-
大模型LLM深入浅出、主打通俗易懂
AI(人工智能)是通过机器来模拟人类认识能力的一种科技能力。AI最核心的能力就是根据给定的输入做出判断或预测。对数据进行分析,从而总结得到研究对象的内在规律。一般通过使用适当的统计、机器学习、深度学习等方法,对收集的大量数据进行计算、分析、汇总和整理,以求最大化地开发数据价值,发挥数据作用。
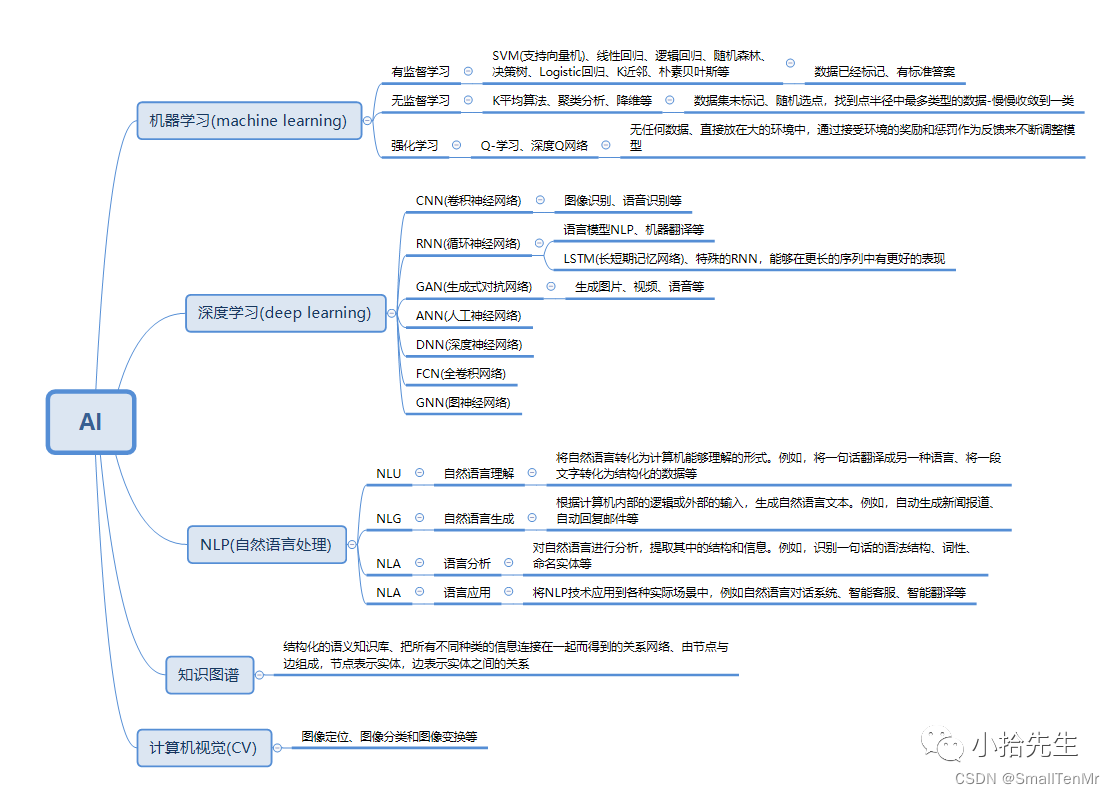
目前AI分两大模块,计算机视觉和自然语言处理
1.计算机视觉应用场景:人脸识别、自动驾驶、车辆识别、医学影像、工业机器人图像分类、图片增强现实等。
2.自然语言处理应用场景:智能客服、语音识别、机器翻译、自然语言生成、智能助理、信息抽取等。
NLP(自然语言处理)它是研究如何让计算机读懂人类语言,也就是将人的自然语言转换为计算机可以阅读的指令,NLP是人工智能和语言学领域的分支学科。
而LLM是 NLP 中的一个重要组成部分,主要是用来预测自然语言文本中下一个词或字符的概率分布情况,可以看作是一种对语言规律的学习和抽象。
本文主要针对LLM(大语言模型)展开叙述。
LLM它是一种人工智能模型,主要是为了理解和生成人类语言,是在大量的文本数据上进行训练,可以执行大量的任务,包括文本总结、机器翻译、情感分析等等,其中最常见的应用是智能客服、语音识别、机器翻译、自然语言生成等。
LLM的特点是规模庞大,包含成百、上千亿的参数,该模型可以捕捉语言的复杂模式,包括句法、语义和一些上下文信息,从而生成连贯的、有意义的文本。
目前国内外有很多成熟大模型,如下:

其中ChatGLM是清华技术成果转化的公司智谱AI研发的支持中英双语的对话机器人。按照训练参数分类分别为ChatGLM-130B、ChatGLM-6B、ChatGLM2-6B等几种大模型(参数单位 1B=10亿)。
在斯坦福大学2022年对全球30个主流大模型全方位的评测中,ChatGLM-130B是亚洲唯一入选的大模型,其在准确性和恶意性指标上与 GPT-3-175B 接近或持平。
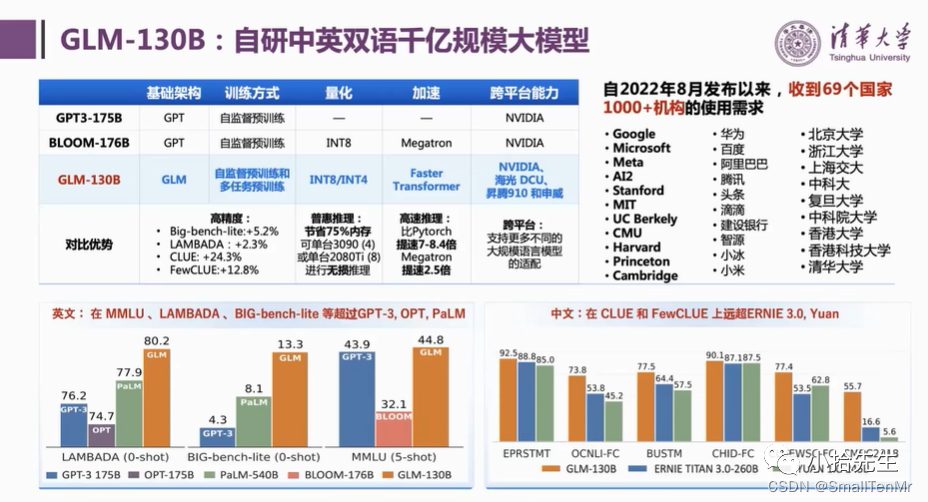
