-
岭回归与LASSO回归:解析两大经典线性回归方法
🍋引言
在机器学习和统计建模中,回归分析是一项重要的任务,用于预测一个或多个因变量与一个或多个自变量之间的关系。在这个领域中,有许多回归方法可供选择,其中岭回归和LASSO回归是两种经典的线性回归技术。在本文中,我们将深入探讨这两种方法的原理、应用和优缺点,帮助您更好地理解它们在实际问题中的作用。
🍋岭回归(Ridge Regression)
岭回归,又称L2正则化,是一种用于解决多重共线性问题的线性回归技术。多重共线性是指自变量之间存在高度相关性的情况,这会导致普通最小二乘法(OLS)估计的不稳定性,使得模型的预测性能下降。岭回归通过在损失函数中添加一个正则化项来解决这个问题,其数学表达式如下:
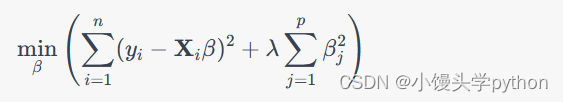
其中, y i y_i yi 是观测值, X i \mathbf{X}_i Xi 是自变量矩阵, β \beta β 是待估计的回归系数, λ \lambda λ 是正则化参数,用于控制正则化的强度。岭回归通过增加 β j \beta_j βj的平方和来限制回归系数的大小,从而减少多重共线性对估计结果的影响。
岭回归的优点包括:
- 改善多重共线性问题。
- 稳定的估计结果,不容易受到异常值的影响。
- 可以处理高维数据集,避免过拟合。
然而,岭回归也有一些缺点,例如它不能自动选择重要的特征,需要手动调整正则化参数 λ \lambda λ,并且可能不适用于稀疏数据集。
🍋实战—岭回归
首先我们假设一组数据
import numpy as np import matplotlib.pyplot as plt np.random.seed(666) x = np.random.uniform(-3,3,size=100) X = x.reshape(-1,1) y = 0.5 * x + 3 + np.random.normal(0,1,size=100) plt.scatter(X,y) plt.show()- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
运行结果如下
