-
PostgreSQL Page结构
Page结构
在数据文件(堆表、索引、自由空间映射和可见性映射)内部,它被划分为固定长度的page(或block),默认为 8192 字节(8 KB)。每个文件中的页面从 0 开始顺序编号,这些编号称为块编号。如果文件已满,PostgreSQL 会在文件末尾添加一个新的空页,以增加文件大小。
Page整体结构
page包含三个重要数据
- heap tuples: 它本身就是用来记录数据,heap tuples从页面底部开始依次堆叠。其内部数据结构下文再提。
- line pointers: 行指针构成一个简单的数组,作为heap tuples的索引,每个索引从1开始依次编号,为偏移量编号,新元组被添加到页面时,新的行指针也被加入数组,指向新的tuple。line pointers大小为4bytes
- header data:由PageHeaderData定义的header data分配再页面开头,长度为24个bytes,包含页面的一般信息,该结构体如下:
typedef struct PageHeaderData { /* XXX LSN是*任何*块的成员,不仅限于页面组织的块 */ PageXLogRecPtr pd_lsn; /* LSN:指向此页面上次更改的xlog记录的下一个字节 */ uint16 pd_checksum; /* 校验和 */ uint16 pd_flags; /* 标志位,见下文 */ LocationIndex pd_lower; /* 空闲空间开始的偏移量 */ LocationIndex pd_upper; /* 空闲空间结束的偏移量 */ LocationIndex pd_special; /* 特殊空间开始的偏移量 */ uint16 pd_pagesize_version; TransactionId pd_prune_xid; /* 最旧可修剪的XID,如果没有则为零 */ ItemIdData pd_linp[FLEXIBLE_ARRAY_MEMBER]; /* 行指针数组 */ } PageHeaderData;- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- pd_lsn: 存储page最后依次更改写入的XLOG记录的LSN,8bytes,与WAL机制有关
- pd_checksum:存储page的校验和值
- pd_lower, pd_upper:pd_lower 指向行指针的末尾,而 pd_upper 指向最新堆元组的开头。
- pd_special : 用于索引,在page中它指向page尾部
行指针末尾和最新元组开头之间的空位称为Free space。
为了识别表内的元组,内部使用了元组标识符(TID)。TID 由一对值组成:包含元组的页面块编号和指向元组的行指针偏移编号。写tuple
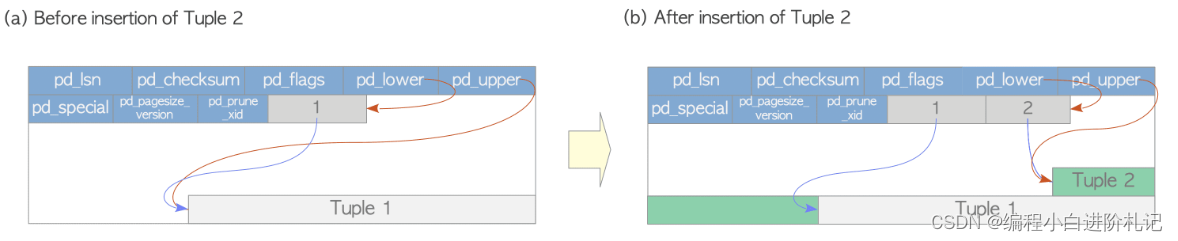
