-
实训笔记——Spark计算框架
实训笔记——Spark计算框架
- Spark计算框架
- 一、Spark的概述
- 二、Spark的特点
- 三、Spark的安装部署(安装部署Spark的Cluster Manager-资源调度管理器的)
- 四、Spark程序的部署运行
- 五、Spark集群运行中三个核心角色和一些名词
- 六、Spark的核心基础Spark Core
- 七、【补充】Scala的比较器问题
Spark计算框架
一、Spark的概述
Spark是一个分布式的计算框架,是Hadoop的MapReduce的优化解决方案。Hadoop的MR存在两大核心问题:1、无法进行迭代式计算 2、MR程序是基于磁盘运算,运算效率不高
Spark主要解决了Hadoop的MR存在的问题,Spark是基于内存运算的一种迭代式计算框架
Spark还有一个思想 one stack to rule them all(一栈式解决方案),Spark内置了很多子组件,子组件可以应用于不同的计算场景下,Spark SQL(结构化数据查询)、Spark Streaming(准实时计算)、Spark MLlib(算法)、Spark GraphX(图计算)、Spark R,以上这些子组计都是基于Spark Core开发的。
Spark之所以可以实现基于内存的迭代式计算,主要也是因为Spark Core中的一个核心数据抽象RDD
二、Spark的特点
- 计算快速
- 易用
- 通用
- 兼容
三、Spark的安装部署(安装部署Spark的Cluster Manager-资源调度管理器的)
3.1 本地安装–无资源管理器
3.2 Spark的自带独立调度器Standalone
3.2.1 主从架构的软件
3.2.2 Master/worker
3.2.3 伪分布、完全分布、HA高可用
3.3 Hadoop的YARN
3.4 Apache的Mesos
3.5 K8S容器技术
【注意】:我们在安装部署Spark的资源管理器的同时,也可以安装一个Spark的job history
四、Spark程序的部署运行
Spark部署运行和MR程序的部署运行方式一致的,需要将我们编写的Spark程序打包成为一个jar包,放到我们的Spark集群中,然后通过Spark相关命令启动运行Spark程序即可
spark-submit --class 全限定类名 --master 运行的资源管理器 --deploy-mode 部署运行的模式 --num-executors 只在yarn模式下使用 指定executor的数量 --executor-cores 指定每一个executor具备多少个CPU内核,一个内核可以运行一个TASK --executor-memory 每一个executor占用的内存 jar包路径 main函数的args参数列表- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
五、Spark集群运行中三个核心角色和一些名词
5.1 Driver驱动程序
编写的Spark程序,Spark程序中SparkContext,负责任务调度
5.2 Cluster Manager(资源管理器)
负责分配资源给Spark程序运行的,Spark支持很多资源管理器,YARN、Spark的Standalone、Apache的Mesos
5.3 Executor(执行器)
Spark申请资源的最小单位,每一个executor包含了内存、CPU Core
5.4 Task(任务)
每一个executor内部可以同时启动多个任务,Task就是Spark程序运行的最小单位,一个executor可以运行多少个task取决于cpu core
假如Spark程序总共有100个任务,一般分配30个左右task。
5.5 DAGScheduler
记录RDD之间的依赖关系的,也是用来划分stage阶段
5.6 Stage阶段
核心就是用来划分shuffle阶段的,一个stage阶段可能包含多分RDD的计算的,因此一个stage中包含多个Task的。Spark程序在运行的时候,一个stage的任务调度运行的
5.7 TaskScheduler
任务调度器,Driver驱动程序分配任务给task运行的
