-
Flink 环境对象
前言
本文隶属于专栏《大数据技术体系》,该专栏为笔者原创,引用请注明来源,不足和错误之处请在评论区帮忙指出,谢谢!
思维导图
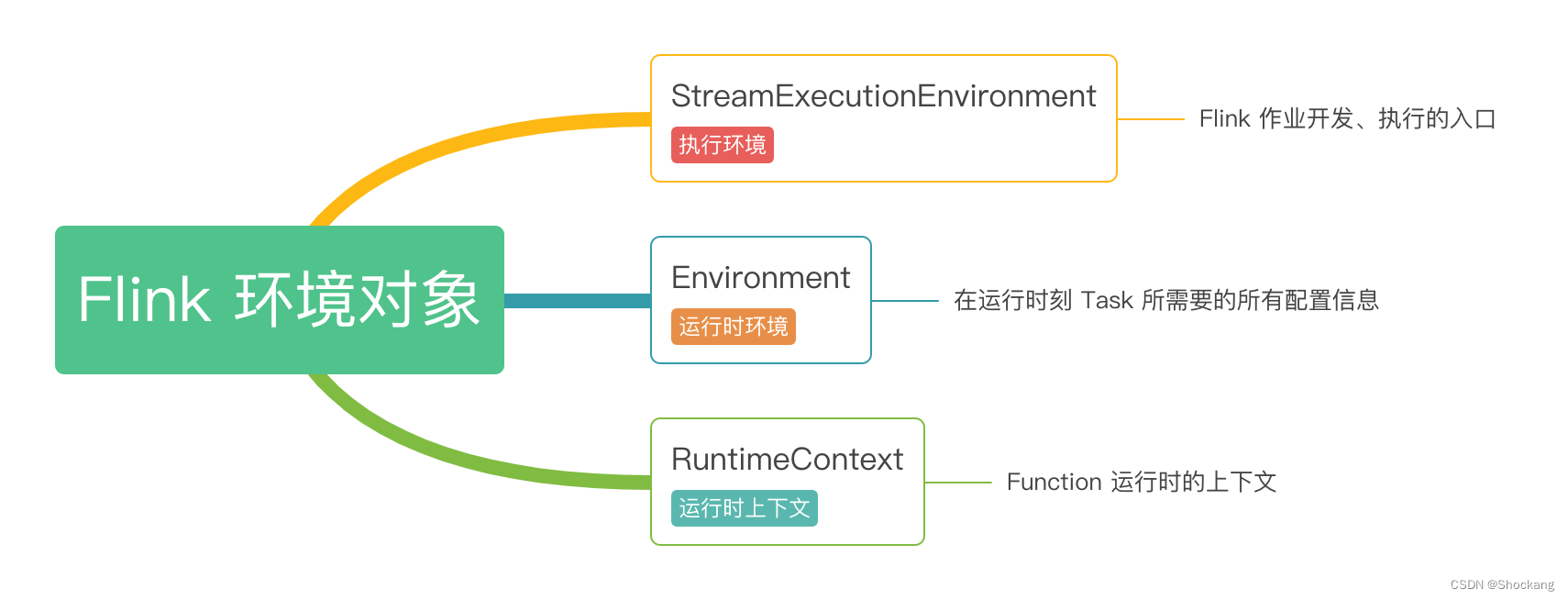
总览
StreamExecutionEnvironment 是Flink 应用开发时的概念,表示流计算作业的执行环境, 是作业开发的入口、数据源接口、生成和转换 DataStream 的接口、数据 Sink 的接口、作业配置接口、作业启动执行的入口。
Environment 是运行时作业级别的概念,从 StreamExecution Environment 中的配置信息衍生而来。
进人到 Flink 作业执行的时刻,作业需要的是相关的配置信息,如作业的名称、并行度、作业编号 Job ID、监控的 Metric、容错的配置信息、IO 等,用 StreamExecutionRuntime 对象就不合适了,很多 API 是不需要的,所以在 Flink 中抽象出了 Environment 作为运行时刻的上下文信息。
RuntimeContext 是运行时 Task 实例级别的概念。
Environment 本身仍然是比较粗粒度作业级别的配置,对于每一个task 而言,其本身有更细节的配置信息,所以 Flink 又抽象了RuntimeContext, 每一个Task 实例有自己的 RuntimeContext, RuntimeContext 的信息实际上是 StreamExecutionEnvironment 中配置信息和算子级别信息的综合。
3种环境对象之问的关系如下图所示。
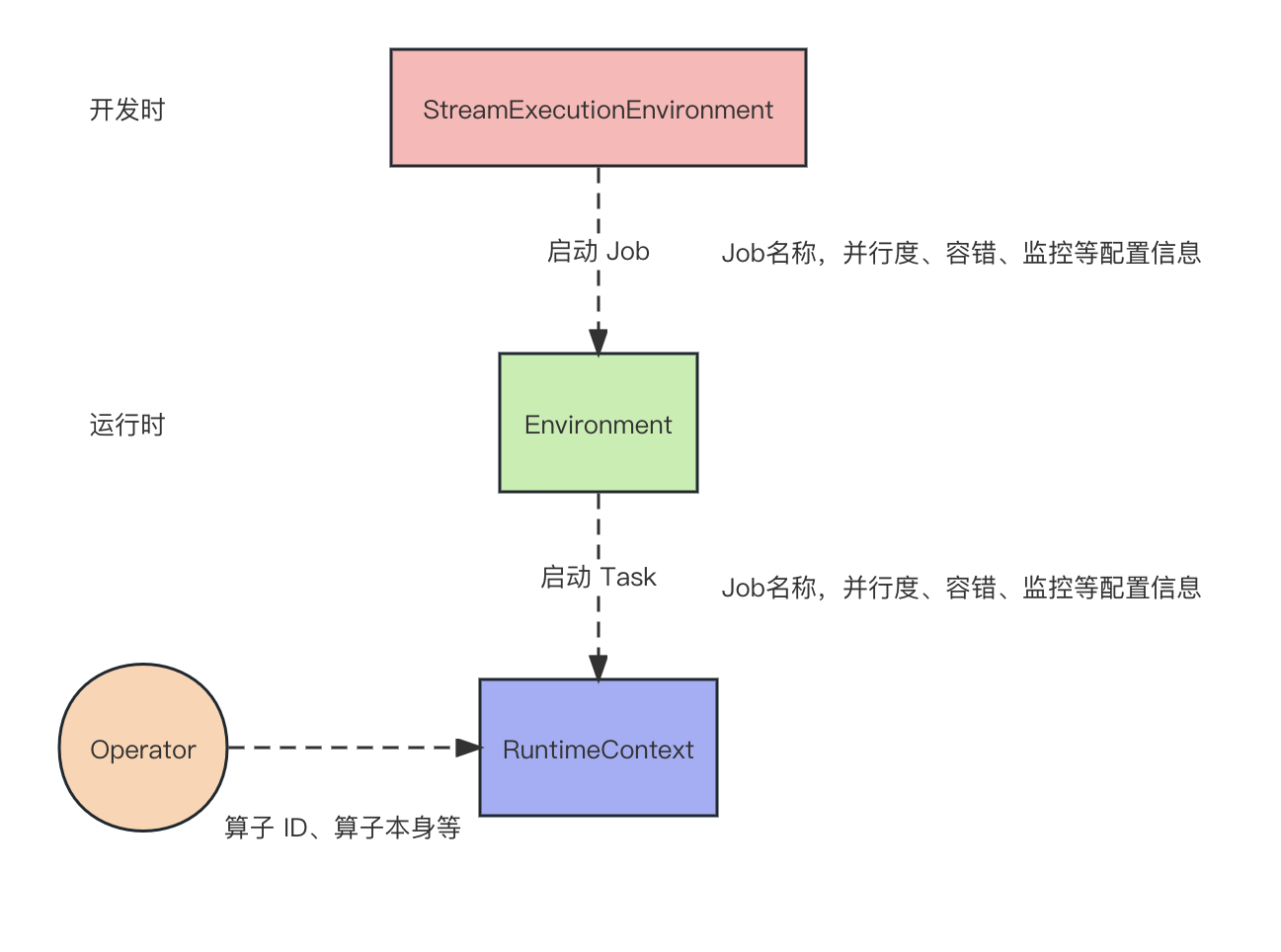
对于开发者而言,StreamExecutionEnvironment 在作业开发的 Main 函数中使用,RuntimeContext 在 UDF 开发中使用,Environment 则起到街接 StreamExecutionEnvironment 和 RuntimeContext 的作用。
