-
八股整理(计网,os)
1.进程和线程的区别
1.1什么是进程和线程
1.进程是操作系统进行资源分配和调度的一个基本单位,资源包括cpu,内存,磁盘等等IO设备等等。每一个进程启动都会最先产生一个线程,即主线程,然后主线程会在创建其他的子线程。
2.线程是一个基本的cpu执行单元,必须依托进程存货,一个线程是一个execution context(执行上下文),即一个cpu执行时所需要的一串指令。
举例子:电脑上同时运行的浏览器和视频播放器是两个不同的进程。进程可能包含多个子任务,这些子任务就是线程。比如视频播放器在播放视频时要同时显示图像、播放声音、显示字幕,可以理解为三个线程。linux内核中实现方式
linux里面,无论是进程还剩线程,到了内核,统一叫任务(Task)。由一个统一的结构 task_struct 进行管理,这个task_struct 数据结构非常复杂,囊括了进程管理生命周期中的各种信息。
在Linux操作系统内核初始化时会创建第一个进程,即0号创始进程。随后会初始化1号进程(用户进程的第一个:/usr/lib/systemd/systemd),2号进程(内核进程的第一个:[kthreadd]),其后所有的进程线程都是在他们的基础上fork出来的。
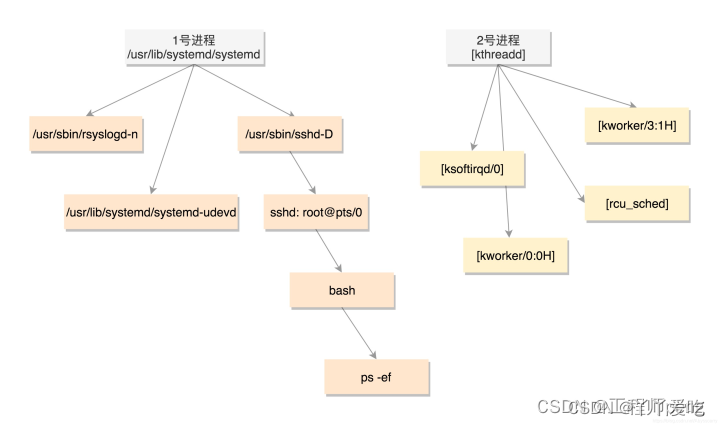
我们一般都是通过fork系统调用来创建新的进程。fork 系统调用包含两个重要的事件,一个是将 task_struct 结构复制一份并且初始化,另一个是试图唤醒新创建的子进程。无论是进程还是线程,在内核里面都是task,但是,线程不是一个完全由内核实现的机制,它是由内核态和用户态合作完成的。创建进程的话,调用的系统调用是 fork,会将五大结构 files_struct、fs_struct、sighand_struct、signal_struct、mm_struct 都复制一遍,从此父进程和子进程各用各的数据结构。而创建线程的话,调用的是系统调用 clone,五大结构仅仅是引用计数加一,也即线程共享进程的数据结构。

1.3 主要区别
1.根本区别:
进程是操作系统资源分配的基本单位,而线程是任务调度和执行的基本单位(也可以理解为进程中的一条执行流程)。2.开销:
每个进程都有独立的内存空间,存放代码和数据段等,程序之间的切换会有较大的开销;线程可以看做轻量级的进程,共享内存空间,每个线程都有自己独立的运行栈和程序计数器,线程之间切换的开销小。(线程上下文切换比进程上下文切换快得多)3.包含关系:
在操作系统中能同时运行多个进程;而在同一个进程(程序)中有多个线程同时执行(通过CPU调度,在每个时间片中只有一个线程执行)4.内存分配:
在创建新进程的时候,会将父进程的所有五大数据结构复制新的,形成自己新的内存空间数据,即进程之间的地址空间和资源相互独立。而在创建新线程的时候,则是引用进程的五大数据结构数据,但是线程会有自己的私有数据、栈空间。即同一进程的线程共享本进程的地址空间和资源。5.执行过程:
每个独立的线程有一个程序运行的入口、顺序执行序列和程序的出口。但是线程不能够独立执行,必须依存在应用程序中,由应用程序提供多个线程执行控制。(进程可独立执行,线程不可独立执行,两者均可并发执行)逻辑意义:
多线程的意义在于一个应用程序中,有多个执行部分可以同时执行。但操作系统并没有将多个线程看做多个独立的应用,来实现进程的调度和管理以及资源分配。2.http标志码有了解吗
1xx:指示信息–表示请求已接收,继续处理。
2xx:成功–表示请求已被成功接收、理解、接受。(200 OK服务器响应成功)
3xx:重定向–要完成请求必须进行更进一步的操作。
4xx:客户端错误–请求有语法错误或请求无法实现。(400:客户端语法错误)(403,服务器收到请求,拒绝提供服务)(404请求资源不存在,such as输入了错误的URL)
5xx:服务器端错误–服务器未能实现合法的请求。(500 服务器发生错误)web服务器告诉客户端当前网页发生什么事情,或者说当前web服务器的响应状态
