-
【hive】列转行—collect_set()/collect_list()/concat_ws()函数的使用场景
一、collect_set()/collect_list()
在 Hive 中想实现按某字段分组,对另外字段进行合并,可通过collect_list()或者collect_set()实现。
-
collect_set()函数与collect_list()函数:列转行专用函数,都是将分组中的某列转为一个数组返回。有时为了字段拼接效果,多和concat_ws()函数连用。
-
collect_set()与collect_list()的区别:
- collect_list()函数 - - 不去重
- collect_set()函数 - - 去重
有点类似于Python中的列表与集合。
二、实际运用
创建测试表及插入数据
drop table test_1; create table test_1( id string, cur_day string, rule string ) row format delimited fields terminated by ','; insert into test_1 values ('a','20230809','501'),('a','20230811','502'),('a','20230812','503'),('a','20230812','501'),('a','20230813','512'),('b','20230809','511'),('b','20230811','512'),('b','20230812','513'),('b','20230812','511'),('b','20230813','512'),('b','20230809','511'),('c','20230811','512'),('c','20230812','513'),('c','20230812','511'),('c','20230813','512');- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
把同一分组的不同行的数据聚合成一个行
举例1:按照id,cur_day分组,取出每个id对应的所有rule(不去重)。
select id,cur_day,collect_list(rule) as rule_total from test_1 group by id,cur_day order by id,cur_day;- 1

举例2:按照id,cur_day分组,取出每个id对应的所有rule(去重)。select id,cur_day,collect_set(rule) as rule_total from test_1 group by id,cur_day order by id,cur_day;- 1

用下标可以随机取某一个
select id,cur_day,collect_list(rule)[0] as rule_one from test_1 group by id,cur_day order by id,cur_day; select id,cur_day,collect_set(rule)[0] as rule_one from test_1 group by id,cur_day order by id,cur_day;- 1
- 2
- 3

聚合后的中的值用‘|’分隔开
select id,cur_day,concat_ws('|',collect_list(rule)) as rule_total from test_1 group by id,cur_day order by id,cur_day; select id,cur_day,concat_ws('|',collect_set(rule)) as rule_totalfrom test_1 group by id,cur_day order by id,cur_day;- 1
- 2
- 3

使用collect_set()/collect_list()使得全局有序
现在需求:严格按照同一个id进行分组,规则按时间升序排序,使用collect_list()将时间与规则按升序排序且一 一 对应展示出来。
1.原数据详情:
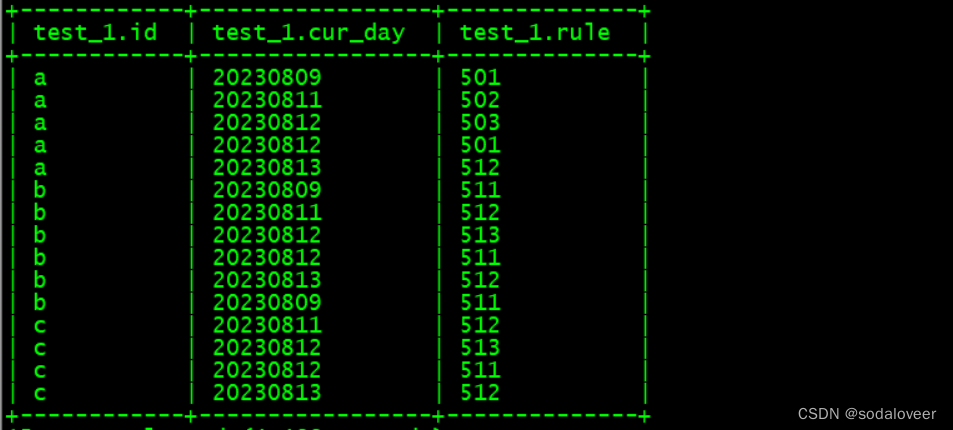
2.要求输出结果如下:按id分组,将rule按cur_day升序排序,将cur_day,rule放在一个列表中,并且列表中cur_day与rule是按升序一一对应的关系。

