-
《Linux从练气到飞升》No.22 Linux 基础IO
🕺作者: 主页
😘欢迎关注:👍点赞🙌收藏✍️留言
🏇码字不易,你的👍点赞🙌收藏❤️关注对我真的很重要,有问题可在评论区提出,感谢阅读!!!
文章目录
前言
在本篇之前我们讲的大部分都是关于进程的相关知识,从本篇开始我将带领大家进入IO的世界,常听闻Linux下一切皆文件,它到底是什么意思?文件的定义是什么?让我们开始学习起来吧!
1.预备知识-从系统角度理解文件
1.1 文件 = 内容 + 属性
之前我们讲过文件 = 内容 + 属性,这很好理解,一个文件不仅包括它的内容还包括一些描述内容的属性,比如大小、格式、存储位置等等,但是这里要强调的是属性和内容一样都是数据。
1.2 文件的操作类型
文件的所有操作无外乎两种:
1. 对内容
2. 对属性1.3 怎么访问文件?
文件在磁盘(硬件)上放着,我们访问文件的流程:
先写代码 → 编译 → exe文件 → 运行 → 访问文件本质是谁在访问文件?
进程要向硬件写入只有谁有权力?
操作系统(通过驱动程序等)普通用户也想写入怎么办?
必须调用操作系统提供的文件类的系统调用接口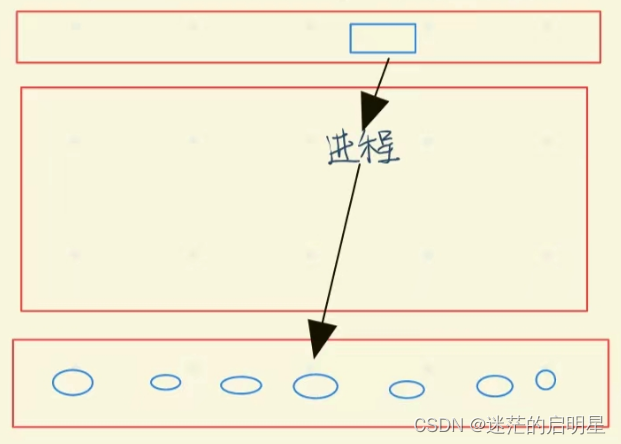
文件类的系统调用接口,为什么之前都没怎么听过呢?
1。因为它比较难,为了让接口更好的使用,语言上对这些接口做了封装,这也导致了不同的语言有不同的语言级别的文件访问接口(都不一样),但是封装的都是系统接口。为什么要学习OS层面上的文件接口呢?这样的接口只有一套。
为什么呢?因为你正在使用的操作系统只有一个。2。跨平台
如果语言不提供对文件的系统接口的封装是不是所有的访问文件的操作,都必须直接使用OS的接口?
是。而用语言的客户要不要访问文件呢?
当然要一旦使用系统接口,编写所谓的文件代码,无法在其他的平台中直接运行了,就不具备跨平台性。
怎么做到跨平台的?
把所有的平台的代码都实现一遍,使用条件编译,然后动态裁剪。1.4 显示器是硬件吗?
printf向显示器打印,为什么从来没有感到奇怪过?
因为它比较直观,但是其实它和磁盘写入没有本质区别。1.5 怎么理解Linux下一切皆文件?
曾经我们理解的文件就是
- .exe文件、.c文件、.txt文件这样的 → 可以进行read、write等操作。
- 显示器:printf、cout → 可以进行write操作
- 键盘:scanf、cin → 可以进行read等操作
站在我们写程序的角度,这个操作是加载到内存
站在内存的角度它则是执行input(read)、output(write)
普通文件的写入过程:
普通文件 → fopen/fread → 进程内部(内存) → fwrite → 文件中
|------------------- input -----------------|------------------ output ---------|1.6 总结
1.6.1 什么叫文件?
站在系统角度,能够被
input读取,或者能够output写出的设备就叫做文件狭义的文件:普通磁盘文件
广义的文件:显示器、键盘、网卡、声卡等几乎所有的外设,都可以称之为文件。
1.6.2 文件种类
文件有两种:
1、被进程打开的文件(内存文件)
2、没有被打开的文件(磁盘上,文件=内容➕属性)(磁盘文件)1.6.3 文件属性从哪里来?
来自磁盘,在打开文件时会将属性载入到struct file结构体中.【后面详细了解】
2. 复习一下接口使用
2.1 C语言接口
vim下——底行模式
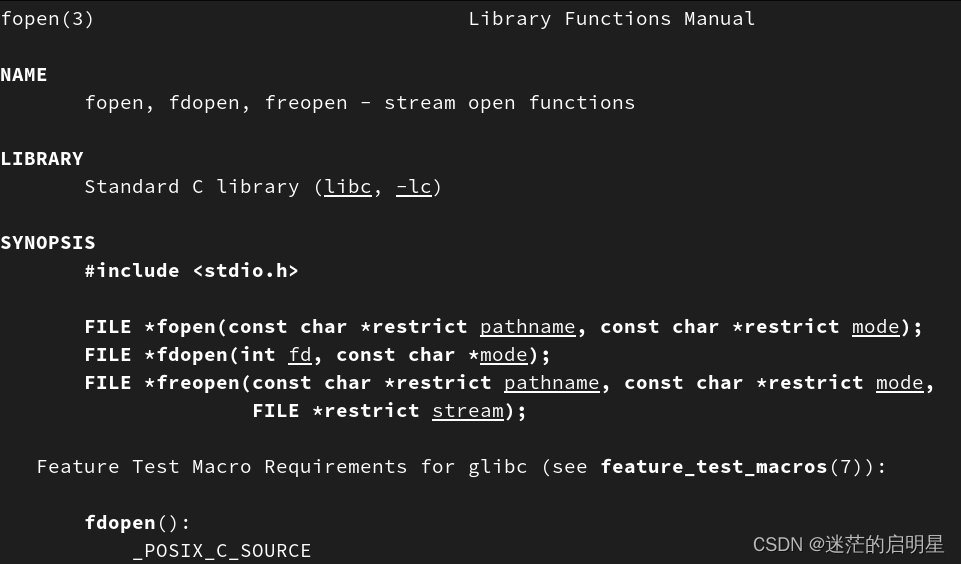
!man fopen- 1
(【查看fopen】,查看其他的接口也是同样的)
使用一下
mycode.c#include#include int main(int argc, char *argv[]) { FILE *fp = fopen("log.txt","w"); if(fp==NULL) { perror("fopen"); return 1; } const char*s1 = "hello fwrite"; fwrite(s1,strlen(s1),1,fp); fclose(fp); return 0; } - 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
运行后向log.txt写入文件