状态码200:表示服务器响应成功(即服务器找到客户端请求的内容,并且将内容返回给客户端)
状态码302:代表临时跳转(URL地址从A跳到B,但非永久,经过一段时间后,UR地址A还可能跳到C)
状态码301:和302相似,代表永久的重定向,严格意义上来讲,不是服务器跳转,而是客户端跳转,服务器通过回传状态码301给客户端,让客户端完成跳转。
状态码304:服务器告诉客户端请求资源成功,但这个资源并非 服务器提高,返回给客户端,而是从客户端本地浏览器缓存中有的这个资源进行获取(这里和状态码200有区别,状态码200是服务器找到客户端请求的内容返回给客户端,而非304从客户端本地资源缓存中获取)
状态码403:请求的服务器资源权限不够,没有权限去访问服务器的资源或者请求的IP地址被封掉
状态码404:服务器没有该资源,或者是服务器找不到客户端请求的资源。
状态码500:程序错误,请求的网页程序本身报错讲讲 http1.0和http1.1的区别
1.响应状态码
1.1定义了16种状态码,1.1新加了大量的状态码,尤其是错误响应码,比如100(请求大资源前的预热请求),206(范围请求的标识码),410(资源已被永久转移)
2.默认连接方式
1.0默认为短链接(操作时建立,用完就结束),1.1默认为长连接(http操作时建立,当前任务结束TCP连接也不一定关闭,可以长时间存在,其实1.0也可以长连接,使用connection:keep-alive)
3.缓存的处理
1.0通过header里的if-modified-since,expires判断是否缓存
1.1引入缓存控制策略,引入entity tag if-unmodified-since,if-match,if-none-match等缓存头控制缓存4.带宽优化及网络连接的使用
1.0存在浪费带宽的现象,列入客户端只是需要某个对象的一部分,服务器却把整个对象送过来,不支持断电续传功能
1.1则在请求头引入了range头域,允许只请求资源的某个部分,返回码2006,方便了开发者自由的选择3.给出一个字符串,如何判断是否为ipv4地址
python解法:
import re def is_valid_ipv4(ip_str): # 使用正则表达式匹配IPv4地址格式 pattern = r'^(\d{1,3})\.(\d{1,3})\.(\d{1,3})\.(\d{1,3})$' match = re.match(pattern, ip_str) if match: # 检查每个部分是否在0-255的范围内 parts = match.groups() for part in parts: if not (0 <= int(part) <= 255): return False return True else: return False # 测试 ip_address = "192.168.1.1" if is_valid_ipv4(ip_address): print(f"{ip_address} 是有效的IPv4地址。") else: print(f"{ip_address} 不是有效的IPv4地址。")- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
c++:
正则式解法:
regex ipv4("^(?:(?:25[0-5]|2[0-4]\\d|1\\d\\d|[1-9]?\\d)($|(?!\\.$)\\.)){4}$"); regex ipv6("^(?:(?:[\\da-fA-F]{1,4})($|(?!:$):)){8}$"); class Solution { public: string validIPAddress(const string& queryIP) { return regex_search(queryIP, ipv4) ? "IPv4" : regex_search(queryIP, ipv6) ? "IPv6" : "Neither"; } };- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