5.8 application
Spark应用程序,一个Spark程序可以包含多个job
5.9 job
遇到一个action算子,算子之前的依赖链上的RDD组成一个job
5.10 RDD
RDD就是Spark程序运行的核心,在Spark程序中,无外乎就三种操作:创建RDD、转化RDD、从RDD中获取结果/将结果输出保存
六、Spark的核心基础Spark Core
Spark Core是Spark计算框架的核心基础,Spark中子组件都是基于Spark Core封装而来的。
Spark Core中包含了Spark的运行调度机制、Spark的迭代式计算、基于内存的运算机制
6.1 Spark Core中最核心的有两个概念
6.1.1 SparkContext
SparkContext:Spark的上下文对象,Spark程序的提交运行,任务分配等等都是由SparkContext来完成的。
6.1.2 RDD
RDD:也是Spark最核心最重要的概念,也是Spark中最基础的数据抽象(spark处理的所有数据都会封装称为RDD然后进行处理)
6.2 RDD的属性(RDD具备的一些特征)
6.2.1 一组分区(一组切片)
RDD可分区的数据集,RDD内部的数据是以分区的形式存在,每一个分区的数据可以存储在不同的节点上
6.2.2 一个计算每一个分区(切片)数据的compute函数
RDD计算的时候每一个分区的数据是并行计算的,通过一个函数将计算逻辑封装在分区数据上运行计算
6.2.3 一个用来记录RDD依赖关系的列表
记录RDD的依赖关系,容错机制
6.2.4 一个分区机制(RDD必须得是键值对类型的RDD)
分区器只对键值对类型的RDD生效
6.2.5 一个用来记录分区位置的列表
如果计算程序和数据不在同一个节点上,会把数据移动到计算节点
6.3 RDD的弹性的体现
6.3.1 存储的弹性
RDD数据可以在内存和磁盘之间自由切换
6.3.2 计算的弹性
RDD在计算的时候,stage、task都有可能计算失败,如果失败了stage和task都会进行特定次数的重试,默认重试4次
6.3.3 容错的弹性
RDD计算中如果数据丢失,可以根据依赖链重新计算
6.3.4 分片的弹性
RDD计算中,我们可以根据实际情况,在代码中动态的调整分片
6.4 RDD的特点
6.4.1 分区
6.4.2 只读
RDD是只读的,不可变的,RDD一旦创建,内部不能改变了,只能根据RDD计算返回一个新的RDD,而原有的RDD不受任务的干扰
6.4.3 依赖
-
宽依赖:父RDD的一个分区数据被子RDD的多个分区同时使用,一般在shuffle算子中才会出现
-
窄依赖:父RDD的分区数据只能给子RDD的一个分区
依赖是Spark程序划分stage的核心依据,stage划分规则是从上一个宽依赖算子到下一个宽依赖算子之间的操作都属于同一个stage.
6.4.4 缓存
6.4.5 检查点
6.5 RDD的分类
RDD数据集,内部可以存放各种各样的数据类型,根据存储的数据类型不同,将RDD分为两类:
- 数值类型的RDD(RDD)
- 键值对类型的RDD(PairRDD)
数值类型的RDD存放的数据类型可以是任何类型,包括键值对类型 RDD[String]、RDD[People]
键值对类型的RDD指的是数据集中存放的数据类型是一个二元组 是一种比较特殊的数值类型的RDD RDD[(String,Int)]、RDD[(Int,(String,Int))]
键值对类型的RDD有它自己独特的一些算子操作,同时键值对类型的RDD可以使用数值类型RDD的所有操作
6.6 RDD的编程
在Spark中,对数据操作其实就是对RDD的操作,对RDD的操作无外乎三种:1、创建RDD 2、从已有的RDD转换得到一个新的RDD 3、从已有的RDD得到相应的结果
RDD的编程方式主要分为两种:命令行编程方式(spark-shell–数据科学、算法研究)、API编程方法(数据处理 java scala python R)
RDD的操作
转换操作(Transformation): 从一个RDD中得到另外一个RDD的算子
行动操作(Action): 从RDD得到一个Scala集合、Scala标量、将RDD数据保存到外部存储中
