-
单体120万连接,小爱网关如何架构?
说在前面
在40岁老架构师 尼恩的读者交流群(50+)中,很多小伙伴拿到一线互联网企业如阿里、网易、有赞、希音、百度、滴滴的面试资格。
最近,尼恩指导一个小伙伴简历,写了一个《长连接网关项目架构与实操》,此项目帮这个小伙拿到 字节/阿里/微博/汽车之家 面邀, 所以说,这是一个牛逼的项目。
为了帮助大家拿到更多面试机会,拿到更多大厂offer,
尼恩决定:9月份給大家出一章视频介绍这个项目的架构和实操,《33章: 10Wqps 高并发 Netty网关架构与实操》,预计月底发布。然后,提供一对一的简历指导,这里简历金光闪闪、脱胎换骨。
《33章: 10Wqps 高并发 Netty网关架构与实操》 海报如下:

配合《33章:10Wqps 高并发 Netty网关架构与实操》, 尼恩会梳理几个工业级、生产级网关案例,作为架构素材、设计的素材。
前面梳理了
- 《日流量200亿,携程网关的架构设计》
- 《千万级连接,知乎如何架构长连接网关?》
- 《日200亿次调用,喜马拉雅网关的架构设计》
- 《100万级连接,爱奇艺WebSocket网关如何架构》
- 《亿级长连接,淘宝接入层网关的架构设计》
除了以上的5个案例,在梳理学习案例的过程中,尼恩又找到一个漂亮的生产级案例:《单体120万连接,小爱网关如何架构?》,
注意,这又一个非常 牛逼、非常顶级的工业级、生产级网关案例。
这些案例,并不是尼恩的原创。
这些案例,仅仅是尼恩在《33章:10Wqps 高并发 Netty网关架构与实操》视频备课的过程中,在互联网查找资料的时候,收集起来的,供大家学习和交流使用。
《尼恩 架构笔记》《尼恩高并发三部曲》《尼恩Java面试宝典》的PDF,请到公号【技术自由圈】获取
文章目录
单体120万连接,小爱网关如何架构?
作者:小爱技术团队
1、小爱接入网关的巨大的演进成果
小爱(又名“小爱同学”)是小米公司旗下的一款人工智能语音交互引擎,
“小爱同学”是小米集团统一的智能语音服务基础设施,
“小爱同学”客户端被集成在小米手机、小米 AI 音箱、小米电视等设备中,广泛应用于个人移动、智能家居、智能穿戴、智能办公、儿童娱乐、智能出行、智慧酒店和智慧学习等八大场景。
小爱接入层是小爱云端设备接入的关键服务,也是核心服务之一。
小米技术团队在 2020 年至 2021 年期间对该服务进行的一系列优化和尝试,最终,成功地将单机可承载的长连接数量从 30 万提高到 120 w+,节省了 30 +台机器。
2、什么是小爱接入层
小爱整体架构的分层如下所示:
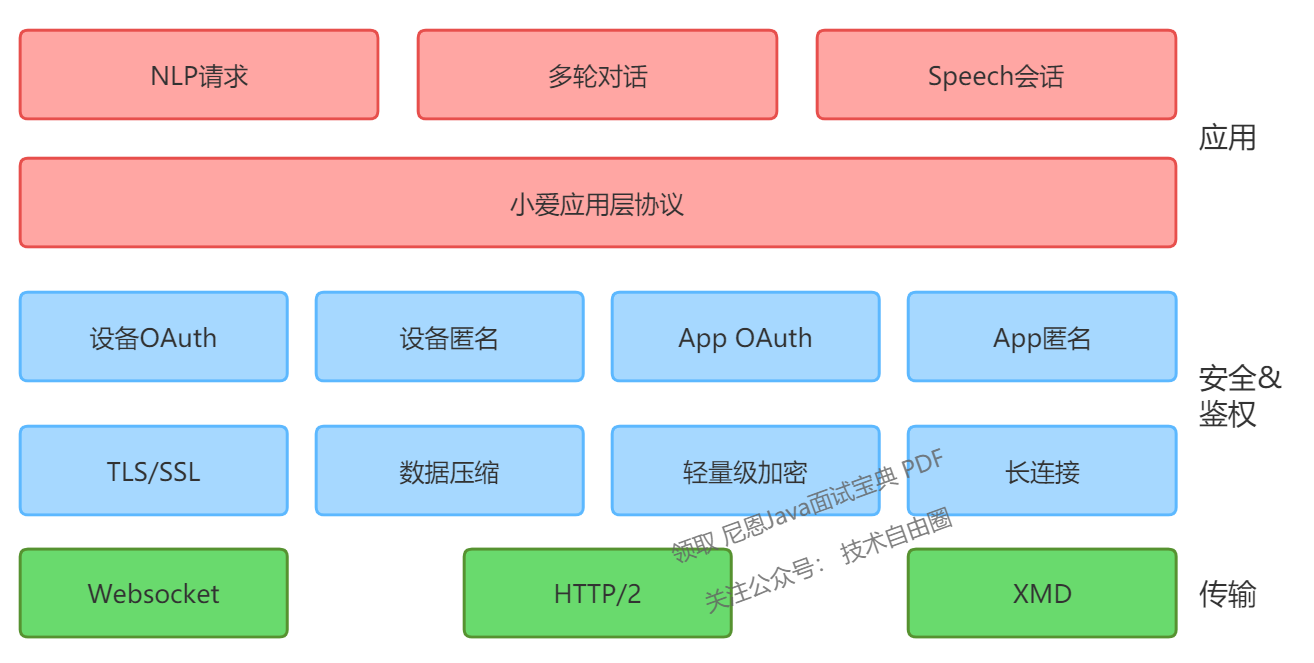
接入服务主要负责鉴权授权层和传输层的工作,它是所有小爱设备与小爱大脑互动的第一个服务。
从上图我们可以看出,小爱接入服务的重要功能包括以下几点:
- 1)安全传输与鉴权:保护设备与大脑之间的安全通道,确保身份认证的有效性和数据传输的安全;