接下来我们导入我们需要的一些库from sklearn.preprocessing import PolynomialFeatures,StandardScaler from sklearn.pipeline import Pipeline # 管道 from sklearn.linear_model import LinearRegression,Ridge,Lasso # 岭回归和LASSO回归 from sklearn.model_selection import train_test_split from sklearn.metrics import mean_squared_error- 1
- 2
- 3
- 4
- 5
为了方便读者理解,这里我将每个库进行一些说明
-
sklearn.preprocessing:这个库是scikit-learn(通常被称为sklearn)的一部分,用于数据预处理。其中的PolynomialFeatures类可以用来生成多项式特征,将原始特征转换为高次幂的特征,以帮助模型拟合非线性关系。这对于处理非线性问题非常有用。StandardScaler类用于标准化数据,即将数据进行均值为0、方差为1的缩放,以确保特征在相同的尺度上。
-
sklearn.pipeline:Pipeline是一种机器学习中用于构建和管理多个数据处理和模型构建步骤的工具。它允许将多个数据处理步骤串联在一起,形成一个连续的流程。在您的代码示例中,Pipeline用于将多项式特征生成、数据标准化和线性回归(或其他回归算法)的步骤组合在一起,使其可以一次性执行。
-
sklearn.linear_model:这个库包含了各种线性回归模型的实现。这里面提到了LinearRegression、Ridge和Lasso。这些模型用于进行线性回归分析。具体来说,LinearRegression是标准的线性回归模型,Ridge是岭回归模型,Lasso是LASSO回归模型。这些模型用于建立线性关系模型,其中目标是拟合自变量和因变量之间的线性关系,并预测未知数据的因变量值。
-
sklearn.model_selection:这个库提供了用于模型选择和评估的工具。train_test_split函数用于将数据集分成训练集和测试集,以便训练模型和评估其性能。您可以使用此函数将数据划分为两部分,一部分用于训练模型,另一部分用于评估模型的性能。
