
- 84
- 85
- 86
- 87
- 88
- 89
- 90
- 91
- 92
- 93
- 94
- 95
- 96
- 97
- 98
- 99
- 100
- 101
四、案例二
目标网站:http://shanzhi.spbeen.com/
需求:爬取当页数据职位-人数-薪资
代码实现
import requests # 导入 requests 库,用于发送 HTTP 请求和处理 HTTP 响应 from lxml import etree # 导入 lxml 库中的 etree 模块,用于解析 HTML 文档 from fontTools.ttLib import TTFont # 导入 fontTools 库中的 TTFont 模块,用于处理 TrueType 字体文件 # 目标 url url = 'http://shanzhi.spbeen.com/' # 发送 get 请求,获取目标网页的响应对象 res = requests.get(url) # 响应内容 html = res.text # 加载字体文件 szec = TTFont('szec.ttf') # 查看字体之间的映射关系 szec.saveXML('szec.xml') # 获取字符映射表 name = szec.getBestCmap() # 创建一个空字典用于存储转换后的字符映射表 dic = {} # 遍历原字符映射表的键值对 for k, v in name.items(): # 将键转换为十六进制表示形式 k = hex(k) # 去除相同的前缀 new_key = str(k)[2:] # 将转换后的键值对存储到字典中 dic[new_key] = v # 打印转换后的字符映射表 # print(dic) # 识别文字,组合成列表 lst = [ '0', '1', '2', '3', '4', '5', '6', '7', '8', '9', ] # 获取字体文件中的字形顺序,去除第一个列表里面的空值 order = szec.getGlyphOrder()[1:] # 使用字形顺序和给定列表 lst 创建一个新的字典 new_dic = dict(zip(order, lst)) # 打印新的字典 # print(new_dic) # 遍历字典 dic 的键值对 for k, v in dic.items(): # 根据字典 value 的值在新字典 new_dic 中获取对应的字体值 value = new_dic[v] # 打印键和对应的 value # print(k, value) # 将加密文字替换成对应文字 html = html.replace(k, value) # 去除数据中多余字符 html = html.replace(';&#x', '').replace('&#x', '').replace('; ¥', '¥').replace(';人', '人') # 打印处理后的网页源码 # print(html) # 使用 lxml 库中的 etree 模块解析 HTML 响应内容 html_text = etree.HTML(html) # 职位 positions = html_text.xpath('//h5[@class="card-title"]//text()') # 人数 peoples = html_text.xpath('//p[@class="float-right"]//text()') # 薪资 salaries = html_text.xpath('//p[@class="card-text text-muted"]//text()') # 创建一个空列表用于存储处理结果 result = [] # 列表合并遍历 for position, people, salary in zip(positions, peoples, salaries): # 将每个职位、人数和薪资信息组合成一个字符串,并添加到结果列表中 result.append(f"{position} {people} {salary}") # 将结果列表中的字符串使用换行符连接起来,形成最终的输出字符串 output = '\n'.join(result) # 打印结果 print(output)- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 61
- 62
- 63
- 64
- 65
- 66
- 67
- 68
- 69
- 70
- 71
- 72
五、案例三
目标网站:https://www.qidian.com/rank/yuepiao/
需求:爬取标题和对应月票值
代码实现