- 2)维护长连接:保持设备与大脑之间的长连接(如 Websocket 等),妥善保存连接状态,进行心跳维护等工作;
- 3)请求转发:针对小爱设备的每次请求进行转发,确保每次请求的稳定性。
3、早期接入层的技术实现
小爱接入层最早的实现是基于Akka和playframework,我们使用它们搭建了第一个版本,其特点如下:
- 1)基于Akka,我们实现了初步的异步化,确保核心线程不会被阻塞,性能表现良好。
- 2)playframework框架天然支持Websocket,因此我们在有限的人力下能够快速搭建和实现,且能够保证协议实现的标准性。
注意, playframework 简称为 play , 是一款 和springmvc 类似的web 开发框架。
4、早期接入层的技术问题
随着小爱长连接数量达到千万级别,我们发现早期接入层方案存在一些问题。
主要的问题如下:
- 1)随着长连接数量增加,需要维护的内存数据日益增多,JVM 的 GC 成为性能瓶颈,且存在 GC 风险。经过事故分析,我们发现 Akka+Play 版的接入层单实例长连接数量上限约为 28w左右。
- 2)老版本的接入层实现较为随意,Akka Actor 之间存在大量状态依赖,而非基于不可变消息传递,导致 Actor 间通信如同函数调用,代码可读性较差,维护困难,未能发挥 Akka Actor 在构建并发程序的优势。
- 3)作为接入层服务,老版本对协议解析有较强依赖,需随版本更新频繁上线,可能引发长连接重连,存在雪崩风险。
- 4)由于依赖 Play 框架,我们发现其长连接打点不准确(因无法获取底层 TCP 连接数据),这会影响我们每日巡检对服务容量的评估,且在长连接数量增加后,我们无法进行更细致的优化。
5、新版接入层的设计目标
鉴于早期接入层技术方案存在诸多问题,我们决定重构接入层。
新版接入层的设计目标如下:
- 1)高稳定性:上线过程中尽可能避免断连接,保证服务稳定;
- 2)高性能:目标单机可承载至少 100 万长连接,尽量避免 GC 影响;
- 3)高可控性:除底层网络 I/O 的系统调用外,其他所有代码需自行实现或采用内部组件,以提高自主权。
因此,我们开始了实现单机百万长连接的探索之旅。
6、新版接入层的优化思路
6.1 接入层的依赖关系
接入层与外部服务的关系理清如下:
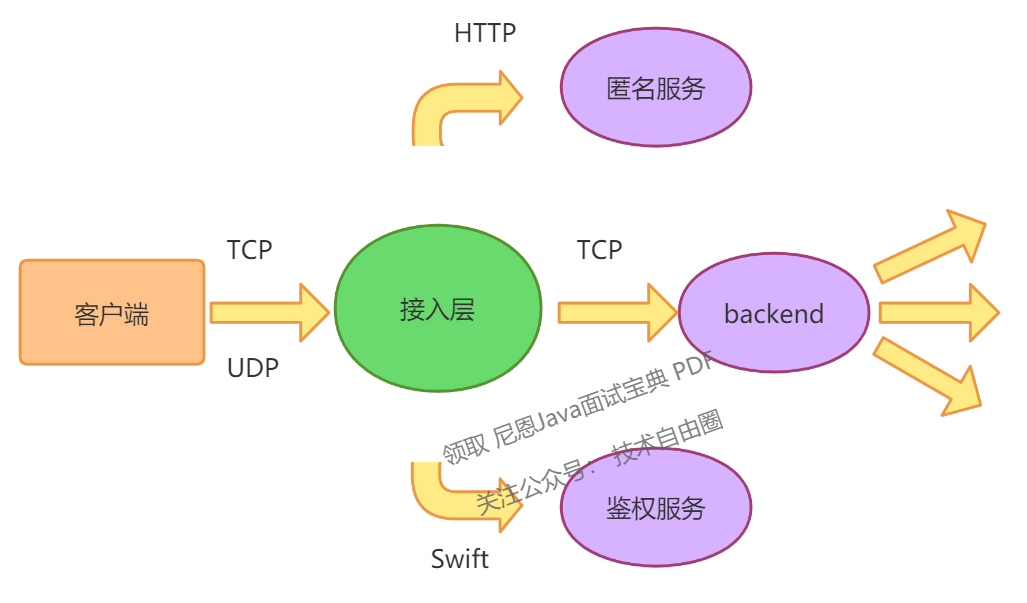
6.2 接入层的功能划分
接入层的主要职责可以概括为以下几点:
- 1)WebSocket 解码:接收到的客户端数据流需根据 WebSocket 协议进行解析;
- 2)保持 Socket 状态:存储连接的基本信息;
- 3)加密与解密:与客户端通讯的数据均需加密,而后端模块间传输为明文 JSON;
- 4)顺序化:同一物理连接上的先后两个请求 A、B 到达服务器,后端服务中 B 可能先于 A 得到响应,但我们需等待 A 完成后,再按 A、B 顺序发送给客户端;
- 5)后端消息分发:接入层不仅对接单个服务,还可能根据不同消息将请求转发至不同服务;
