-
【大数据】Doris 构建实时数仓落地方案详解(二):Doris 核心功能解读
本系列包含:
1.Doris 发展历程
Apache Doris 是由 百度 研发并开源的数据库项目。 Doris 2008 年开始在百度内部立项,经历了五个大版本的迭代后于 2017 年开源,2018 年进入 Apache 基金会孵化项目。2022 年 4 月 18 日正式发布 Doris
1.0,2022 年 6 月 16 日正式毕业,成为 Apache 软件基金会的顶级项目。Doris 数据库软件主要有 BE 和 FE 两个组件构建。BE 是后台数据存取组件,是由 C++ 语言编写;FE 是前端查询入口和查询解析组件,由 Java 语言编写。
2.Doris 三大模型
Doris 最大的特点是提供了三大数据模型:
-
Duplicate Key模型也叫 可重复模型、明细模型,和普通的数据库表用法一样,保留每一条插入的数据,并且支持索引。 -
Aggregate Key模型也叫 聚合模型、汇总模型,将表的所有字段分为维度列和指标列,按照维度汇总指标数据,大大缩小数据量。 -
Unique Key模型也叫 去重模型、唯一模型,是按照主键保留最新记录,用于实现数据的删除和修改。
此外,Doris 还支持各种外部表,包括 ODBC 外部表、Hive 外部表、ES 外部表和 Iceberg 外部表,分别用于直接使用 Doris 查询引擎查询关系型数据库、Hive 数仓、ES 文本检索和 Iceberg 数据湖的数据,极大的拓宽了 Doris 数据库的应用边界。
3.Doris 数据导入
虽然 Doris 对外部表支持很丰富,但是外部表由于网络的瓶颈和无法支持索引,因此大数据的查询性能低于内部表,这里我们就要用到 Doris 的数据导入能力。Doris 的数据导入具有原子性,也就是说一批数据要么全部导入成功,要么全部失败;也支持容错参数,低于一定比例异常的数据都视为成功。
Doris 数据导入和数据搬迁工具包括
Insert Into、Stream Load、Broker Load、Routine Load、Binlog Load、Spark Load和 DataX 导入。
库内数据处理优先Insert Into,离线数据导入优选Stream Load和 DataX 导入,流式数据接入可以选择Routine Load和Binlog Load,Hive 数据导入选择Broker Load和Spark Load。可以看出,Doris 支持的数据来源非常丰富,并且对各种大数据生态产品支持都非常友好。当然,我们还可以通过外部表直接
Insert Into来搬迁数据量较小的外部数据。4.Doris 多表关联
然后就是 Doris 的多表关联功能。Doris 支持