执行环境(StreamExecutionEnvironment)

执行环境是 Flink 作业开发、执行的入口,当前版本 Flink 的批流在 API 并没有统一所以有流计算(StreamExecutionEnvironment)和批处理 (ExecutionEnvironment)两套执行环境。
StreamExecutionEnvironment 是 Flink 流计算应用的执行环境,是Flink 作业开发和启动执行的人口,开发者对 StreamExecutionEnvironment 的实现是无感知的。
1. LocalStreamEnvironment
本地执行环境,在单个 JVM 中使用多线程模拟 Flink 集群。
一般用作本地开发、调试。使用 Idea 之类的 IDE 工具,可以比较方便地在代码中设置断点调试和单元测试。如果测试没有问题,就可以提交到真正的生产集群。
工作流程
- 执行 Flink 作业的 Main 函数生成 StreamGraph,转化为 JobGraph
- 设置任务运行的配置信息。
- 根据配置信息启动对应的 LocalFlinkMiniCluster
- 根据配置信息和 miniCluster 生成对应的 MiniClusterClient
- 通过 MiniClusterClient 提交 JobGraph 到 MiniCluster
2. RemoteStreamEnvironment
在大规模数据中心中部署的 Flink 生成集群的执行环境。
当将作业发布到 Flink 集群的时候,使用 RemoteStreamEnvironment
工作流程
- 执行 Flink 作业的 Main 函数生成 StreamGraph,转化为JobGraph
- 设置任务运行的配置信息。
- 提交 JobGraph 到远程的 Flink 集群。
3. StreamContextEnvironment
在 Cli 命令行或者单元测试时候会被使用,执行步骤同上。