IPv4:1、根据".“分割开;2、四段;3、每段0-255;4、无前导0;5、全是digit
IPv6:1、根据”:"分隔开;2、八段;3、1-4位;4、字母(abcdef)或者数字class Solution { public: string validIPAddress(string queryIP) { vector<string> ipv4; vector<string> ipv6; char v4='.'; char v6=':'; if(queryIP.size()==0) return "Neither"; char c=queryIP[queryIP.size()-1]; if(c==v4||c==v6) return "Neither";//如果地址字符串末尾是:or. 那肯定不是 split(queryIP,ipv4,v4); split(queryIP,ipv6,v6); if(IsIPv4(ipv4)) return "IPv4"; IsIPv6(ipv6); if(IsIPv6(ipv6)) return "IPv6"; return "Neither"; } private: bool IsIPv4(vector<string> &ip) { if(ip.size()!=4) return false; for(auto subip:ip) { if(subip[0]=='0'&&subip.size()>1||subip.size()>3||subip.empty()) return false; //一定要判空subip.empty()不然底下stoi会报错 for(char c:subip) { if(c<'0'||c>'9') return false;//先判断每个是不是数字 } int subipint=stoi(subip); if(subipint<0||subipint>255) return false;//再判断数字的范围 } return true; } bool IsIPv6(vector<string> &ip) { if(ip.size()!=8) return false;//首先是不是八个子串 for(auto subip:ip) { int len=subip.size(); if(len<=0||len>=5) return false;//八个子串的长度是不是1~4 for(int i=0;i<subip.size();i++) { if(subip[i]<='f'&&subip[i]>='a'||subip[i]<='F'&&subip[i]>='A'||subip[i]<='9'&&subip[i]>='0') continue; else return false; // if(subip[i]<'0'||subip[i]>'9'&&subip[i]<'A'||subip[i]>'F'&&subip[i]<'a'||subip[i]>'f') return false; } } return true; } void split(string s,vector<string>&ip,char c) { s+=c; for(int i=0;i<s.size();i++) { int j=i; string item; while(s[j]!=c) item+=s[j++]; i=j; ip.push_back(item); } } };- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 61
- 62
- 63
- 64
- 65
答案 但是内存消耗不容乐观
其中出现的几个问题总结一一下,第一个是spilt函数截取字符串的问题。
ipv4:1.子字符串为4个,2.子字符串不为空,子字符串的长度不能大于3(即数字在1-3个之间),子字符串不含前导零 3.子字符串的每个字符必须是数字,4.子字符串在0~255之间(先使用stoi()转为int)