import requests # 导入 requests 库,用于发送 HTTP 请求和处理 HTTP 响应 from lxml import etree # 导入 lxml 库中的 etree 模块,用于解析 HTML 文档 from fontTools.ttLib import TTFont # 导入 fontTools 库中的 TTFont 模块,用于处理 TrueType 字体文件 # 目标 url url = 'https://www.qidian.com/rank/yuepiao/' # 发送 get 请求,获取响应对象 res = requests.get(url) # 响应内容 html = res.text # 打印响应内容 # print(html) # 查找字体文件 url 的起始位置 start_index = html.find(", url('") + len(", url('") # 查找字体文件 url 的结束位置 end_index = html.find(".ttf") + len(".ttf") # 获取 url link = html[start_index:end_index] # 打印 url # print(link) # 发送请求,获取字体文件 response = requests.get(link) # 检查响应是否成功 if response.status_code == 200: # 保存字体文件 with open('qd.ttf', 'wb') as f: f.write(response.content) print('文件保存成功!') else: print('无法下载文件!') # 加载字体文件 qd = TTFont('qd.ttf') # 查看字体之间的映射关系 qd.saveXML('qd.xml') # 获取字符映射表 name = qd.getBestCmap() # 打印字符映射表 # print(name) # 识别文字,组合成列表 lst = [ '.', '0', '1', '2', '3', '4', '5', '6', '7', '8', '9', ] # 获取字体文件中的字形顺序,去除第一个列表里面的空值 order = qd.getGlyphOrder()[1:] # 使用字形顺序和列表 lst 创建一个新的字典 new_dic = dict(zip(order, lst)) # 打印新的字典 # print(new_dic) # 在替换之前,将列表里面的数据转成字符串类型的数据 html_str = str(html) # 遍历字典的键值对 for k, v in name.items(): # 根据字典 value 的值在新字典 new_dic 中获取对应的字体值 value = new_dic[v] # 打印键和对应的 value # print(k, value) # 将加密文字替换成对应文字 html_str = html_str.replace(str(k), str(value)) # 去除数据中多余字符 html_str = html_str.replace(r';&#', '').replace(r'&#', '').replace(r';', '') # 打印处理后的网页源码 # print(html_str) # 解析 HTML 响应内容 html = etree.HTML(html_str) # 标题 titles = html.xpath('//h2/a//text()') # 月票 contents = html.xpath('//div[@class="total"]/p/span/span//text()') # 创建一个空列表用于存储处理结果 result = [] # 列表合并遍历 for title, content in zip(titles, contents): # 将每个职位、人数和薪资信息组合成一个字符串,并添加到结果列表中 result.append(f"{title} {content}") # 将结果列表中的字符串使用换行符连接起来,形成最终的输出字符串 output = '\n'.join(result) # 打印结果 print(output)- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 61
- 62
- 63
- 64
- 65
- 66
- 67
- 68
- 69
- 70
- 71
- 72
- 73
- 74
- 75
- 76
- 77
- 78
- 79
- 80
- 81
- 82
- 83
六、安装 Tesseract
开源软件,识别字母,数字。
1、安装步骤
1、点击“Next”;