4. StreamPlanEnvironment
在 Flink web UI 管理界面中可视化展现 Job 的时候,专门用来生成执行计划(实际上就是 StreamGraph)。
5. ScalaShellStreamEnvironment
这是 Scala shell 执行环境,可以在命令行中交互式开发 Flink 作业。
工作流程
- 校验部署模式,目前 Scala Shell 仅支持 attached 模式。
- 上传每个作业需要的Jar文件。
其余步骤与 RemoteStreamEnvironment 类似。
运行时环境(Environment)

运行时环境在 Flink 中叫作 Environment,是Flink 运行时的概念,该接口定义了在运行时刻 Task 所需要的所有配置信息,包括在静态配置和调度器调度之后生成的动态配置信息。
Environment 有两个实现类 RuntimeEnvironment 和 SavepointEnvironment
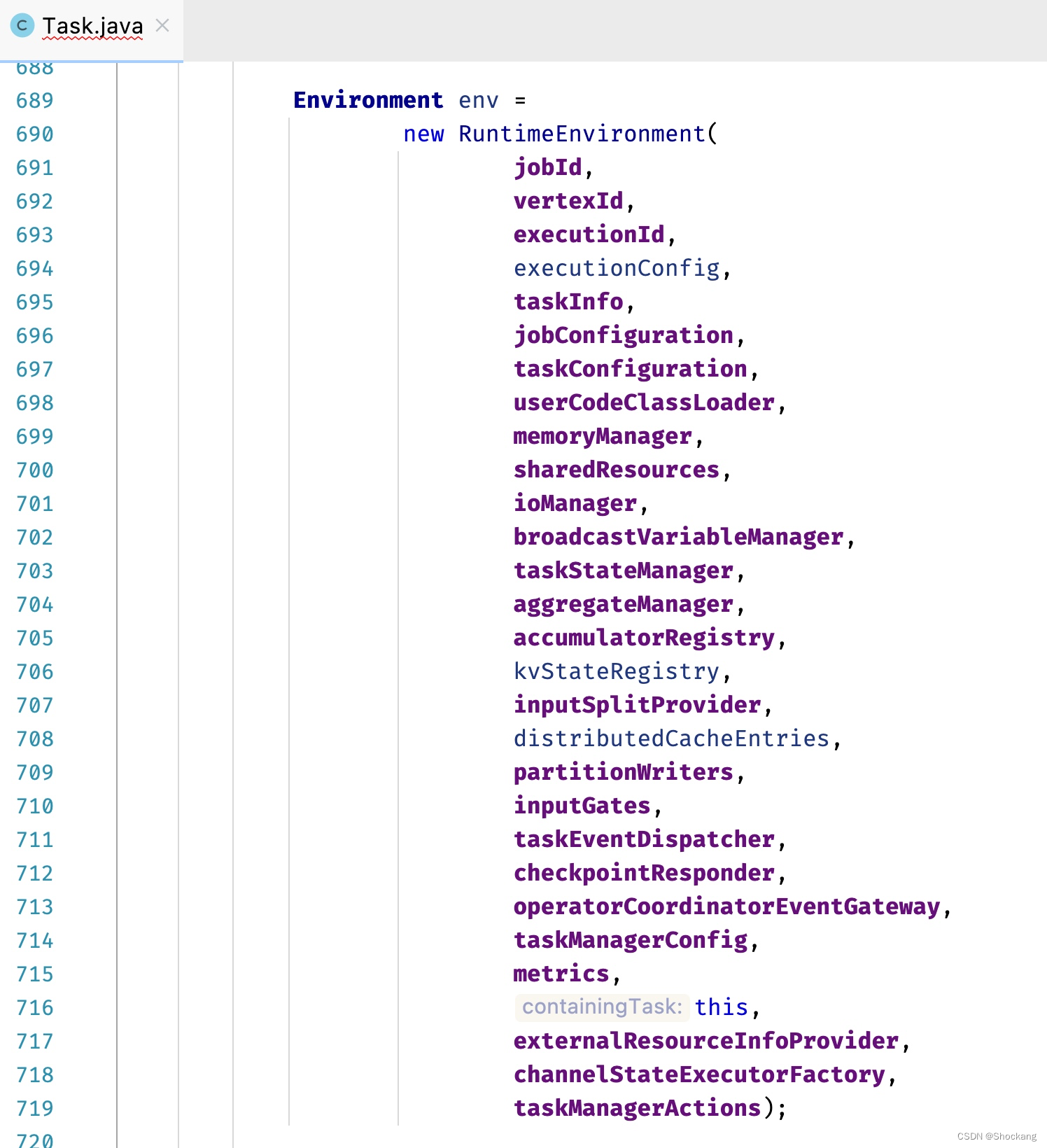
1. RuntimeEnvironment
在 Task 开始执行时进行初始化,把 Task 运行相关的信息都封装到该对象中,其中不光包含了配置信息,运行时的各种服务也会被包装到其中,如下图的代码清单所示。
2. SavepointEnvironment
SavepointEnvironment 是 Environment 的最小化实现,在状态处理器的 API 中使用, Flink 1.9 版本引人的状态处理器(State Processor) API 真正改变了这一现状,实现了对应用程序状态的操作。
该功能借助 Dataset API 扩展了输人和输出格式以读写保存点或检查点数据。
由于 DataSet 和Table API 的互通性,用户甚至可以使用关系表 API 或 SQL, 查询来分析和处理状态数据。
运行时上下文(RuntimeContext)
