-
机器学习_个人笔记_周志华(停更中......)
第1章 绪论
1.1 引言
形成优秀的心理表征,自然能成为领域内的专家。
系统1 & 系统2。机器学习:致力于研究如何通过计算的手段,利用经验来改善系统自身的性能。主要研究计算机从数据中产生model的算法,即“learning algorithm”。
“经验”通常的存在形式——“数据”。1.2 基本术语
数据集
每条记录——示例——样本
属性
属性值
属性空间——样本空间——输入空间
一个示例——特征向量(feature vector)
训练样本——训练示例(training instance)——训练例学得模型亦称hypothesis,学习过程是为了逼近ground-truth。本书有时称模型为“学习器”(learner)。
标记空间(label space)——输出空间
分类(classificatioin):离散值预测类的学习任务。
回归(regression): 连续值预测类任务。
binary classification任务:includes positive class & negative class。
multi-class classification预测类任务是希望建立输入空间x到输出空间y的映射f
testing:使用学得模型进行预测的过程。
testing sample:被预测的样本。
clustering
cluster据training data是否拥有label information,划分为supervised learning & unsupervised learning,classification和regression是前者的代表,而clustering是后者的代表。
“泛化(generalization)”能力
1.3 假设空间
科学推理的两大基本手段:induction(归纳)& deduction(演绎)。
induction: 从特殊到一般。
deduciton: 从generalization到specialization。inductive learning(归纳学习)——从样例中学习。分为广义和狭义。
version space
1.4 归纳偏好
inductive bias:机器学习算法在学习过程中对某种类型假设的偏好。任何一个有效的机器学习算法必有其归纳偏好,否则无法产生确定的学习结果。
Attention!!!
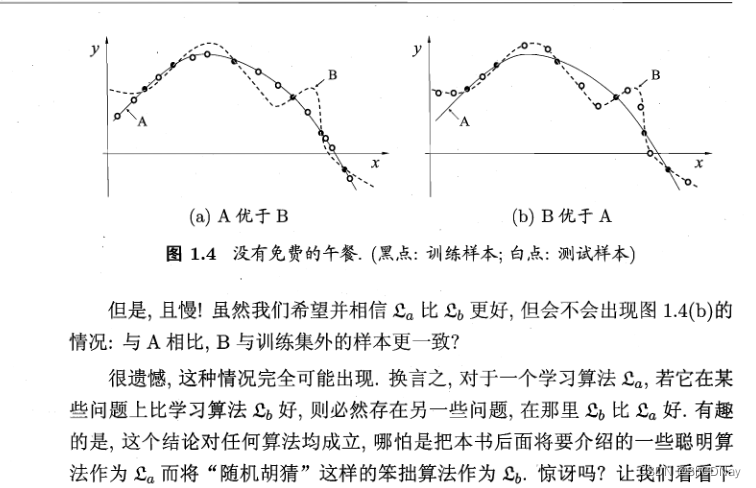
NFL定理:No Free Lunch Theorem!
NFL定理的重要前提:…
NFL Theorem的寓意:具体问题具体分析。学习算法自身的induction bias与problems是否相配,往往起决定性作用。1.5 发展历程
20世纪50年代到70年代初:AI研究处于“推理期”。
20世纪70年代中期开始,”知识期“。
20世纪80年代,ML成为一个独立的学科领域,各种ML技术百花初绽——学习期。本书大部分内容均属于广义的induction learning范畴,涵盖supervised learning and unsupervised learning等等。
ILP:Inductive Logic Programming(归纳逻辑程序设计)。
参数调节上失之毫厘,学习结果可能谬之千里。
statistical learning(统计学习)
Support Vector Machine(SVM,支持向量机)深度学习:狭义地说是“很多层”的神经网络。
ML已发展为一个相当大的学科领域,本节仅管中窥豹。耐心读完本书会有更全面的了解。
1.6 应用现状
在CV及NLP等“计算机应用技术”领域,ML已成为最重要的技术进步源泉之一。ML也为许多交叉学科提供重要的技术支撑。
“数据分析”是ML技术的舞台。ML提供数据分析能力,云计算提供数据处理能力,众包(crowdsourcing)提供数据标记能力。
数据挖掘(data mining)。
数据挖掘与机器学习的联系。
数据库领域研究为数据挖掘提供数据管理技术。ML和统计学的研究为data mining提供数据分析技术。ML技术是建立输入与输出之间联系的内核。
奥巴马的“竞选核武器”——R.Ghani领导的机器学习团队。

