-
Pytorch学习笔记(模型训练)
模型训练
在同一个包下创建
train.py和model.py,按照步骤先从数据处理,模型架构搭建,训练测试,统计损失,如下面代码所示train.py
import torch.optim import torchvision from torch import nn from torch.utils.data import DataLoader from torch.utils.tensorboard import SummaryWriter from model import NNN # 1. 准备数据集 train_data = torchvision.datasets.CIFAR10("./data", train=True, transform=torchvision.transforms.ToTensor(), download=True) test_data = torchvision.datasets.CIFAR10("./data", train=False, transform=torchvision.transforms.ToTensor(), download=True) train_data_size = len(train_data) test_data_size = len(test_data) print(f"训练数据集的长度:{train_data_size}") print(f"测试数据集的长度:{test_data_size}") # 2. 利用DataLoader 加载数据集 train_dataloader = DataLoader(train_data, batch_size=64) test_dataloader = DataLoader(test_data, batch_size=64) # 3. 搭建神经网络 # 引入model.py nnn = NNN() # 4. 创建损失函数loss loss_fn = nn.CrossEntropyLoss() # 交叉熵 # 5. 优化器 learning_rate = 0.01 optimizer = torch.optim.SGD(nnn.parameters(), lr=learning_rate) # 随机梯度下降 # 6. 设置训练网络的一些参数 total_train_step = 0 # 记录训练次数 total_test_step = 0 # 训练测试次数 epoch = 10 # 训练轮数 # 补充tensorboard writer = SummaryWriter("../logs") # 开始训练 for i in range(epoch): print(f"--------第{i+1}轮训练开始--------") # 训练 nnn.train() for data in train_dataloader: imgs, targets = data outputs = nnn(imgs) loss = loss_fn(outputs, targets) optimizer.zero_grad() loss.backward() optimizer.step() total_train_step += 1 if total_train_step % 100 == 0: print(f"训练次数:{total_train_step}---loss:{loss.item()}") writer.add_scalar("train_loss", loss.item(), total_train_step) # 测试 nnn.eval() total_test_loss = 0 # 总体的误差 total_accuracy = 0 # 总体的正确率 with torch.no_grad(): for data in test_dataloader: imgs, targets = data outputs = nnn(imgs) loss = loss_fn(outputs, targets) total_test_loss += loss.item() accuracy = (outputs.argmax(1) == targets).sum() total_accuracy += accuracy print(f"整体测试集上的loss:{total_test_loss}") print(f"整体测试集上的准确率:{total_accuracy/test_data_size}") writer.add_scalar("test_loss", total_test_loss, total_test_step) writer.add_scalar("total_accuracy", total_accuracy/test_data_size, total_test_step) total_test_step += 1 # 保存每一轮训练的模型 torch.save(nnn, f"nnn_{i+1}.pth") print("模式已保存") writer.close()- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 61
