-
基于Yolov8的野外烟雾检测(1)
目录
1.2 通过voc_label.py得到适合yolov8需要的txt
1.Yolov8介绍
Ultralytics YOLOv8是Ultralytics公司开发的YOLO目标检测和图像分割模型的最新版本。YOLOv8是一种尖端的、最先进的(SOTA)模型,它建立在先前YOLO成功基础上,并引入了新功能和改进,以进一步提升性能和灵活性。它可以在大型数据集上进行训练,并且能够在各种硬件平台上运行,从CPU到GPU。
具体改进如下:
-
Backbone:使用的依旧是CSP的思想,不过YOLOv5中的C3模块被替换成了C2f模块,实现了进一步的轻量化,同时YOLOv8依旧使用了YOLOv5等架构中使用的SPPF模块;
-
PAN-FPN:毫无疑问YOLOv8依旧使用了PAN的思想,不过通过对比YOLOv5与YOLOv8的结构图可以看到,YOLOv8将YOLOv5中PAN-FPN上采样阶段中的卷积结构删除了,同时也将C3模块替换为了C2f模块;
-
Decoupled-Head:是不是嗅到了不一样的味道?是的,YOLOv8走向了Decoupled-Head;
-
Anchor-Free:YOLOv8抛弃了以往的Anchor-Base,使用了Anchor-Free的思想;
-
损失函数:YOLOv8使用VFL Loss作为分类损失,使用DFL Loss+CIOU Loss作为分类损失;
-
样本匹配:YOLOv8抛弃了以往的IOU匹配或者单边比例的分配方式,而是使用了Task-Aligned Assigner匹配方式

框架图提供见链接:Brief summary of YOLOv8 model structure · Issue #189 · ultralytics/ultralytics · GitHub
2.野外火灾烟雾数据集介绍
数据集大小737张,train:val:test 随机分配为7:2:1,类别:smoke


2.1数据集划分
通过split_train_val.py得到trainval.txt、val.txt、test.txt
- # coding:utf-8
- import os
- import random
- import argparse
- parser = argparse.ArgumentParser()
- #xml文件的地址,根据自己的数据进行修改 xml一般存放在Annotations下
- parser.add_argument('--xml_path', default='Annotations', type=str, help='input xml label path')
- #数据集的划分,地址选择自己数据下的ImageSets/Main
- parser.add_argument('--txt_path', default='ImageSets/Main', type=str, help='output txt label path')
- opt = parser.parse_args()
- trainval_percent = 0.9
- train_percent = 0.7
- xmlfilepath = opt.xml_path
- txtsavepath = opt.txt_path
- total_xml = os.listdir(xmlfilepath)
- if not os.path.exists(txtsavepath):
- os.makedirs(txtsavepath)
- num = len(total_xml)
- list_index = range(num)
- tv = int(num * trainval_percent)
- tr = int(tv * train_percent)
- trainval = random.sample(list_index, tv)
- train = random.sample(trainval, tr)
- file_trainval = open(txtsavepath + '/trainval.txt', 'w')
- file_test = open(txtsavepath + '/test.txt', 'w')
- file_train = open(txtsavepath + '/train.txt', 'w')
- file_val = open(txtsavepath + '/val.txt', 'w')
- for i in list_index:
- name = total_xml[i][:-4] + '\n'
- if i in trainval:
- file_trainval.write(name)
- if i in train:
- file_train.write(name)
- else:
- file_val.write(name)
- else:
- file_test.write(name)
- file_trainval.close()
- file_train.close()
- file_val.close()
- file_test.close()
1.2 通过voc_label.py得到适合yolov8需要的txt
- # -*- coding: utf-8 -*-
- import xml.etree.ElementTree as ET
- import os
- from os import getcwd
- sets = ['train', 'val']
- classes = ["smoke"] # 改成自己的类别
- abs_path = os.getcwd()
- print(abs_path)
- def convert(size, box):
- dw = 1. / (size[0])
- dh = 1. / (size[1])
- x = (box[0] + box[1]) / 2.0 - 1
- y = (box[2] + box[3]) / 2.0 - 1
- w = box[1] - box[0]
- h = box[3] - box[2]
- x = x * dw
- w = w * dw
- y = y * dh
- h = h * dh
- return x, y, w, h
- def convert_annotation(image_id):
- in_file = open('Annotations/%s.xml' % (image_id), encoding='UTF-8')
- out_file = open('labels/%s.txt' % (image_id), 'w')
- tree = ET.parse(in_file)
- root = tree.getroot()
- size = root.find('size')
- w = int(size.find('width').text)
- h = int(size.find('height').text)
- for obj in root.iter('object'):
- difficult = obj.find('difficult').text
- #difficult = obj.find('Difficult').text
- cls = obj.find('name').text
- if cls not in classes or int(difficult) == 1:
- continue
- cls_id = classes.index(cls)
- xmlbox = obj.find('bndbox')
- b = (float(xmlbox.find('xmin').text), float(xmlbox.find('xmax').text), float(xmlbox.find('ymin').text),
- float(xmlbox.find('ymax').text))
- b1, b2, b3, b4 = b
- # 标注越界修正
- if b2 > w:
- b2 = w
- if b4 > h:
- b4 = h
- b = (b1, b2, b3, b4)
- bb = convert((w, h), b)
- out_file.write(str(cls_id) + " " + " ".join([str(a) for a in bb]) + '\n')
- wd = getcwd()
- for image_set in sets:
- if not os.path.exists('labels/'):
- os.makedirs('labels/')
- image_ids = open('ImageSets/Main/%s.txt' % (image_set)).read().strip().split()
- list_file = open('%s.txt' % (image_set), 'w')
- for image_id in image_ids:
- list_file.write(abs_path + '/images/%s.jpg\n' % (image_id))
- convert_annotation(image_id)
- list_file.close()# -*- coding: utf-8 -*-
- import xml.etree.ElementTree as ET
- import os
- from os import getcwd
- sets = ['train', 'val']
- classes = ["smoke"] # 改成自己的类别
- abs_path = os.getcwd()
- print(abs_path)
- def convert(size, box):
- dw = 1. / (size[0])
- dh = 1. / (size[1])
- x = (box[0] + box[1]) / 2.0 - 1
- y = (box[2] + box[3]) / 2.0 - 1
- w = box[1] - box[0]
- h = box[3] - box[2]
- x = x * dw
- w = w * dw
- y = y * dh
- h = h * dh
- return x, y, w, h
- def convert_annotation(image_id):
- in_file = open('Annotations/%s.xml' % (image_id), encoding='UTF-8')
- out_file = open('labels/%s.txt' % (image_id), 'w')
- tree = ET.parse(in_file)
- root = tree.getroot()
- size = root.find('size')
- w = int(size.find('width').text)
- h = int(size.find('height').text)
- for obj in root.iter('object'):
- difficult = obj.find('difficult').text
- #difficult = obj.find('Difficult').text
- cls = obj.find('name').text
- if cls not in classes or int(difficult) == 1:
- continue
- cls_id = classes.index(cls)
- xmlbox = obj.find('bndbox')
- b = (float(xmlbox.find('xmin').text), float(xmlbox.find('xmax').text), float(xmlbox.find('ymin').text),
- float(xmlbox.find('ymax').text))
- b1, b2, b3, b4 = b
- # 标注越界修正
- if b2 > w:
- b2 = w
- if b4 > h:
- b4 = h
- b = (b1, b2, b3, b4)
- bb = convert((w, h), b)
- out_file.write(str(cls_id) + " " + " ".join([str(a) for a in bb]) + '\n')
- wd = getcwd()
- for image_set in sets:
- if not os.path.exists('labels/'):
- os.makedirs('labels/')
- image_ids = open('ImageSets/Main/%s.txt' % (image_set)).read().strip().split()
- list_file = open('%s.txt' % (image_set), 'w')
- for image_id in image_ids:
- list_file.write(abs_path + '/images/%s.jpg\n' % (image_id))
- convert_annotation(image_id)
- list_file.close()
2.3生成内容如下