- 6)鉴权:安全相关验证,身份验证等。
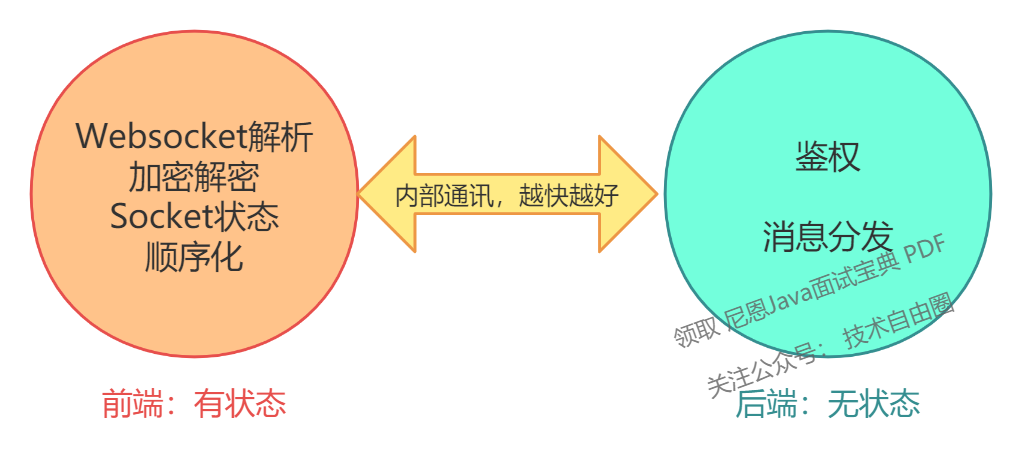
6.3 接入层的拆分思路
把之前的单一模块按照是否有状态,拆分为两个子模块。
具体如下:
- 1)前端:有状态,功能最小化,尽量减少上线;
- 2)后端:无状态,功能最大化,上线时用户无感知。
因此,根据上述原则,理论上我们将实现这样的功能划分,即前端较小,后端较大。示意图如下所示。
7、新版接入层的技术实现
7.1 总览
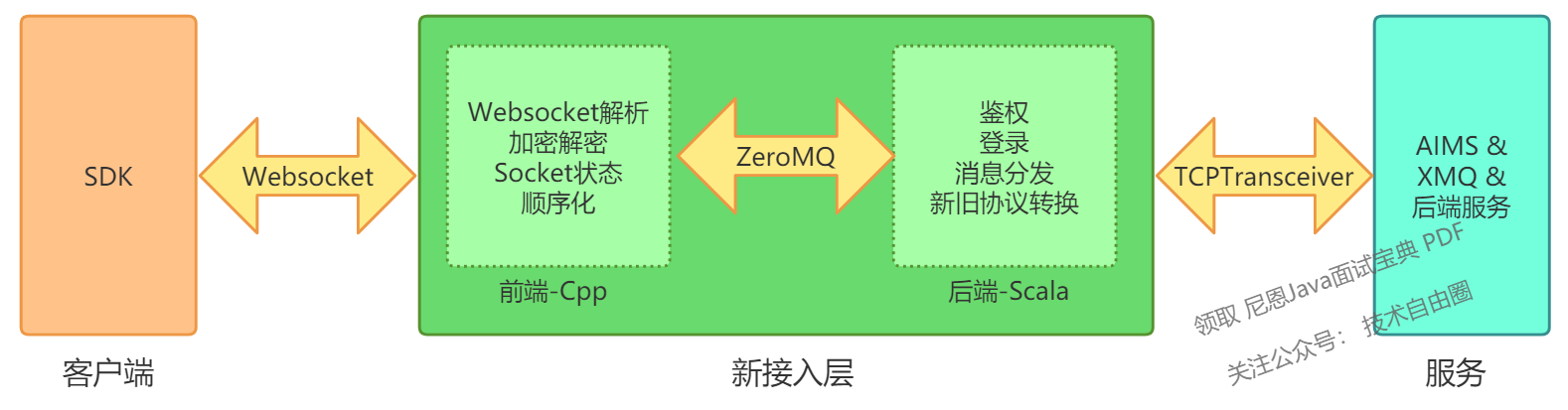
模块拆分为前端和后端:
- 1)前端有状态,后端无状态;
- 2)前端和后端是独立的进程,但在同一台机器上部署。
补充:前端负责维护设备长连接的状态,因此它是有状态的服务;而后端负责处理具体的业务请求,所以它是无状态的服务。后端服务的上线不会导致设备连接中断并重新连接,也不会引发鉴权调用,这样就避免了因为版本升级或逻辑调整而导致的长连接状态的不必要波动。
前端使用C++实现:
- 1)自主解析 WebSocket 协议:可以从 Socket 层面获取所有信息,能够处理任何Bug;
- 2)更高的 CPU 利用率:没有任何额外的 JVM 开销,无GC拖累性能;
- 3)更高的内存利用率:当连接数量增加时,与连接相关的内存消耗也会增加,自行管理可以实现极端优化。
后端暂时使用Scala实现:
- 1)已实现的功能可以直接迁移,比重新编写的成本要低得多;
- 2)部分外部服务(如鉴权)有可以直接使用的 Scala(Java)SDK 库,而没有 C++ 版本,如果用 C++ 重写,成本会非常大;
- 3)全部功能无状态化改造,可以做到随时重启而用户无感知。
通讯使用ZeroMQ:
- 进程间通信最高效的方式是共享内存,ZeroMQ基于共享内存实现,速度没有问题。
7.2 前端实现
整体架构:

如上图所示,由四个子模块组成:
- 1)传输层:Websocket协议解析,XMD协议解析;
- 2)分发层:屏蔽传输层的差异,无论传输层使用何种接口,在分发层转化为统一的事件并投递给状态机;
- 3)状态机层:为了实现纯异步服务,采用自主研发的基于 Actor 模型的类 Akka 状态机框架 XMFSM,该框架内实现了单线程的 Actor 抽象;
- 4)ZeroMQ通讯层:由于 ZeroMQ 接口是阻塞实现,这一层通过两个线程分别负责发送和接收。
7.2.1 传输层:
WebSocket 部分采用 C++和 ASIO 实现 websocket-lib。小爱长连接基于 WebSocket 协议,因此我们自主实现了一个 WebSocket 长连接库。
这个长连接库的特点是:
- a. 无锁化设计,保证性能优秀;
- b. 基于 BOOST ASIO 开发,保证底层网络性能。
压测显示该库的性能十分优异的:
长链接数 qps P99延时 100w 5w 5ms 这一层同时也负责除原始 WebSocket 外,其他两种通道的收发任务。