假设表格由一页组成,其中只包含一个heap tuple。该页的 pd_lower 指向第一个行指针,行指针和 pd_upper 都指向第一个堆元组。
插入第二个元组时,它被放在第一个元组之后。第二个行指针被附加到第一个行指针上,并指向第二个元组。pd_lower 变为指向第二个行指针,pd_upper 变为指向第二个堆元组。
该页面中的其他头数据(如 pd_lsn、pg_checksum、pg_flag)也会更新为适当的值;
读tuple
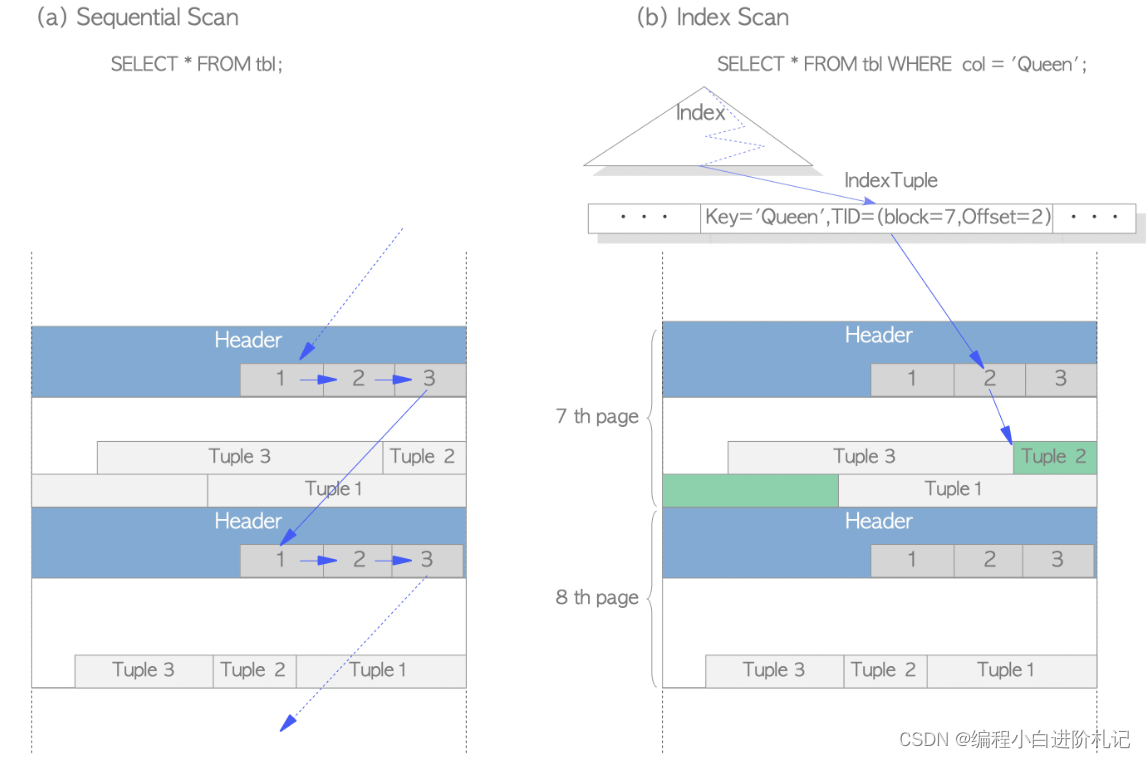
- 顺序扫描:它通过扫描每个page中的所有行指针,按顺序读取所有页面中的所有tuple
- B树索引扫描:它读取包含索引tuple的索引文件,每个索引元组都由索引键和指向目标堆元组的 TID 组成。如果找到了带有所需键的索引元组,PostgreSQL 就会使用获得的 TID 值读取所需的堆元组。
例如,在图 1.6(b)中,获得的索引元组的 TID 值为’(block = 7, Offset = 2)',这意味着目标堆元组是表中第 7 页的第 2 个元组,因此 PostgreSQL 可以读取所需的堆元组,而无需在页面中进行不必要的扫描。
PostgreSQL的page会出现point和tuple空隙,这是因为page中的行数据是动态变化的,可能会发生插入、删除、更新等操作,导致page中的空闲空间分散在不同的位置,形成空隙。这些空隙会影响page的利用率和性能,因为它们会占用额外的空间和IO,而且会增加扫描和查找的时间。
PostgreSQL有一些方法来解决point和tuple空隙的问题,主要有以下几种:
- 使用VACUUM命令来清理page中的死元组(dead tuples),即已经被删除或更新过的元组,释放它们占用的空间。VACUUM命令可以手动执行,也可以通过autovacuum机制自动执行。VACUUM命令不会改变page中元组的物理顺序,只会将空闲空间集中到page的末尾,方便后续插入新元组。
- 使用VACUUM FULL命令来重建page中的元组,重新排列它们的物理顺序,消除所有的空隙。VACUUM FULL命令会创建一个新的数据文件,并将旧文件中有效的元组复制到新文件中,然后删除旧文件。VACUUM FULL命令会占用更多的时间和空间,而且会锁定表,所以不建议频繁使用。
- 使用pg_repack扩展来重新打包page中的元组,类似于VACUUM FULL命令,但是不需要锁定表。pg_repack扩展会创建一个新表,并将旧表中有效的元组复制到新表中,然后用新表替换旧表。pg_repack扩展可以有效地消除page中的空隙,提高page的利用率和性能。
tuple 结构
堆元组由三部分组成:HeapTupleHeaderData 结构、NULL 位图和用户数据