Shuffle Join、Bucket Shuffle Join、Broadcast Join和Colocate Join四种分布式join策略,可以最大程度减少 MPP 架构下的数据重分布,提高数据查询效率。- Shuffle Join 要重分布关联的两个表所有数据。
- Bucket Shuffle Join 只需要重分布两个关联表中一个表的数据。
- Broadcast Join 则是广播关联表的其中一个数据量较小的表的全量数据。
- Colocate Join 则是直接在本地完成数据关联,无需进行任何数据重分布,这是大表数据关联的一种理想状态。
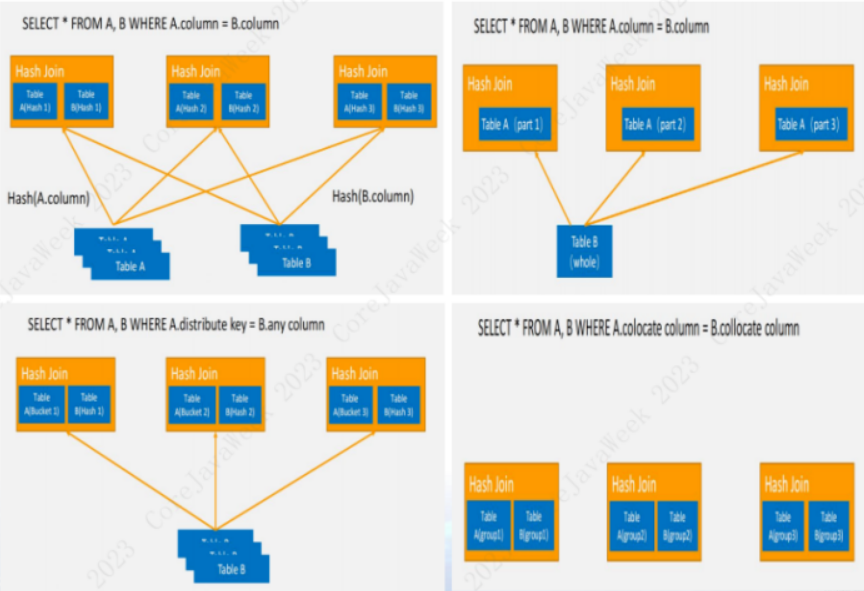
四种数据分布策略各有不同的应用场景,我们需要根据不同的数据关联需要进行优化,减少重分布的数据量,可以可以降低网络消耗,提高查询速度。5.Doris 核心设计
Doris 的核心设计参考了 Google Mesa、Apache Impala、OrcFile 存储格式。
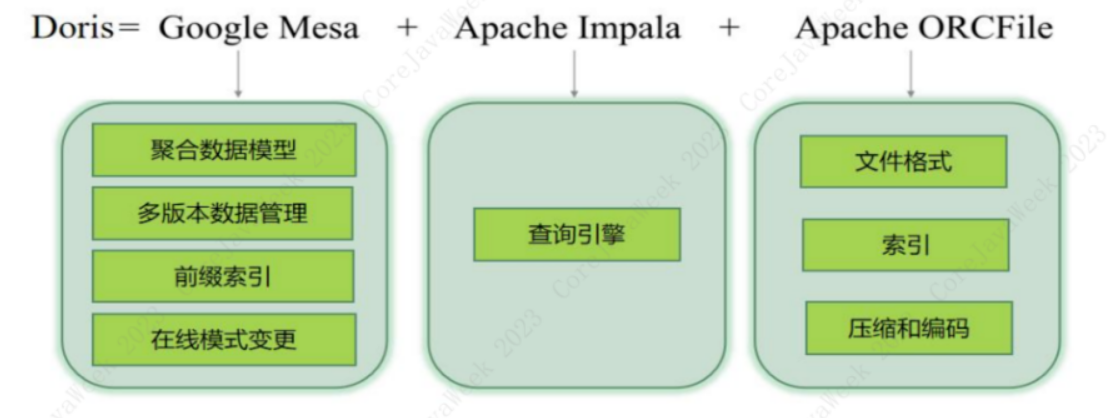
这里我想重点介绍一下 Doris 的数据存储。Doris 的存储设计结合传统 MPP 数据库的优点和 Hadoop 分布式数据的优点,引入了一个叫bucket的概念。我们都知道 Hadoop 是把一个表的数据按照文件大小切分成多个块,每个块三个副本随机分布到集群的三台服务器上的。而传统的 MPP 数据(例如 Greenplum、Clickhouse),数据要么按照节点平均分布,要么每个节点一份副本的全节点分布,前者对大表友好,后者对小表友好,但是都有缺点,前者并发查询上不去,后者浪费存储,节点数据同步消耗时间多。而 Doris 则是结合二者的优点又舍弃了其缺点,既支持小表多节点分布数据,又支持大表按照指定节点数分布式,并且 Doris 的数据副本可以参与计算,分散并发查询压力。- 针对聚合的热点数据表或者需要多次关联的维度表,我们可以设置 3 3 3 个以上的副本数,提高数据并发查询能力;
- 针对需要关联或者全表扫描的大表,我们设置尽可能多的分桶数,在查询时调用多节点同步进行来提高查询效率;
- 针对 ODS 层的大表或者实时数据写入的表,我可以只保留一份副本,降低磁盘空间占用。
另外,Doris 的数据文件存储格式,也是结合了行存的优点和列存的优点,选择的是基于行列混合的模式,在读写性能上也有非常大的提升。传统的 OLTP 数据库选择行存储是为了便于数据更新和删除,OLAP 数据库选择列存储是为了减少数据查询读取的列数,行列混合存储则结合了二者的优点,又提高了数据存储的灵活性。Doris
2.0还提供了对 S3 对象存储的支持,可以将冷数据自动备份到对象存储中,并且支持在线查询,只是查询速度会降低。6.Doris 查询优化