在ChatGLM产品中,ChatGLM-6B 是一个开源的、支持中英双语的对话语言模型,基于 GLM (General Language Model) 架构,具有62亿参数。ChatGLM-6B 使用了和 ChatGPT 相似的技术,针对中文问答和对话进行了优化。经过约 1T 标识符的中英双语训练,辅以监督微调、反馈自助、人类反馈强化学习等技术的加持,62 亿参数的 ChatGLM-6B 已经能生成相当符合人类偏好的回答。 并且ChatGLM-6B可以在消费级的显卡上进行本地部署(INT4 量化级别下最低只需6GB显存),即使量化参数为FP16精度,推理也只需要13GB显存,本次采用一张NVIDIA GeForce RTX 3090 GPU, 显存大小为24G。
目前主流大模型,都是基于LLaMA、chatglm进行预训练,所以诞生了几种预训练架构,如下:

图中的autoencoding自编码模型(AE模型)、 autoregressive自回归模型(AR模型)、encoder-decoder(Seq2seq模型),这三种预训练框架各有利弊,没有一种框架在“自然语言理解(NLU)、无条件生成以及条件生成”这三种领域中表现最佳。T5曾经尝试使用MTL的方式统一上述框架,然而“自编码”和“自回归”的目标天然存在差异,简单的融合无法继承各个框架的优点。
在天下三分的僵持局面下,GLM诞生了。GLM模型基于autoregressive blank infilling方法,结合了上述三种预训练模型的思想,GLM主要使用的技术是:双向注意力和自回归空白填充目标,嵌入梯度收缩策略可以显著提升训练稳定性。(模型结构详见论文:Glm: General language model pretraining with autoregressive blank infilling
那么接下来我将根据这张“GLM的mask原理”图详细解说一下

1.原理图简单注释:输入到模型中的prompt是如何进行mask,并同时实现单向和双向的注意力机制,借此全面了解训练目标和GLM结构。
2.假设说明:假设有一条原始数据,通过文本分割后,解析为6个span,分别为x1-x6。此时,随机遮住两个span,分别为x3、x5和x6,并且以mask打标记,假设分割后的文本x = [x1,x2..xn],多个采样span标识为{s1,s2...sm}, 其中选中的span用[mask]标记,则构成标记后的文本Xcorrupt。现在用Zm来表示长度是m的标号序列的所有的可能性,那么预训练的目标就可以表示为:

3.详细说明:图中(a)(b)可看出:原来的数据是x1-x6,分别采样x3、x5和x6后,就变成了两部分Part A和Part B。Part A是被损坏后的文本,被采样的数据用[mask]标记,而Part B是由采样数据组成。此时Part A和Part B部分将进行拼接作为模型的输入。
图(c)可看出:多了[E]和[S],其表达意思是每个span片段使用[S]填充在开头作为输入,使用[E]填充在末尾作为输出。而且能看到x5和x6 与 x3调换了位置,可以得知采样出来的片段是随机顺序,更能保证模型充分学习到片段之间的依赖关系。同时可看到,Position 1和Position 2,其中Position 1:代表每个Token在原始文本中所在的位置,可以看到Part B部分的span位置在Part A中的掩码表示 [M]对应的位置编码相同,而Position 2在待填空span中的相对位置。Part A部分中的Token用0来编码,能看到[s] x5 x6 是一个待填空片段,因此编码为1,2,3。
图(d)可看出:既有有双向注意力也有单向注意力。巧妙的地方在于:Part A中的tokens彼此可见,但是不可见B中的任意tokens,Part B tokens可见Part A,Part B tokens可见B中过去的tokens,不可见B中未来的tokens(蓝、黄、绿圈出的数据范围)。
总结理解一下就是:Part A部分相当于自编码的MLM语言模型,自然是利用双向的上下文信息,而Part B部分的每个Token需要采用自回归的形式至左向右预测,自然只能看到单向的信息。 模型可以自动学习双向encoder(Part A)以及单向decoder(Part B), 其实GLM主要的目的就是想利用未遮挡的数据来自回归式预测被遮住的信息。
若要构建垂直领域大模型,需要根据各自行业知识做预训练。目前各行业垂直领域大模型如下:
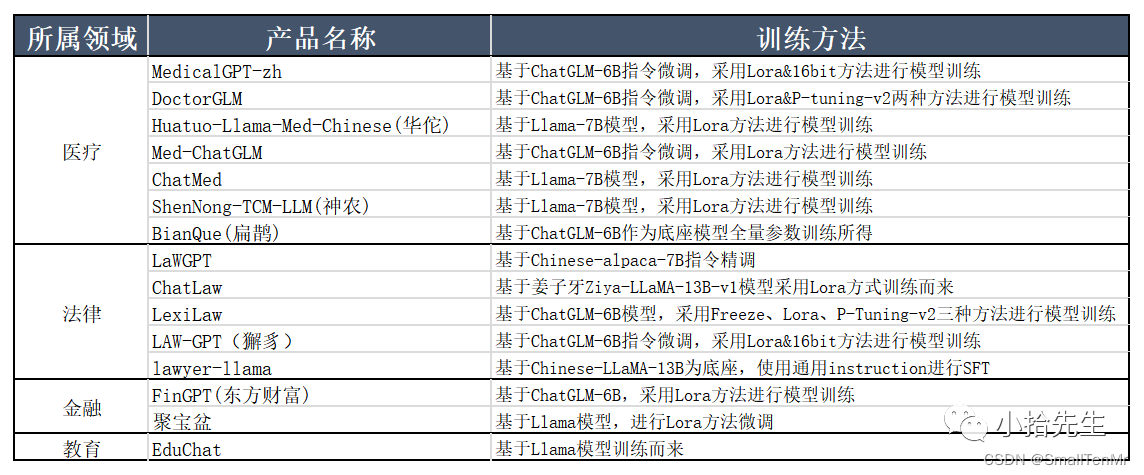