3.训练结果分析
训练结果如下:
mAP@0.5 0.839
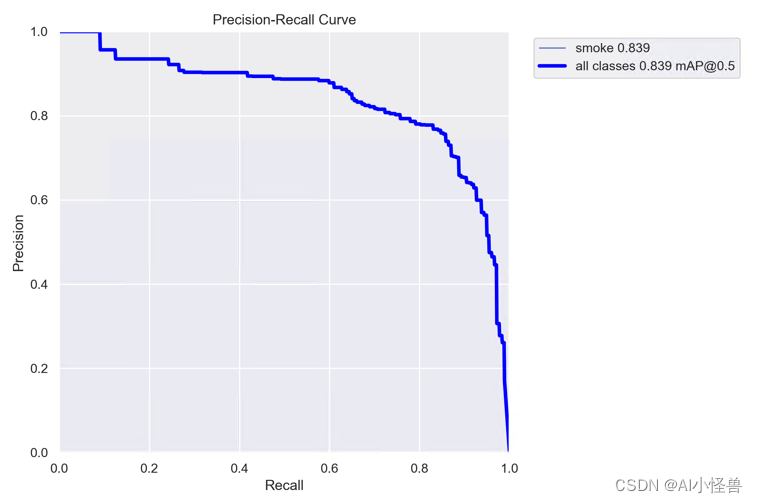
- YOLOv8n summary (fused): 168 layers, 3005843 parameters, 0 gradients, 8.1 GFLOPs
- Class Images Instances Box(P R mAP50 mAP50-95): 100%|██████████| 4/4 [00:06<00:00, 1.55s/it]
- all 199 177 0.749 0.859 0.839 0.469
4.系列篇
2)基于Yolov8的野外烟雾检测(2):多维协作注意模块MCA| 2023.9最新发布
3)基于Yolov8的野外烟雾检测(3):动态蛇形卷积,实现暴力涨点 | ICCV2023
-
-
相关阅读:
【强化学习论文合集】ICRA-2022 强化学习论文 | 2022年合集(六)
【jmeter+ant+jenkins】之搭建 接口自动化测试平台
操作系统覆盖技术与交换技术的思想
线性变换与矩阵(3Blue1Brown视频笔记)
SpringBoot项目访问后端页面404
聚合电商API接口平台:让数据成为生产力!
Redis源码与设计剖析 -- 9.字符串对象
Revit中如何彻底删除房间标记及“项目族管理”
【数据结构】栈
pnpm ERR_PNPM_ADDING_TO_ROOT
- 原文地址:https://blog.csdn.net/m0_63774211/article/details/133043120