-
sklearn.metrics:这个库包含了各种用于模型性能评估的指标。在您的代码示例中,您提到了mean_squared_error。这是一个用于回归问题的评估指标,用于度量模型的预测值与实际观测值之间的均方误差。均方误差越小,模型的性能越好。
之后我们需要创建一个多项式回归模型管道,管道的创建方式之前有提过,这里就直接展示
def polynomialRegression(degree): return Pipeline([ ('poly',PolynomialFeatures(degree)), ('std_scaler',StandardScaler()), ('lin_reg',LinearRegression()) ])- 1
- 2
- 3
- 4
- 5
- 6
之后我们进行分割数据集并且设置随机种子
np.random.seed(666) X_train,X_test,y_train,y_test = train_test_split(X,y)- 1
- 2
接下来我们还是创建一个函数,为了可视化数据
def plot_model(estimator): y_predict = estimator.predict(X_test) print(mean_squared_error(y_test,y_predict)) X_plot = np.linspace(-3,3,100).reshape(-1,1) y_plot = estimator.predict(X_plot) plt.scatter(X,y) plt.plot(X_plot,y_plot,color='r') plt.axis([-3,3,-2,6])- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
这里我进行一个代码的解释说明,我们定义了一个plot_model函数,这个函数的参数是一个已经训练好的模型,之后打印一个均方误差,用于为了测试预测性能;之后就是预测并且绘制图像了
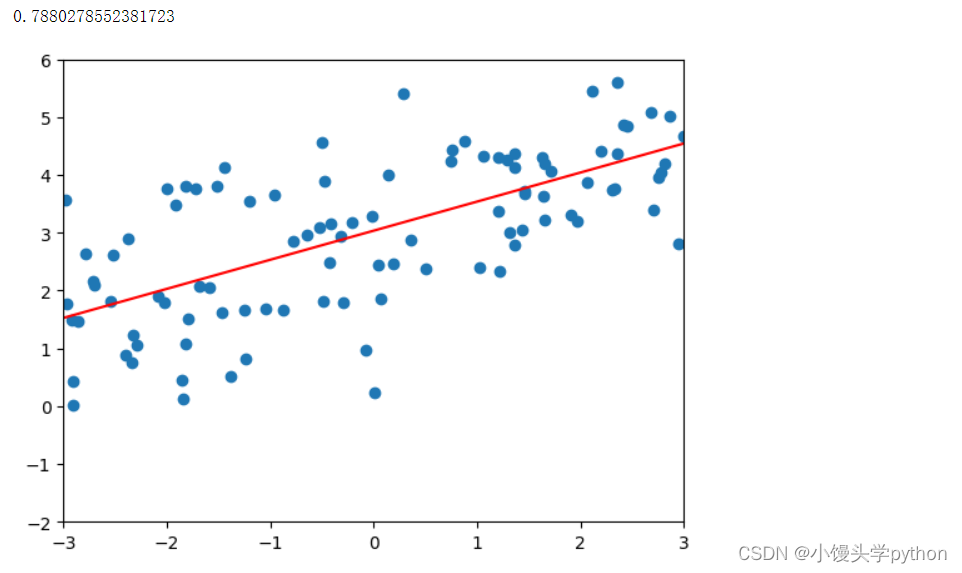
之后我们就可以进行拟合了,这里采用的是多项式回归模型
poly_reg = polynomialRegression(1) poly_reg.fit(X_train,y_train) plot_model(poly_reg)- 1