最后是 Doris 的查询优化功能。Doris 在查询方面做了非常多的优化。主要包括以下几个方面:
- 索引。其中最重要的是稀疏索引。稀疏索引是首先将入库的数据按照数据块的排序键进行顺序存储,然后每隔
1024
1024
1024 行数维护一条索引,既大幅降低了索引的空间占用,又可以快速扫描数据,是一个极具突破性的设计。前面介绍 Clickhouse 快的原因也提到了这个功能。而 Doris 在前缀稀疏索引之外,还支持了
MinMax索引、Bloom Filter索引、Bitmap索引,还支持通过rollup设置多种不同字段组合的索引,功能简直逆天。 - rollup 和物化视图。Doris 支持通过
rollup和物化视图提前预聚合数据,减少查询的数据量,提高响应速度。 - 分区。Doris 支持多级分区,可以通过分区降低数据的扫描范围,提高查询速度。
- 向量化查询引擎。Doris 通过支持向量化查询引擎,可以大幅提高 CPU 数据处理能力,提高查询效率。
- 查询优化。Doris 接收到用户的查询语句以后,会先进行 SQL 语句改写,尽可能降低查询复杂度,减少数据扫描范围。例如谓词下推、Join Order 优化、复杂 SQL 改写。
7.Doris 应对实时数仓的痛点
然后我们回顾一下实时数仓的三大难点:多表关联、维度数据变更、数据失效。
- 在 Doris 中,多表关联 我们可以通过流数据分别写入主键表的方式,在查询的时候才进行多表关联,这样可以完美的解决窗口不一致导致关联丢失的问题。
- 而 维度数据变更 也是一样的,我们可以在查询的时候才进行维度关联,舍弃大宽表模型,在不损失查询效率的情况下实现数据的一致性和实时性。
- 关于 数据失效 问题,Doris 主键模型支持按照主键删除和修改数据,失效的数据我们可以直接在明细数据上置为无效或者删除,在查询时过滤掉失效数据。
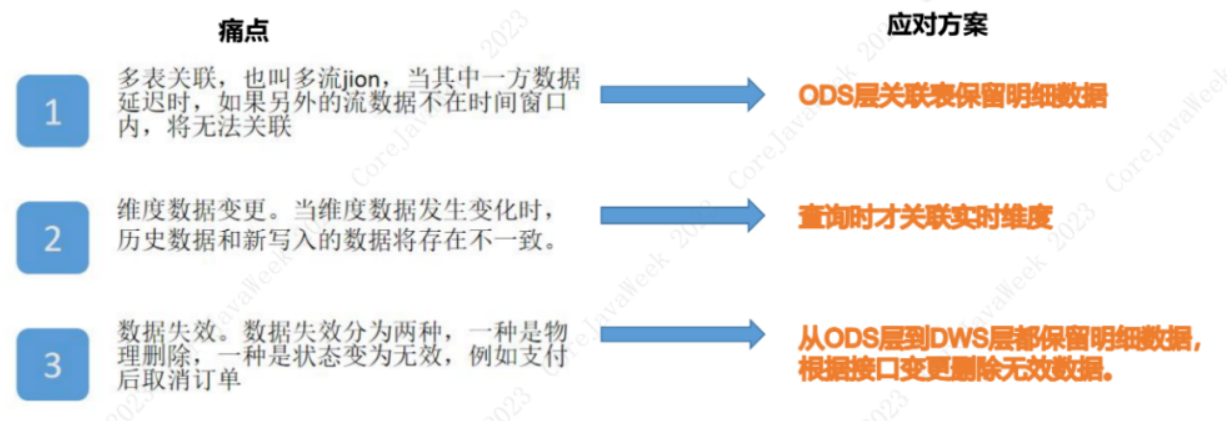
所以我说 Doris 数据库可以解决实时数仓的三大痛点。 -
-
相关阅读:
遥感影像正射矫正
敏稳融合时代,云原生PaaS是企业IT转型的“灵药”吗?
PCL点云处理之Failed to find match for field ‘intensity‘问题的解决方法 (二百一十四)
flutter报错: library “libflutter.so“ not found
SpringBoot-Web开发-数据响应与内容协商
websocketpp的回调函数解析
MPI之通信模式(标准,缓存,同步,就绪)
新电脑到手如何验机?保姆级攻略来了
Mysql入库不了表情符号怎么办
就业喜报:不拼一把 你怎么知道自己有多优秀
- 原文地址:https://blog.csdn.net/be_racle/article/details/133000372