2、同意协议,点击“Next”;
3、点击“Next”;

4、点击“Next”;

5、更改存放位置,点击“Next”;

6、点击“Install”;

7、点击“Next”;

8、点击“Finish”。
2、配置环境
1、在桌面上“此电脑”图标上右击,选择“属性”,选择“高级系统设置”;
2、选择“高级”,点击“环境变量”;
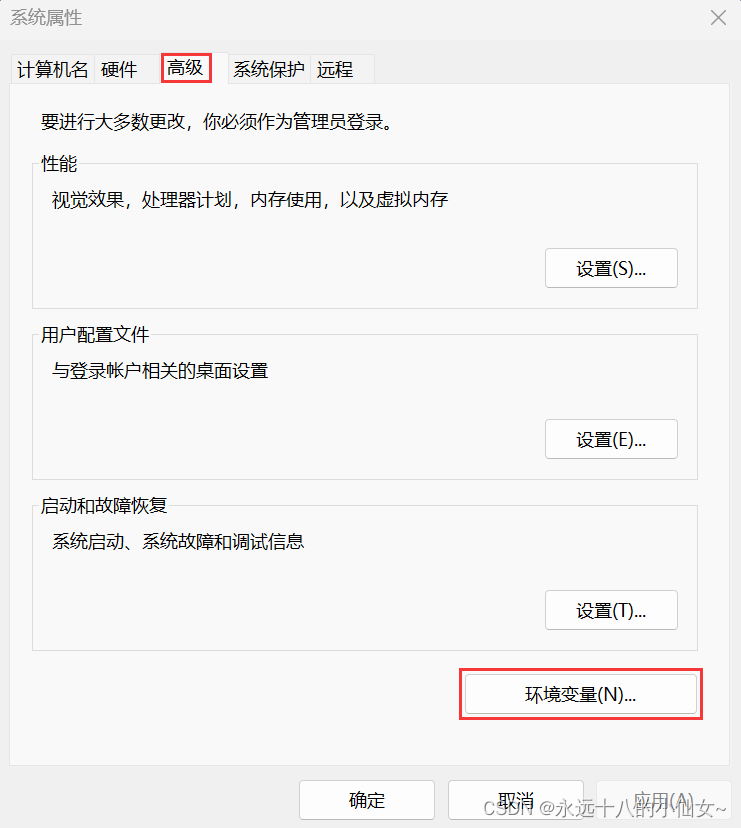
3、找到系统变量,点击“新建”;
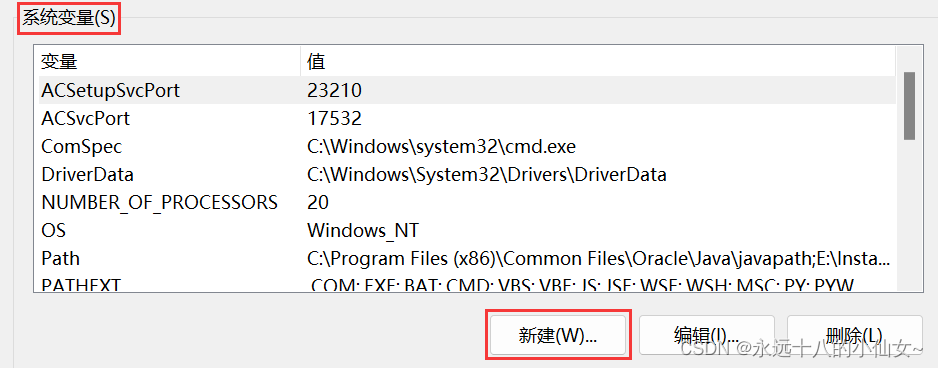
4、填入变量名和变量值,变量值为安装路径,点击“确定”;
变量名输入:TESSDATA_PREFIX
变量值输入:E:\Install\Tesseract-OCR

5、选中“Path”,点击“编辑”;

6、点击“新建”,填入安装路径,点击“确定”;

7、验证是否配置成功;
在终端输入命令:tesseract --version

3、使用 Python 识别图片信息
1、在终端安装模块:pip install pytesseract
2、在源码中找到 Lib 文件夹下的 site-packages 文件夹