- 2
- 3
第一行定义了一个polynomialRegression类,参数为1代表是一阶多项式;之后使用fit进行训练,最后将训练好的模型传入到plot_model函数中
运行结果如下
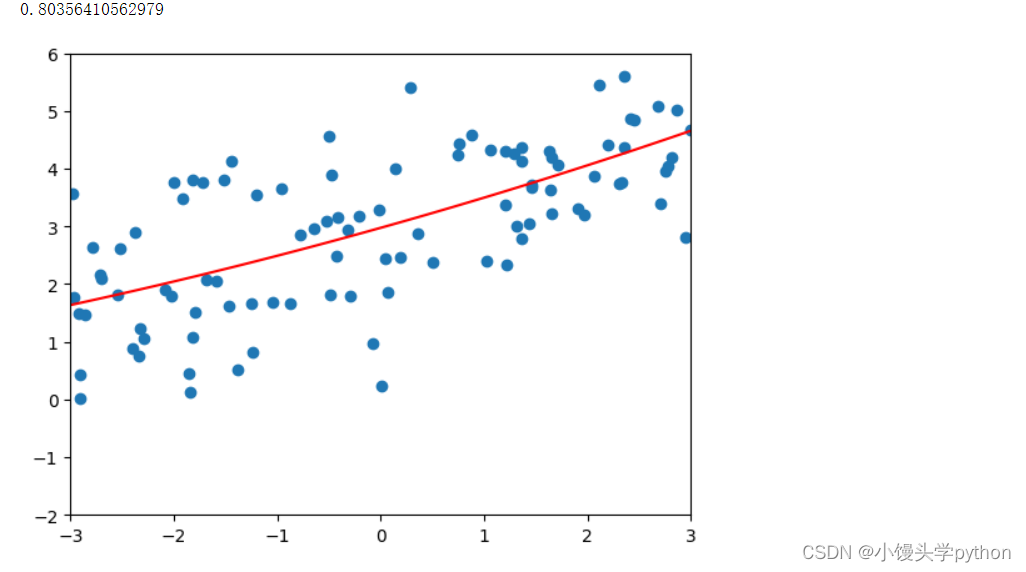
接下来我们再以二阶多项式和二十阶多项式进行绘制图像
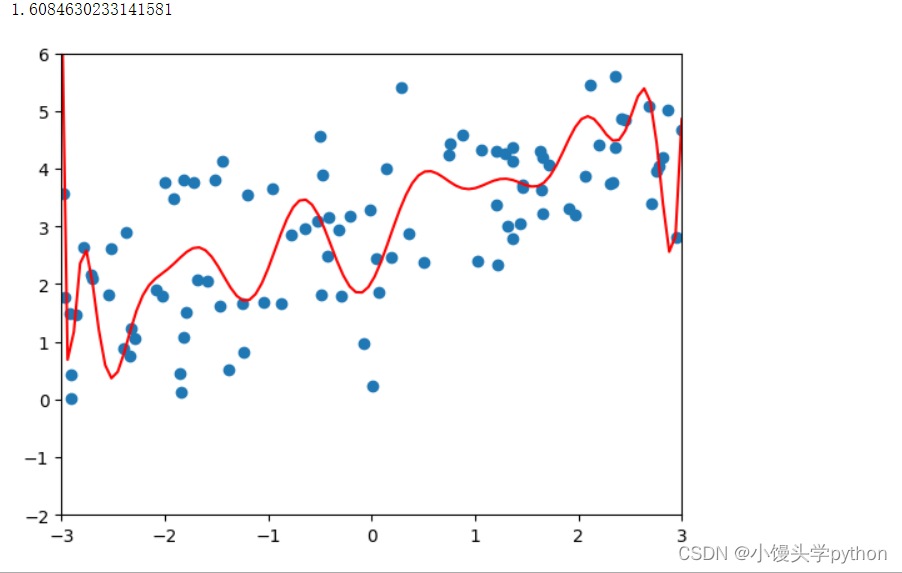
接下来我们重新定义管道,使用岭回归def polynomialRidgeRegression(degree,alpha): return Pipeline([ ('poly',PolynomialFeatures(degree)), ('std_scaler',StandardScaler()), ('lin_reg',Ridge(alpha=alpha)) ])- 1
- 2
- 3
- 4
- 5
- 6
之后我们进行拟合
poly_reg = polynomialRidgeRegression(20,0.0001) poly_reg.fit(X_train,y_train) plot_model(poly_reg)- 1
- 2
- 3
运行结果如下
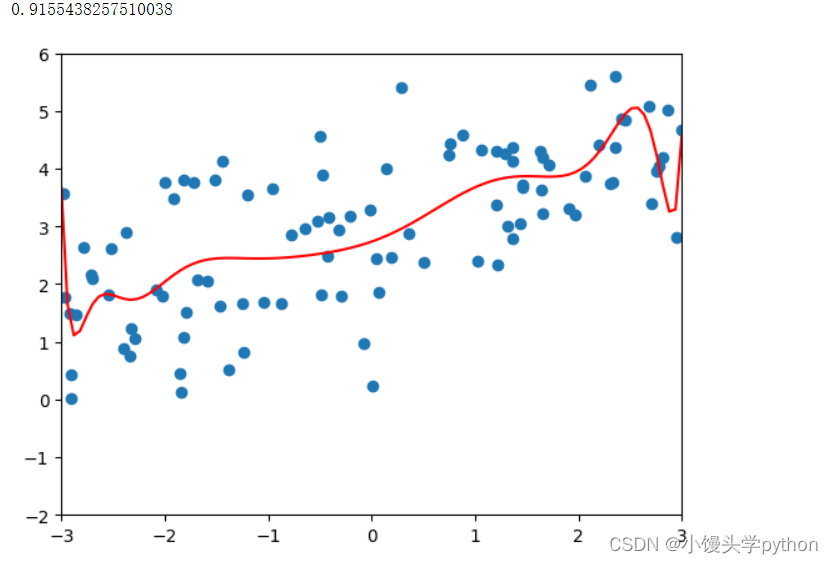
之后我们再重新修改一下参数poly_reg = polynomialRidgeRegression(20,1000) poly_reg.fit(X_train,y_train) plot_model(poly_reg)- 1
- 2
- 3
运行结果如下
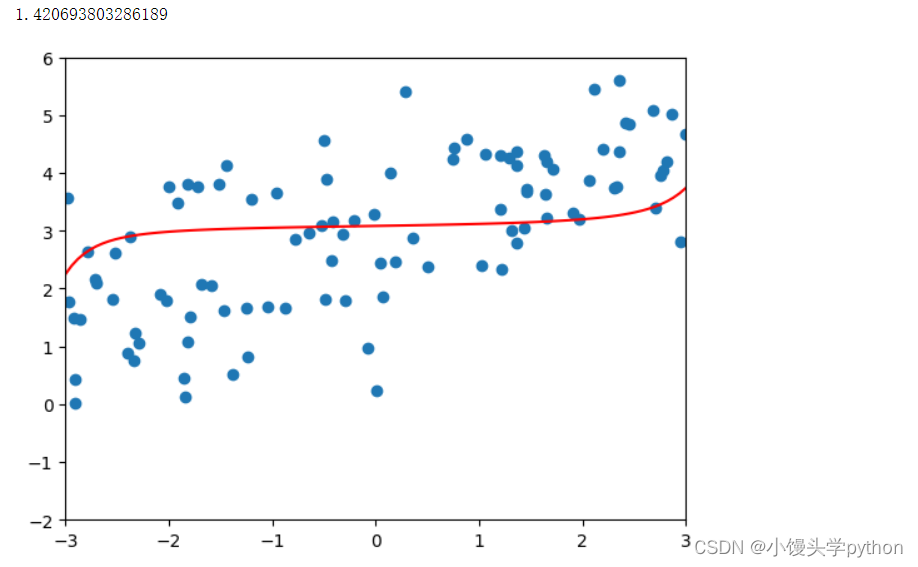
从均方误差来看,有点正则过头了那么如果 λ \lambda λ再大点呢
poly_reg = polynomialRidgeRegression(20,100000) poly_reg.fit(X_train,y_train) plot_model(poly_reg)- 1
- 2
- 3
运行结果如下
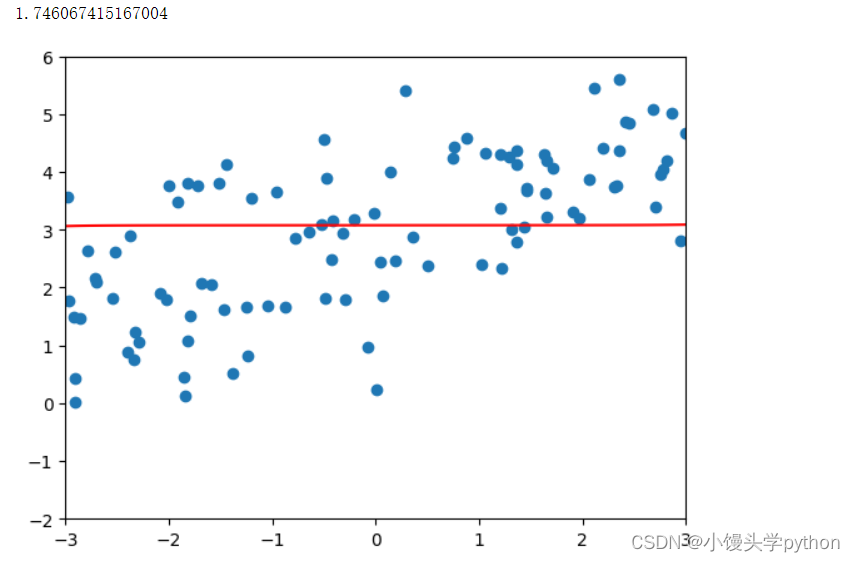