目前传输层一共支持以下 3 种不同的客户端接口:
- a. websocket(tcp):简称ws;
- b. 基于ssl的加密websocket(tcp):简称wss;
- c. xmd(udp):简称xmd。
7.2.2 分发层:
将不同的传输层事件转化为统一事件并投递给状态机,这一层起到适配器的作用,确保无论前面的传输层使用哪种类型,到达分发层都会变成一致的事件投递给状态机。
7.2.3 状态机处理层:
主要的处理逻辑都在这一层,这里非常重要的一个部分是对发送通道的封装。
对于小爱应用层协议,不同的通道处理逻辑是完全一致的,但在处理和安全相关逻辑上每个通道又有细节差异。
比如:
- a. wss 收发无需加密解密,加密解密由更前端的 Nginx 完成,而 ws 需要使用 AES 加密发送;
- b. wss 在鉴权成功后无需向客户端发送 challenge 文本,因为 wss 不需要做加密解密;
- c. xmd 发送的内容与其他两个不同,是基于 protobuf 封装的私有协议,且 xmd 需要处理发送失败后的逻辑,而 ws/wss 不需要考虑发送失败的问题,由底层 Tcp 协议保证。
针对这种情况:我们使用 C++的多态特性来处理,专门抽象了一个 Channel 接口,这个接口中提供的方法包含了一个请求处理的一些关键差异步骤,如何发送消息到客户端,如何停止连接,如何处理发送失败等等。对于 3 种 (ws/wss/xmd) 不同的发送通道,每个通道有自己的 Channel 实现。
客户端连接对象一创建,对应类型的具体 Channel 对象就立刻被实例化。这样状态机主逻辑中只需实现业务层的公共逻辑即可,当有差异逻辑调用时,直接调用 Channel 接口完成,这样一个简单的多态特性帮助我们分割了差异,确保代码整洁。
7.2.4 ZeroMQ 通讯层:
通过两个线程将 ZeroMQ 的读写操作异步化,同时负责若干私有指令的封装和解析。
7.3 后端实现
7.3.1 无状态化改造:
后端做的最重要改造之一就是将所有与连接状态相关的信息进行剔除。
整个服务以 Request(一次连接上可以传输 N 个 Request)为核心进行各种转发和处理,每次请求与上一次请求没有任何关联。一个连接上的多次请求在后端模块被当作独立请求处理。
7.3.2 架构:
Scala 服务采用 Akka-Actor 架构实现了业务逻辑。
服务从 ZeroMQ 收到消息后,直接投递到 Dispatcher 中进行数据解析与请求处理,在 Dispatcher 中不同的请求会发送给对应的 RequestActor 进行 Event 协议解析并分发给该 event 对应的业务 Actor 进行处理。最后将处理后的请求数据通过 XmqActor 发送给后端 AIMS&XMQ 服务。
一个请求在后端多个 Actor 中的处理流程:

7.3.3 Dispatcher 请求分发:
通过使用 Protobuf,前端和后端可以进行交互,这样可以节省 Json 解析的性能,同时让协议更加规范化。