2.2 什么是当前路径?
当一个进程运行起来的时候,每个进程都会记录自己当前所处的工作路径,这个叫进程的工作路径,也叫当前路径。
... cwd(当前工作目录) -> /home/venus/linuxtest/5_基础IO/test_c- 1
举例:
为了让大家看到进程的情况,所以我们直接设计一个死循环的函数#includeint main(){ while(1){} return 0; } - 1
- 2
- 3
- 4
- 5
- 6
查看进程:
[venus@localhost test_c]$ ps ajx | head -1 && ps ajx | grep mycode PPID PID PGID SID TTY TPGID STAT UID TIME COMMAND 3063 3468 3468 3063 pts/0 3468 S+ 1000 0:01 vim mycode.c 4583 6982 6982 4583 pts/1 6982 R+ 1000 2:15 ./mycode 6983 7064 7063 6983 pts/2 7063 S+ 1000 0:00 grep --color=auto mycode [venus@localhost test_c]$ ls /proc/4583 -l 总用量 0 ... -r--r--r--. 1 venus venus 0 8月 31 18:02 cpuset lrwxrwxrwx. 1 venus venus 0 8月 31 18:02 cwd -> /home/venus/linuxtest/5_基础IO/test_c -r--------. 1 venus venus 0 8月 31 18:02 environ lrwxrwxrwx. 1 venus venus 0 8月 31 18:02 exe -> /usr/bin/bash dr-x------. 2 venus venus 0 8月 31 18:02 fd dr-xr-xr-x. 2 venus venus 0 8月 31 18:02 fdinfo -rw-r--r--. 1 venus venus 0 8月 31 18:02 gid_map -r--------. 1 venus venus 0 8月 31 18:02 io ...- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
此时创建文件test.txt,就会用当前路径加上创建文件的文件名,再利用系统接口来创建文件。
2.3 文件写入接口问题
示例代码:
#include#include int main(int argc, char *argv[]) { FILE *fp = fopen("log.txt","w"); if(fp==NULL) { perror("fopen"); return 1; } const char*s1 = "hello fwrite\n"; fwrite(s1,strlen(s1),1,fp); const char*s2 = "hello fprintf\n"; fprintf(fp,"%s",s2); const char*s3 = "hello fputs\n"; fputs(s3,fp); fclose(fp); return 0; } - 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
2.3.1 写入是时要不要使用strlen(s1)+1[也就是要不要考虑\0?]
不用考虑,因为\0是C语言的规定,文件不用遵守,文件保存的是有效数据。
2.3.2 tips
⚡fopen以w的方式打开文件时,会直接清空文件
⚡ '>'符号,输出重定向这样使用时也是fopen的相同原理和效果↓
> log.txt- 1
log.txt文件会被清空
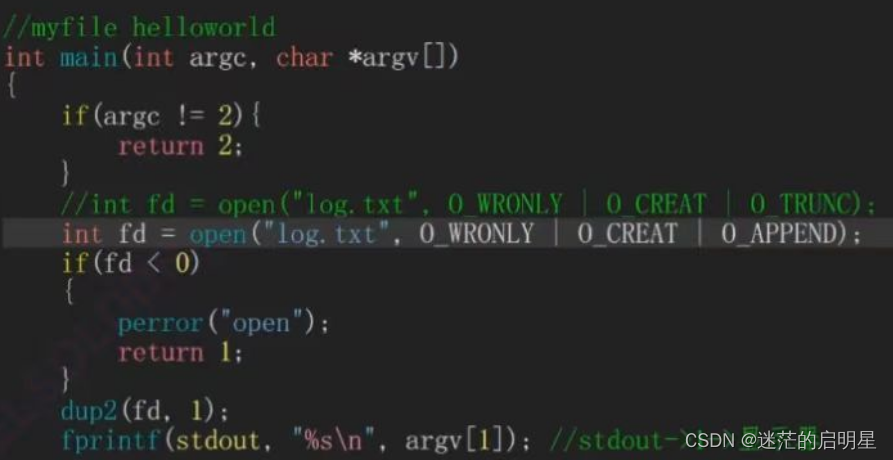
⚡以a(append)的方式打开则是追加
⚡以r的方式打开是只读
回想一下其实cat命令的底层其实也是只读,不过是把文件内容打印到了显示器上而已,那我们来简单实现一个cat命令。#includeint main(int argc,char *argv[]) { if(argc != 2) { printf("argv error!\n"); return 1; } FILE *fp = fopen(argv[1],"r"); if(fp==NULL) { perror("fopen"); return 2; } char line[64]; while(fgets(line,sizeof(line),fp)!=NULL) { fprintf(stdout,"%s",line); } return 0; } - 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
这样,我们就可以利用它来查看文件,如下:
2.2 系统接口(open、close、read、write)
2.2.1 C库函数与系统接口的对应:
C库函数:fopen fclose fread fwrite
系统接口:open close read write
2.2.2 系统接口的使用
2.2.2.1 open
以open为例
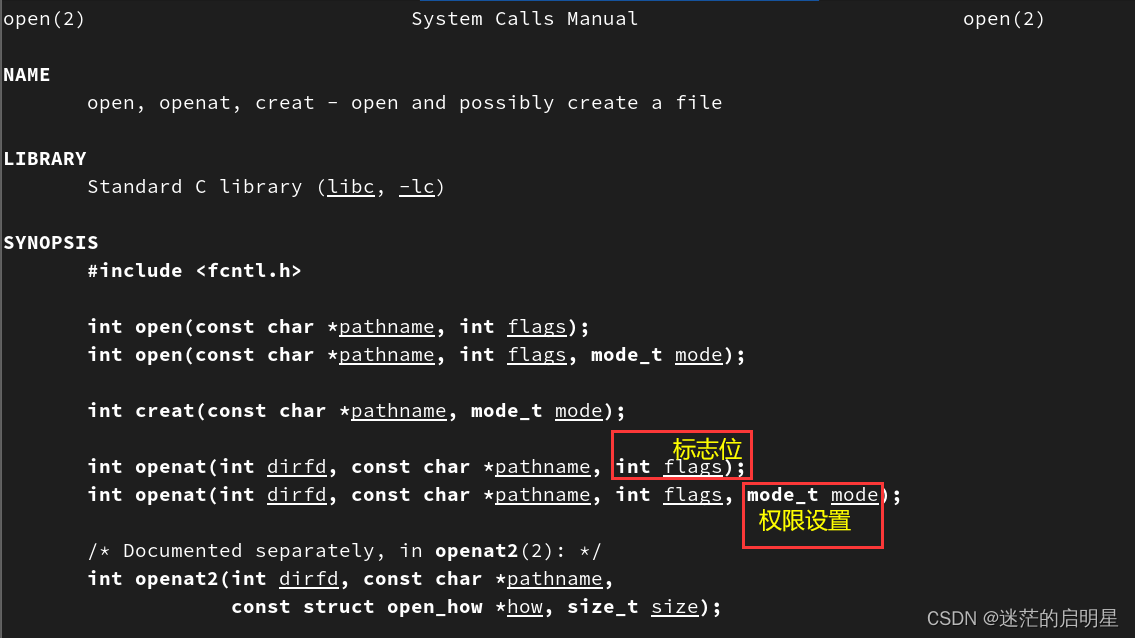
open成功后会返回file descriptor 失败返回-1

以写的方式打开:O_WONLY
举例:#include#include int main() { int fd=open("log.txt",O_WONLY); ... return 0; } - 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
但是只有这个就可以创建文件了吗?
非也!
你在应用层看到一个很简单的动作,在系统层甚至OS层面,可能要做非常多的动作。
修改后#include#include #include int main() { umask(0);//为了不影响我们测试,将该文件的掩码改为0 //umask函数用于设置文件创建时的权限掩码 int fd=open("log.txt",O_WONLY|O_CREATE,0666); ... return 0; } - 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
2.2.2.2 标志位
open 函数是用于打开文件的系统接口。
其中的flags参数用于指定打开文件的方式和属性
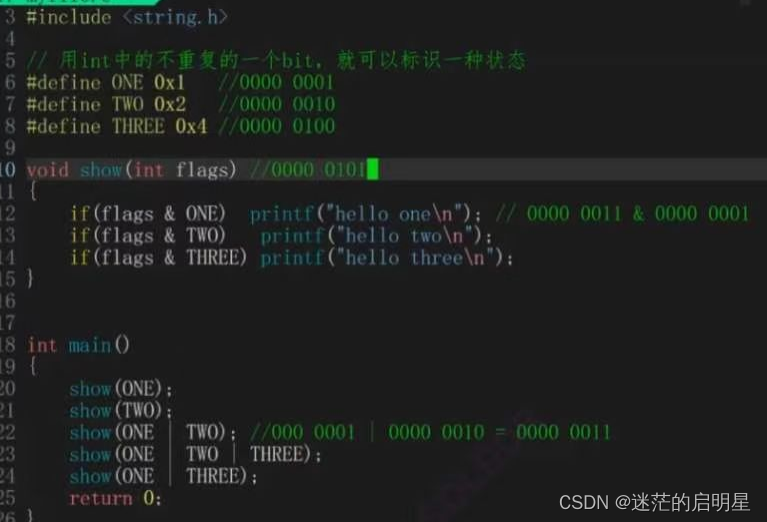
flags参数是一个整数值,可以使用不同的标志位进行按位或(bitwise OR)操作,以同时提供多个选项
以下是常见的些fags参数选项
- O_RDONLY:以只读方式打开文件
- O_WRONLY:以只写方式打开文件
- O_RDWR:以读写方式打开文件
- O_CREAT:如果文件不存在,则创建文件
- O_APPEND:追加方式打开文件,写入数据时会在文件未尾添加而不是覆盖原有内容
- O_TRUN:如果文件存在且成功打开,将其长度截断为0。
- O_EXCL:与O_CREAT一起使用,如果文件已存在,则打开失败
**当flags参数等于0时,它表示没有指定何特殊选项,默认使用最基本的打开方式。相当于只读方式打开文件,类似于O_RDOMLY。**需要注意的是,flags参数的含义可能受到操作系统和文件系统的影响,因此在实际使用时应参考相关文档和规范来确定具体行为。
操作系统传递标志位的一种方案:
2.2.2.3 close
关闭文件

... close(fd); ...- 1
- 2
- 3
2.2.2.4 write
写入

... const *s="hello world!\n" write(fd,s,strlen(s));//strlen(s)不需要+1,前面解释过了 ...- 1
- 2
- 3
- 4
继续写入呢?
... const *a="aa" write(fd,a,strlen(a)); ...- 1
- 2
- 3
- 4
预测结果显示
aa,因为之前我们说写入会先清空再写入。
实际上:显示aallo world!之前说过在应用层一个简单的动作,其实底层并不简单,
我们要在open时int fd=open("log.txt",O_WONLY|O_CREATE,0666);- 1
上加上
O_TRUNC