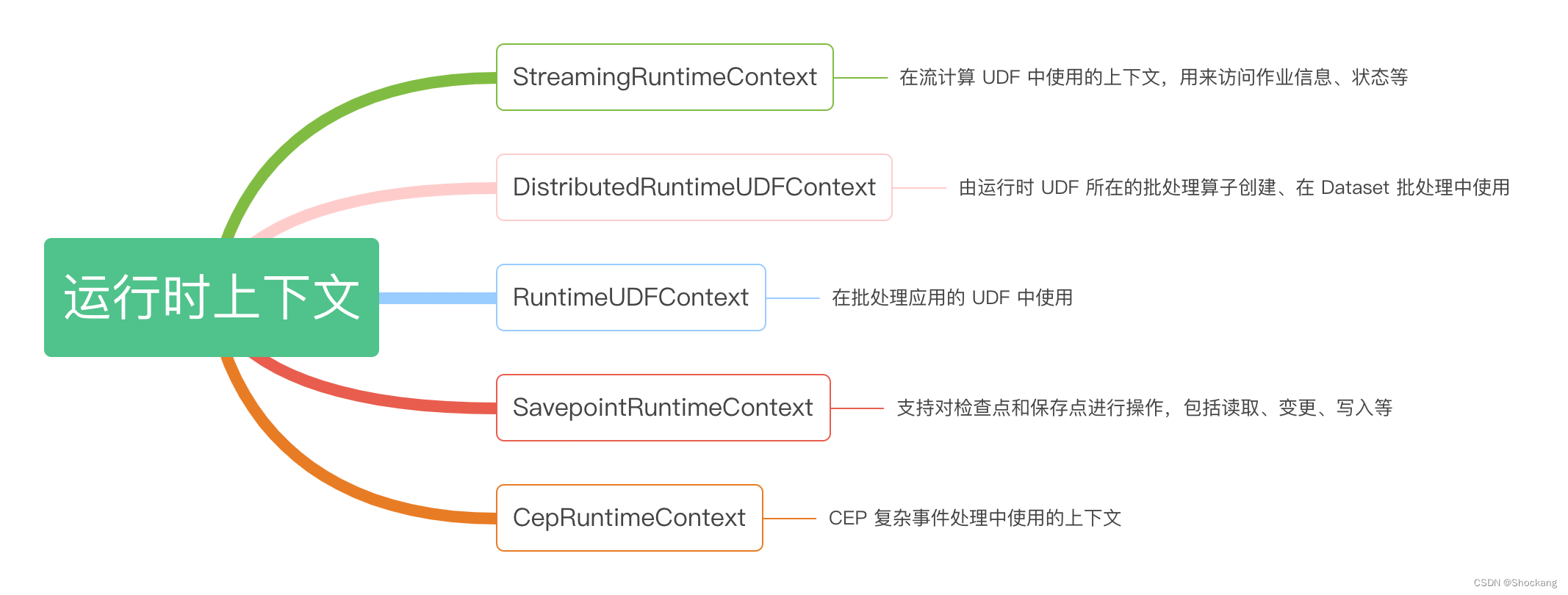
RuntimeContext 是 Function 运行时的上下文,封装了 Function 运行时可能需要的所有信息,让 Function 在运行时能够获取到作业级别的信息,如并行度相关信息、Task 名称、执行配置信息
(ExecutionConfig)、State 等。Function 的每个实例都有一个RuntimeContext 对象,在RichFunction 中通过 getRunctionContext()可以访问该对象。
不同的使用场景中有不同的 RuntimeContext,具体如下。
- StreamingRuntimeContext:在流计算 UDF 中使用的上下文,用来访问作业信息、状态等。
- DistributedRuntimeUDFContext:由运行时 UDF 所在的批处理算子创建、在 Dataset 批处理中使用。
- RuntimeUDFContext:在批处理应用的 UDF 中使用。
- SavepointRuntimeContext: Fink 1.9 版本引人了一个很重要的状态处理 API,这个框架支持对检查点和保存点进行操作,包括读取、变更、写入等。
- CepRuntimeContext:CEP 复杂事件处理中使用的上下文。
另外,在一些场景中不需要将 RuntimeContext 中的信息完全暴露,只需要其中某一部分信息,或者需要使用 RuntimeContext 之外的一些其他信息,这两种情况下,需要对 RuntimeContext 再进行一次封装。
总结
Flink中的环境对象可以分为三种:
1. 执行环境(StreamExecutionEnvironment)
执行环境是Flink作业开发和执行的入口,当前版本中有流计算的StreamExecutionEnvironment和批处理的ExecutionEnvironment两种。执行环境负责作业开发期间的各种功能,比如定义数据源、生成和转换DataStream、配置数据Sink、设置作业配置信息等。常见的执行环境包括LocalStreamEnvironment(本地多线程模拟)、RemoteStreamEnvironment(远程集群)等。