1.7 阅读材料

第2章 模型评估与选择
2.1 经验误差与过拟合
error rate: E = a/m;
accuracy: = 1 - E
error(误差)

training error——empirical error
generalization error
overfitting(过拟合): 学习器把训练样本学得“太好”,且将一些的训练样本自身的特点“当作”所有潜在样本具有的一般性质,导致generalization性能下降的现象。亦称“过配”。
underfitting(欠拟合):亦称“欠配”。underfitting比较容易克服,overfitting的则很麻烦,且overfitting的问题无法避免,只能“缓解”。
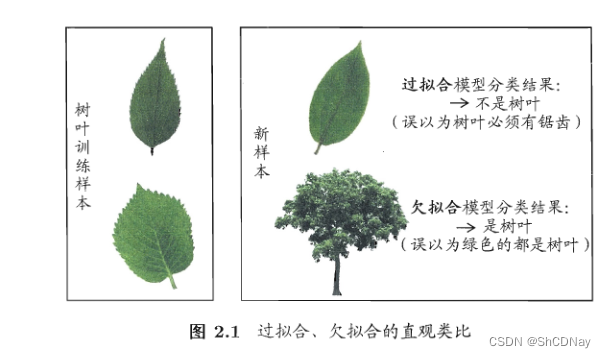
model selection
理想的解决方案,即选择generaliztion error最小的model.2.2 评估方法


2.2.1留出法(hold-out)
hold-out: 直接将数据集D划分为两个互斥的集合,训练集S和测试集T。

“分层采样(stratified sampling)”:保留类别比例的采样方式。保真性(fidelity)。
解决留出法的窘境问题,常见做法是将大约2/3 ~ 4/5的样本用于训练,剩余样本用于测试。2.2.2 交叉验证法(cross validation)
cross validation: 将数据集D划分为k个大小相似的互斥子集。每个子集都尽可能保持数据分布的一致性,即从D中通过分层采样得到。
cross validation通常被称为“k折交叉验证(k-fold cross validation)”。
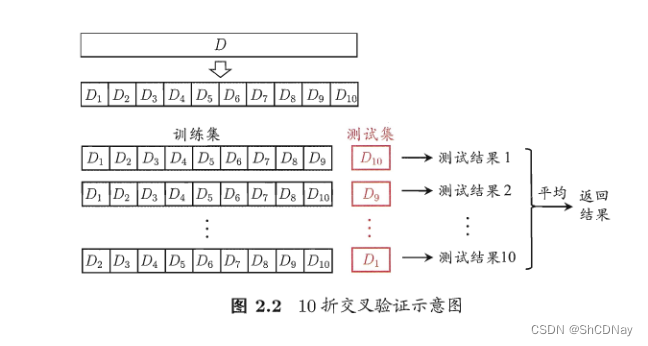

留一法(Leave-One-Out,简称LOO):假定数据集D中包含m个样本,若令k = m,则得到cross validation的一个特例。
LOO优点:评估结果往往被认为比较准确;LOO缺点:数据集比较大时,训练的计算开销将会非常大,且NTF定理对实验评估方法同样适用。2.2.3 自助法(bootstrapping)
bootstrapping: 是一个比较好的解决方案,它直接以bootstrap sampling为基础。
D’作为训练集,D \ D’用作测试集。
“\”表示集合减法。
“out-of-bag estimate(包外估计)”。bootstrapping在数据集较小、难以有效划分训练/测试集时很有用。其产生训练集的方式对集成学习等方法有很大帮助。但bootstrapping会引入估计偏差。故hold-out和cross validation在初始数据量足够时,更常用一些。
2.2.4 调参与最终模型
大多数学习算法都需设定某些parameter,parameter配置不同,学得model的性能往往有显著差别。
“参数调节”简称“调参(parameter tuning)”。

2.3 性能度量(performance measure)
model的"好坏"是相对的,不仅取决于algorithm和data,还决定于任务需求。
2.3.1 错误率与精度
2.3.2 查准率(precision)、查全率(recall)与F1
TP + FP + TN + FN = 样例总数
confusion matrix(混淆矩阵)
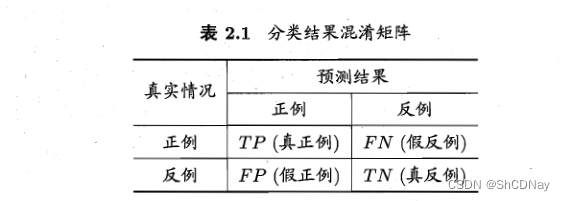

Precision: 给一批定好瓜和坏瓜,能分辨好瓜的能力。
Recall:将好瓜挑全的能力,FN属于把好瓜判为坏瓜,进而将其放回瓜堆。
“平衡点(Break-Event Point,简称BEP)”:是Precision = Recall时的取值。


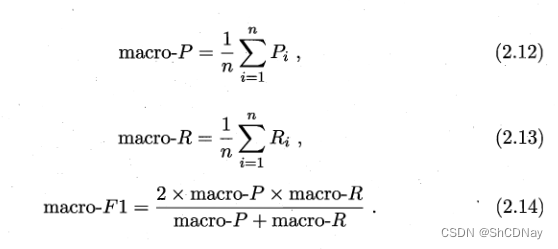

2.3.3 ROC与AUC
threshold(分类阈值)
cut point(截断点)
ROC(Receiver Operating Characteristic)曲线,源于“二战”中检测检测敌机的雷达信号分析技术。
AUC(Area Under ROC Curve)