对上图中的训练方法再做个简单介绍,预训练私有垂直领域大模型目前有两种方式,第一种微调模型(LoRA、p-tuning v2),第二种基于LangChain框架的知识库原理。
1.LoRA(Low-Rank Adaptation of Large Language Models)的方法,是微软研究员引入的一项新技术,主要用于处理大模型微调的问题,在使用大模型适配下游任务时,只需训练少量参数即可达到很好的效果。核心原理: 通过冻结大语言模型中的预训练权重,同时在Transformer架构的每一层中加入可训练的低秩分解矩阵,通过低秩矩阵来运算,可以极大减少网络运算参数量。
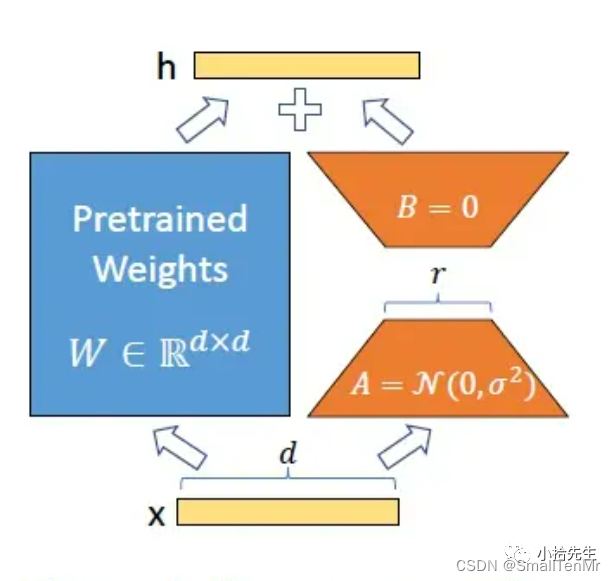
上图中(论文地址:https://arxiv.org/abs/2106.09685),左边蓝色代表预训练好的模型参数,右边橘色分别初始化A和B两块模型。众所周知,如果想直接训练蓝色的原始模型,将是十分耗费资源,需要8张A100显卡(A100目前市场价格13万一个),并且训练中耗费大量电力资源(OpenAI的chatGPT-3训练一次的成本约为140万美元),而为了节省资源,LoRA思想是将右边橘色的两个模型,先分别初始化为高斯分布和0,训练的时候固定预训练语言模型的参数(蓝色部分),只训练降维矩阵 A 与升维矩阵 B,而模型的输入输出维度不变,输出时将 BA 与预训练语言模型的参数叠加。用随机高斯分布初始化 A,用 0 矩阵初始化 B,这样能保证训练开始时,新增的通路BA=0,从而对模型结果没有影响,在推断时可以利用重参数(reparametrization)思想,将AB与W合并,这样就不会在推断时引入额外的计算了
假设在原始全量参数模型上微调,那么需要加入增量 W=W0+ΔW 。参考此公式,那么Lora其就是通过冻结原始参数W0 ,并且把增量部分通过低秩分解方式进一步降低参数量级ΔW=B*A ,原始参数的维度是d∗d (蓝色部分), 则低秩分解后的参数量级是2∗r∗d ,因为这里的r远小于d,所以起到了大幅降低微调参数量级的效果,即公式转变为 W = W0 + B*A。
此外,有兴趣可以了解prompt-tuning(提示调优)、p-tuning v2(Prefix-tuning)等算法,有时间再总结。
2.LangChain知识库