ipv6:1.子字符串为8个 2.子字符串的长度必须要在1-4之间(不能<1不能>5) 3.子字符串的字符必须在0-9,a-f,A-F之间4.tcp和udp有了解吗,分别有什么应用呢
tcp和udp在运输层,都是运输层的协议,tcp:传输控制协议。udp:用户数据包协议。
1.tcp面向字节流,udp面向报文。
2.粗略的来说tcp只能一对一,无法提供广播或者多播服务,udp属于广播,但也支持一对一,一对多,多对多的交互通信。
3.因为tcp点对点,所以其提供有连接的可靠服务,而udp提供无连接不可靠服务(这边有无连接体现在传送数据前需不需要先建立连接)
4.因为tcp提供有连接的服务,因此首部开销大,20~60个字节,而UDP首部开销只有8个字节
5.因为tcp提供有连接服务且首部开销大,因此适用于可靠传输的应用,比如文件传输,udp适用于实时应用,且他首部开销小,高效的很,随便发发,不需要考虑对方是否接收成功,比如ip电话,视频会议,直播等,所以有时候视频会掉帧哈哈哈哈哈
6.tcp需要使用socket套接字,但是udp不用,因为将udp数据包通过相应端口,上交给应用进程(应用层)的时候,只有端口,但无连接。(socket套接字的组成(ip地址,端口))UDP
面向报文,一次交付一个完整的报文,不拆分不合并报文,无拥塞控制。
想发就发,发之前不要建立连接,只是数据报文的搬运工,没有脑子,不会根据报文的大小拆分和拼接报文,每一次交付一个完整的报文。
具体来说,发送端的应用层把数据传送到运输层,UDP加个UDP头表示就给网络层,然后对应接收端,接收端在传输层去掉IP报文(运输层的数据名称)头就给应用层。
因此不太可靠,也不会确认对方是不是正确接收,不管网络是好是坏,没有拥塞控制,所以虽然高效,但是不可靠,网络不好的时候会丢包,视频丢帧,但是对实时性要求高的场景(比如电话会议)就是使用UDP的TCP
面向字节流,只能点对点,提供有连接的可靠服务,首部开销大。
TCP的连接是一条虚连接,每一条连接有两个端口,端口即socket套接字,socket={IP地址:端口号)
记一下常用的端口号:DNS-53 FTP-21/20 Telent-23 HTTP-80 HTTPS-443
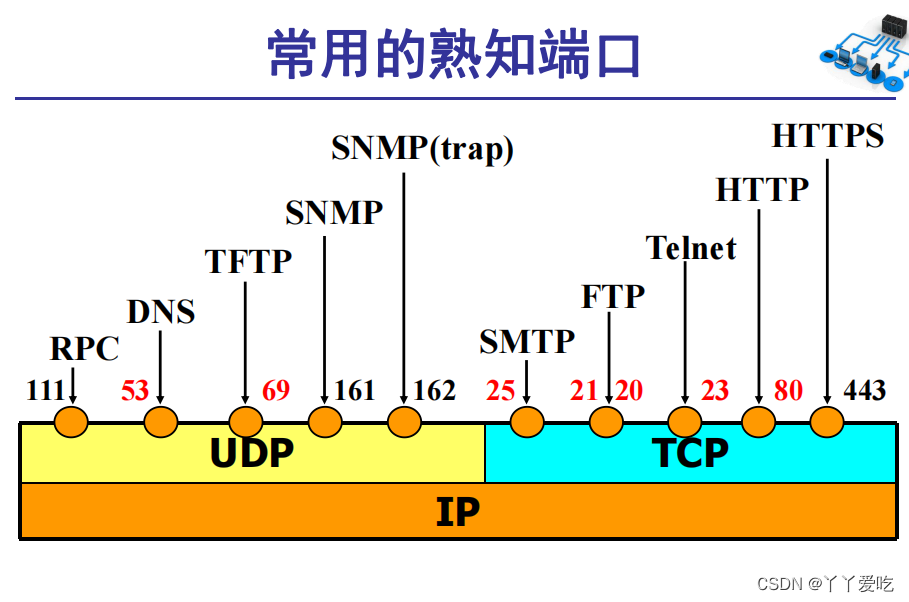
同一个IP地址可以多个不同的TCP连接,同一个端口号可以出现多个不同的TCP连接
TCP几个问题
1.三次握手
2.四次挥手
3.断开连接后为什么要等待2msl
4.怎么提供可靠服务的TCP的三次握手(三报文握手,交换三个TCP报文)
1.客户端发送一个SYN数据包(SYN=1,Seq=X,ACK=0)给服务端,请求进行连接,这是第一次握手
2.服务端收到请求并且允许连接的话,就会发送一个SYN+ACK的包(SYN=1,Seq=Y,ACK=X+1)给发送端,告诉它,可以通讯了,并且让客户端发送一个确认数据包,这是第二次握手
3.服务端发送一个ACK数据包(Seq=Z,ACK=Y+1)给客户端,告诉他连接已经被确认,这是第三次握手,TCP连接建立,开始通讯
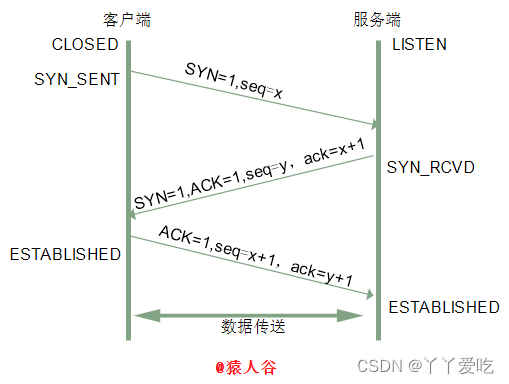
其中SYN=1 表示标志位置1 表示请求建立连接 ACK=0 表示初始建立连接值为0,表示当前没有接收数据(第一个握手的seq是随机序列号)
还有两个关键字段 FIN 关闭连接 PSH表示有DATA数据传输为什么连接的时候是三次握手,两次握手行不行
三次握手的目的是什么:
第一次握手:客户端发送网络包,服务端收到了,这样子服务端就知道:客户端的发送能力,服务端的接受能力都是正常的。(判断其中两方是不是都是正常人)
第二次握手:服务端发宝,客户端收到了,这样子客户端就知道,服务端的接收/发送能力,客户端的接收/发送能力都是正常的。但是此时服务端是不知道客户端的接受能力正不正常。
第三次握手:客户端发包,服务端收到了,这样子服务端就知道,客户端接收能力也完全欧克!