RDD计算操作是惰性计算的,遇到转换算子不会计算,只会先记录RDD的依赖关系,只有当遇到行动算子,才会根据记录的依赖链依次计算
6.6.1 RDD的创建操作
将数据源的数据转换称为Spark中的RDD,RDD的创建主要分为三种:1、从外部存储设备创建RDD(HDFS、Hive、HBase、Kafka、本地文件系统…)2、Scala|Java集合中创建RDD 3、从已有的RDD转换成为一个新的RDD(RDD的转换算子)
-
从集合中创建RDD
RDD的数据类型取决于集合的数据类型
函数名 说明 parallelize(Seq[T],num)makeRDD(Seq[T],num)底层就是parallelize函数的实现了 makeRDD(Seq[(T, Seq[String])])这种方式创建的RDD是带有分区编号的 ,集合创建的RDD的分区数就是指定的分区数 parallelize(Seq[T],num)和makeRDD(Seq[T],num):都可以传递一个第二个参数,第二个参数代表的是RDD的并行度(RDD的分区数),默认分区数就是master中设置的cpu核数 -
从外部存储创建RDD
-
文件纯文本文件
sc.textFile(path) sc.wholeTextFile(path):RDD[String]sequenceFile文件 sc.sequenceFiile(path,classof[Key],classof[V]):RDD[(Key,V)]objectFile文件 sc.objectFile(Path):RDD[T] -
外部存储软件HDFS、HBase、数据库…
-
-
从其他RDD转换一个新的RDD(RDD的转换算子)
6.6.2 RDD的转换操作(转换算子)
RDD之所以可以实现迭代式操作,就是因为RDD中提供了很多算子,算子之间进行操作时,会记录算子之间的依赖关系
RDD中具备一个转换操作的算子,转换算子是用来从一个已有的RDD经过某种操作得到一个新的RDD的,转换算子是惰性计算规则,只有当RDD遇到行动算子,转换算子才会去执行。
6.6.2.1 算子
算子:就是Spark已经给我们封装好的一些计算规则,只不过这些计算规则内部还需要传入计算逻辑,代码层面上,算子就是需要传入函数的函数。Spark提供了80+个算子。
6.6.2.2 数值型RDD的转换算子(通用算子)
函数名 说明 类型 map(f:T=>U)算子–一对一算子 一对一算子 mapPartitions(f:Iterator[T]=>Iterator[U])算子—一对一算子,一个分区的数据统一执行一次map操作 一对一算子 mapPartitionsWithIndex(f:(Index,Iterator[T])=>Iterator[U])一对一算子,和mapPartitions算子的逻辑一模一样的,只不过就是多了一个分区编号。 一对一算子 filter(f:T=>Boolean)算子—过滤算子,清洗数据,RDD的数据类型不会发生任何的更改。对原有RDD的每一个算子应用一个f函数,如果函数返回true,那么数据保留,如果返回false,那么数据舍弃 过滤算子 flatmap(f: T => TraversableOnce[U]):RDD[U]一对多的算子,一条输入数据可以被映射成为0个或多个数据,最后函数的返回值必须是一个集合类型,最好得到的RDD的类型就是集合元素的类型 压扁算子 sample(boolean是否为有放回的抽样,抽取比例,种子-底层抽样算法使用默认值)随机抽取原始RDD的部分数据,RDD的数据类型不会发生任何的更改,一般使用在源RDD的数据量过多。数据量越大,抽取的数据越精准,数据量越小,抽取的数据偏差越大。 抽样算子 union(RDD[T]):RDD[T]将两个RDD中所有数据组合成为一个新的RDD然后返回 并集算子 intersection(RDD[T]):RDD[T]将两个RDD取交集返回 交集算子 subtract差集算子 distinct([numPartitions]))(implicat ordering = null)对RDD元素去重,借助元素的equals方法去重的,第二个隐式参数的目的是为了去重之后对数据分区进行排序,如果没有排序规则,不排序了。不会改变RDD的数据类型 去重算子 cartesian(RDD[U])生成笛卡尔乘积,里面需要传入RDD[O],在T和U类型的RDD上,列出T和U的所有组合情况,返回一个新的RDD[(T,U)] 笛卡尔乘积 sortBy(T=>U,asc:Boolean=true)(implicit ordering[U])不会改变RDD的数据类型,可以指定将RDD中数据类型转换为其他一种类型进行排序比较。(将RDD中T类型转换成为U类型然后对RDD进行排序,返回的还是RDD[T])
