0、前言:
- 机器学习聚类算法主要就是两类:K-means和DBSCAN
- 聚类:一种无监督的学习,事先不知道类别(相当于不用给数据提前进行标注),自动将相似的对象归到同一个簇中
1、K-means:
- 原理:先根据预先提供的k值,随机从数据中选k个点,然后分别计算所有点到这k个点之间的距离。根据它们距离k个点距离的远近对所有点进行分类,然后计算k个聚类簇的中心(用欧氏距离计算),再次对所有点计算它们距离k个聚类簇中心的距离,再次依据远近程度分类,直至k个聚类簇的中心不再变化为止。
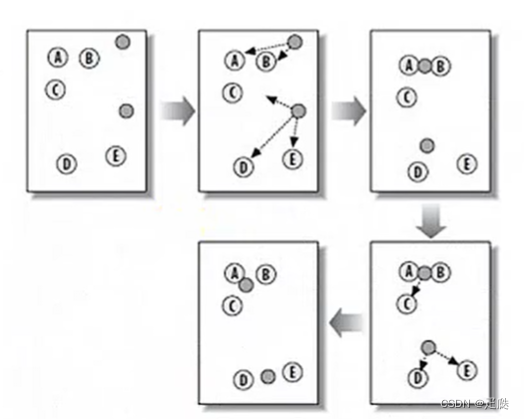
- 优缺点:优点是简单、快速,适合常规数据集,缺点是k值难确定,很难发现任意形状的簇。
- 重要参数:n_clusters:聚类簇的个数(相当于k值)
- 重要属性:cluster_centers_:聚类中心点的坐标;labels_:每个样本点的标签
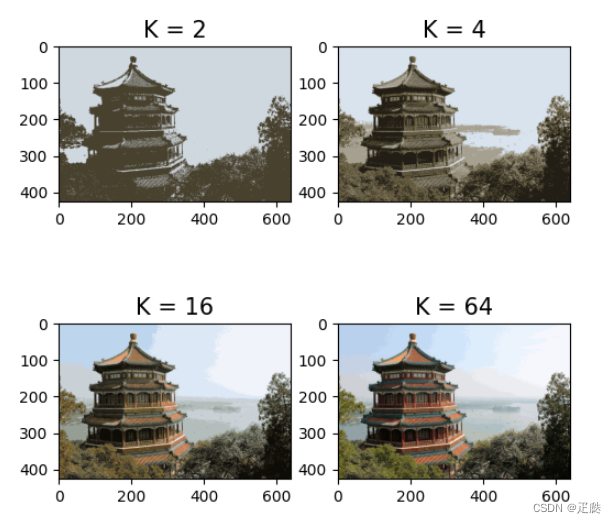
- 应用实例:图片压缩
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
from sklearn.cluster import KMeans, DBSCAN
from sklearn.datasets import load_sample_image
china = load_sample_image('china.jpg')
china = china.reshape(-1,3)
display(china.shape)
data_train = china.copy()
np.random.shuffle(data_train)
data_train = data_train[:10000]
display(data_train.shape)
plt.figure(figsize=(2*3,2*3))
for i,k in enumerate([2,4,16,64]):
ax = plt.subplot(2,2,i+1)
km = KMeans(k,n_init='auto')
km.fit(data_train)
centers = km.cluster_centers_
label = km.predict(china)
final_img = centers[label]
final_img = final_img/256
ax.imshow(final_img.reshape(427,640,3))
ax.set_title(f'K = {k}',fontsize=15)
plt.imsave(f'./tupian{i}.png',final_img.reshape(427,640,3))
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35

2、DBSCAN:
- 原理:给定算法聚类半径和最小生成簇的样本数量,算法就会挨个计算所有样本周围的数据直到找到在聚类半径中所有的点,然后看这些点能否满足最小生成簇的样本数量,如果可以就是一个簇,否则就是噪点。

3、轮廓系数
- 1、聚类算法的评估指标:轮廓系数,其计算公式如下,bi代表当前点到其他簇内的距离中最小的距离,ai代表当前点到所属簇内最大的距离。如果最终s值接近1,说明样本i聚类合理,接近-1,说明样本i更应该分类到另外的簇,接近0,表示样本在两个簇的边界。

- 2、轮廓系数的求法:一般选用平均轮廓系数得分,轮廓系数中需要两个参数(data和labels):数据样本和数据样本对应的标签,所以一般是训练完聚类模型之后才能算出轮廓系数的得分。

- 轮廓系数作用:对于K-means算法,通过遍历可能的k值,然后比较k值大小,轮廓系数越大说明k值越合适。对于DBSCAN算法,可以通过遍历半径参数,同理轮廓系数越大说明参数越合适。