这样子才可以去判别劝人双方的接收和发送能力是不是正常
如果是两次握手:
如果客户端发送连接请求,但是发的连接请求报文丢失导致没有收到来自服务端的确认,于是客户端在重传一次连接请求,后来收到了确认,建立了连接。数据传输完毕后,释放连接,但是客户端其实是发送了两个连接请求报文段的(其中一个丢失,一个到达了服务器),但是第一个丢失的报文段只是在某些网络结点长时间滞留了,延误到连接释放以后的某个时间才到达服务器,此时服务端收到滞留了的连接请求报文,误以为客户端又再次发起连接请求,于是重新向客户端发出确认报文段,同意建立连接,这时又重新建立新的连接,但是客户端并不会发送数据,会忽略服务端发来的ack确认包,而服务端一致等待客户端发送数据,这时候就会导致资源的浪费。TCP三次握手的半连接队列
服务器第一次收到客户端的SYN之后,会处于SYN_RCVD状态,此时双方还没有完全建立连接,服务器会把这种状态下的请求连接放在一个队列里,这种队列成为半连接队列。
全连接:三次握手后,建立起连接的就会放在全连接队列中,队列满了就可能会出现丢包现象。
SYN_ACK重传次数的问题::服务器发送完SYN——ACK包之后,如果没收到客户确认包(即第三次握手),服务器开始重传行动,还没等到,再重传,直到超过系统规定的最大重传次数,就会把连接信息从半连接队列中删除
每次重传等待的时间不一定相同,一般指数增长initial sequence numberISN
当一端为建立连接而发送其SYN连接请求包,里面的seq是随机的初始序列号,ISN随着时间而变化,因此每个连接都会有不同的ISN,ISN可以看作是一个32bit的计数器,每4ms加1.