【注意】U必须能排序的,两种方式:实现Ordered接口,定义一个隐式类是Ordering[U]的子类 当然我们也可以手动在sortBy函数的第二个括号中传递一个Ordering的匿名内部类排序算子,排序要求RDD的T元素必须能比较大小,必须具备Scala比较器 zip两个RDD的元素个数必须相同 拉链算子 repartition(num)将RDD的分区数重新划分,RDD的数据类型不会发生任何的变化,将RDD数据重新分区之后得到一个新的RDD 分区算子 6.6.2.3 键值对类型RDD的转换算子
函数名 说明 类型 groupByKey([numPartitions])根据key值,把value聚合到一起,RDD的value类型发生变化。根据RDD的键值对数据的key值把Value数据聚合到一起,然后返回一个新的RDD,新的RDD也是kv类型,v变成集合类型 分组算子 join(RDD[(K,W)])和另外一个键值对RDD做inner join操作,返回RDD[(K,(V,W))] 内连接算子 leftOutJoin、rightOutJoin、fullOutJoin(RDD(K,W))和另外一个RDD做外连接操作
左连接:返回RDD[(K,(V,Option[W]))]
右连接:返回RDD[(K,(Option[V],W))]
全外连接:返回RDD[(K,(Option[V],Option[W]))]
Option是为了防止空指针异常的,Option的取值有两种:None、Some,如果Option包含的数据不为Null,那么使用Some将数据封装,然后我们可以使用get方法获取里面的值,如果数据为Null,那么使用None将数据封装,不能使用get获取数据外连接算子 四种连接查询算子( join(RDD[(K,W)])、leftOutJoin、rightOutJoin、fullOutJoin(RDD(K,W)))需要传入一个RDD[(K,W)] RDD的value类型发生变化了,value也变成了一个二元组(v,w) 看具体情况,套上Option cogroup(RDD[(K,W)])连接查询算子,需要传入一个RDD[(K,W)],返回一个 RDD[(K, (Iterable, Iterable)) ] 将两个RDD中所有key值相同的数据全部聚合到一块,RDD1中相同的Value组成Iterable[V] RDD2中相同的value组成Iterable[W] 连接算子plus版本 mapValues(f: V => U) :RDD[(K,U)]针对KV类型的RDD只对v操作返回一个新的类型,由新的类型和原有的key组成一个新的RDD 操作键值对的value数据算子,一对一 reduceByKey(func: (V, V) => V)根据key值,把value聚合到一起,并且对value求出一个聚合结果,RDD的类型不会发生变化。reduceByKey=groupBykey+reduce操作,函数输入数据有两个,输出有一个,输出类型和输出类型是同一个类型 输入的两个v:第一个v是上一次聚合的结果 第二v是本次要聚合的value 输出的v就是本次聚合的结果 分组聚合算子,累加… 最大值 最小值 总数 combineByKey( createCombiner: V => C,mergeValue (C, V) => C,mergeCombiners: (C, C) => C)combiner也是根据key值聚合value,只不过value如何聚合,是什么样的聚合逻辑,我们要通过三个函数说明(比reduceByKey的功能要强大):