- 62
- 63
- 64
- 65
- 66
- 67
- 68
- 69
- 70
- 71
- 72
- 73
- 74
- 75
- 76
- 77
- 78
- 79
- 80
- 81
- 82
- 83
- 84
- 85
model.py

import torch from torch import nn # 搭建神经网络 class NNN(nn.Module): def __init__(self): super(NNN, self).__init__() self.model = nn.Sequential( nn.Conv2d(3, 32, 5, stride=1, padding=2), nn.MaxPool2d(kernel_size=2), nn.Conv2d(32, 32, 5, stride=1, padding=2), nn.MaxPool2d(kernel_size=2), nn.Conv2d(32, 64, 5, stride=1, padding=2), nn.MaxPool2d(2), nn.Flatten(), nn.Linear(1024, 64), nn.Linear(64, 10) ) def forward(self, x): x = self.model(x) return x if __name__ == '__main__': nnn = NNN() input = torch.ones((64, 3, 32, 32)) output = nnn(input) print(output.shape)- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
运行
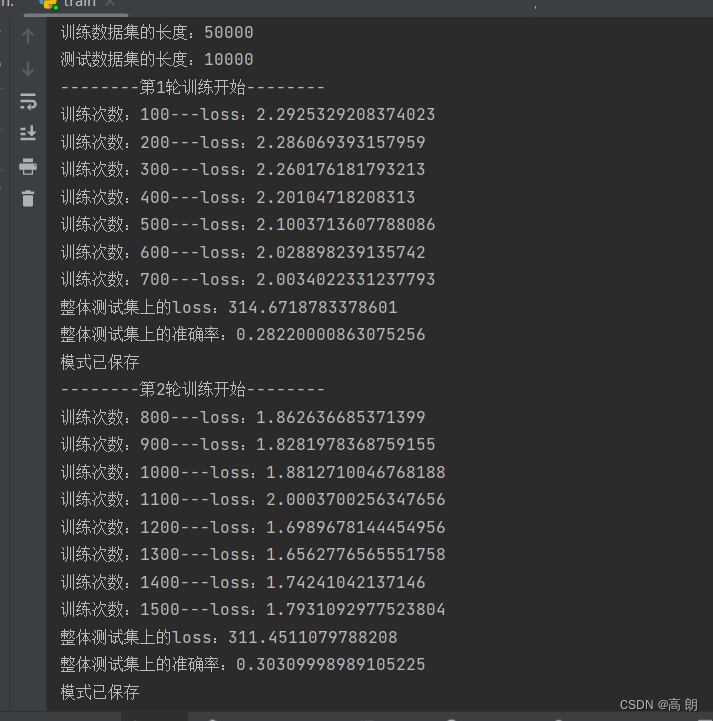
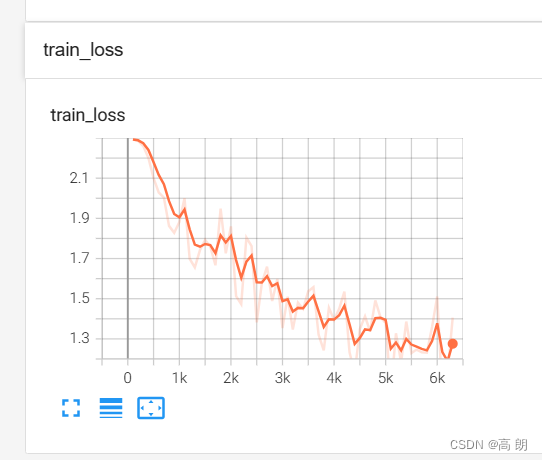
train.py后可以通过启动tensorboard进行查看我们的loss情况,损失是不断下降的。

 补充
补充argmax函数的使用
我们模型预测处理的是概率,我们需要使用argmax函数还得到预测的结果,就是选出概率最大的,上面测试准确率的计算使用到了。
简单代码示例:import torch # 模型输出的概率 outputs = torch.tensor([[0.1, 0.3], [0.7, 0.2]]) # 真实的分类 targets = torch.tensor([[1, 1]]) # 对概率进行预测 preds = outputs.argmax(1) # 1:横向比较 0:竖向比较 # 预测与真实进行比较 print(preds == targets) print((preds == targets).sum().item()) # 统计正确的个数- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
输出:
tensor([[ True, False]]) 1- 1
- 2
-
相关阅读:
看到这个应用上下线方式,不禁感叹:优雅,太优雅了!
[stm32]温湿度采集与OLED显示
TYFLOW学习23
tar.gz文件修复
C++ Reference: Standard C++ Library reference: Containers: array: array
java考试编排管理系统计算机毕业设计MyBatis+系统+LW文档+源码+调试部署
【MongoDB】Ubuntu22.04 下安装 MongoDB | 用户权限认证 | skynet.db.mongo 模块使用
深入探讨Kubernetes(K8s)在云原生架构中的关键作用和应用
Map介绍
unity---Mesh网格编程(六)
- 原文地址:https://blog.csdn.net/qq_43466788/article/details/132919914