目的:主要是防止网络延迟分组在之后又被传送,而导致某个连接的一方做错误的解释
三次握手的其中一个重要功能是客户端和服务端交换ISN,这样让对方知道接下来接收数据如何按序列号组装数据,如果ISN固定,那么攻击者很容易猜出后续的确认号,
因此ISN动态生成,根据时间而变化,可看成一个32bit的计数器,每4ms加1三次握手过程中可以携带数据吗
第一次,第二次不行,不然携带数据,如果有人恶意攻击服务器,那攻击者only need在第一次握手的SYN报文中放入大量的数据,攻击者根本就不理服务器的接收,发送能力是否正常,然后疯狂重复SYN报文,那么服务器会花费很多时间,内存空间来接收这些报文。
而第三次,客户端已经处于ESTABLISTENED状态,也知道双方的接收,发送能力正常,所以可以携带数据。什么是SYN攻击
服务端的资源分配是二次握手的时候分配的,客户端的资源是在三次握手分配的,因此服务器容易收到SYN洪泛攻击。SYN攻击就是CLient在短时间内伪造大量不存在的ip地址,并不断向server发送SYN包,Server回复确认包,并等client确认,由于ip地址不存在,此时server需要不断重发直至超时,这些伪造的SYN包将长时间占用未连接队列,导致正常的SYN包请求因为队列满而被丢弃,从而导致网络拥塞或者系统瘫痪。SYN攻击是一种电信的DoS/DDoS攻击。
DoS(拒绝服务攻击):单一源,发送大量请求,消耗目标服务器的资源(带宽,cpu和内存),反正服务器资源耗尽,正常用户也没办法访问了(队列满而被丢弃发送来的队列请求包)
DDoS攻击:更先进的拒绝服务攻击,利用多个已感染的网络设备(僵尸网络)发起攻击,形成强大的攻击流量。
常见的防御DoS/DDoS攻击的常用手段:
1。防火墙 2.负载均衡 3 限流 4 内容分发网络。如何检测:服务器出现大量的半连接状态时,尤其是源ip地址随机的时候,基本可以断定这是一次SYN攻击,LINUX上可以使用netstat检测SYN攻击
netstat -n -p TCP|grep SYN_RECV //-n使得数字形式表示地址和端口号,-p表示后面跟着协议名称,表示只显示TCP协议的连接或者套接字,- 1
常见的防御SYN攻击的方法:
- 缩短超时(SYN timeout)时间
- 增加最大半连接数
- 过滤网关防护
- SYN cookies技术
TCP的四次挥手()
客户端或者服务端均可主动发起挥手动作。
刚开始刷u你官方都处于 ESTABLISHENED状态,假如是客户端先发起关闭请求,四次回收的过程如下:- 第一次挥手:客户端发送一个FIN报文,报文中会指定一个序列号,FIN=1,seq=u,(连接释放报文段),并且停止再发数据,主动关闭TCP连接。此时客户端处于FIN_WAIT!状态,告诉他我要关闭连接了!我不发数据了!你快给我确认!快点!我等着呢!
- 第二次挥手:服务端收到FIN连接释放请求报文后,会发生ACK确认报文,(ACK=1,ack=u+1,seq=v)服务端进行CLOSE_WAIT关闭等待状态,此时TCP处于半关闭状态,客户端到服务端的连接释放,客户端收到确认后,进入FIN_WIAIT2(中止等待状态,等待服务端发来的连接释放报文。服务端说我知道了你想关闭了!给你发个确认包!客户端:我等着你呢!你快给我发连接释放报文啊!
- 第三次挥手:如果此时服务点也想断开连接,和客户端的第一次挥手一样,发FIN连接释放报文(FIN=1,ACK=1,seq=w,ack=u+1),指定一个序号seq,服务端处于LAST_ACK状态。服务器告诉它我也没有东西要发了!我也想断开连接了!等你给我最后确认一下!
- 第四次挥手,客户端收到服务端发来的FIN连接释放报文,发送一个ACK报文(ACK=1,seq=u+1,ack=w+1),此时客户端处于TIME_WAIT状态。需要过一阵子来确保服务端收到自己的ACK报文后才进入CLOSED状态。此时还没又释放掉TCP,需要经过时间等待计时器设置的2MSL后,客户端才进入CLOSED状态。客户端说我知道你也想断开连接了!给你发个确认包!咱俩等2msl彻底拜拜!