typedef struct HeapTupleFields { TransactionId t_xmin; /* 插入事务的ID */ TransactionId t_xmax; /* 删除或锁定事务的ID */ union { CommandId t_cid; /* 插入或删除命令的ID,可能同时存在 */ TransactionId t_xvac; /* 旧式VACUUM FULL事务的ID */ } t_field3; } HeapTupleFields; typedef struct DatumTupleFields { int32 datum_len_; /* varlena头部(不要直接操作!) */ int32 datum_typmod; /* -1,或记录类型的标识符 */ Oid datum_typeid; /* 复合类型的OID,或RECORDOID */ /* * datum_typeid不能是复合类型上的域,只能是普通复合类型,即使datum被视为是复合类型上的域的值。 * 这与通常的原则一致,即CoerceToDomain不会改变基础类型值的物理表示。 * * 注意:选择字段顺序是考虑到Oid可能在将来扩展到64位。 */ } DatumTupleFields; struct HeapTupleHeaderData { union { HeapTupleFields t_heap; DatumTupleFields t_datum; } t_choice; ItemPointerData t_ctid; /* 当前元组的TID或更新的元组(或一个假设性插入标记) */ /* 下面的字段必须与MinimalTupleData匹配! */ #define FIELDNO_HEAPTUPLEHEADERDATA_INFOMASK2 2 uint16 t_infomask2; /* 属性数量 + 各种标志 */ #define FIELDNO_HEAPTUPLEHEADERDATA_INFOMASK 3 uint16 t_infomask; /* 各种标志位,见下文 */ #define FIELDNO_HEAPTUPLEHEADERDATA_HOFF 4 uint8 t_hoff; /* 头部大小,包括位图和填充 */ /* ^ - 23字节 - ^ */ #define FIELDNO_HEAPTUPLEHEADERDATA_BITS 5 bits8 t_bits[FLEXIBLE_ARRAY_MEMBER]; /* NULL位图 */ /* 结构的末尾有更多的数据 */ };- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- t_xmin :保存插入该元组的事务的 txid
- t_xmax :保存删除或更新此元组的事务的 txid。如果这个元组没有被删除或更新,t_xmax被设置为0,这意味着INVALID。
- t_cid : 保存命令id(cid),它是当前事务内执行此命令之前执行的SQL命令的数量,