2. 运行时环境(Environment)
运行时环境是作业执行期间的概念,包含了任务运行所需的各种配置信息,包括静态配置和动态配置。它由执行环境的配置衍生而来,提供了比执行环境更细粒度的环境信息。Flink中的运行时环境主要有两种实现:RuntimeEnvironment和SavepointEnvironment。前者包含任务运行时各种服务和配置信息,后者是精简版,用于状态处理器API。
3. 运行时上下文(RuntimeContext)
运行时上下文封装了函数实例运行时需要的各种信息,如作业并行度、任务名、执行配置、状态等。每个函数实例都有对应的运行时上下文对象。Flink根据不同使用场景提供了多种上下文,如流计算中使用StreamingRuntimeContext,批处理使用DistributedRuntimeUDFContext等。
三者之间,执行环境生成运行时环境,运行时上下文集成了两者的信息。执行环境用于开发阶段,运行时上下文用于函数开发。
三者分工明确,合理封装了不同粒度的环境信息,为任务开发、执行和监控提供支持。
-
相关阅读:
【CSPNet】《CSPNet:A New Backbone that can Enhance Learning Capability of CNN》
C语言程序的编译(预处理) —— 下
Java内部类详解
三分钟学会Sqoop安装与部署
数学建模--数据预处理
代碼隨想錄算法訓練營|第六十二天|84.柱状图中最大的矩形。刷题心得(c++)
中国首款电音音频类“山野电音”数藏发售来了!
使用Postern实现Android设备的全局代理优劣势分析
如何简单理解大数据
Ubuntu1804.5安装后的基本配置
- 原文地址:https://blog.csdn.net/Shockang/article/details/132914872