-
Hive 数据仓库介绍

目录
一、Hive 概述
1.1 Hive产生的原因
1)方便对文件及数据的元数据进行管理,提供统一的元数据管理方式
2)提供更加简单的方式来访问大规模的数据集,使用SQL语言进行数据分析
1.2 Hive是什么?
官网的解析:The Apache Hive ™ data warehouse software facilitates reading, writing, and managing large datasets residing in distributed storage using SQL. Structure can be projected onto data already in storage. A command line tool and JDBC driver are provided to connect users to Hive.
hive是一个构建在Hadoop上的数据仓库工具(框架)。
可以将结构化的数据文件映射成一张数据表,并可以使用类sql的方式来对这样的数据文件进行读,写以及管理(包括元数据)。1.3 Hive 特点
Hive具有如下特点:
1)Hive是一个构建于Hadoop顶层的 数据仓库工具 ,可以查询和管理PB级别的分布式数据。
2)支持大规模数据存储、分析,具有良好的可扩展性
3)某种程度上可以看作是 用户编程接口 ,本身不存储和处理数据。
4)依赖分布式文件系统HDFS存储数据。
5)依赖分布式并行计算模型MapReduce处理数据。
6)定义了简单的类似SQL 的查询语言——HiveQL。
7)用户可以通过编写的HiveQL语句运行MapReduce任务。
8)可以很容易把原来构建在关系数据库上的数据仓库应用程序移植到Hadoop平台上。
9)是一个可以提供有效、合理、直观组织和使用数据的分析工具。Hive具有的特点非常适用于 数据仓库 。
1)采用批处理方式处理海量数据。数据仓库存储的是静态数据,对静态数据的分析适合采用批处理方式,不需要快速响应给出结果,而且数据本身也不会频繁变化;
2)提供适合数据仓库操作的工具。Hive本身提供了一系列对数据进行提取、转换、加载(ETL)的工具,可以存储、查询和分析存储在Hadoop中的大规模数据。这些工具能够很好地满足数据仓库各种应用场景;
3)支持MapReduce,Tez,Spark等多种计算引擎;
4)可以直接访问HDFS文件以及HBase;
5)易用易编程。1.4 Hive生态链关系
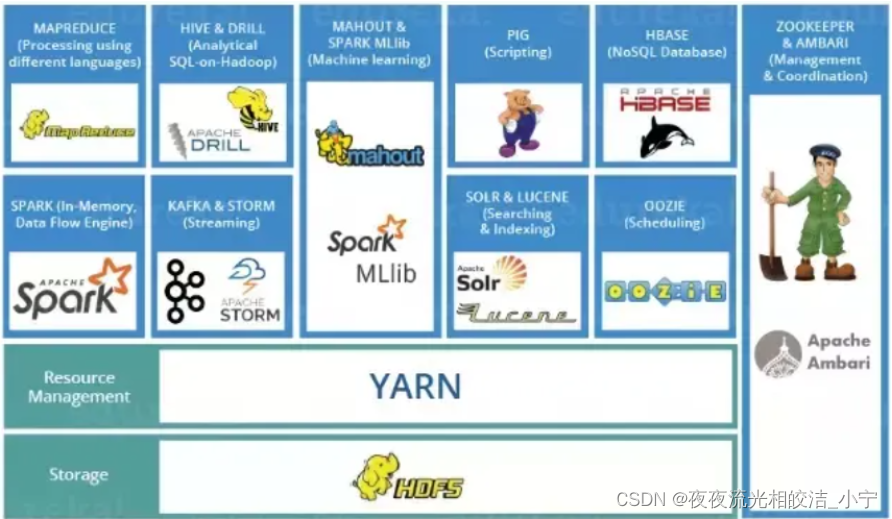
Hive是Hadoop生态的一员,依托于Hadoop生态,赋予了其强大的生命力。Hive与其他Hadoop组件的关系为:
1)Hive依赖于HDFS 存储数据
2)Hive依赖于MapReduce 处理数据
3)在某些场景下Pig可以作为Hive的替代工具
4)HBase 提供数据的实时访问二、Hive架构
2.1 架构图

2.2 架构组件说明
2.2.1 Interface
Hive提供三个主要的用户接口。
2.2.1.1 CLI
CLI 是Shell命令行接口,提供交互式 SQL 查询
2.2.1.2 JDBC/ODBC
JDBC/ODBC 是Hive的Java数据接口实现,使远程客户端可以通过Hiveserver2查询数据;例如 beeline 方式
2.2.1.3 WebUI
用户可以通过浏览器访问Hive页面,查看Hive使用的信息
2.2.2 MetaData
Hive将元数据存储在RMDB中,如MySQL\Derby\Postgresql。元数据包括表结构、表名、列属性、分区信息、权限信息及Location等信息。
2.2.3 MetaStore
Hive提供的元数据查询服务,通过MetaStore管理、操作元数据
2.2.4 Hiveserver2
基于thrift的跨平台、跨编程语言的Hive查询服务。为Hive客户端提供远程访问、查询服务
2.2.5 Driver
Hive 的核心是驱动引擎, 驱动引擎由解释器、编译器、优化器、执行器四部分组成
2.2.5.1 解释器
解释器的作用是将 HiveSQL 语句转换为抽象语法树(AST Abstract-Syntax-Tree)
2.2.5.2 编译器
编译器是将语法树编译为逻辑执行计划