会发现几乎趋近于一条直线了。我们再来看看LASSO回归🍋LASSO回归(LASSO Regression)
LASSO回归,又称L1正则化,是另一种处理多重共线性问题的线性回归方法。与岭回归不同,LASSO回归在损失函数中添加的正则化项是回归系数的绝对值之和,其数学表达式如下:
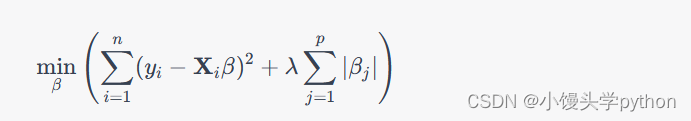
与岭回归相比,LASSO回归有以下特点:- LASSO回归具有特征选择的能力,它可以将某些回归系数缩减至零,从而自动选择重要的特征。
- 可以用于稀疏数据集的建模。
- LASSO回归的正则化路径可以帮助选择最优的正则化参数 λ \lambda λ。
然而,LASSO回归也有一些缺点,例如当自变量之间高度相关时,它可能随机选择其中一个自变量并将其系数设为零,不稳定性较高。
🍋实战—LASSO回归
与岭回归类似,这里就不一一赘述了
def polynomialLsssoRegression(degree,alpha): return Pipeline([ ('poly',PolynomialFeatures(degree)), ('std_scaler',StandardScaler()), ('lin_reg',Lasso(alpha=alpha)) ])- 1
- 2
- 3
- 4
- 5
- 6
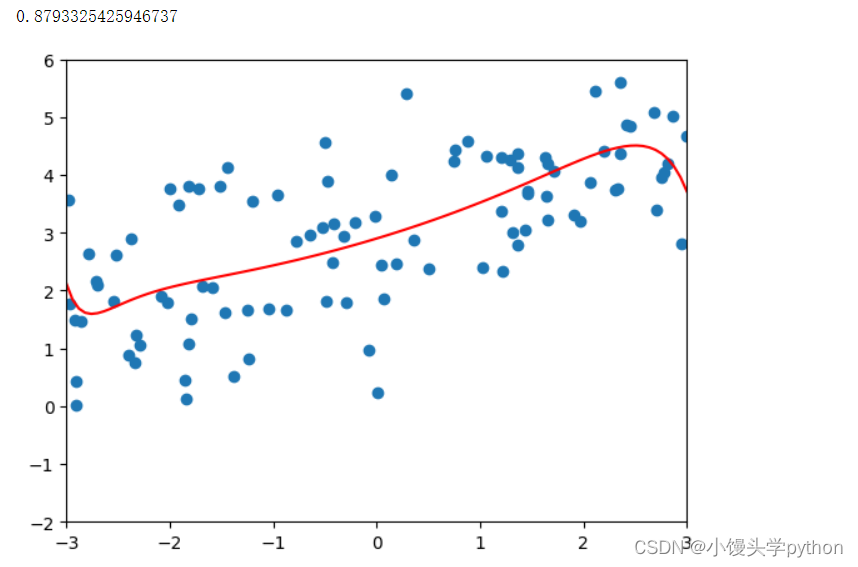
poly_reg = polynomialLsssoRegression(20,0.01) poly_reg.fit(X_train,y_train) plot_model(poly_reg)- 1
- 2
- 3
运行结果如下
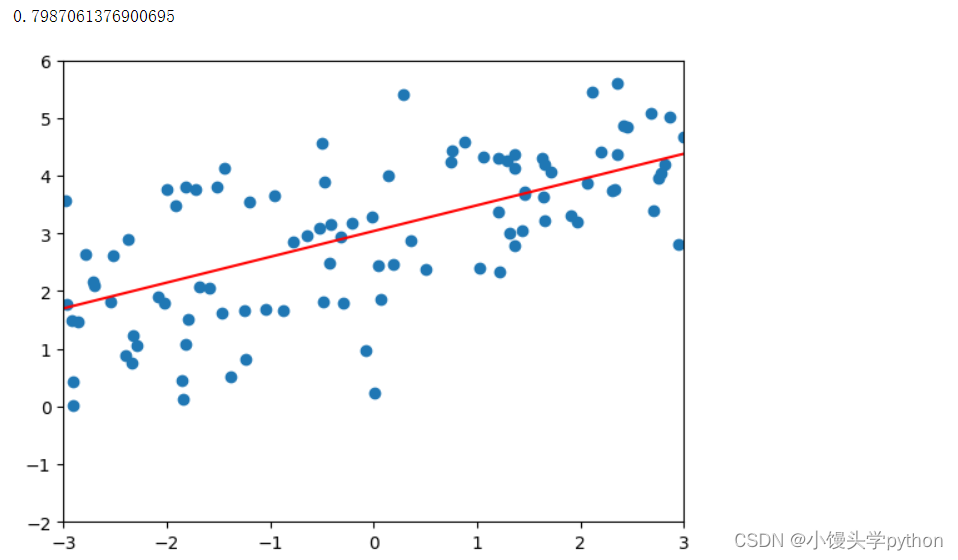
poly_reg = polynomialLsssoRegression(20,0.1) poly_reg.fit(X_train,y_train) plot_model(poly_reg)- 1
- 2
- 3
运行结果如下
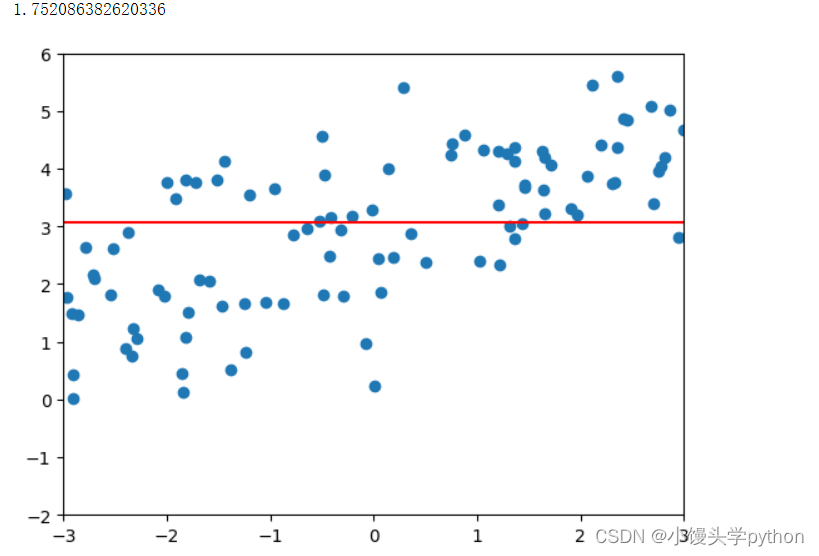
poly_reg = polynomialLsssoRegression(20,1) poly_reg.fit(X_train,y_train) plot_model(poly_reg)- 1