变为:
int fd=open("log.txt",O_WONLY|O_CREATE|O_TRUNC,0666);- 1
那
w+底层是什么样的?需要加上
O_APPEND

int fd=open("log.txt",O_WONLY|O_CREATE|O_APPEND,0666);- 1
2.2.2.5 read
读取
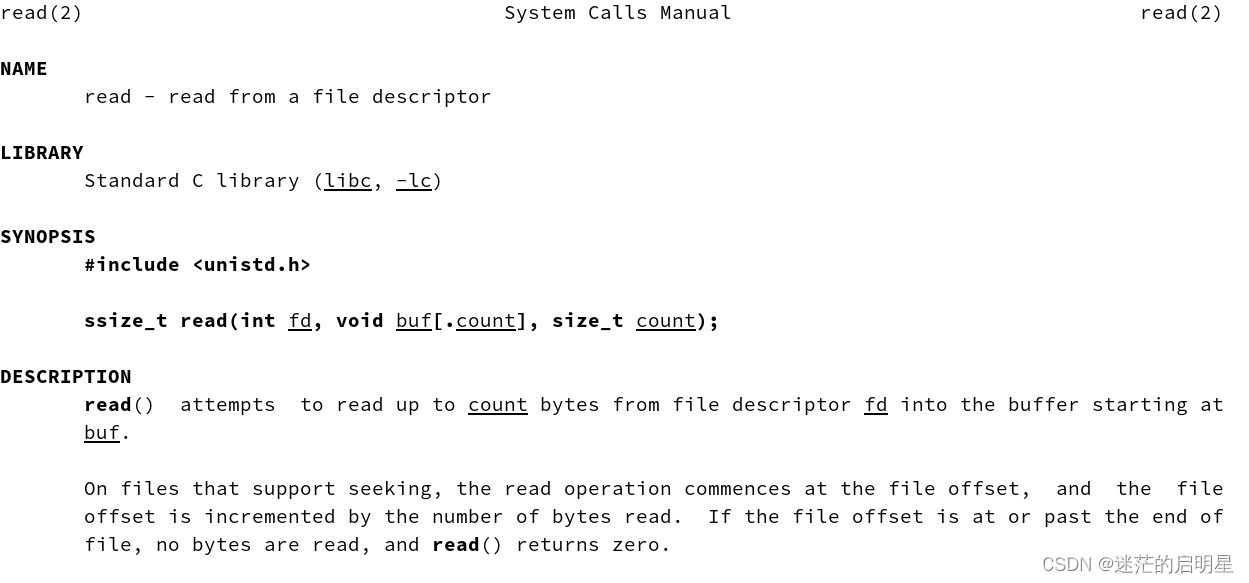
int fd=open("log.txt",O_RDONLY)- 1
3. 分析接口细节,引入fd(文件描述符)
3.1 如何深入理解?
当我们连续写入
↓int fd1=open("log.txt",O_WONLY|O_CREATE|O_TRUNC,0666); printf("%d\n",fd1); ... int fd4=open("log.txt",O_WONLY|O_CREATE|O_TRUNC,0666); printf("%d\n",fd4); //关闭 close(fd1) ... close(fd4)- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
cat log.txt- 1
结果显示:
3 4 5 6- 1
- 2
- 3
- 4
那么0 1 2在哪里?
其实:
它们分别对应着stdin → 0 标准输入
stdout → 1 标准输出
stderr → 2 标准错误怎么验证?它们之间是什么关系?
往1里面写,依旧可以输出到显示器上
fprintf(stdout,"hello stdout\n"); //等效于↓ const char *s="hello stdout\n"; write(1,s,strlen(s));- 1
- 2
- 3
- 4
读取到0里面,依旧可以输入到显示器上
char input[16]; ssize_t s=read(0,input,sizeof(input)); if(s>0) { input[s]='\0'; printf("%s\n",input); }- 1
- 2
- 3
- 4
- 5
- 6
- 7
3.2 FILE是什么?
之前我们使用过fopen函数,它的返回值是一个指向
FILE的指针FILE *fopen(const char *path,const char *mode)- 1
FILE是什么?
它是由C标准库提供的一个结构体,内部有多种成员。
我们知道,C文件、库函数内部一定要调用系统调用的。在系统角度,它是认FILE还是fd呢?
只认fd!所以FILE中必定封装了fd
所以stdin、stdout、stderr→都是 FILE* →都含有 fd
怎么证明?printf("stdin:%d\n",stdin->_fileno); printf("stdout:%d\n",stdout->_fileno); printf("stderr:%d\n",stderr->_fileno);- 1
- 2
- 3
输出结果:
stdin:0 stdout:1 stderr:2- 1
- 2
- 3
4.周边文件(fd的理解,fd和FILE的关系,fd分配规则,fd和重定向,缓冲区?)
4.1 fd的理解
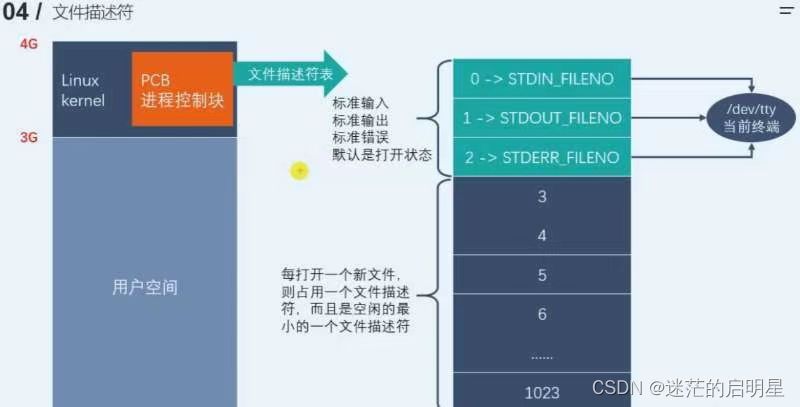
- 进程要访问文件,必须先打开文件。
- 进程可以打开多个文件吗?
- 一般而言,进程:打开文件 = 1:n
- 文件要被访问,前提是加载到内存中,才能被直接访问。
- 进程:打开文件 = 1:n -> 如果有多个进程都打开自己的文件呢?
- 系统会存在大量的被打开的文件!
- 所以os要不要把如此多的文件也管理起来呢?
- 要,先描述,再组织!
- 那么在内核中如何看待打开的文件?OS为了管理每一个被打开的文件,构建
struct file { struct file *next; struct file *prev; //包含一个被打开的文件的几乎所有的内容,不仅仅是属性 }- 1
- 2
- 3
- 4
- 5
- 6
它会创建struct file 的对象,充当一个被打开的文件,如果有很多就用双向链表组织起来。