- t_ctid :保存指向自身或新元组的元组标识符(tid)
Insert Delete and Updating Tuples
会简要描述用于插入和更新元组的自由空间映射(FSM)。
元组的表示

插入
将新元组直接插入目标表的页面中
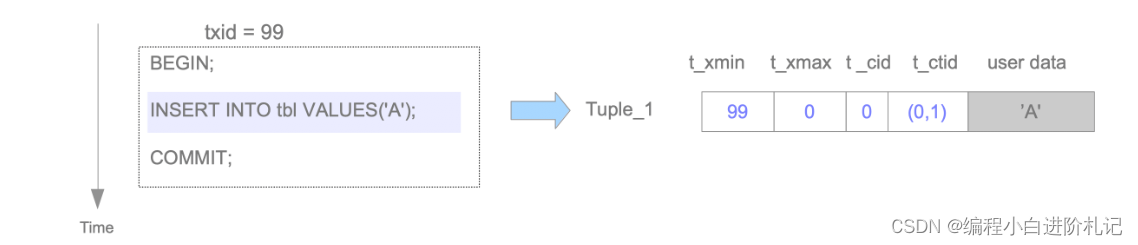
假设一个 txid 为 99 的事务在页面中插入了一个元组,在这种情况下,插入元组的标头字段设置如下
Tuple_1:- t_xmin 设置为 99,因为该元组是由 txid 99 插入的。
- t_xmax 设置为 0,因为该元组未被删除或更新。
- t_cid 设置为 0,因为该元组是由 txid 99 插入的第一个元组。
- t_ctid 设置为 (0,1),指向自身,因为这是最新的元组。
删除
目标元组会被逻辑删除。执行 DELETE 命令的 txid 值被设置为元组的 t_xmax
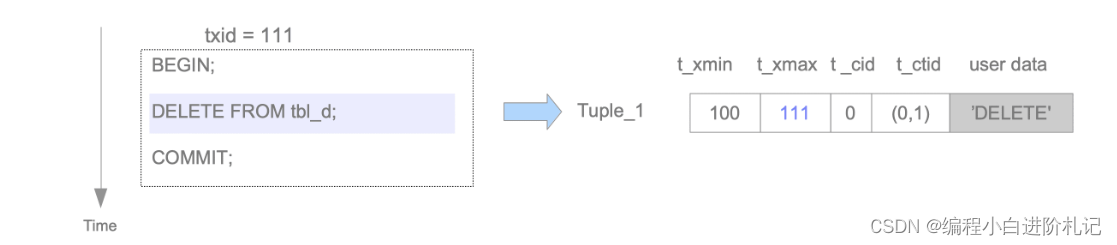
假设 txid 111 删除了元组 Tuple_1。在这种情况下,Tuple_1 的标头字段设置如下:Tuple_1:
- t_xmax 设置为 111。
如果 txid 111 已提交,则不再需要 Tuple_1。一般来说,不需要的图元在 PostgreSQL 中被称为死图元。
更新
PostgreSQL 在逻辑上删除最新的元组并插入新的元组
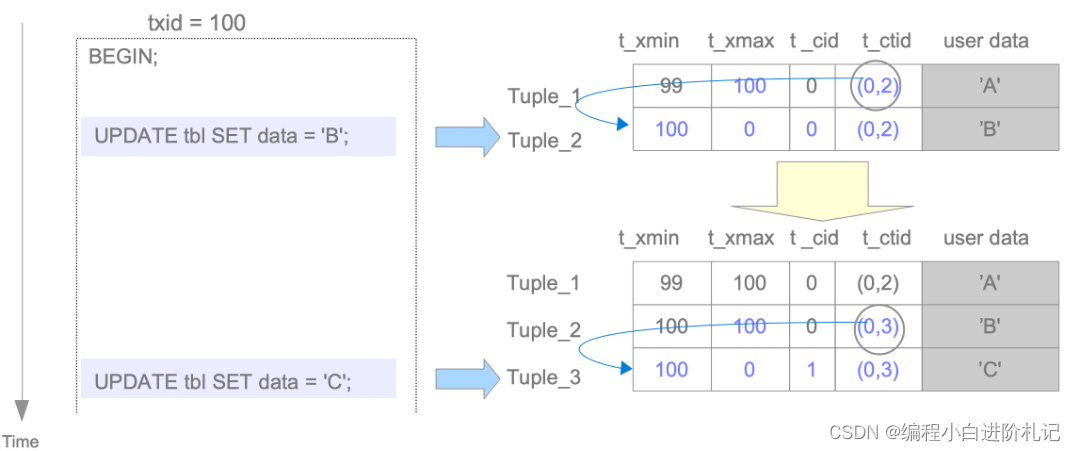
假设用 txid 99 插入的记录被 txid 100 更新了两次。执行第一条 UPDATE 命令时,通过将 txid 100 设置为 t_xmax,逻辑上删除了 Tuple_1,然后插入了 Tuple_2。然后,Tuple_1 的 t_ctid 被改写为指向 Tuple_2。Tuple_1 和 Tuple_2 的标头字段如下:
Tuple_1:- t_xmax 设置为 100。
- t_ctid 由(0,1)改写为(0,2)。
Tuple_2: - t_xmin 设置为 100。
- t_xmax 设置为 0。
- t_cid 设置为 0。
- t_ctid 设置为 (0,2)。
执行第二条 UPDATE 命令时,与第一条 UPDATE 命令一样,逻辑上删除 Tuple_2,插入 Tuple_3。Tuple_2 和 Tuple_3 的标头字段如下:
Tuple_2:- t_xmax 设置为 100。
- t_ctid 从(0,2)改写为(0,3)。
Tuple_3: - t_xmin 设置为 100。
- t_xmax 设置为 0。
- t_cid 设置为 1。
- t_ctid 设置为 (0,3)。
与删除操作一样,如果 txid 100 提交,Tuple_1 和 Tuple_2 将成为死图元;如果 txid 100 中止,Tuple_2 和 Tuple_3 将成为死图元。
自由空间映射