createCombiner:V=>C 将key值对应得value数据先进行初始化操作,返回一个新的类型
mergeValue:(C,V)=>C 每一个分区都会单独执行一个mergeValue函数,通过mergeValue函数将当前分区的key的value值和刚刚创建的初始值做计算 得到当前分区下的唯一的计算结果,结算结果的类型必须和初始化之后的类型保持一致
mergeCombiners:(C,C)=>C 将所有分区当前key值计算出来的结果C 再进行一次全局的聚合,得到唯一的结果,结果就是我们这个combineByKey的计算结果 返回RDD[(K,C)]分组聚合Plus算子 aggregateByKey(zeroValue:U)(mergerValue(U,V)=>U,mergerCombiner:(U,U)=>U)和reduceByKey类似,但是比reduceByKey功能要更加强大 RDD的value的类型可以改变。
aggreGateByKey算子和CombineByKey算子实现的效率是一样的,区别在于初始值不一样的,combineBykey的初始值是根据函数计算来的,是根据每一个分区的一个真实的value数据计算得来的,而aggregateByKey的初始值是我们随意给的。分组聚合plus算子 foldByKey(zeroValue:V)(f:(V,V)=>V))相当于是aggregateByKey的简化版,当aggregateByKey的mergeValue和mergeCombiner函数的计算逻辑一致,并且zerovalue初始化类型的值和原先RDD的value的类型一致的时候,就可以使用foldByKey简化。 aggregateByKey算子的简化版 sortByKey(asc:Boolean=true)根据键值对kv的key进行排序,RDD的类型不会改变,默认升序排序
【注意】key值必须实现了Ordered比较器接口,如果想让排序规则准确,那么你的Ordered接口中排序逻辑必须得是升序逻辑排序算子,key必须实现了比较器 partitionBy(分区器)将键值对类型的RDD以指定的分区机制进行重新分区
只有再涉及到shuffle算子的时候才会出现分区器的概念HashPartitioner默认的分区器,可能会出现数据倾斜问题RangePartitioner范围分区器–尽可能保证每个分区的数据一致,抽样算法
自定义分区器flatMapValues操作键值对的value数据算子 一对多 keys、values算子一个获取KVRDD中所有key值,一个是获取所有的value值,但是它两的底层都是由map算子实现的 6.6.2.4 查看一个RDD的分区数和分区器
RDD中存在两个内容:partitioner 属性、getNumPartitions 函数
6.6.3 RDD的行动算子
行动算子是用来触发依赖链的执行的,在Spark程序中,一个行动算子触发的一个依赖链会单独成为Spark中job运行
6.6.3.1 数值型RDD的行动算子(通用算子)
函数名 说明 reduce((T,T)=>T):T聚合算子,从RDD中把所有的数据聚合得到一个结果,结果的类型必须和RDD中数据类型保持一致 aggregate(zerovalue:U)(mergeValue,combineValue):U聚合算子的plus版本 fold(zerovalue:T)(f:(T,T)=>T):Taggregate的简化版本 collect() :Array[T]算子慎用,很可能造成OOM异常,将RDD所有分区的数据拉取到Driver驱动程序端以数组的形式在内存中保存RDD中的所有数据。 foreach(T=>Unit) foreachPartition(Iterator[T] => Unit)对RDD中的数据进行一个函数操作,函数无返回值,这个函数中我们既可以输出数据(不用担心OOM问题),同时也可以在函数内部编写保存数据代码,保存到外部存储中 使用foreach替换collect去检查数据 count():Long返回RDD中数据量 获取RDD中的部分数据的算子
函数名 说明 first():T获取RDD中第一个元素,底层实现就是take(1) take(n): Array[T]获取RDD中的前n个元素 takeOrdered(num: Int)(implicit ord: Ordering[T]): Array[T]获取RDD排好序之后的前N个元素