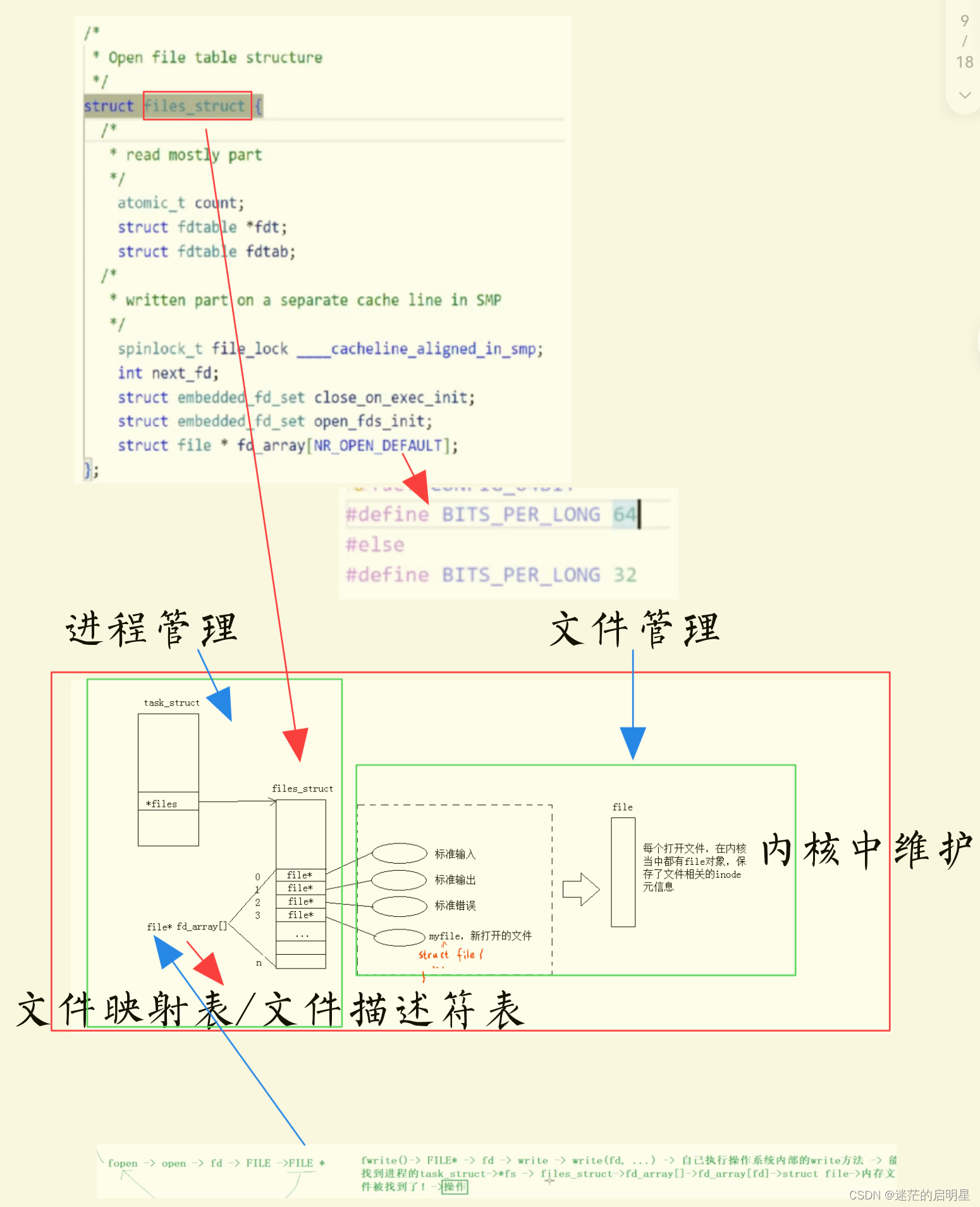
进程和文件的对应关系是怎样的?
每一个进程都有一个task_struct,这个task_struct会指向一个struct files_struct结构体,这个结构体里会有一个指针数组struct file* fd_array[32],而这个指针数组就是文件描述符对应的数组。
fd的本质是一个数组下标!
4.2 fd和FILE的关系
4.3 fd分配规则
最小的、没有被占用的文件描述符
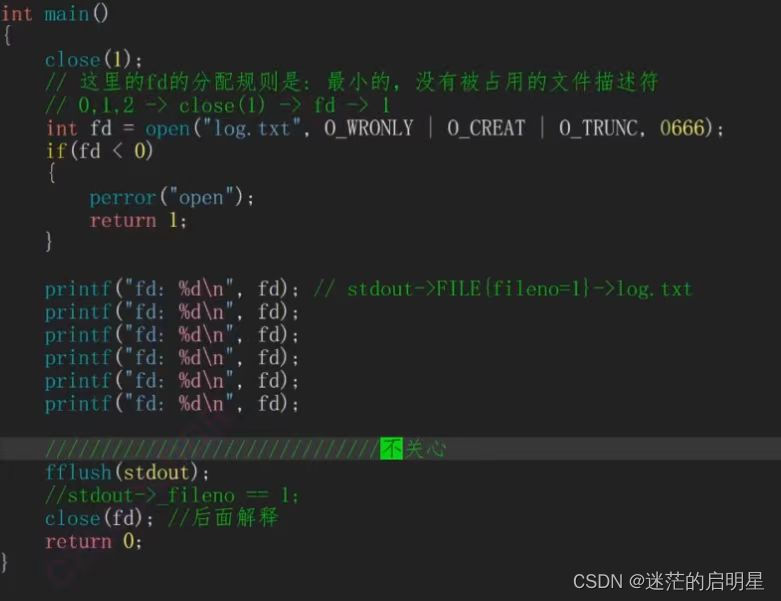
4.4 fd和重定向
close(1)后,fd=1,根据fd的分配原理,就都打印到了文件里,这个功能叫做输出重定向.
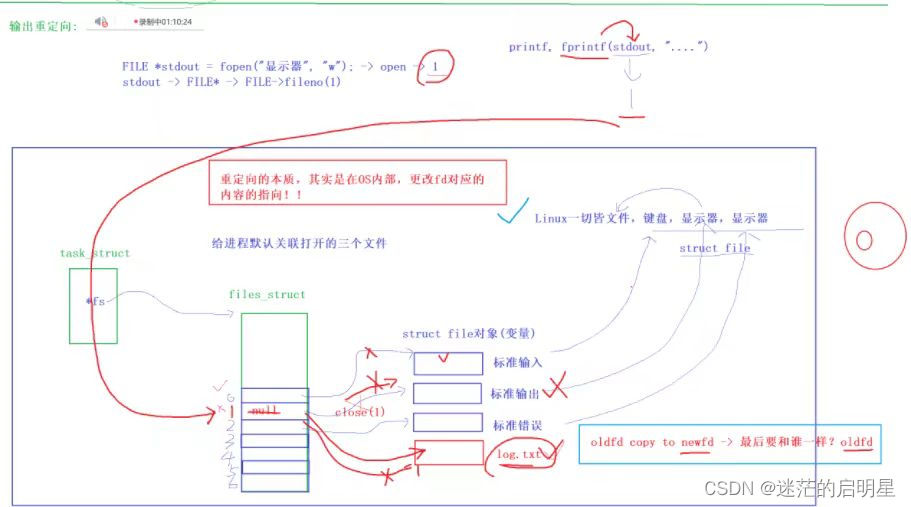
输出重定向原理:
系统一开始会给进程默认关联打开的三个文件:标准输入、标准输出、标准错误,它们在内核中都是一个struct_file对象,重定向的本质其实是在OS内部更改fd的对应的内容的指向。
4.4.1 dup
4.4.1.1 查看手册
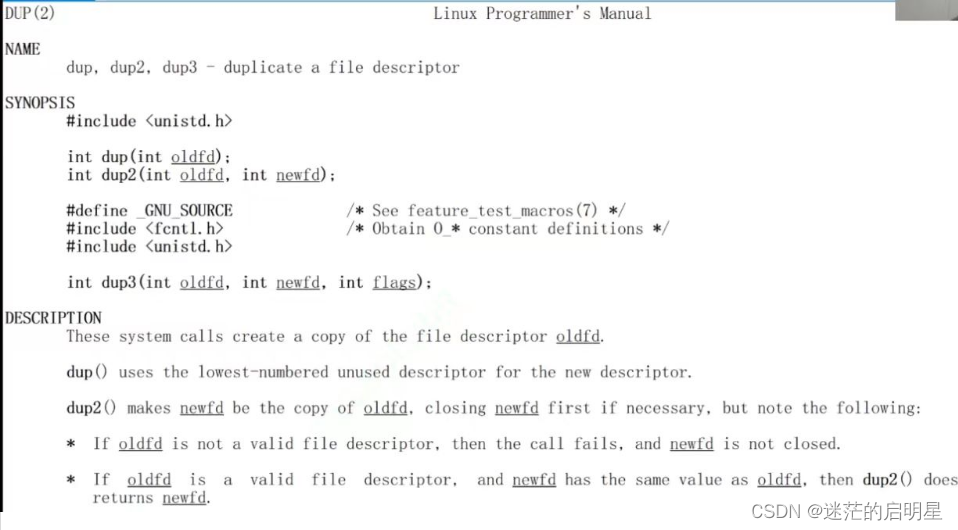
4.4.1.2 原理
oldfd copy to newfd → 最后要和oldfd一样
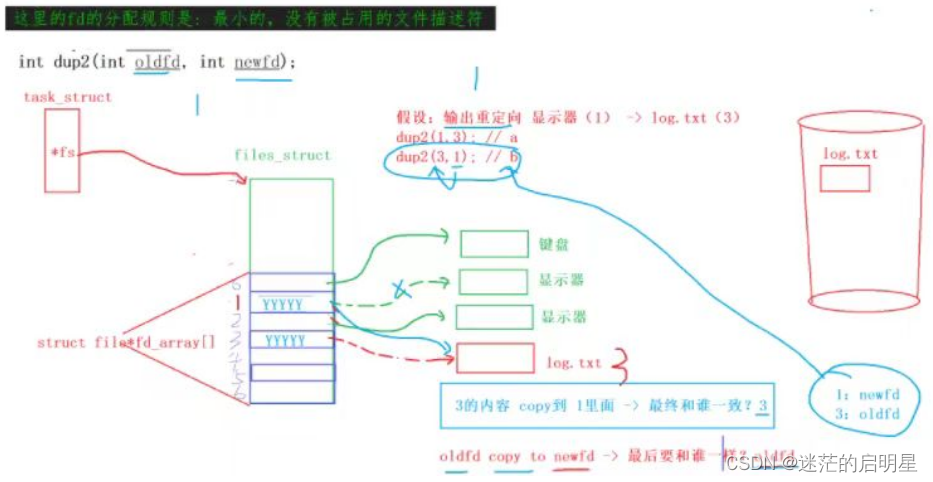
4.4.1.3 测试代码
输出重定向
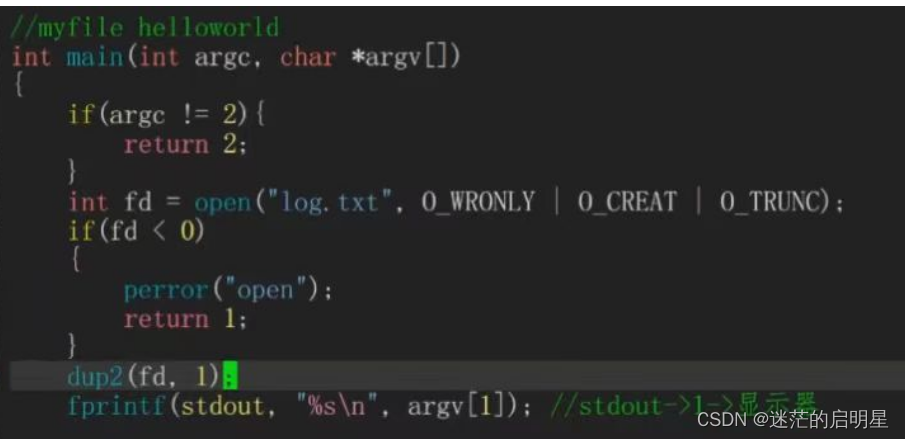
追加重定向
5. 如何理解一切皆文件?
如何理解一切皆文件?
这是Linux的设计哲学,它体现在操作系统的软件设计层面。
我们用一个例子来理解一下:
我们知道Linux是C语言写的,那么我们如何用C语言来实现面向对象呢?甚至是多态?
面向对象需要利用到类来实现,它里面包含成员属性和成员方法,在C语言中有没有类似的结构?有!struct。但是它能包含成员方法吗?不能。但是有没有办法来解决这个问题呢?有的!比如下面这样:

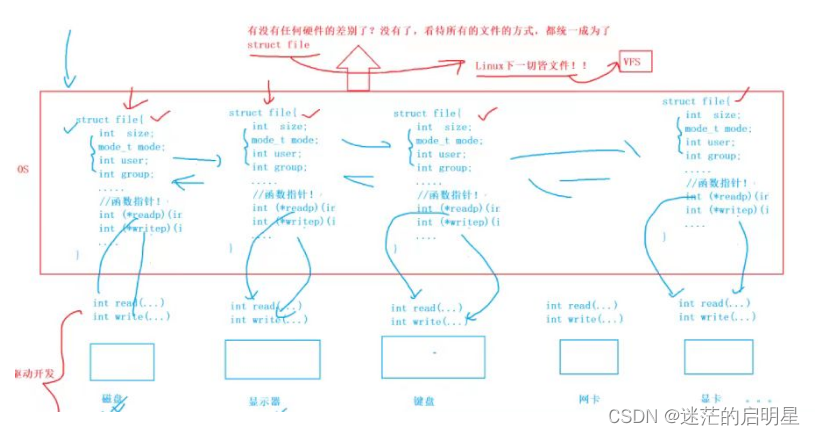
再讲一下:外设与文件。
我们应该知道底层不同的硬件,一定对应的是不同的操作方法,但是上面的设备都是外设,所以每一个设备的核心访问函数都可以是read、write…但是代码的实现一定是不一样的!所以就需要struct_file来对它进行管理,但是OS对磁盘上的文件也是这样管理的,所以到这里我们发现它们没有任何区别了,看待所有文件的方式统一成为struct_file。
具体原理:struct_file与文件的交互,相同的函数,不同的实现方式也就是 多态,这也就是C++的前身。
6. 缓冲区
6.1 什么是缓冲区?
缓冲区是内存中的一部分预留空间,用于存储输入或输出的数据。具体来说,缓冲区可以由专门的硬件寄存器组成,也可以利用内存作为缓冲区。缓冲区是由计算机系统的内存管理单元(MMU)或操作系统来维护的,而不是由某个特定实体提供。

不同的程序有各自不同的缓冲区。缓冲区可以根据其行为分为三类:全缓冲、行缓冲和无缓冲。全缓冲是指只有在缓冲区完全填满后才会执行 I/O 操作,一个典型的例子是对磁盘文件的读写。行缓冲则是在输入或输出过程中遇到换行符时才会执行 I/O 操作,这使得我们可以一次只写一个字符,但只有在写完一行之后才会进行 I/O 操作。通常,标准输入流(stdin)和标准输出流(stdout)是行缓冲。无缓冲是指标准 I/O 不缓存字符,表现最明显的是标准错误输出流(stderr),它使得出错信息能够尽快返回给用户。每个进程都有自己独立的缓冲区,称为进程缓冲区。因此,用户程序的 I/O 读写操作,大多数情况下并没有直接进行实际的 I/O,而是在读写自己的进程缓冲区。
但是所有的设备都倾向于全缓冲,只有在缓冲区满时才会刷新,这样可以减少IO操作次数,从而减少外设访问次数,提高效率。与外部设备进行IO操作时,数据量大小并不是主要矛盾,而是与外设预备IO的过程最为耗费时间。其他策略是根据实际情况而定的,例如在显示器上,需要兼顾效率和用户体验,在极端情况下可以自定义规则。
6.2 问题
同样一个程序,向显示器打印输出4行文本,
向普通文件(磁盘上)打印的时候变成了7行,
其中:- C IO接口是打印了两次
- 系统接口只打印了一次和向显示器打印一样
上面的测试,并不影响系统接口,如果有缓冲区,由谁维护呢?
C标准库还是OS呢?
我们“曾经所谈的缓冲区”,绝对不是由操作系统提供的,如果由操作系统统一提供,我们上面的代码表现应该是一样的,所以只能是C标准库提供的。
- 在fork前加上fflush(stdout),再向普通文件打印,发现也变成4行了,
为什么❓
因为它把缓冲区的数据已经刷新了,空了以后fork,子进程的缓冲区就没有数据了。
为什么参数是stdout?
因为FILE结构体内不仅仅封装了fd,还包含了该文件fd对应的语言层的缓冲区结构。
我们一般把C语言的中打开的FILE称为文件流,
cin>>、cout<<是什么?和C语言类似,它是一个类,它必须包含fd,必须含有缓冲区。
那write写入时是直接写到外设吗?不是!它同样有缓冲区,不过是系统管理的内核缓冲区。
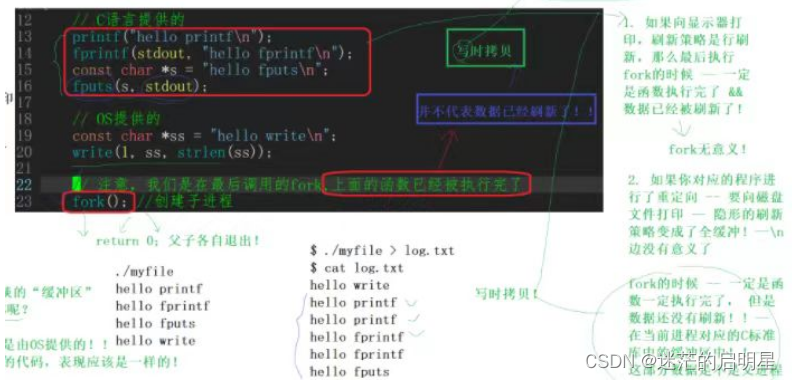
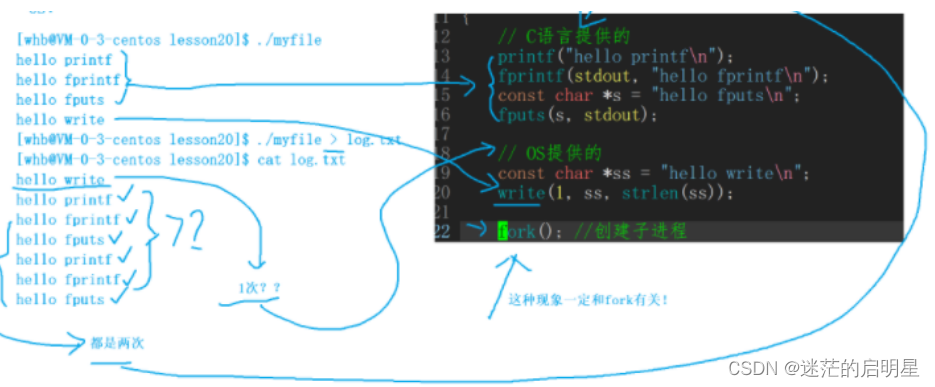
对于同一个程序,向显示器打印输出4行文本和向普通文件(磁盘上)打印时产生不同的行数,是因为在默认情况下输出缓冲的模式不同导致的。
-
向显示器打印输出(标准输出):
当向标准输出打印文本时,默认使用行缓冲模式。即当遇到换行符(‘\n’)或者输出缓冲区已满时,缓冲区中的内容会被立即刷新并显示在屏幕上。所以4行文本会立即显示在屏幕上,没有缓冲延迟。 -
向普通文件(磁盘上)打印输出:
当向普通文件打印输出时,默认使用块缓冲模式。即输出的数据会被收集到缓冲区中,直到缓冲区被填满或者手动刷新缓冲区时,才会将缓冲区中的内容写入磁盘文件。
在这种模式下,输出的数据不会立即写入磁盘文件,而是先放入缓冲区中。当缓冲区被填满、程序结束时或程序显式刷新缓冲区(如调用fflush函数)时,缓冲区中的内容才会写入磁盘文件。如果缓冲区未满,那么可能需要等待一定时间才能刷新缓冲区,即产生了缓冲延迟。
当使用
fork()函数创建一个新进程时,新进程会继承父进程的各个属性,包括输出缓冲区的状态。因此,如果在fork()之前有输出操作,并且输出缓冲区中存在未刷新的内容,那么这些内容会被复制到子进程中。所以在你提到的情况下,假设在
fork()之前有输出操作,这些输出内容会复制到子进程中。然后由于子进程和父进程是独立的,各自有自己的输出缓冲区,所以父进程和子进程的输出缓冲区是相互独立的。当接下来的输出操作在父进程和子进程中分别进行时,父进程和子进程各自的输出缓冲区会根据不同的缓冲模式进行刷新。由于块缓冲模式的特性,父进程和子进程的输出缓冲区在某个时刻将会被刷新,从而导致了多次输出的效果,产生了额外的行数。
因此,在使用
fork()函数后,如果存在输出操作,需要注意父子进程之间输出缓冲区的独立性,以免产生意外的结果。可通过手动刷新缓冲区(如使用fflush函数)或调整缓冲模式(如设置为无缓冲模式)来避免这种情况。6.3 errno
当使用诸如open等函数时,如果出现错误,系统会提供提示信息。查看man手册得知,这些函数会设置errno错误码。
errno是一个错误码,表示了出错的原因。
如果你想要自己实现一个可以报错误信息的函数,可以利用strerror函数。该函数可以根据错误码返回对应的错误信息。
下面是一个示例代码:
#include#include #include void myFunction() { FILE *fp; fp = fopen("non_existent_file.txt", "r"); if (fp == NULL) { printf("Error: %s\n", strerror(errno)); return; } // 其他代码... } - 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
在上述示例中,我们尝试打开一个不存在的文件。当fopen函数失败时,它会设置errno错误码。然后我们可以使用strerror函数将该错误码转换为可读的错误信息,并打印出来。
也可以直接封装一个打印错误信息的函数:
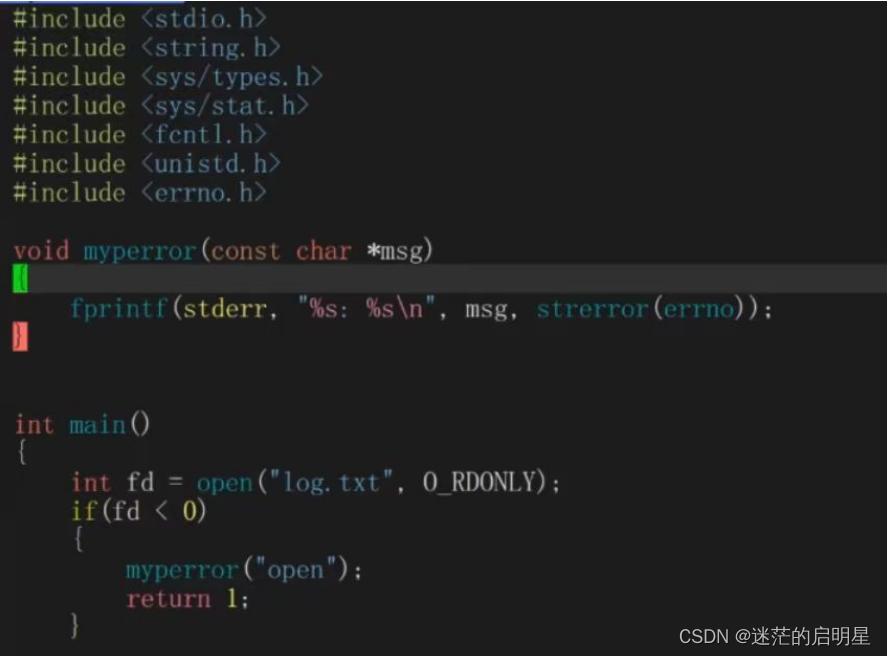
为什么close关闭1和fd以后文件内部没有数据❓

