-
Linux:基础开发工具之Makefile和缓冲区的基本概念
动静态库
首先要知道什么是链接:
C程序中,并没有定义printf的函数实现,且在预编译中包含的stdio.h中也只有该函数的声明,而没有定义函数的实现系统把这些函数实现都被做到名为
libc.so.6的库文件中去了,在没有特别指定时,gcc会到
系统默认的搜索路径“/usr/lib”下进行查找,也就是链接到libc.so.6库函数中去,这样就能实现函
数printf了,而这也就是链接的作用因此,链接的理解:
- 我们实现的代码,很多都是用了别人帮我们写好的函数
- 那这些函数是在哪里?如何看到这些函数?就是库的概念
那么动静态库如何理解?有什么区别?
从库的命名来看:
动态库的命名是使用的.so文件的后缀通常是.dll
静态库的命名是使用的.a文件的后缀通常是.lib那动态库和静态库如何使用,具体是如何作用的?
所谓动态库,就是
c或c++或其他第三方提供方法的集合,所有的程序用链接的方式关联起来,在库中的所有的函数都有一个入口地址,而动态链接就是把链接的库的函数地址拷贝到可执行程序的特殊位置静态库和动态库相同,也是一个方法的集合,但是是将所有应用程序以拷贝的方式将需要的代码直接拷贝到可执行程序当中,这样就是静态链接的原理
因此优缺点也就看出来了,动静态库各有利弊:
- 对于动态库来说,使用动态链接生成的可执行程序体积很小,比较节约资源,但是从原理上就能看出,动态链接非常依赖动态库,如果动态库被意外损毁,那么整个和这个动态库相关的程序都不能使用了
- 对于静态库来说,优点就是可以无视库的概念,可以直接把库内的东西拷贝到本地进行使用,可以进行独立运行,但是缺点也很明显,那就是体积过大,太过于浪费资源,因为要把代码都考取到本地的地方
总结
因此,可以这样进行总结,我们的代码与头文件再加上库就可以被形成可执行程序
所以,所谓的开发环境的安装,其实就是安装下载并拷贝头文件和库文件到开发环境中的特定路径下,让编译器可以找到
所谓开发环境要做到什么才能被称之为开发环境?
- 下载开发环境中
include和lib - 设置合理的查找路径
- 规定好形成可执行程序的链接方式
自动化构建代码
在大型文件中会有几百个源文件,那这些文件的编译工作和编译顺序是一个很繁重的事,那么如果有一个工具可以帮助我们进行这些编译的工作,就会节约很大一部分时间,因此就产生了自动化构建代码的工具:
make/Makefilemake是一个命令
makefile是一个在当前目录下存在的一个具有特定格式的文本文件下面开始具体使用makefile:
首先,既然
makefile是一个用来进行项目自动化构建的工具,那么首先必须要有可以运行的文件,因此要首先写一个c文件:
这是一个程序用来倒序输出一段数字,下面要使用