在接收到 ZeroMQ 发送的消息后,后端服务会在 DispatcherActor 中对 PB 协议进行解析,并根据不同的分类(简称 CMD)进行数据处理,分类如下:
BIND 命令:
这个功能是用来进行设备鉴权的,因为鉴权逻辑复杂,用 C++实现起来比较困难,所以目前仍然在 scala 业务层进行鉴权。这部分主要是解析设备端请求的 HTTP Headers,提取其中的 token 进行鉴权,然后将结果返回给前端。
LOGIN 命令:
这个命令用于设备登录。设备在通过鉴权后,连接已经成功建立,就会执行 LOGIN 命令,将这个长连接信息发送到 AIMS 并记录在 Varys 服务中,以便后续的主动推送等功能。在 LOGIN 过程中,服务首先会请求 Account 服务获取长连接的 uuid(用于连接过程中的路由寻址),然后将设备信息+uuid 发送到 AIMS 进行设备登录操作。
LOGOUT 命令:
这个命令用于设备登出。设备在与服务端断开连接时,需要执行 Logout 操作,用于从 Varys 服务中删除这个长连接记录。
UPDATE 与 PING 命令:
- a. Update 命令,设备状态信息更新,用于更新该设备在数据库中保存的相关信息;
- b. Ping 命令,连接保活,用于确认该设备处于在线连接状态。
TEXT_MESSAGE 与 BINARY_MESSAGE:
文本消息与二进制消息,在收到文本消息或二进制消息时将根据 requestid 发送给该请求对应的RequestActor进行处理。
7.3.4 Request 请求解析:
收到的文本和二进制消息会根据 requestId 被 DispatcherActor 发送给相应的 RequestActor 进行处理。
其中:文本消息会被解析为 Event 请求,然后根据其中的 namespace 和 name 分发给指定的业务 Actor。而二进制消息则会根据当前请求的业务场景被分发给对应的业务 Actor。
7.4 其他优化
在完成新架构 1.0 调整过程中,我们也在不断压测长连接容量,总结几点对容量影响较大的点。
7.4.1 协议优化:
- a. JSON替换为Protobuf:早期的前后端通信采用 JSON 文本协议,但发现 JSON 序列化、反序列化占用 CPU 较多,改用 Protobuf 协议后,CPU 占用率明显下降。
- b. JSON支持部分解析:由于业务层协议基于 JSON,无法直接替换,我们采用“部分解析 JSON”的方式,仅解析较小的 header 部分获取 namespace 和 name,然后将大部分直接转发的消息转发出去,只对少量 JSON 消息进行完整反序列化成对象。此种优化后 CPU 占用下降 10%。
7.4.2 延长心跳时间:
在首次测试 20w 连接时,我们发现在前后端收发的消息中,用于保持用户在线状态的心跳 PING 消息占总消息量的 75%,收发这个消息消耗了大量 CPU。因此,我们延长心跳时间,也达到了降低 CPU 消耗的目的。