因为它这是输入到普通文件中,数据会加载到缓冲区中,以全缓冲的方式来读取缓冲区中的文件,所以不会因为’\n’而读入,代码中也没有fflush函数来强制刷新,所以文件内部没有数据。
6.4 stdout和stderr
1和2对应的都是显示器文件,但是他们是不同的,可以认为是同一个显示器文件被打开了两次。
原理及相关知识:

7. 文件系统
7.1 背景知识
-
未被打开的文件在磁盘中是存在的,这种级别的文件系统被称为磁盘级文件系统。
-
学习磁盘级文件系统的侧重点主要在于以下几个方面:单个文件角度、系统角度。理解文件系统的整体结构,包括文件数量、各个文件的属性、如何快速查找特定的文件、系统还能存储多少文件以及如何通过分类来优化存储性能。
-
了解内存和磁盘
内存是掉电易失存储介质,而磁盘是永久性存储介质,包括SSD、U盘、flash卡、光盘、磁带等。磁盘是一个外设,与CPU相比它很慢,操作系统中一定会有一些提速的方式(了解即可)。 -
磁盘的结构
磁盘由磁盘盘片、磁头、音圈马达等结构组成。盘面上通过磁头向磁盘写入数据,本质就是改变磁盘上的正负形。
7.2 从物理角度看如何向磁盘写入数据
磁盘是由多个盘片(也称为碟片)组成的。每个盘片都具有两个表面,类似于硬币。每个表面上都有一个磁头,磁头位于盘片上方或下方的非常接近的位置。
现代磁盘通常采用磁性材料来存储数据。磁性材料涂覆在盘片的表面上,被划分成许多圆形的磁道,每个磁道又被划分成扇区。扇区是存储最小单位的一个区域,通常有固定大小(例如512字节)。
要向磁盘写入数据,需要遵循以下步骤:
-
定位磁头:首先,磁头需要准确地定位到要写入数据的磁道上。这通过控制磁头的位置和移动机制来实现。磁头可以在盘片的表面上进行水平移动,同时也可以在盘片堆叠的不同盘片之间进行垂直移动。
-
选择正确的盘片表面:在某些情况下,磁盘可能具有多个盘片。在这种情况下,需要确定写入数据的是哪一个盘片表面。这通常由磁头的位置和移动机制来控制。
-
磁化磁性材料:一旦磁头定位到正确的磁道和盘片表面上,就可以开始写入数据。数据在磁盘上以磁场的形式存储。具体地说,磁头会通过在磁道上产生磁场,改变磁性材料中的磁化方向。这样,每个扇区都可以表示为磁化方向的一个组合。
-
完成写入操作:在将数据写入磁性材料后,磁头会移动到下一个要写入数据的位置,或者可能移动到另一个磁道或盘片。整个过程会重复,直到所有数据都被成功写入磁盘。
需要注意的是,上述步骤是一个简化的描述,并且磁盘的实际工作原理非常复杂。现代磁盘使用了许多高级技术和算法来提高数据访问速度、数据可靠性和容量效率。这些包括磁头飞行高度控制、错误纠正码、缓存管理等等。但从基本的物理角度上看,这些步骤涵盖了向磁盘写入数据的基本过程。
7.3 从物理层面看写入数据到指定扇区
在物理层面,要写入数据到指定扇区,首先需要确定该扇区所在的磁头、柱面和扇区。这可以通过CHS寻址的方式实现。具体步骤如下:
- 确定扇区所在的磁头:扇区在哪个磁头上,就对应了哪个磁头号。
- 确定扇区所在的柱面:每个磁道被分成多少个扇区,这个数字就是柱面号。
- 确定扇区号:每个扇区在各自所在的磁道上,其号是顺序编号的,即从1开始,一直到该磁道上的扇区数。
通过以上三个步骤,我们就可以找到任意一个扇区。CHS寻址是早期硬盘的一种寻址方式,现代硬盘已经普遍采用LBA(Logic Block Address,逻辑块地址)寻址方式,提高了寻址效率。
形象描述:
将数据存储到磁盘=>将数据存储到该数组
找到磁盘特定扇区的位置=>找到数组特定的位置
对磁盘的管理=>对该数组管理7.4 磁盘的抽象(虚拟,逻辑)结构
从逻辑角度来理解磁盘的LBA(Logical Block Addressing)寻址方式,我们可以将其类比于磁带的块(block)寻址方式。
在磁带上,数据被物理地分成多个连续的块,每个块具有唯一的地址。我们可以通过指定块的地址,定位到磁带上的特定数据。块的大小可以根据需求进行调整,常见的块大小为512字节或4KB。
类似地,磁盘的LBA寻址方式也采用了类似的思想。在逻辑上,磁盘被划分为多个逻辑块,每个逻辑块具有唯一的地址。我们可以通过指定逻辑块的地址,准确地定位到要读取或写入的数据。
LBA寻址方式的优势在于它简化了寻址过程。相比于传统的CHS(Cylinder-Head-Sector)寻址方式,LBA只需要指定逻辑块的地址,而不需要考虑磁头、柱面和扇区的具体位置。硬盘控制器会根据逻辑块地址和设备配置,自动将其转换为物理磁道和扇区的地址。
总的来说,磁盘的LBA寻址方式可以类比于磁带的块寻址方式。它们都是通过指定块或逻辑块的地址来定位数据。LBA寻址方式简化了寻址过程,提高了磁盘的存取效率。同时,它也使得磁盘控制器能够更高效地管理数据访问,进一步提高了系统的整体性能。
7.5 磁盘的基本单位
磁盘的基本单位是扇区(512字节),但是操作系统(文件系统)和磁盘进行IO的基本单位是4KB(8*512byte)[一般称之为块大小,块设备]
为什么不以512字节为单位?
- 太小了有可能会导致多次IO,进而导致效率的降低
- 如果操作系统使用和磁盘一样的大小,万一磁盘基本大小变了的话,操作系统的源代码也要改,因为的因为硬件和软件进行了解耦。假设操作系统和磁盘进行io的基本单位和磁盘的基本单位一样,当磁盘的基本单位改变时,假设改变至2×512字节时,此时操作系统的源代码也要进行修改,所以为了防止这种情况出现,我们就采用了这种方式来避免。