知识库存在的意义:建立一套对中文场景与开源模型支持友好、可离线运行的知识库问答解决方案
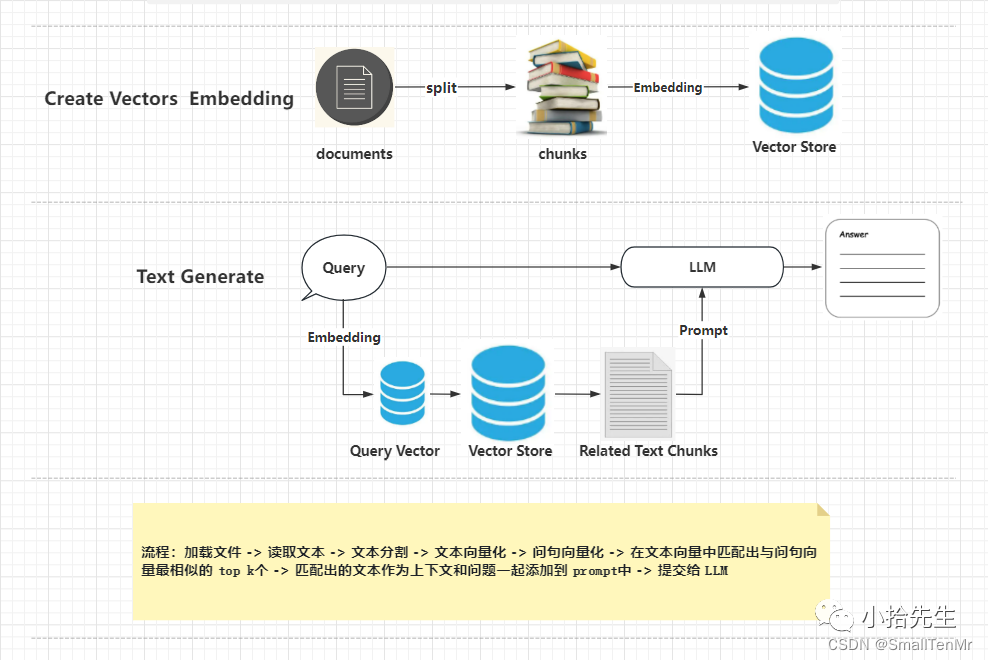
理解知识库,结合上图,三步走:
1.将一段文本划分为多个段落(split),将分割后的文档Embedding(向量化),存到向量库(图Vector Store标识)。
2.获取到用户的问题,先对问题Embedding,生成Query Vector,然后去Vector Store匹配最相近的TOP K。每一条内容都有评分,可以根据阈值筛选评分低的数据(相似Elasticsearch技术)。
3.将获取到的K条内容,整理成Prompts,并汇总用户问题,调LLM接口,生成答案。
举个例子理解:
有一个文本,里面有一段话
"小拾喜欢玩手机、打游戏、看电影。阿敏喜欢吐槽小拾。"
根据逗号分割问两句话:
(1)"小拾喜欢玩手机、打游戏、看电影。"
(2)"阿敏喜欢吐槽小拾。"
你可以问这么一个问题:
"小拾喜欢做什么?"
用这个问题查询文本向量库,根据相似性,会返回以下内容:
"小拾喜欢玩手机、打游戏、看电影。"
因为这句话和你的问题中都包含了"小拾","喜欢"
然后把这段话加上你的问题组合成prompts:
"""已知信息:
小拾喜欢玩手机、打游戏、看电影。
根据上述已知信息,简洁和专业的来回答用户的问题。如果无法从中得到答案,请说 “根据已知信息无法回答该问题” 或 “没有提供足够的相关信息”,不允许在答案中添加编造成分,答案请使用中文。问题是:小拾喜欢做什么
"""
将这个prompts扔给LLM,然后模型会重新组织语言,给出回答!
-
相关阅读:
java的基础用法和常见错误
Go语法之函数 defer使用
CSS逻辑组合伪类
每日一练 | 网络工程师软考真题Day43
Linux aarch64交叉编译之sqlite数据库
Linux进程控制
2023年【焊工(初级)】报名考试及焊工(初级)考试总结
常见移动端导航类型
关于ThreadPoolTaskExecutor线程池的配置
spring boot and php
- 原文地址:https://blog.csdn.net/SmallTenMr/article/details/133066350