- 2
- 3
运行结果如下
🍋岭回归和LASSO哪个更容易是直线
-
岭回归:
岭回归引入的正则化项是L2正则化,它是回归系数的平方和。这个正则化项的作用是限制回归系数的大小,使它们不能过大。因此,岭回归有助于处理多重共线性问题,同时也可以防止过拟合。由于L2正则化是平方和的形式,所以它倾向于平滑回归系数,使它们趋向于均匀分布,不太容易生成稀疏模型。
岭回归的拟合曲线通常是平滑的,因为它在正则化项中对所有回归系数都施加了一定的约束,不容易将某些系数压缩至零。这意味着岭回归的模型通常不会是严格的直线,而是某种形式的平滑曲线。
-
LASSO回归:
LASSO回归引入的正则化项是L1正则化,它是回归系数的绝对值之和。这个正则化项的作用是促使一些不重要的回归系数变为零,实现自动特征选择。因此,LASSO回归可以生成稀疏模型,即只保留一部分重要的特征。
由于L1正则化的性质,LASSO回归的拟合曲线可能是分段线性的,也就是说,在某些特征上,回归系数为零,因此模型会生成严格的直线。这使得LASSO回归在某些情况下更容易生成直线模型。
🍋岭回归与LASSO回归的应用
这两种回归方法在许多领域都有广泛的应用,包括金融、医学、自然语言处理和工程等。具体应用如下:
- 金融领域:用于预测股票价格、房地产市场分析和信用评分模型。
- 医学领域:用于疾病预测、药物研发和医疗成本估计。
- 自然语言处理:用于文本分类、情感分析和机器翻译等。
- 工程领域:用于预测材料强度、机械故障检测和质量控制。
🍋L1正则化和L2正则化
L1正则化和L2正则化都是用于线性回归等机器学习模型中的正则化技术,它们的作用是防止模型过拟合,提高模型的泛化能力。它们的区别在于正则化项的形式和影响:
L1正则化(Lasso正则化):-
正则化项形式:L1正则化引入的正则化项是回归系数的绝对值之和。在数学上,它是回归系数的L1范数。
-
效果:L1正则化具有稀疏性质,即它有助于将某些不重要的特征的回归系数缩减至零,从而实现特征选择。这意味着L1正则化可以用来降低模型的复杂性,使模型更简单且易于解释。
-
稀疏性:L1正则化使得一些回归系数变得精确地等于零,因此可以生成稀疏模型。这对于高维数据集中的特征选择非常有用。