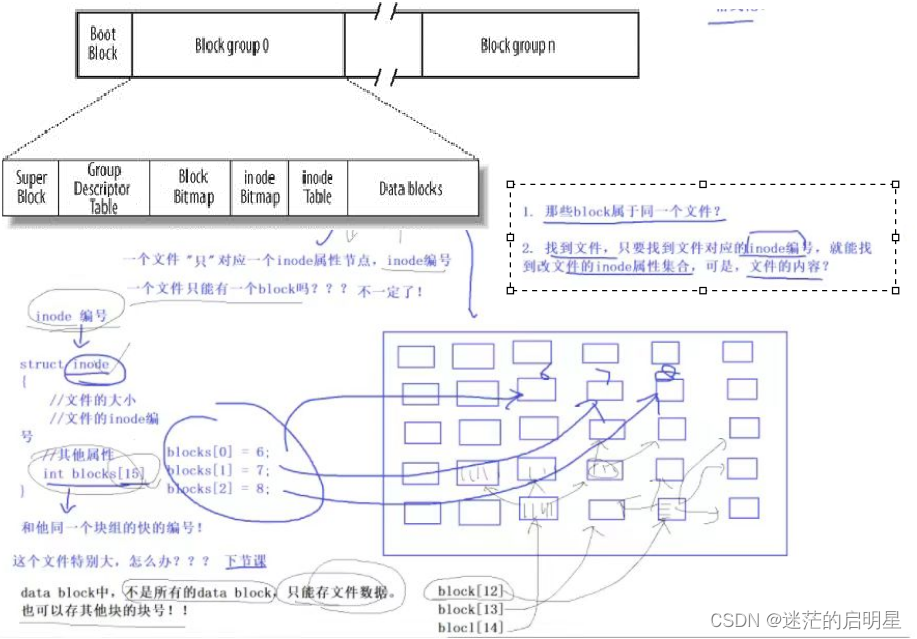
文件系统采用了间接索引和多级索引的方式。前12个索引直接映射到数据块,而后续的索引块(如data block12)存储的是其他块的编号,而非直接存储数据。每个块可存储4个字节,因此一个块可以包含1000多个文件块。当查找文件内容时,如果文件较小,可以直接找到对应的块;如果文件较大,可以在12个块中继续查找,或者在指向的块内部继续读取。这些块可能还指向其他的数据块,这些数据块的内容也可以保存其它块的编号,从而形成了一个多级索引的结构。因此,我们可以通过这种二级或三级的方式,间接地找到文件的大部分内容。这种设计思路允许我们用内容块来索引其他的文件,而不必存储文件数据。我们存储的是其他对应文件的块编号,这样就可以保存大量的文件内容了。7.6 inode和文件名
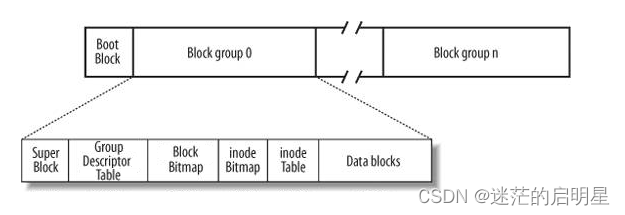
7.6.1 怎么找到文件?
找到文件:通过inode编号→找到分区特定的Block group→确认inode→找到属性→内容
查看磁盘分区

7.6.2 怎么知道inode编号的?
Linux中,inode属性里面没有文件名这样的说法
- 一个目录下,是不是可以保存很多文件?但是他们没有重复的文件名。
- 目录是文件吗?是,那它也就有自己的data block,data block内保存着文件名和inode编号的对应关系,文件名和inode编号互为key值。
- 权限与文件的关系:进入目录需要X权限,创建文件需要W权限,显示文件名与属性需要R权限
inode编号是依托于目录结构。
这就是为什么找一个文件要使用相对路径或绝对路径7.6.3 创建文件,系统做了什么?
根据文件系统,在整个分区当中,找到目录所对应的分区、块组,根据文件系统找到保存这个文件的“块”,在inode bitmap里去遍历它的位图,找到第一个为0的比特位,为0说明它是没有被占用的文件,把它置1的同时拿到一个inode编号,然后给这个文件在inode table里面,把这个新建文件的属性写进去(inode编号、权限、最近修改时间、文件大小等),填完以后没有数据块,因为是新文件,所以就把内部与数据块的对应关系的那个数组清为0,当后面写入内容的时候,直接去block bitmap里面找块,把数据写到块里面,再建立inode和块的映射关系就可以了,所以最后无论是inode还是数据块,我们都可以通过位图的方式去找到,并且把数据和内容写到对应的项目当中,对应的项目当中,我们把文件创建好了,此时把文件创建好,你只是把 [ 找到分区特定的Block group→确认inode→找到属性→内容 ]创建好了,有了之后,最后拿到一个inode编号,之前我们讲过在一个目录下面创建文件,文件名和inode编号有对应的关系,文件名来自用户,inode编号来自文件系统,相当于用户给了一个文件名,文件系统再把文件创建以后把inode给我们,然后再把文件名和inode建立映射关系,写到目录的inode当中,就是找到目录的编号inode,再继续找到它的数据块,把它往里面一写就可以了,那我们是不是得通过目录的inode去找目录的data block?可是找的时候我们也只是知道目录的文件名,怎么办?Linux内核中会建立一个树,把Linux下常用的目录结构在内核中构建好,这个目录结构里就帮我们建立它文件名和目录的inode映射关系,只要拿到这个文件名,它的inode,最后就能够通过文件目录找到目录的inode,进而找到目录的data block,然后把新建的文件名和inode写到目录的data block里,至此文件创建就完成了。
7.6.4 删除文件,系统做了什么?
删除文件和创建文件其实本质一样,首先删文件,我们是在一个文件目录下面删,找到这个目录对应的data block,删文件,用户一定提供了文件名,以文件名为key值去索引目录块中的内容,找到对应的inode,然后根据inode找到inode bitmap对应的比特位由1置为0,这个文件曾经还使用了一些data block,我们把数据块的位图【block bitmap】由1置0,此时只要把这两个位图修改了,文件就被删掉了,然后再从目录当中把文件名和inode的映射关系去掉,就删掉了。
这就是为什么下载一个视频可能要一两个小时,但是删除只要几分钟,因为系统只是把文件内容设置为无效,就相当于删除。那删除以后可以恢复吗?可以,只要还能找到曾经那个文件的inode,就可以用一些恢复工具把对应的分区当中block bitmap和inode bitmap恢复出来,inode bitmap恢复出来,inode的属性就知道,因为inode table还保存着和数据块的映射关系,哪些数据块属于这个文件就知道了,此时这个文件就都恢复了,所以最关键的点是找到删除文件的inode编号,在linux下,删除文件会有删除日志,它里面会保存inode,所以想恢复是可以的,不过成本较高,windows系统下也类似。但是能恢复出来的前提是inode编号没有被使用,inode和data block没有被重复占用。如果把文件误删了,最好的做法是什么都不要做。7.6.5 查看文件,系统做了什么?
ls 、 echo、cat时做了什么?
ls是显示文件名,它是显示一个目录下的文件名,所以ls的时候只要找到这个目录,以及目录的inode,然后再找到data block,把文件名全部挑出来显示就好了,ls -l以列表形式显示,无非是找到这个目录,找到对应的data block,根据文件名、inode找到对应的属性,然后显示需要的即可。echo “hello”>myfile.c 向文件写入,首先把文件打开,FILE对象就有了,把"hello"写到FILE对象的内核缓存区里,操作系统定期刷新,把数据刷新到文件上,也就是向磁盘写入,inode我们知道因为有文件名,而且目录也知道,目录知道就知道文件名和inode的映射关系,inode知道了我们就可以得到inode的属性,然后就找到了对应的数据块,最后就把文件刷到对应的块当中。
cat myfile.c,打印文件很简单,根据文件名找到对应的inode,根据文件的inode,找到它的属性,然后找到数据块,然后把块的内容加载到内存里,刷新到显示器上,最后也就看到了。
7.6.6 发现磁盘分区/块组还有空间,为什么创建文件失败?
inode是固定的,data block是固定的,缺一不可,但是这种情况少见。
8. 软硬链接
- ls -li显示文件把inode也显示
- ln -s testLink.txt soft.link 建立软链接