3.实现思路:将其使用row_number()over(partition by id order by cur_day as)排序,然后再使用collect_list()或者collect_list()/collect_set()进行聚合就可以了。
drop table test_2 ; create table test_2 as select id,collect_list(cur_day),collect_list(rule) from ( select t.id,t.cur_day,t.rule,row_number() over(partition by id order by cur_day asc) rn from test_1 t )t group by id ; select * from test_2 group by id order by id;- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8

4.发现问题:cur_day数组内的时间并没有按照升序排序输出。
5.原因分析:
- HiveQL执行时,大部分情况都会转换为MR来执行,当开户多个Mapper的时候,Mapper1可能处理的是id为a,cur_day排名为1、2、3的数据,Mapper2可能处理的id为a,cur_day排名为4、5、6的数据。
- collect_list()的底层是ArrayList来实现的,当put到ArrayList的时候,不一定是哪个Mapper先,哪个Mapper后,所以会出现20230811、20230812、20230813在20230809前面的情况。所以,row_number() over(partitiion by order by) 与collect_list一起使用只能实现局部有序,不能实现全局有序。
6.解决方案:
- 方法一:全局 order by
drop table test_2 ; create table test_2 as select id,collect_list(cur_day),collect_list(rule) from ( select t.* from( select t.id,t.cur_day,t.rule,row_number() over(partition by id order by cur_day asc) rn from test_1 t ) t order by rn )t group by id ; select * from test_2 group by id order by id;- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10

- 方法二:distribute by + order by
select id,collect_list(cur_day),collect_list(rule) from( select t.id,t.cur_day,t.rule ,row_number()over(partition by id order by cur_day asc) as rn from( select t.id,t.cur_day,t.rule from test_1 t distribute by id sort by cur_day asc )t )t group by id order by id;- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14

- 方法三:sort_array (只支持升序)
select id,concat_ws(',',collect_list(cur_day)),regexp_replace(concat_ws(',',sort_array(collect_list(concat_ws('|' ,lpad(cast(rn as string),2,'0') ,rule)))),'\\d+\\|','') from( select t.* from( select id,cur_day,rule, row_number()over(partition by id order by cur_day asc) as rn from test_1 )t order by rn )t group by id order by id;- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11

上面代码用到相关函数解析:
-
lpad(str,len,pad) 函数:这个是对排序值(也就是rule)来补位的,当要排序的值过大时,因为sort_array是按顺序对字符进行排序(即11会在2的前面),所以可以使用此函数补位(即将1,2,3,4变成01,02,03,04),这样就能正常排序了。
- 第一个参数:你要补齐的字段值
- 第二个参数:补齐之后总共的位数
- 第三个参数:你要在左边填充的字符
-
regexp_replace(strA,strB,strC) 函数:将字符串A中的符合JAVA正则表达式B的部分替换为C,即排序之前将序号使用,跟需要的字段拼接,而排序之后,需要将序号和:去掉
-
sort_array(expr[, ascendingOrder])默认是升序排序,但其中可以带参数,默认为True,即按升序,如果输入False,就会按降序排序。
- expr:一个可排序元素的 ARRAY 表达式。
- ascendingOrder:可选的 BOOLEAN 表达式,默认值为 True,即按升序。
select id ,concat_ws(',',sort_array(collect_list(concat_ws('|' ,lpad(cast(rn as string),2,'0') ,rule)))) as middle_value --中间值 ,regexp_replace(concat_ws(',',sort_array(collect_list(concat_ws('|' ,lpad(cast(rn as string),2,'0') ,rule)))),'\\d+\\|','') as result_values --最终结果 from( select t.* from( select id,cur_day,rule, row_number()over(partition by id order by cur_day asc) as rn from test_1 )t order by rn )t group by id order by id;- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
-
-
相关阅读:
2024深圳杯(东北三省)A题多个火箭残骸的准确定位原创论文分享
[SWPUCTF 2023 秋季新生赛]——Web方向 详细Writeup
图解系列 图解Kafka之Producer
3D模型格式汇总
猿创征文|Aixos的引入与基本使用
Linux 线程控制 —— 线程清理 pthread_cleanup_push
Mysql进阶-视图篇
蓝桥杯国赛算法复习
MySql 数据库【子查询】
MybatisPlus 实体类与数据库表映射关系&MybatisPlus:ORM思想
- 原文地址:https://blog.csdn.net/sodaloveer/article/details/132814272