【注意】RDD中的T类型必须可以比较大小,Scala中所有数值型的数据类型都不需要传递takeSample(withReplacement, num, [seed]):Array[T]随机抽取RDD中的num条数据 返回一个array数组 用来保存数据到文件中算子
saveAsTextFile(path)saveAsObjectFile(path)6.6.3.2 键值对类型RDD的行动算子
函数名 说明 saveAsSequenceFile(path)countByKey(): Map[K,Long]将键值对RDD中key值出现的次数以map集合的形式给我们返回 6.6.3.3 RDD的一些比较特殊的行动算子(只针对整数类型的RDD有效)
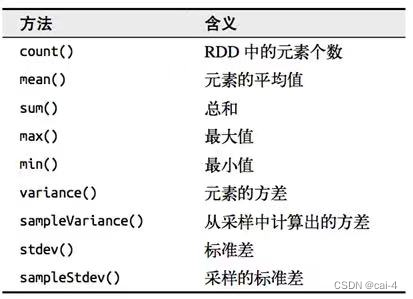
【补充】
在Scala中,每一个RDD都是RDD类型的,可调用的方法按道理来说只能是RDD内部定义的方法,但是有些特殊的RDD(键值对RDD、整数类型的RDD)可以调用非RDD内部声明的函数,底层采用了Scala的隐式转换机制扩充了特殊RDD类型的功能
6.6.4 RDD的分区机制
只有键值对类型的RDD才有分区器,分区器在执行shuffle算子的时候才会生效。
HashPartitioner(默认)、RangePartitioner、自定义分区器
6.6.4 整数型RDD的计算操作
只有整数型的RDD才具备这个操作
sum|mean…
6.6.5 RDD的底层的隐式转换
在Scala当中,所有的rdd数据集都是RDD的类型,RDD里面有很多算子没有,但是rdd确实能使用的。底层就是通过隐式转换扩充的功能。
6.7 RDD的持久化(缓存)
在一个Spark的Application中,可能一个RDD被多个Job,或者被同一Job多次使用,但是RDD每次计算完成之后,下次如果还需要使用,需要根据依赖链从头开始计算RDD,这样的话,效率太低,根据依赖链计算确实挺安全,但是也特别浪费时间。如果我们想让计算快速完成,Spark提供了一种机制,缓存机制,可以实现将重复性使用的RDD缓存大起来(内存、磁盘、内存+磁盘),RDD缓存只有当触发了第一个行动算子之后才会进行缓存操作。这样的话第二个job和后续的job再使用RDD直接从缓存获取,就不需要重新计算了。而且如果缓存的数据丢失,可以根据依赖链重新计算。
RDD计算过程中,可能会出现某个RDD被重复性使用的情况,但是RDD计算有一个原则,每次使用RDD时候,需要根据血统依赖链重新计算RDD的数据。所以为了避免重复利用的RDD被重复性计算,我们可以把重复利用的RDD给缓存起来,后期再使用这个RDD的时候,就不根据依赖链重复计算。(如果缓存数据丢失会根据依赖链重新计算生成缓存)
cache | persist | persist(缓存级别)【特点】
不会断依赖链
应用场景
重复性使用RDD(主要)、依赖链过长
6.7.1 缓存涉及到两个算子
cache() persist() persist(StorageLevel)- cache底层实现是persist(),persist底层实现persist(StorageLevel.MEMORY_ONLY)
- StorageLevel有很多种缓存级别
6.8 RDD的检查点机制
检查点也是一种另类的RDD缓存方式,只不过和RDD持久化的区别在于,检查点会把依赖链断掉,同时检查点的数据保存到HDFS分布式文件系统中,这样依靠HDFS的副本机制保证缓存的高可靠性。RDD检查点一旦设置成功,依赖链断了,下一次如果我们再重新运行Spark程序,会从检查点获取数据往后运行,RDD之前的依赖计算全部不用执行了。
如果设置缓存点,那么设置之前,必须先使用SparkContext设置检查点目录,
sc.setCheckPointDir(hdfspath),然后需要进行设置检查点的RDD,使用rdd.checkpoint()。检查点也是第一次触发行动算子之后才会进行操作的。
6.7 RDD的持久化(缓存)~6.8 RDD的检查点机制:持久化和检查点都得需要action触发之后才会执行的