- ln testLink.txt hard.link 建立硬链接
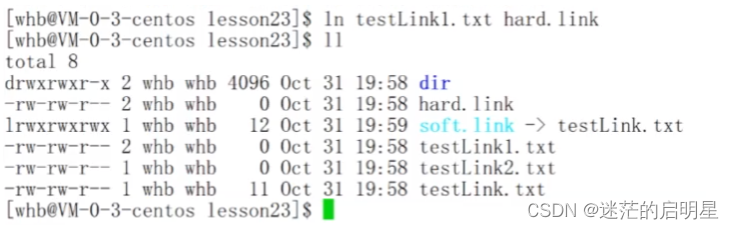
- unlink可以取消链接
8.1 软硬链接有什么区别?
软链接有独立的inode,硬链接的inode与原文件相同,说明软链接是一个独立的文件而硬链接不是。
8.1.1 软链接的特性与应用
特性:可以理解为软链接的文件内容是指向文件对应的路径。
应用:

相当于windows下的快捷方式。8.1.2 硬链接
● 创建硬链接做了什么?
○ 它不是真正的创建新文件,就是在指定的目录下建立了文件名和指定的inode的映射关系而已。
● 属性中有一个数字改变了,它是什么意思?
○ 它代表的是硬链接的数量,在inode属性中有一个引用计数count,我们删除一个文件的时候,并不是把文件inode删除,而是将这个文件的inode引用计数减减,当引用计数为0时,没有文件名和它关联了,这个文件才会真的被删除。
● 有什么用?
○ 为什么创建一个普通文件,它的引用计数是1?
○ 因为在创建一个文件的时候,它的文件名和inode就是一组对应关系,所以是1
○ 建立一个空目录,为什么它的引用计数是2?
○ 因为它本身是一对,然后进入目录后,它会有默认的’.’ '…‘文件,’.‘和当前目录inode也会有对应关系所以引用计数就是2了。
○ 然后再在这个空目录下再建立一个空目录,发现它的引用计数变为了3,为什么?
○ 我们进入到最下面这个目录里,ll -lia查看发现’…'文件的inode和最开始建立的目录的inode相同,所以就是3了。
○ '.‘指向的是当前路径,’…'指向的是上一级的路径。9. 动态库与静态库
曾经我们讲过动态链接和静态链接,动态链接是我们的程序和库产生关联,当我们运行的时候需要指定库函数调用,然后会跳转到指定库里去执行,执行完再返回,静态库是把库函数的内容拷贝到我们的可执行程序里,所以动态链接产生的可执行文件体积小,静态链接的体积大。
为什么要学这个?因为以后我们需要用到别人的库。
9.1 怎么写一个静态库?(开发者角度) 静态库是怎么用的?(用户角度)
静态库 .a
动态库 .so
● 库里面不能有main函数
● 如果我只把.o、.h文件给别人,别人能用吗?可以!把这些文件放到lib目录下即可。
● 但是.o文件太多,容易丢,所以可以打包[ ar -rc file.a file1.o file2.o ]把.o文件打包为.a文件【生成静态库】//在makefile文件中添加下面代码,可以自动打包 file.a:file1.o file2.o ar -rc file1.o file2.o- 1
- 2
- 3

● 将头文件和库函数分别自动放置到include和lib目录下,然后将hello文件中include、lib目录下的内容拷贝到的拷贝到系统uselib目录下对应的位置就可以用了
● 但是因为自己写的库是第三方库,直接gcc main.c编译失败,需要使用 gcc main.c -lhello
● 库函数的默认搜索路径是:uselib/lib64 or uselib/usr/lib64 ,所以想要创建一个自己使用的库需要在该目录下创建库。
● 头文件gcc的默认搜索路径是:uselib/usr/include
● 以上,我们将库拷贝到系统的默认路径下就叫做库的安装
● 但是不建议将自己写的库放到系统路径中,因为我们自己写的库没有经过测试。
● 那怎么办?可以不放在系统路径中,直接使用gcc main -I ./hello/include/ -L ./hello/lib -lhello- 1
● -I:头文件搜索路径
● -L:库文件搜索路径
● -lhello :表明使用哪一个库9.2 怎么写一个动态库?(开发者角度) 动态库是怎么用的?(用户角度)
● 在编译的时候如果要使用动态库进行编译,需要使用以下命令
gcc -fPIC -c file.c -o file.o- 1
● 怎么打包生成一个动态库?
gcc -shared file.o -o libhello.so- 1
● 怎么使用?
先往makefile中加入下面代码,使其既能生成动态库也能生成静态库
● 发布make//编译 make output//发布动态库- 1
- 2
● 此时代码已完成打包
● 然后将它放到系统路径下
● 怎么使用?
和静态库一样,得告诉它在哪里,命令如下:gcc main.c -I output/include -L output/lib -lhello//[最后一个是-l加上.a或.so文件的前缀和后缀去掉]- 1
● 但是lib目录下有两个库, -lhello 默认指定的是动态库还是静态库?动态库。
● 编译成功,运行失败。
● 使用命令ldd a.out查看依赖关系,发现二者都在时,使用的是动态库
● 如果一定要在两种库都在时使用静态库,执行命令后面加上 -static
● 为什么加载动态库会运行失败?- 与静态库相比,动态库是一个“独立”的库文件,静态库编译时会把库代码和你的代码一起加载到内存里。
- 动态库可以和可执行程序分批加载,当可执行程序加载到内存中时,如果需要用到动态库就加载动态库中的代码,然后将它映射到地址空间里被调用
- 按理来说在运行时[gcc 后面]把位置告诉它了,为什么会显示无法打开共享文件,因为这是给gcc说,还需要给系统说
- 之前使用静态库不需要这个步骤,因为使用动态库编译后,它在运行时还需要找到动态库的链接,而静态库编译后就在可执行文件中了。
● 怎么办?【四种方法】 - 1.拷贝.so文件到系统共享库路径下, 一般指/usr/lib
- 2.我们需要将它的路径告诉系统,LD_LIBRARY_PATH下存储着系统的库路径,系统会默认在它下面搜索
echo $LD_LIBRARY_PATH//查看- 1
- 将原来那个库的路径倒入到这个目录下
export LD_LIBRARY_PATH=LD_LIBRARY_PATH:[我的库路径]- 1
- 此时就可以运行了,但是一退出来就会发现刚才所有的配置都没有了
- 怎么持久保持使用?
- 3.需要在etc/ld/so.conf.d/目录下建立一个配置文件file.conf
○ 将我们的库的路径写到file.conf文件中
○ 然后再执行命令 sudo ldconfig更新一下
○ LD_LIBRARY_PATH目录下没有路径,但是也不影响我们执行代码了
○ 之后退出配置也不会被清空
○ 还有一种更简单的办法 - 4.使用命令
sudo ln -s [动态库路径] [系统路径 /lib64/libhello.so]回车
○ 此时就建立了一个软链接
○ 它此时也可以运行
9.3 为什么要有库?
- 如果没有库,很多东西就需要我们自己写,站在使用库的角度,库的存在可以大大减少开发的周期,提高软件本身的质量
- 站在写库的人的角度:
-
1.简单,对写库的人来说可以和其他人解耦,只要写自己的东西就好- 1
-
2.代码安全,生成库的本身就是一种加密- 1
9.4 推荐两个好玩的库【可使用yum安装】
○ ncurses 字符的界面库
○ boost 准标准库9.5 拓展
● 每一个动态库被加载到内存,映射到进程的地址空间,映射的位置可能是不一样的,但是因为库里面是相对地址,每一个函数定位采用的事偏移量的方式找的,换句话说,只要知道这个库的相对地址,库的起始地址+函数偏移量=就可以在自己的地址空间中访问库中的所有函数了,只要你有访问的话。
-
相关阅读:
如何使用Node.js、TypeScript和Express实现RESTful API服务
CentOS 编译安装 Nebula Graph 3.10
基于隐马尔可夫模型的股票预测【HMM】
mmpose管道pipelines
在Node.js项目中使用node-postgres连接postgres以及报错指南
[Python画图][科研可视化]小提琴图变形代码实现
知识点滴 - 在Win10里添加Excel的ODBC数据源
C51之智能感应垃圾桶
Maven核心概念全解析
SpringBoot整合WebSocket实战演练——Java入职十三天
- 原文地址:https://blog.csdn.net/m0_67759533/article/details/132554483
