-
常见排序算法
一、冒泡排序(稳定)
模板:(交换排序)
- for (int i = 0; i < ans.size()-1; i++) {//一共排序 n-1 轮,因为最后一个元素不需要比较
- for (int j = 0; j < ans.size() - i -1; j++) {
- //比较完i轮就是有i个数被排序,所以还剩n-i个数,-1变成下标(即不包含的右边界)
- if (ans[j] > ans[j + 1]) {//升序
- int temp = ans[j];
- ans[j] = ans[j + 1];
- ans[j + 1] = temp;
- }
- }
- }
时间复杂度:
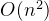
特点:
- 简单易实现:不需要额外的数据结构
- 稳定性:相等元素的相对位置在排序前后不会改变,冒泡排序是稳定的排序算法
- 效率较低:复杂度较高,适用于小规模的数据排序或者在其他排序算法中作为优化手段的一部分
适应场景:
- 由于冒泡排序的效率较低,在处理大量数据时不是首选。
- 更适用于处理小规模的数据或者在其他排序算法中作为优化手段的一部分。
二、选择排序
三、插入排序
四、希尔排序
五、归并排序
六、快速排序(不稳定)
模板:(交换排序)
视频链接:秒懂算法快速排序-动画4分钟精讲_哔哩哔哩_bilibili
- void quickSort(vector<int>& nums,int left,int right) {
- if (left >= right) return;//终止条件
- int midnum = nums[left];//选中基准值
- int i = left, j = right;
- while (i < j) {
- while (i
midnum) j--;//从右边界找到比基准值小的数 - if (i < j) {//比基准值小的数字插入左边槽中 移动左边界
- nums[i] = nums[j];
- i++;
- }
- while (i < j && nums[i] < midnum) i++;//从左边界找到比基准值大的数
- if (i < j) {//比基准值大的数子插入右边槽中 移动右边界
- nums[j] = nums[i];
- j--;
- }
- }
- nums[i] = midnum;//将基准值放入左边槽中
- quickSort(nums, left, i - 1);//将基准值左边的区间进行快排
- quickSort(nums, i + 1, right);
- }
时间复杂度:
- 平均时间复杂度为
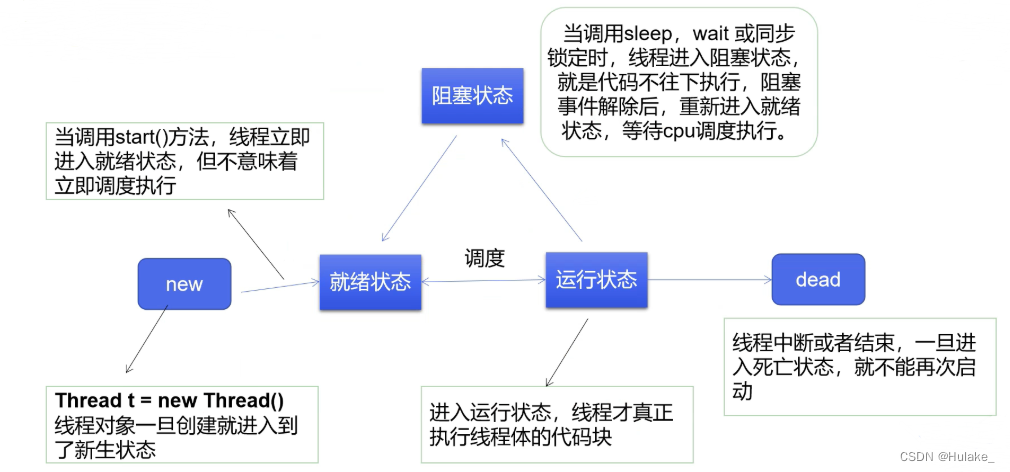
- 最差情况下的时间复杂度为 。
特点:
- 高效性:平均情况下时间复杂度为 ,相比于其他排序算法,效率更高
- 原地排序:不需要额外的辅助空间
- 分治思想:将排序序列分成大于基准值和小于基准值的两部分,然后分别递归划分和排序
- 不稳定性:排序过程中相同元素的相对顺序可能会发生变化
适应场景:
- 数组排序:排序大规模数字数据
- 查找第 k 大/小的元素:通过每次划分比较基准值所在的位置与 k 的大小关系,可以只对需要的部分继续进行排序,从而提供查找效率。(只需要判断基准值插入的槽,和 k 相同时,就是查找元素)
七、堆排序(不稳定)
- void heapify(vector<int>& arr, int size, int i)
- {
- int largest = i;
- int lson = 2 * i + 1;
- int rson = 2 * i + 2;
- if (lson < size && arr[largest] < arr[lson])
- largest = lson;
- if (rson < size && arr[largest] < arr[rson])
- largest = rson;
- if (largest != i)//当父节点不是最大值
- {
- swap(arr[i], arr[largest]);//把最大值和父节点值交换
- heapify(arr, size, largest);//维护下一层
- }
- }
- void heap_sort(vector<int>& arr)
- {
- int size = arr.size();
- // 建堆
- for (int i = size / 2 - 1; i >= 0; i--)
- heapify(arr, size, i);
- // 排序
- for (int i = size - 1; i > 0; i--)
- {
- swap(arr[0], arr[i]);
- heapify(arr, i, 0);
- }
- }
时间复杂度:
特点:
- 构建初始堆需要
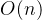 的时间,而对每个元素进行堆调整和交换的操作都需要
的时间,而对每个元素进行堆调整和交换的操作都需要 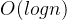 的时间,共需要进行
的时间,共需要进行  次。
次。 - 原地排序,不需要额外的存储空间。因此空间复杂度为
 。
。 - 相等元素的相对顺序可能会发生改变,排序不稳定。
适用场景:
- 在数据量较大且没有进一步的空间限制时非常有效,由于时间复杂度为 ,因此处理大规模数据时表现良好。
- 适用于对内存占用有限的场景。
- 适用于部分排序场景。
八、计数排序
九、桶排序
十、基数排序
-
相关阅读:
SpringBoot 整合 MyBatis-Plus
[ 一刷完结撒花!! ] Day50 力扣单调栈 : 503.下一个更大元素II |42. 接雨水 | 84.柱状图中最大的矩形
150:vue+openlayers 多边形拐点用不同形状表示(圆形、三角形、矩形、正方形、星形...)
SpringCloud Alibaba - Sentinel 授权规则、自定义异常结果
ZMUIFramework视屏教程获取&案例使用
提前预体验阿里大模型“通义千问”的方法来了!
大学网课查题公众号零基础注册使用(内含详细教程和接口)
【Leetcode】70. 爬楼梯
工业互联网:数字化革命的引擎
【融合ChatGPT等AI模型】Python-GEE遥感云大数据分析、管理与可视化及多领域案例实践应用
- 原文地址:https://blog.csdn.net/Ricardo_XIAOHAO/article/details/133101384