Postgresql中插入和更新元组的自由空间映射是一种用于提高数据存储效率和性能的机制,它可以避免对每个页面进行全表扫描,从而快速找到有足够空间的页面来存放新的或更新的元组。
- Postgresql中的每个表都有一个关联的自由空间映射(Free Space Map,FSM),它是一个记录了表中每个页面(Page)剩余空间大小的数据结构。FSM可以存储在共享内存(Shared Memory)或磁盘文件(Disk File)中,根据表的大小和配置参数而定。
- 当插入或更新一个元组时,Postgresql会首先检查FSM,找到一个有足够空间的页面来存放这个元组。如果FSM中没有找到合适的页面,Postgresql会扫描表中的所有页面,直到找到一个有足够空间的页面,或者分配一个新的页面。如果找到了合适的页面,Postgresql会将元组写入该页面,并更新FSM中该页面的剩余空间大小。
- 当删除一个元组时,Postgresql不会立即回收该元组占用的空间,而是将其标记为死元组(Dead Tuple),即已经被删除或更新过的元组。死元组占用的空间可以被后续插入或更新的元组重用,但是不会被FSM记录。只有当执行VACUUM命令时,死元组才会被清理,并释放它们占用的空间。
- FSM是一个近似的数据结构,它不保证记录每个页面的精确剩余空间大小。这是因为FSM需要占用一定的内存或磁盘空间,如果记录每个页面的精确剩余空间大小,那么FSM本身就会变得很大,并且需要频繁地更新。因此,Postgresql采用了一种折衷的方法,将剩余空间大小分为若干个区间,并用一个字节来表示每个区间。例如,如果page大小为8KB,那么剩余空间大小可以分为256个区间,每个区间表示32字节。这样,FSM就可以用一个字节来表示每个页面的剩余空间区间。
- FSM还有一个限制,就是它不能记录超过4GB大小的表。这是因为FSM使用4字节来表示每个页面的编号(Page Number),而4字节最多只能表示2^32个页面。如果page大小为8KB,那么最多只能表示32GB大小的表。如果表的大小超过了这个限制,那么FSM就无法记录所有页面的剩余空间大小。这时候,Postgresql就只能通过扫描表来找到有足够空间的页面。
-
相关阅读:
docker stop slow 解决
Tomcat 的部署和优化
pytorch深度学习实战lesson12
数商云:数字化供应链系统搭建,赋能企业实现物流供应链的优化升级
国内最牛的Java面试八股文合集,不接受反驳 我这该死的魅力
【Jmeter】提取和引用Token
Dubbo—dubbo admin安装
万界星空科技商业开源MES
http1.0到http3.0的介绍以及新特性
论文辅导 | 基于贝叶斯优化-卷积神经网络-双向长短期记忆神经网络的锂电池健康状态评估
- 原文地址:https://blog.csdn.net/weixin_47895938/article/details/132813793