为啥四次
好吧必须要四次缺一个都不行,A得说我要断开 我不发了 B说我知道了 我可能给你发也可能不给你发 然后B
也没东西发了 B也说我也想断开连接了 A说好的 咱俩等2msl彻底拜拜
缺一个都不行2msl等待状态
每个具体TCP实现必须设置MSL即一个报文段的最大生存时间,是任何报文段被丢弃前在网络内的最长时间。最后一次挥手,发送ACK确认包,该连接必须在TIME_WAIT状态停留为2倍的MSL,这样可以防止最后ACK的包丢失
意义:为了确认保证客户端发送的最后一个ACK报文段能够到达服务器,如果ACK丢失,服务器惠崇传FIN连接释放报文包,接着客户端再一次确认发送ACK包,重新启动时间等待计时器2msl。保证双方都能正常的关闭。
如果不设置,直接关闭,一旦ACK包丢失,服务器就无法进入正常的关闭连接状态。
两个理由::
1.保证客户端的发送的最后一个确认ACK包能够到达服务器
2.防止已经失效的连接请求报文段出现在本连接中(发送最后一个ACK后,在经过2msl,就可以使得本连接持续的时间内产生的所有报文段从网络中消失,使下一个新的连接中不会出现这种旧的连接请求报文段)TCP怎么提供可靠服务的
5.多线程有了解吗
进程是电脑程序运行的最小单位,线程是进程的最小执行单位
多线程指一个进程运行时,多个线程并行交替执行的过程。
实现方式:- 继承thread类,因为通过继承,不能继承其他类了 直接使用该类调用start方法
- 实现Runnable接口 解决上面的局限性。new Thread().start()
- 实现Callable接口 get获取线程结果 cancel(bool)中止或取消线程。底层主要是LockSupport+CAS的结合使用
解决多线程安全
1.使用lock,synchronized锁6.手撕,找到集合出现最多的元素
7.测试电梯的用列
电梯的测试用例主要包括:功能测试,界面测试,易用性测试,安全测试,性能测试,兼容性测试六个方面。
功能测试:
开关门按键是否能正常按下回退,是否能正常亮起熄灭,对应的电梯门是否能正常开关。
1.1电梯运行时不能开门。
1.2一直按着开关门键的结果。
报警键/电话键是否能正常按下回退,是否能正常亮起熄灭,对应的报警是否能正常得到响应。
各层的上下楼键是否能正常按下回退,是否能正常亮起熄灭,对应电梯是否能正常在各楼层停止等待。
电梯内的楼层选择按键是否能正常按下回退,是否能正常亮起熄灭,电梯是否能正常到达对应楼层。
4.1当电梯向上或者向下移动式,不能选择反方向的楼层。
电梯门是否能自动关闭。
楼层显示屏显示的电梯所在位置是否和电梯当前位置同步。
当有多个电梯时,之间的时间调度是否合理。
界面测试:
电梯形状大小是否符合设计要求。
电梯内按键形状大小颜色是否符合设计要求。
电梯内张贴物是否符合要求。
易用性测试:
按键上的标识符是否容易理解。
到达楼层时是否有提示音且提示音是否合理。
电梯光照是否会让人感到不适。
电梯通风是否会让人感到不适。
按键的整体高度是否符合大众。
电梯内的信号是否满足日常生活需求。
是否有提供给老人的扶手。
安全性测试:
暴力破坏电梯是否会报警报。
超载是否会有警报。
停电时是否有应急电源。
发生火灾时是否有对应处理措施。
电梯外部是否可以强制开门。
当电梯关门时,有物体通过电梯门是否能立即停止关门。
性能测试:
不载重的运行情况。
承载单人的运行情况。
承载多人的运行情况。
承载多人+较长时间运行,测试电梯的运行稳定性。
超长时间的运行情况。
载重的能力。
电梯正常使用的次数/年限。
兼容性测试:
电梯与常在一起使用的设备是否兼容。
不同的电压是否兼容。
不同的安装环境是否兼容(如潮湿/干燥)。8.怎么定位404和502的缺陷来源
404:表示客户端无法找到请求的资源。即服务器无法找到用户寻找的文件或页面。
发生在以下的情况:-
输入的URL错误
-
请求的资源已被移动,删除或者重命名
-
网站更新导致旧页面失效
502错误:表示错误的网关,这意味着作为代理或网关的服务器从上游服务器(如应用服务器/数据库服务器)接收到了一个无效的响应。
来源: -
服务器硬件或者网络故障
-
配置错误或不当的服务器设置
-
上游服务器遇到问题,如过载,软件崩溃,响应超时等
需要更深入的检查服务器和应用的配置或者解决上游服务器的问题
9.测试购物车以及提交订单界面
11.场景题:海量数据查询如何优化?