2.3.4 代价敏感错误率与代价曲线
unequal cost(非均等代价): 为权衡不同类型错误所造成的不同损失,可为错误赋予“unequal cost”。
cost matrix
total cost
cost-snesitive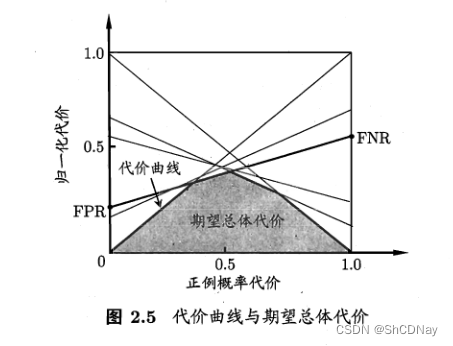
2.4 比较检验
本小节涉及的基础知识为《概率论与数理统计》。
hypothesis test
二项(binomial)分布
binomial test(二项检验)
confidence(置信度)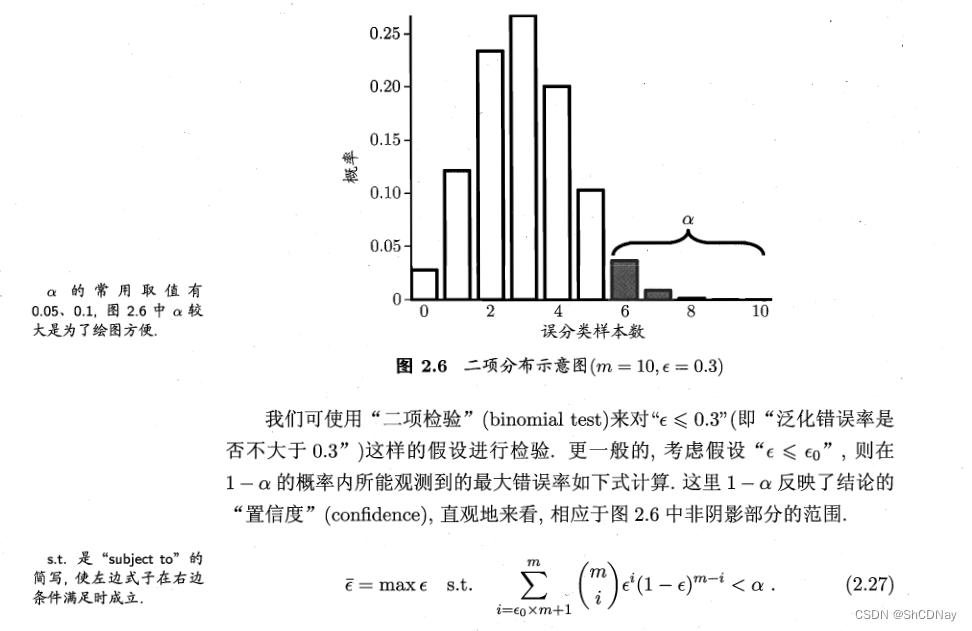
2.4.1 假设检验
2.4.2 交叉验证 t 检验
2.4.3 McNemar检验
2.4.4 Friedman检验与Nemenyi后续检验
F检验
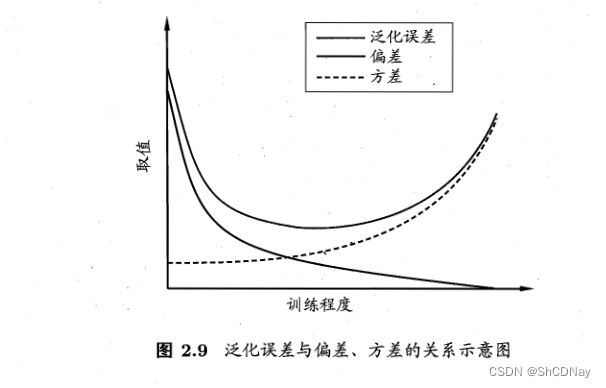
2.5 偏差与方差
偏差-方差分解(bias-variance decomposition)
泛化误差可分解为偏差、方差与噪声之和。bias-variance dilemma(偏差-方差窘境)
2.6 阅读材料
第3章 线性模型
第4章 决策树
第5章 神经网络
第6章 支持向量机
-
相关阅读:
RocketMQ快速入门_2. rocketmq 的应用场景、与其他mq的差异
JavaScrip获取视频第一帧作为封面图
《算法竞赛·快冲300题》每日一题:“取石子游戏”
nohup 不输出日志文件方法
单兵渗透工具-Yakit-Windows安装使用
小程序一键链接WIFI
C++中的string类
wireshark 流量抓包例题重现
MCU设计--M3内核整体功能说明
基于机器视觉的移动消防机器人(二)--详细设计
- 原文地址:https://blog.csdn.net/Sjoqwdk/article/details/132808599