-
2023年 python结合excel实现快速画图(零基础快速入门)
目录
1.适用人群
电脑有python环境,会python基本使用,需要短时间内完成大量画图任务的数据分析的人群。(有过matplab相关画图库及echart用户使用起来会很快)
2.环境配置
pip install pandas jupyter-notebook pyecharts3.基本用法
3.1 数据读取
可以快速读入excel,选择你需要处理的Sheet1。这里请注意,不要有合并单元格。variable_types = data.dtypes查阅你需要处理的的数据类型。下面是样表:
序号 性别 民族 政治面貌 出生年月 中学名称 考生类别 毕业类别 考试类别 考生特征 投档单位 外语 投档志愿 1 男 回族 群众 2004/8/9 银川高级中学 城镇往届 普通高中毕业 秋季统考 统招 英语 1 2 男 汉族 共青团员 2004/3/10 银川市第六中学 城镇往届 普通高中毕业 秋季统考 统招 英语 1 打开jupyter notebook,运行数据分析代码
- import pandas as pd
- # 读取xlsx表格数据
- data = pd.read_excel("./录取名单汇总2100 .xls",sheet_name='Sheet1')
- # 分析数据的变量类型
- variable_types = data.dtypes
- variable_types
简单看一下数据类型:

3.2 数据分析
- objlist = []
- for id,i in enumerate(variable_types):
- # print(variable_types.index[id],variable_types.values[id])
- if(variable_types.values[id]=='object'):
- # print(variable_types.index[id])
- objlist.append(variable_types.index[id])
- dic_list = {}
- for col in objlist:
- col_data = data[col]
- unique_values = col_data.unique()
- if len(unique_values)<=100:
- dic_list[col] = unique_values
- print('属性',col,'\n=============')
- print(unique_values)
- print('=============')
可以看看数据的基本类别 改一改可以看分布情况。现在你如果想查找某种数据的分布情况,就可以针对列进行数据处理及分析。

3.3 数据组装
这里的数据组装是对数据的预处理,将需要分析的列。比如我需要查看电气工程及其自动化专业的男女比例,数据构造过程如下:
- def get_tuple_list(df, column_name):
- # 使用value_counts()函数进行分布统计
- distribution = df[column_name].value_counts()
- # 转换为元组并组成列表
- result_list = list(distribution.items())
- return result_list
- # 这句代码可能有些超纲,是pandas的df选择,不懂得同学补补对应的知识。
- df_dq = df[(df['专业'] == '电气工程及其自动化')]
- data_dq = get_tuple_list(df_dq,'性别')
data_dq结果:
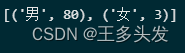
3.4 制表:
引入数据:
- from pyecharts import options as opts
- from pyecharts.charts import Bar
- from pyecharts.charts import Pie
制作饼状图:
- # 准备数据
- data = data_dq
- # 创建Pie对象
- pie = (
- Pie()
- .add("", data)
- # .set_colors(["blue", "white"]) # 设置颜色为蓝色和白色
- .set_global_opts(title_opts=opts.TitleOpts(title="电气自动化男女比例分布"))
- .set_series_opts(label_opts=opts.LabelOpts(formatter="{b}: {c}"))
- )
- # 渲染生成HTML文件
- # pie.render("pie_chart.html")
- pie.render_notebook()
样图:

制作条形统计图:
- # 准备数据
- x_data = [ i[0] for i in data]
- y_data = [ i[1] for i in data]
- # 创建Bar对象
- bar = (
- Bar()
- .add_xaxis(x_data)
- .add_yaxis(x_data, y_data)
- .set_global_opts(title_opts=opts.TitleOpts(title="电气自动化男女比例分布"),
- xaxis_opts=opts.AxisOpts(
- axislabel_opts={"interval":"0","rotate":90}),
- )
- )
- # 渲染生成HTML文件
- # pie.render("pie_chart.html")
- pie.render_notebook()
样图:
4.快速提升
根据Examples - Apache ECharts的网站选择你需要的图标,然后到GitHub - pyecharts/pyecharts-gallery: Just use pyecharts to imitate Echarts official example.
搜索你需要的组件~
比如:
我需要这个bar表


复制代码自己试一试,然后自己组装一下数据即可~
5.效果展示
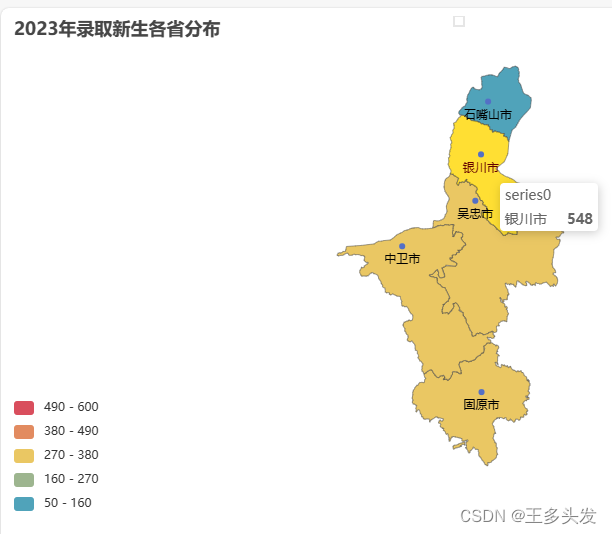
对应代码:
- # 2100 的省份
- from pyecharts.charts import Map # 注意这里与老版本pyecharts调用的区别
- from pyecharts import options as opts
- import random
- # prov_city = ['银川市', '中卫市', '吴忠市', '石嘴山市','固原市']
- # data_prov_city = [(i, random.randint(100, 200)) for i in prov_city]
- data = [("银川市", 548), ("中卫市", 279),("吴忠市",340),("石嘴山市",89),("固原市",357)]
- maps = Map().add("",
- data,
- "宁夏").set_global_opts(
- title_opts=opts.TitleOpts(title="2023年录取新生各省分布"),
- visualmap_opts=opts.VisualMapOpts(
- min_=50,
- max_=600,
- is_piecewise=True
- )
- )
- maps.render("maps_chart.html")
- maps.render_notebook()
这是根据实际需要制作的省份分布图,大家也可以根据自己的需要查阅最符合你需求的图表。
-
相关阅读:
P8842 [传智杯 #4 初赛] 小卡与质数2 垃圾筛
第23期 | GPTSecurity周报
1092:求出e的值 (信奥一本通)
一遍关于vue基础语法上篇
PHP中interface关键字
Mysql(增删改查指令)
关于爬虫中的hook(defineProperty,hook cookies, hook载荷数据,hookXHR)
【Transformer Based Cls&Det】Transformer系列分类和检测网络原理和源码讲解导航
虹科小课堂 | 在各种恶劣环境下,光纤传感器毫不畏惧、C位出道!
alibaba国际版阿里巴巴API接入说明(阿里巴巴商品详情+关键词搜索商品列表)
- 原文地址:https://blog.csdn.net/QAQterrible/article/details/132947151