- 数据分片(Sharding):通过将数据分割成多个较小的单元,可以将查询负载分散在多个数据库服务器上,进而提高查询速度。
- 分布式缓存:使用分布式缓存(如Redis或Memcached)可以缓存热点数据,从而减少在数据库上的查询次数。只有在需要的数据没有被缓存时,才会发起对实际数据库的查询
- 索引优化:对数据库表中的关键列进行索引,可以大大降低查询所需的时间。在优化查询时,要考虑在哪些列上创建索引,以及如何避免过度索引以减少维护成本。
- 查询优化:优化SQL查询语句,避免复杂的子查询或连接操作,尽量使用直接的查询语句。在查询过程中,只需获取必要的数据列,避免SELECT *操作。
12.多个表如何保证数据一致性
- 数据库事务(Database Transactions):事务是一系列操作,它们应该作为一个整体来执行。事务应具有四个特性:原子性、一致性、隔离性和持久性(ACID属性)。使用事务可以确保多个相关的表在被更新时保持一致。
- 数据库约束(Database Constraints):约束用于限制数据表中的数据。这可以确保多个表之间的数据具有一致性。一些常见的数据库约束包括:
主键约束(Primary Key Constraint):确保主键列中的值唯一且不能为空。
外键约束(Foreign Key Constraint):确保一个表中的外键值与另一个表中的主键值相匹配时的数据一致性。
唯一约束(Unique Constraint):确保在特定列中的每个值都是唯一的。
检查约束(Check Constraint):确保满足指定条件的值才能被存储。 - 使用触发器(Triggers):触发器是在表的插入、更新或删除操作发生前或后自动执行的一段程序。触发器可以用来维护多个表之间的数据一致性,例如同步数据或保证数据完整性。
- 应用层使用代码进行数据一致性控制:在应用程序代码中实现数据一致性检查逻辑,以确保写入数据库的数据符合预期。这包括数据验证、业务逻辑和错误处理等,确保在写入数据库之前就检查数据的一致性。
15.用过什么自动化测试框架
Selenium - Selenium 是一个非常流行的 web 测试框架,可用于编写跨浏览器的自动化测试。支持多种编程语言,如 Java、Python、C#和 Ruby。
Pytest - Pytest 是 Python 社区中一个非常流行的测试框架,适用于从简单的单元测试到复杂的功能测试。插件生态丰富,使得 Pytest 功能更加强大。
Appium - Appium 是一个开源的移动应用自动化测试框架,可用于 iOS、Android 和 Windows 平台。它允许开发者使用同样的代码,对不同平台的应用进行测试。
XCTest - XCTestCase 是用于测试 iOS 和 macOS 应用程序的官方测试框架。它与 Apple 的开发工具 Xcode 集成,支持单元测试、性能测试及 UI 测试。
Espresso - Espresso 是一个用于 Android 应用程序的自动化测试框架。它专注于测试用户界面,并与 Android Studio 集成,使得创建和执行测试变得非常方便。
18 python的线程是如何使用的
import threading def worker(): """线程工作函数""" print("线程运行中") # 创建一个线程对象,该对象将使用worker函数作为运行的目标 t = threading.Thread(target=worker) # 启动线程 t.start() # 等待线程完成 t.join() print("线程结束")- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
多线程在Python(尤其是CPython)中存在一些限制,主要是全局解释锁(GIL)的限制,这意味着在某些情况下,多线程可能并不会在多核CPU上实现真正的并发。针对这些问题,可以使用multiprocessing模块来实现多进程并行,从而充分利用多核CPU。
-
相关阅读:
Packet Tracer - 排除 IPv4 的 EIGRP 故障
Open3D 网格滤波
JavaWeb前端基础(HTML CSS JavaScript)
光谱下的养殖业:数据可视化的现代变革
[ spring boot入门 ] java: 错误: 无效的源发行版:17
0101idea运行scala-基础入门-scala
XSS平台与cookie获取
Linux文件系统
数据结构之“刷链表题”
Design patterns--观察者模式
- 原文地址:https://blog.csdn.net/meiyongyue/article/details/131981450