7.4.3 自研内网通讯库:
为提高与后端服务通信性能,我们使用自研的 TCP 通讯库,该库基于 Boost ASIO 开发,是一个纯异步的多线程 TCP 网络库,其优异性能帮助我们将连接数提升到 120w+。
8、未来规划
经过新版架构1.0版的优化,验证了我们的拆分方向是正确的,因为预设的目标已经达到:
- 1)单机承载的连接数 28w => 120w+(普通服务端机器 16G内存 40核 峰值请求QPS过万),接入层下线节省了50%+的机器成本;
- 2)后端可以做到无损上线。
再重新审视下我们的理想目标,以这个为方向,我们就有了2.0版的雏形:

具体就是:
- 1)后端模块使用C++重写,进一步提高性能和稳定性。同时将后端模块中无法使用C++重写的部分,作为独立服务模块运维,后端模块通过网络库调用;
- 2)前端模块中非必要功能尝试迁移到后端,让前端功能更少,更稳定;
- 3)如果改造后,前端与后端处理能力差异较大,考虑到ZeroMQ实际是性能过剩的,可以考虑使用网络库替换掉ZeroMQ,这样前后端可以从1:1单机部署变为1:N多机部署,更好的利用机器资源。
2.0版目标是:经过以上改造后,期望单前端模块可以达到200w+的连接处理能力。
说在最后:有问题可以找老架构取经
架构之路,充满了坎坷
架构和高级开发不一样 , 架构问题是open/开放式的,架构问题是没有标准答案的
正由于这样,很多小伙伴,尽管耗费很多精力,耗费很多金钱,但是,遗憾的是,一生都没有完成架构升级。
所以,在架构升级/转型过程中,确实找不到有效的方案,可以来找40岁老架构尼恩求助.
前段时间一个小伙伴,他是跨专业来做Java,现在面临转架构的难题,但是经过尼恩几轮指导,顺利拿到了Java架构师+大数据架构师offer 。所以,如果遇到职业不顺,找老架构师帮忙一下,就顺利多了。
推荐阅读
《阿里2面:你们部署多少节点?1000W并发,当如何部署?》
《网易一面:25Wqps高吞吐写Mysql,100W数据4秒写完,如何实现?》
《尼恩 架构笔记》《尼恩高并发三部曲》《尼恩Java面试宝典》PDF,请到下面公号【技术自由圈】取↓↓↓
-
相关阅读:
【Java面试小短文】Cookie和Session的区别
预测市场赛道新机遇:Moonquiz生态基于FIFA WORLD CUP推出首个预测应用
惠普星15和联想小新pro16 哪个好
《c++ Primer Plus 第6版》读书笔记(3)
【JAVA入门】JUnit单元测试、类加载器、反射、注解
【车载开发系列】S19/HEX/BIN文件解析
AUTOSAR知识点 之NvM(一):存储栈整体介绍(偏从ASW到BSW的配置与基础概念性质)
多线程可见
Allegro电商平台:为卖家打开全球市场,为消费者带来无限选择
18. 机器学习——集成学习
- 原文地址:https://blog.csdn.net/crazymakercircle/article/details/132941352