2.2.5.3 优化器
优化器是对逻辑执行计划进行优化
2.2.5.4 执行器
执行器是调用底层的运行框架执行逻辑执行计划
三、Hive的工作原理
3.1 工作流程及原理图
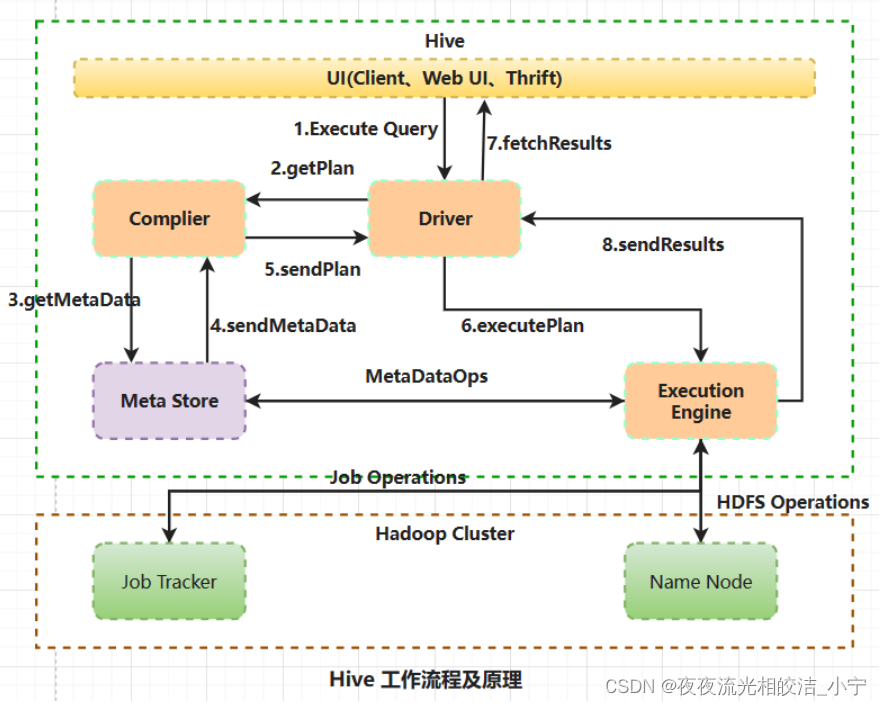
3.2 工作流程说明
1) 用户把查询任务提交给Driver驱动程序
2)驱动程序将Hql发送给编译器Compiler
3)编译器Compiler根据用户查询任务去MetaStore中获取需要的Hive的元数据信息
4)编译器Compiler得到元数据信息,对任务进行编译
4.1)依据Antlr语法规则,解析HiveQL并转换为AST抽象语法树
4.2)遍历AST抽象语法树,抽象出查询的基本组成单元QueryBlock(查询块)
4.3)依据QueryBlock生成逻辑执行计划
4.4)优化、重写逻辑执行计划,合并不必要的ReduceSinkOperator,降低shuffle
4.5)依据逻辑执行计划生成物理执行计划,也就是Hive Job的Task树(默认是MapReduce Job)
4.6)优化、重写物理执行计划5)将最终的执行计划(Hive Job)提交给Driver。到此为止,查询解析和编译完成
6)Driver将执行计划(Hive Job)转交给ExecutionEngine去执行
7)在Yarn上,执行作业的过程默认是一个MapReduce任务
7.1)执行引擎发送作业给JobTracker
7.2)JobTracker将task下发给到TaskTracker执行
7.3)task读、写HDFS数据四、Hive的优缺点
4.1 优点
1)高可靠、高容错:HiveServer采用集群模式。双MetaStor。超时重试机制。
2)类SQL:类似SQL语法,内置大量函数。
3)可扩展:自定义存储格式,自定义函数。
4)多接口:Beeline,JDBC,ODBC,Python,Thrift。4.2 缺点
1)延迟较高:默认MR为执行引擎,MR延迟较高。
2)不支持雾化视图:Hive支持普通视图,不支持雾化视图。Hive不能再视图上更新、插入、删除数据。
3)不适用OLTP:暂不支持列级别的数据添加、更新、删除操作。
4)暂不支持存储过程:当前版本不支持存储过程,只能通过UDF来实现一些逻辑处理。五、Hive数据模型
Hive中元数据(即对数据的描述,包括表,表的列及其它各种属性)一般存储在MySQL等数据库中的,因为这些数据要不断的更新,修改,不适合存储在HDFS中。而真正的数据是存储在HDFS中,这样更有利于对数据做分布式运算。
Hive中主要包括四类数据模型:
数据库:Hive 中的DB类似传统数据库的DataBase。
表 :Hive中的表和关系型数据库中的表在概念上很类似,每个表在HDFS中都有相应的目录用来存储表的数据;
分区 :在Hive中,表的每一个分区对应表下的相应目录,所有分区的数据都是存储在对应的目录中;
桶 :对指定的列计算其hash,根据hash值切分数据,目的是为了并行,每一个桶对应一个文件(注意和分区的区别)。
5.1 数据库
类似传统数据库的DataBase,默认数据库"default"。
数据库切换指令:use xxx;
创建数据库:
hive > create database test_dw;
5.2 表
Hive 表跟关系数据库里面的表类似。逻辑上,数据是存储在 Hive 表里面的,而表的元数据描述了数据的布局。我们可以对表执行过滤,关联,合并等操作。在 Hadoop 里面,物理数据一般是存储在 HDFS 的,而元数据是存储在关系型数据库的。
Hive 有下面两种表:内部表、外部表。当我们在 Hive 创建表的时候,Hive 将以默认的方式管理表数据,也就是说,Hive 会默认把数据存储到 /user/hive/warehouse 目录里面。除了内部表,我们可以创建外部表,外部表需要指定数据的目录。
5.2.1 内部表
当我们把数据 load 到内部表的时候,Hive 会把数据存储在 /user/hive/warehouse 目录下(warehouse地址是在 hive-site.xml 中由hive.metastore.warehouse.dir属性指定的数据仓库的目录)。
- CREATE TABLE managed_table (dummy STRING);