6.9 RDD算子的依赖关系
6.9.1 RDD算子的依赖分为两种
- 宽依赖:shuffle类型的算子,父RDD的一个分区的数据被子RDD的多个分区使用,同时子RDD的一个分区数据也可能来自于多个父RDD的分区
- 窄依赖:父RDD的分区数据只能被子RDD的一个分区使用
如何查看一个算子的前一个依赖是宽依赖还是窄依赖,rdd.dependencies 函数
依赖关系是我们划分stage阶段的关键,stage划分的依据就是根据宽依赖划分。
6.9.2 stage划分依据
一个stage指的是从一个shuffle算子开始到另一个shuffle算子之前的操作都归属于同一个stage
6.9.3 DAG生成
基于依赖链和stage生成的
6.10 RDD的两个特殊的使用
6.10.1 RDD的累加器
累加器就是在程序运行中获取一些感兴趣的数据的量,Spark中累加器功能比较强大的,除了获取感兴趣的数据量,还可以自定义累加器的类型,获取一些其他的数据。
累加器的使用有一个注意点:累加器一般是在Driver端定义,然后在RDD分区中修改累加器的数值,然后在Driver端获取累加器的结果。
用法
-
需要在Driver中创建一个累加器—Spark自带的,累加整数类型的值
val accu = sc.xxxxaccumulator(累加器的名字) -
在RDD的算子计算中对累加器进行赋值操作
accu.add(1) -
在Driver端获取累加器的结果
accu.value
6.10.2 RDD的广播变量
广播变量和累加器还挺像的,广播变量是只能让RDD的分区获取值,而不能修改值,广播变量是只读的。
在Driver端声明一个广播变量以后,这样的话可以在任何一个RDD的任何一个分区中获取广播变量的值计算。而且广播变量的数据类型可以自定义
用法
- Driver端设置广播变量
val factorBC:Broadcast[T] = sc.broadcast(变量名) - RDD分区中使用广播变量
factorBC.value
1、不同行为的总流量,计算转换率 pv->cart->buy pv->fav->buy 2、不同行为下的top10商品 3、每一个用户最喜爱的top10商品(pv 1 fav 2 cart 5 buy 10)- 1
- 2
- 3
七、【补充】Scala的比较器问题
Java中存在两个比较器用于比较Java类的大小关系,Java的比较器有两个Comparable,Comparator,区别在于Comparable是让Java类必须实现的,Comparator是在使用比较器的时候使用匿名内部类的形式传递比较规则的。
Scala也是面向对象的,Scala中也存在类的概念,类在有些情况下也是必须能比较大小的。Scala也给我们提供了两个比较器,两个比较器是Java两个比较器的子接口。 Ordered 是Comparable的子接口 Ordering 是Comparator的子接口
7.1 Scala中比较器
在编程语言中,数据类型基本上都是比较大小的,数值类型的数据类型可以使用大于小于比较运算符直接比较大小,面向对象中引用数据类型也是一种数据类型(自定义类型),因此我们就得需要通过一个比较器来告诉编译器我们自定义的类型如何去比较大小。
7.1.1 Java比较器
ComparableComparator
7.1.2 Scala比较器
Ordered-是Comparable的子接口Ordering-是Comparator的子接口
-
相关阅读:
STM32+ MAX30102通过指尖测量心率+血氧饱和度
二级造价工程师考试还没完?还有资格审核规定!
JVM----GC(垃圾回收)详解
分布式 ID
仿everything的文件搜索工具项目详解:Part2
多要素气象站:推动气象监测进入智能化新时代
undefined reference to `timersub‘ 错误处理
图数据挖掘(一):网络的基本概念和表示方法
商业管理和经济学哪个好ib?
LeetCode:117. 填充每个节点的下一个右侧节点指针 II(C++)
- 原文地址:https://blog.csdn.net/cai_4/article/details/133001408