-
在Pytorch中保存和加载模型,以及构建自定义图片分类数据集
1 在Pytorch中保存和加载模型
1.1 在训练中保存检查点:
def save_checkpoint(state, filename="my_checkpoint.pth.tar"): print("=> Saving checkpoint") torch.save(state, filename)- 1
- 2
- 3
设置在epoch==2的时候保存检查点
for epoch in range(num_epochs): if epoch == 2: checkpoint = {'state_dict': model.state_dict(), 'optimizer': optimizer.state_dict()} save_checkpoint(checkpoint) for batch_idx, (data, targets) in enumerate(train_loader): # 将数据放到cuda中 data = data.to(device) targets = targets.to(device) # forward lables = model(data) loss = criterion(lables, targets) # backward optimizer.zero_grad() loss.backward() # 梯度下降 optimizer.step()- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
得到文件.pth.tar文件
1.2 加载检查点
def load_checkpoint(checkpoint): print("=> Loading checkpoint") model.load_state_dict(checkpoint['state_dict']) optimizer.load_state_dict(checkpoint['optimizer'])- 1
- 2
- 3
- 4
load_model = True if load_model: load_checkpoint(torch.load("my_checkpoint.pth.tar"))- 1
- 2
- 3
- 4
- 5
2 使用PyTorch构建数据集
这里以蜜蜂和蚂蚁的图片数据集为例:
将蚂蚁的标签设置为0,蜜蜂为1,存入csv文件中,代码如下:import os import pandas as pd # 定义两个文件夹的路径 ant_folder = r"" # 替换为ant文件夹的实际路径 bees_folder = r"" # 替换为bees文件夹的实际路径 # 初始化两个空列表,用于存储文件名和标签 file_names = [] labels = [] # 处理ant文件夹 for filename in os.listdir(ant_folder): if filename.endswith(".jpg"): # 假设所有图片都是.jpg格式 file_names.append(filename) labels.append(0) # ant的标签为0 # 处理bees文件夹 for filename in os.listdir(bees_folder): if filename.endswith(".jpg"): file_names.append(filename) labels.append(1) # bees的标签为1 # 创建一个DataFrame对象 data = {'Image_Name': file_names, 'Label': labels} df = pd.DataFrame(data) # 将DataFrame保存为CSV文件 csv_filename = "image_labels.csv" # 保存的CSV文件名 df.to_csv(csv_filename, index=False) print(f"CSV文件已创建: {csv_filename}")- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
得到csv文件如下:
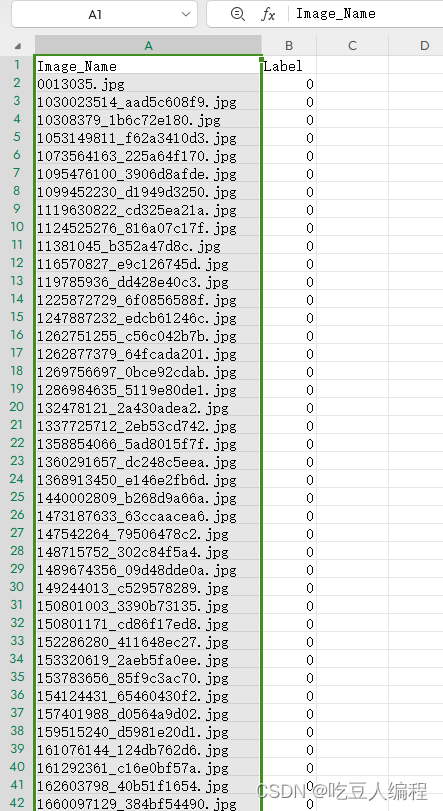
编写自定义数据集类:import os import pandas import pandas as pd import torch from torch.utils.data import Dataset from skimage import io class AntsAndBeesDataset(Dataset): def __init__(self, csv_file, root_dir, transform=None): self.annotations = pd.read_csv(csv_file) self.root_dir = root_dir self.transform = transform def __len__(self): return len(self.annotations) #397 def __getitem__(self, index): img_path = os.path.join(self.root_dir,self.annotations.iloc[index, 0]); image = io.imread(img_path) y_yable = int(self.annotations.iloc[index, 1]) if self.transform: image = self.transform(image) return (image, y_yable)- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
在训练的代码中加载自定义的数据集类
dataset = AntsAndBeesDataset(csv_file='', root_dir='',transform=transformers.Totensor()) train_set, test_set = torch.utils.data.random_split(dataset, [278, 119]); #训练集和测试集 train_loader = DataLoader(dataset=train_set, batch_size=batch_size, shuffle=True) test_loader = DataLoader(dataset=test_set, batch_size=batch_size, shuffle=False)- 1
- 2
- 3
- 4
-
相关阅读:
Android学习笔记 55. 重新认识Android studio开发工具之项目目录结构
安利几个好用的图片转文字识别软件
web网页设计期末课程大作业 HTML+CSS+JavaScript 美食餐饮文化主题网站设计 学生DW静态网页设计
操作系统学习笔记5 | 用户级线程 && 内核级线程
【算法系列 | 9】深入解析查找算法之—哈希表查找
有没有不排队还便宜好用的云渲染呢?
[Games101] Lecture 03-04 Transformation
openfeign客户端A调用服务B,服务B抛出异常时,客户端A接收的几种情况
5年软件测试工程师感悟——写给还在迷茫的朋友
Netty01 - 第一个网络通信程序
- 原文地址:https://blog.csdn.net/m0_46369272/article/details/132323262