- LOAD DATA INPATH '/user/tom/data.txt' INTO table managed_tabl
根据上面的代码,Hive 会把文件 data.txt 文件存储在 managed_table 表的 warehouse 目录下,即 hdfs://user/hive/warehouse/managed_table 目录。
如果我们用 drop 命令把表删除,这样将会把表以及表里面的数据和表的元数据都一起删除。
DROP TABLE managed_table5.2.2 外部表
外部表与内部表的行为上有些差别。我们能够控制数据的创建和删除。删除外部表的时候,Hive 只会删除表的元数据,不会删除表数据。数据路径是在创建表的时候指定的:
- CREATE EXTERNAL TABLE external_table (dummy STRING)
- LOCATION '/user/tom/external_table';
- LOAD DATA INPATH '/user/tom/data.txt' INTO TABLE external_table;
利用 **EXTERNAL** 关键字创建外部表,Hive 不会去管理表数据,所以它不会把数据移到 /user/hive/warehouse 目录下。甚至在执行创建语句的时候,它不会去检查建表语句中指定的外部数据路径是否存在。这个是比较有用的特性,我们可以在表创建之后,再创建数据。
外部表还有一个比较重要的特性,上面有提到的,就是删除外部表的时候,Hive 只有删除表的元数据,而不会删除表数据。
5.3 分区
为了提高查询数据的效率,Hive 提供了表分区机制。分区表基于分区键把具有相同分区键的数据存储在一个目录下,在查询某一个分区的数据的时候,只需要查询相对应目录下的数据,而不会执行全表扫描,也就是说,Hive 在查询的时候会进行分区剪裁。每个表可以有一个或多个分区键。
创建分区表语法:
- CREATE TABLE table_name (column1 data_type, column2 data_type)
- PARTITIONED BY (partition1 data_type, partition2 data_type,….);
下面通过一个例子来更好的理解分区概念:
假如你有一个存储学生信息的表,表名为 student_details,列分别是 student_id,name,department,year 等。现在,如果你想基于 department 列对数据进行分区。那么属于同一个 department 的学生将会被分在同一个分区里面。在物理上,一个分区其实就是表目录下的一个子目录。
假如你在 student_details 表里面有三个 department 的数据,分别为 EEE,ECE 和 ME。那么这个表总共就会有三个分区,也就是图中的绿色方块部分。对于每个 department ,您将拥有与该 department 相关的所有数据,这些数据位于表目录下的单独子目录中。
假如所有 department = EEE 的学生数据被存储在 /user/hive/warehouse/student_details/department=EEE 目录下。那么查询 department 为 EEE 的学生信息,只需要查询 EEE 目录下的数据即可,不需要全表扫描,这样查询的效率就比较高。而在真实生产环境中,你需要处理的数据可能会有几百 TB,如果不分区,在你只需要表的其中一小部分数据的时候,你不得不走全表扫描,这样的查询将会非常慢而且浪费资源,可能 95% 的数据跟你的查询语句并没有关系。
5.4 桶
对指定的列计算其hash,根据hash值切分数据,目的是为了并行,每一个桶对应一个文件(注意和分区的区别)。
Hive 可以对每一个表或者是分区,进一步组织成桶,也就是说桶是更为细粒度的数据范围划分。Hive 是针对表的某一列进行分桶。Hive 采用对表的列值进行哈希计算,然后除以桶的个数求余的方式决定该条记录存放在哪个桶中。分桶的好处是可以获得更高的查询处理效率。使取样更高效。
分桶表创建命令:
- CREATE TABLE table_name
- PARTITIONED BY (partition1 data_type, partition2 data_type,….)