makefile工具来进行自动化构建,这个工具的创建十分简单,直接在目录下创建一个Makefile命名的文件即可,接着在这个文件内可以进行一些输入:mybin:code.c gcc code.c -o mybin .PHONY:clean clean: rm -f mybin- 1
- 2
- 3
- 4
- 5
上面是较为基本的版本,一开始的
mybin表示最后要生成的文件名字是mybin,而生成mybin需要借助的文件是code.c,对于code.c的操作是用gcc进行编译,这样就可以生成mybin文件,这里要引入两个概念:依赖关系和依赖方法:何为依赖关系?简单来说,依赖关系就是要完成这个操作需要依赖于什么文件,对于这个文件内的信息来说,依赖关系就是
mybin文件的生成需要依赖于code.c这个文件那何为依赖方法?就是要生成目标文件需要进行什么样的操作,对于这个文件内的信息来说,依赖方法就是要进行
gcc code.c -o mybin,这样就能生成mybin,因此这个操作也就被叫做是依赖方法因此,这样就写好了最初始版本的
Makefile文件,这个工具就可以进行一些初步的操作: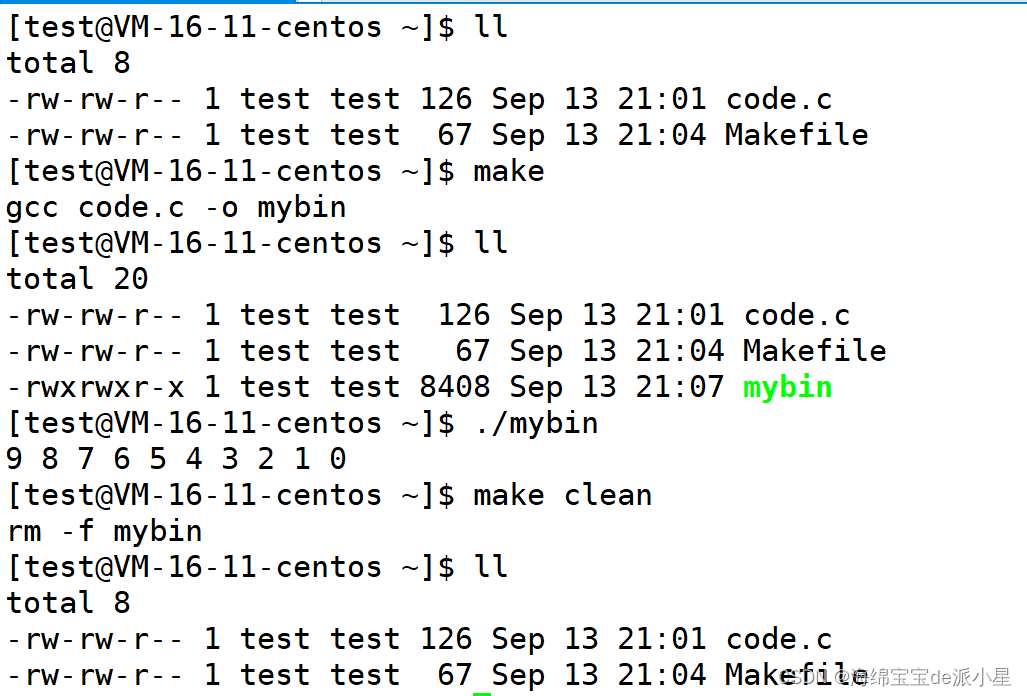
从上面的图中可以看出进行操作的一些步骤,首先当前目录下只有一个code.c和项目自动化构建工具,使用make指令后,就在当前目录下使用gcc编译器完成了编译,生成了mybin文件,此时当前目录下就生成了mybin这个可执行文件,而这个可执行文件运行后的结果也可以被打印出来下面的操作是
make clean,通过这个指令可以调用Makefile文件下的clean指令,可以执行rm命令,将生成的mybin可执行文件进行删除那现在再次看到
Makefile文件,文件内的信息中除了总结的依赖关系和依赖方法外,还有一些没见过的内容,这些内容的意义是什么?首先是
.PHONY:clean,这个语句中有一个.PHONY,这个的意义是作为一个伪目标,那什么又是伪目标?下面进行解释先说结论,伪目标的意义就是可以让依赖方法总是被执行,不会收到任何情况的阻拦,也就是说如果被确认的伪目标,那么语句总是会被执行的
那问题又来了,什么叫总是被执行,难道还有不会被执行的情况吗?有下面的实验
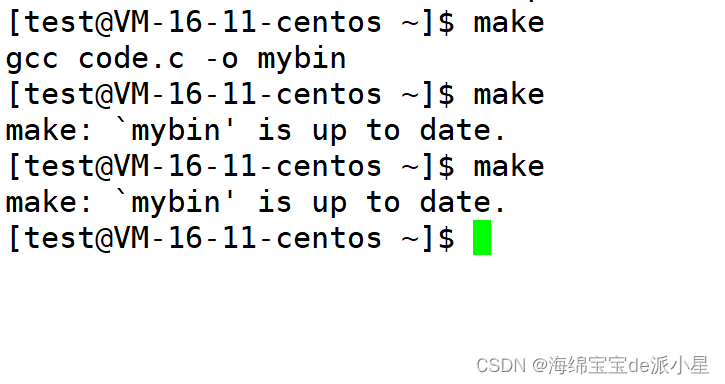
上面的实验就很好的说明了这个问题,在这个实验中,第一次使用make指令是可以成功的,可以让code.c经过gcc编译,但是如果继续使用make,就会提示上面的报错信息,而这个报错信息产生的原因其实是因为mybin文件不需要被更新,因此这个自动化构建的工具没有让代码进行编译,也就是说,通过一些比较,是可以让一些代码不再重新编译的,或者总结来说,可以让一些操作不被重复执行,因为执行这些操作没有必要为什么要这样设置?有什么好处?