-
适用情况:L1正则化通常用于具有大量特征的数据集,并且希望自动选择最重要的特征的情况下。它也适用于处理多重共线性问题,但不如L2正则化那样强烈。
L2正则化(Ridge正则化):
-
正则化项形式:L2正则化引入的正则化项是回归系数的平方和。在数学上,它是回归系数的L2范数。
-
效果:L2正则化有助于防止模型的回归系数过大,从而降低模型对训练数据的过拟合风险。它不具备L1正则化的稀疏性质,通常不会将回归系数精确地压缩至零,而是使其趋向于较小的值。
-
平滑性:L2正则化倾向于生成平滑的回归系数,使模型更加稳定。它对多重共线性问题有较好的处理能力,可以减小相关特征之间的系数差异。
-
适用情况:L2正则化通常用于处理多重共线性问题或者在模型需要保留大部分特征的情况下,但希望限制回归系数的大小以提高模型的泛化能力。
🍋偏差和方差
偏差和方差是统计学和机器学习中两个重要的概念,用于评估模型的性能和泛化能力。它们通常一起讨论,因为它们在模型的复杂性和性能之间存在权衡关系。
-
偏差(Bias):
偏差是指模型的预测值与真实值之间的差距,即模型对问题的错误偏向。
当模型具有高偏差时,意味着它过于简单,无法捕捉数据中的复杂模式。这种情况下,模型可能会欠拟合,导致在训练数据和测试数据上都表现不佳。
通常来说,增加模型的复杂度(例如增加特征数量或增加模型参数)可以减小偏差,使其更能适应训练数据,但可能增加方差。 -
方差(Variance):
方差是指模型对于不同训练数据集的敏感性,即模型在不同数据集上的预测结果波动程度。
当模型具有高方差时,意味着它过于复杂,对训练数据过度拟合。这种情况下,模型在训练数据上表现很好,但在测试数据上可能表现不佳。
减小模型复杂度可以减小方差,使其更加稳定,但可能增加偏差。

挑战与创造都是很痛苦的,但是很充实。
-
相关阅读:
染色法判定二分图的算法
C打印内存16进制
角色妆容的实现
一些小知识点
五子棋(C语言实现)
nginx详解
SpringBoot - @PostConstruct 注解详解
关于泛型的知识
嵌入式操作系统--篮球记分计时系统
opencv项目_人脸识别_LBPH_python
- 原文地址:https://blog.csdn.net/null18/article/details/133079879