- CLUSTERED BY (column_name1, column_name2, …)
- SORTED BY (column_name [ASC|DESC], …)]
- INTO num_buckets BUCKETS;
每个桶只是表目录或者分区目录下的一个文件,如果表不是分区表,那么桶文件会存储在表目录下,如果表是分区表,那么桶文件会存储在分区目录下。所以你可以选择把分区分成 n 个桶,那么每个分区目录下就会有 n 个文件。从上图可以看到,每个分区有 2 个桶。因此每个分区就会有 2 个文件,每个文件将会存储该分区下的数据。
六、字段类型分类
Hive支持原始数据类型和复杂类型,原始类型包括数值型,Boolean,字符串,时间戳。复杂类型包括数组,map,struct。官网地址:https://cwiki.apache.org/confluence/display/hive/languagemanual+types

6.1基本类型
6.1.1 Numeric Type
数值类下包含:tinyint、small int、int/integer、bigint、float、double、numertic、decimal
6.1.2 Date/Time Type
时间类型:timestamp、date、interval
6.1.3 Misc Type
Boolean 、BINARY
6.1.4 String Type
字符串类型:String 、varchar、char
6.2 复杂类型
arrays、maps、structs、union
七、查询语言分类
7.1 DDL
大致包含以下部分内容:
* CREATE DATABASE/SCHEMA, TABLE, VIEW, FUNCTION, INDEX
* DROP DATABASE/SCHEMA, TABLE, VIEW, INDEX
* TRUNCATE TABLE
* ALTER DATABASE/SCHEMA, TABLE, VIEW
* MSCK REPAIR TABLE (or ALTER TABLE RECOVER PARTITIONS)
* SHOW DATABASES/SCHEMAS, TABLES, TBLPROPERTIES, VIEWS, PARTITIONS, FUNCTIONS, INDEX[ES], COLUMNS, CREATE TABLE
* DESCRIBE DATABASE/SCHEMA, table_name, view_name, materialized_view_name详细内容,可参考官网地址:LanguageManual DDL - Apache Hive - Apache Software Foundation
7.2 MDL
大致包含以下部分内容:
* LOAD
* INSERT
* into Hive tables from queries
* into directories from queries
* into Hive tables from SQL
* UPDATE
* DELETE
* MERGE详细内容,可参考官网地址:LanguageManual DML - Apache Hive - Apache Software Foundation
7.3 DQL
Hive select 常规语法与 Mysql 等 RDBMS SQL 几乎无异,大致包含以下部分内容:
* Select Syntax
* WHERE Clause
* ALL and DISTINCT Clauses
* Partition Based Queries
* HAVING Clause
* LIMIT Clause
* REGEX Column Specification
* More Select Syntax详细内容,可参考官网地址:LanguageManual Select - Apache Hive - Apache Software Foundation
今天Hive相关内容就分享到这里,如果帮助到大家,欢迎大家点赞+关注+收藏,有疑问也欢迎大家评论留言!
-
相关阅读:
获取QTextedit文本宽度
Spring Security(3)
npm使用国内淘宝镜像的方法
OpenRoads地形模型添加(增补)地形点
肉苁蓉苷F与牛血清白蛋白偶联物 Cistanoside F-BSA
vuex 学习之路
【机器学习】梯度下降法与牛顿法【Ⅲ】拟牛顿法
如何在CentOS上安装SQL Server数据库并通过内网穿透工具实现远程访问
深入理解Linux网络笔记(二):内核和用户进程协作之阻塞方式
(C语言)printf打印的字符串太长了,我想分两行!
- 原文地址:https://blog.csdn.net/qq_25409421/article/details/133048556