为什么
Makefile和make不让使用者随时重新编译代码,而是会做出一定的限制?原因在于要提高效率,那么又是如何进行判断的?答案是通过时间进行判断,如果通过时间的判断,Makefile工具发现,mybin实际上不需要重新编译,因为code.c内没有进行任何操作,和之前的编译结果产生是一样的,此时就会不让用户进行编译,这样也能提高效率那工具是如何做到的?如何进行比较文件的时间,文件的时间又是一个什么样的概念?
因此就引出了文件的ACM时间的概念想要看到时间需要用到
Linux中的一条指令:stat code.c- 1

借助这个指令可以看到关于code.c文件的各种信息,其中就包括文件的几个修改时间,下面先看文件的这几个修改时间有什么具体的意义:首先要清楚前面的一个概念:
文件=内容+属性,因此在这里关于文件的修改时间,是包括文件的内容修改时间和文件的属性修改时间Access时间:Access修改时间指的是文件的内容被查看就会被修改,但Access并非每次被查看都会被记录到这次的时间变化,原因看后续Modify时间:Modify时间指的是文件的内容被改变的时候,就会改变一次这个时间Change时间:Change时间指的是文件的属性被修改的时候,就会改变一次这个时间现在使用
vim进入文件中对文件进行一些修改,此时再看文件的各项时间:
从中可以看出,使用
vim对文件进行了一些操作后,时间都被修改了,Access和Modify时间被修改是因为文件内容被修改,而文件内容被修改意味着文件的属性也必然会被修改,因此文件的Change时间也被进行了修改,三个时间都进行了一定程度的修改因此可以从中总结出,
Change时间被修改是当文件的属性发生变换时就会修改,因此Change时间是可以单独被修改的,而Modify时间的改变必然会导致其他时间跟着连锁改变,因为文件内容的改变会导致其属性必然改变回到前面的问题,那这个工具是如何判断什么时候要进行修改?
答案是根据的是
Modify的时间来判断,通过Modify的时间就可以对比出来源文件和编译生成的可执行程序的新旧,如果编译出来的可执行程序的时间晚于源文件,就意味着源文件可能被进行了某些修改,需要重新编译,因此此时就具备重新编译的条件,就可以重新编译,但是如果源文件的修改时间晚于可执行程序,就可以被认为源文件在编译形成可执行程序的这段时间内没有进行其他操作,没有重新编译的需要,为了保证效率就不再进行编译,而是直接采用编译好的可执行文件运行即可Access时间的特殊性
在
Linux中可以看到的文件,都是在磁盘上进行的存储,而又由于文件是由内容加属性组成的,因此更改时间的本质其实就是访问磁盘Access时间负责管理的是文件被查看的频率,而如果文件每次被查看都要更改对应的Access时间,那么访问磁盘的频率就过快,而在Linux系统中会存在大量的访问磁盘的IO操作,如果每次查看后都要访问磁盘进行修改时间,会降低系统的效率,因此对于Access时间做了一定的限制,增加了次数限制,因此并不是每次查看文件都会更改这份文件的Access时间缓冲区
C语言中学习过缓冲区,那时的缓冲区是站在输入输出的角度来看的,现在在Linux中重新认识缓冲区的概念
在c语言中,针对输出流有其特定的默认缓冲区,这里主要研究输出缓冲区,输出缓冲区的位置在哪里?如何证明输出缓冲区的概念?
现在有这样的程序:
#include#include int main() { printf("hello linux"); sleep(2); return 0; } - 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
对这个程序编译运行,会发现一个现象:程序会先进行
sleep后进行输出打印,按照正常逻辑来看,程序理应是先输出信息再sleep,那么从这个现象中就可以看出,在运行程序的过程中,输出缓冲区确实是存在的,而要输出的信息就存储在输出缓冲区中,还没有被打印到屏幕上,因此会先sleep后再进行显示到屏幕那么如何处理缓冲区?可以用到缓冲区对应的函数
fflush函数
#include#include int main() { printf("hello linux"); fflush(stdout); sleep(2); return 0; } - 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
或者也可以直接输出后打上
\n,原因是回车换行也是一种刷新的策略有了上面的基础知识,回顾c语言:
\r = 回车键
\n= 换行键而键盘中的
enter键,实际上就是回车+换行因此基于上面的原理,可以实现一个有趣的代码
#include#include int main() { int a=5; while(a--) { printf("%d\r",a); sleep(1); } return 0; } - 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
上面代码输出的结果是没有结果,原因在于:每当打印一个数字的时候,这个数字一直在缓冲区中,而
\r直接把数据进行了覆盖如果将代码更新为这样:
#include#include int main() { int a=5; while(a--) { printf("%d\r",a); fflush(stdout); sleep(1); } return 0; } - 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
对于缓冲区的理解
首先要清楚,缓冲区的本质是一个数组,因此对于单句的
printf函数,如果用这个语句来看的话,缓冲区中会存储的是a的值和\r,假定这里没有fflush函数也没有sleep函数,那么printf函数就会把所有数据缓存到缓冲区,当程序结束后以此进行打印,把数据和\r看成一组,每执行完数据和\r后光标就回到了最开始的地方本篇在Linux下基于前面所学缓冲区和Makefile的概念再加一些函数实现一个进度条
原理实现
- 借助Makefile的原理项目自动化构建
- 借助缓冲区的概念
具体实现
首先实现基础的功能版本
实现原理其实很简单,就是利用缓冲区的概念,打印出信息后借助\r回到最开头的地方,再借助缓冲区把信息打印出来即可
这里做了一些最基础的优化,例如在后面加了百分比和模拟实现了一个滚动实现的效果