3、找到 site-packages 文件夹下的 pytesseract 文件夹下的 pytesseract.py 文件

4、打开 pytesseract.py 文件,修改代码

5、识别图片数字
import pytesseract # 导入 pytesseract 库,用于识别图像中的文本 # pip install pillow from PIL import Image # 导入 PIL 库中的 Image 模块,用于打开和处理图像 # 打开图像文件,并创建一个 Image 对象 img = Image.open('ziroom.jpg') # 使用 pytesseract 库对图像进行文本识别 res = pytesseract.image_to_string(img) # 打印识别结果 print(res)- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
七、案例四
目标网站:https://www.ziroom.com/z/
需求:爬取标题以及租金
页面分析
1、确定目标 url:https://www.ziroom.com/z/
2、找到所有的房屋数据
div_list = //div[@class= “Z_list-box”]/div[@class= “item”]
3、获取标题以及租金
标题:class= “title sign”
租金:
第1个数字:-0px
第2个数字:-21.4px
第3个数字:-42.8px
第4个数字:-64.2px
num_lst = [第1个数字,第2个数字,第3个数字,第4个数字]——图片上的数字(会发生变化)
x_lst = [‘-0px’,‘-21.4px’,‘-42.8px’,‘-64.2px’]——图片上数字的间距(不会发生变化)
合并成一个字典 = {‘-0px’:第1个数字,‘-21.4px’:第2个数字,‘-42.8px’:第3个数字,‘-64.2px’:第4个数字}
4、图片会随时发生变化,每一次发请求需要获取网页源码的同时获取对应的图片
代码实现
import requests # 导入 requests 库,用于发送 HTTP 请求 from lxml import etree # 导入 lxml 库中的 etree 模块,用于解析 HTML/XML from urllib import request # 导入 urllib 库中的 request 模块,用于发送 HTTP 请求 from PIL import Image # 导入 PIL 库中的 Image 模块,用于打开和处理图像 import re # 导入 re 模块,用于正则表达式操作 import pytesseract # 导入 pytesseract 库,用于识别图像中的文本 class ZiRoom(object): # 获取网页源码和图片 def get_html_img(self): # 目标 url url = 'https://www.ziroom.com/z/p50-q888769217579814913/' # 请求头 head = { 'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/116.0.0.0 Safari/537.36' } # 发送 GET 请求 res = requests.get(url, headers=head) # 获取响应的 HTML 内容 html = res.text # 打印响应内容 # print(html) # 匹配图片 url img_url = 'https:' + re.search(r'url\((.*?)\);', html, re.S).group(1) # 打印图片 url # print(img_url) # 下载图片并保存到本地 request.urlretrieve(img_url, '数字.jpg') # 返回 HTML 内容 return html # 解析数据 def parse_data(self, html, replace_dict): # 解析 HTML 内容 tree = etree.HTML(html) # 获取房屋数据 div_list = tree.xpath('//div[@class="Z_list-box"]/div[@class="item"]') for div in div_list: try: # 获取标题文本 title = div.xpath('.//h5[contains(@class, "title ")]/a/text()') # 打印标题 print(title) # 获取价格元素列表 span_lst = div.xpath('.//div[@class="price "]/span[@class="num"]') # 价格 price = '' for span in span_lst: # 获取偏移量 # 获取价格元素的 style 属性值 style = span.xpath('./@style')[0] # 提取 style 属性值中的位置信息 position = style.split(': ')[-1] # 根据位置信息在替换字典中找到对应的数字 num = replace_dict[position] # 拼接数字 price = price + num # 获取价格单位 end = div.xpath('.//span[@class="unit"]/text()')[0] # 拼接价格 price = price + end # 打印价格 print(price) except: pass # 处理主逻辑 def main(self): # 获取 HTML 内容并下载图片 html = self.get_html_img() # 打开图片文件,并创建一个 Image 对象 img = Image.open('数字.jpg') # 使用 pytesseract 库对图像进行文本识别 img_res = pytesseract.image_to_string(img) # 打印图像识别 # print(img_res) # 使用正则表达式提取图像识别结果中的数字,数字转变成列表 num_lst = re.findall('\d', img_res) # 打印提取的数字列表 # print(num_lst) # 偏移量列表 x_lst = ['-0px', '-21.4px', '-42.8px', '-64.2px', '-85.6px', '-107px', '-128.4px', '-149.8px', '-171.2px','-192.6px'] # 两个列表合并成一个字典 replace_dict = dict(zip(x_lst, num_lst)) # 解析数据 self.parse_data(html, replace_dict) # 创建 ZiRoom 对象 zr = ZiRoom() # 调用主函数开始执行代码 zr.main()- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 61
- 62
- 63
- 64
- 65
- 66
- 67
- 68
- 69
- 70
- 71
- 72
- 73
- 74
- 75
- 76
- 77
- 78
- 79
- 80
- 81
- 82
- 83
- 84
- 85
- 86
- 87
- 88
- 89
- 90
- 91
记录学习过程,欢迎讨论交流,尊重原创,转载请注明出处~
-
相关阅读:
realme手机适合什么蓝牙耳机?适合realme手机的蓝牙耳机推荐
达梦数据库(DM8)服务部署与日常运维
谷歌浏览器如何设置和恢复纯黑界面
关于JS进行大文件分片上传碰到的问题
4.HMM和CRF的使用和应用
linux设置应用开机自启(通用:mysql、jar、nginx、solr...)
【愚公系列】2022年12月 使用win11系统自带SSH,远程控制VMware中Liunx虚拟机系统
STM32概念和安装【第一天】
关于进制的简单介绍
基于SSM的甜品店商城系统
- 原文地址:https://blog.csdn.net/muyuhen/article/details/132828820