// process.h #include#include #include #define MAXSIZE 101 #define process_char '#' #define sleep_time 10000 void process_v1(); - 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
// process.c #include "process.h" char str[]="|\\-/"; void process_v1() { int rate=0; char arr[MAXSIZE]={0}; memset(arr,'\0',sizeof(arr)); while(rate<MAXSIZE) { printf("[%-100s][%d%%][%c]\r",arr,rate,str[rate%strlen(str)]); fflush(stdout); usleep(sleep_time); arr[rate++]=process_char; } printf("\n"); }- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
// main.c #include "process.h" int main() { process_v1(); return 0; }- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
写完源文件就应该借助项目自动化构建工具完成简单的编译清除功能了
process:process.c main.c gcc -o $@ $^ .PHONY:clean clean: rm -f process- 1
- 2
- 3
- 4
- 5

这样最基础的版本就实现完成了,用了宏定义可以随意修改进度条的速度等但这样的实现和实际还不太一样,下面实现一个和实际开发相适应的进度条版本
下面进行一些优化版本
在实际开发中,进度条并不是单独出现,它会和具体的下载内容相结合,因此是需要进行结合使用的
因此优化版本的思路就是在将进度条和一个具体的下载情景结合起来使用,借助一个回调函数实现,利用休眠函数模拟下载的这个过程
// process.h #include#include #include #define MAXSIZE 101 #define process_char '#' #define sleep_time 10000 #define process_head '>' #define process_body '=' #define TARGET_SIZE 1000*1000 #define DSIZE 1000*10 #define MAX_RATE 100 void process_v1(); void process_v2(int); typedef void (*callback_t)(int); - 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
// process.c #include "process.h" char str[]="|\\-/"; void process_v1() { int rate=0; char arr[MAXSIZE]={0}; memset(arr,'\0',sizeof(arr)); while(rate<MAXSIZE) { printf("[%-100s][%d%%][%c]\r",arr,rate,str[rate%strlen(str)]); fflush(stdout); usleep(sleep_time); arr[rate++]=process_char; } printf("\n"); } void process_v2(int rate) { static char arr[MAXSIZE]={0}; //memset(arr,'\0',sizeof(arr)); if(rate<MAXSIZE && rate>=0) { printf("[%-100s][%d%%][%c]\r",arr,rate,str[rate%strlen(str)]); fflush(stdout); usleep(sleep_time); if(rate < MAXSIZE-1) { arr[rate-1]=process_body; arr[rate]=process_head; } else { arr[rate]=process_body; } } //printf("\n"); }- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
// main.c #include "process.h" void download(callback_t cb) { int testcnt = 100; int target = TARGET_SIZE; int total = 0; while(total <= target) { usleep(sleep_time); total += DSIZE; double rate = total*100.0/target; if(rate > 50.0 && testcnt) { total = target/2; testcnt--; } cb(rate); } cb(MAX_RATE); printf("\n"); } int main() { download(process_v2); return 0; }- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
-
相关阅读:
【数据治理】Atlas2.2.0基于HDP进行Hive的接入
【精品资源】Java毕业设计攻略:从选题到答辩,一站式指南
(动手学习深度学习)第13章 计算机视觉---图像增广与微调
JUC并发编程(一):Java内存模型(JMM)及三大特性:可见性、有序性、原子性
难道企业真的需要私有区块链吗?
Vue样式绑定
爬取tx视频
numpy对数组进行过滤并获取下标
区块链技术的应用场景和优势
C#语音播报(通过CoreAudioAPI完成对扬声器的控制)
- 原文地址:https://blog.csdn.net/qq_73899585/article/details/132832192
