-
解决hadoop使用put上传报错问题

hadoop使用put上传报错
WARN hdfs.DataStreamer: DataStreamer Exception
org.apache.hadoop.ipc.RemoteException(java.io.IOException): File /input/yxqzdata.COPYING could only be replicated to 0 nodes instead of minReplication (=1). There are 0 datanode(s) running and no node(s) are excluded in this operation.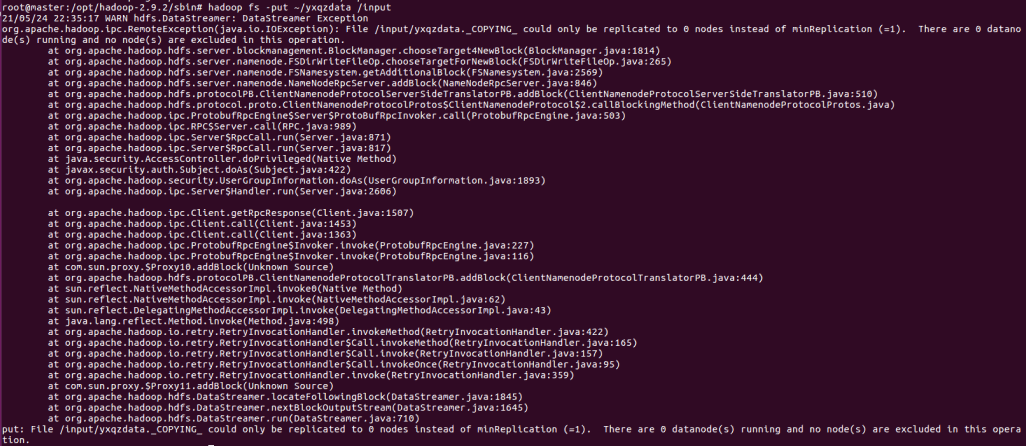
原因是多次格式化了Hadoop或者hdfs。因为id不一致。
停止集群
在hadoop的sbin目录下操作
./stop-all.sh- 1
删除HDFS中的文件
查看Hadoop配置,hadoop安装目录下的ect下的hadoop下的core-size.xml
删除tmp文件
tmp中存储的是hdfs文件
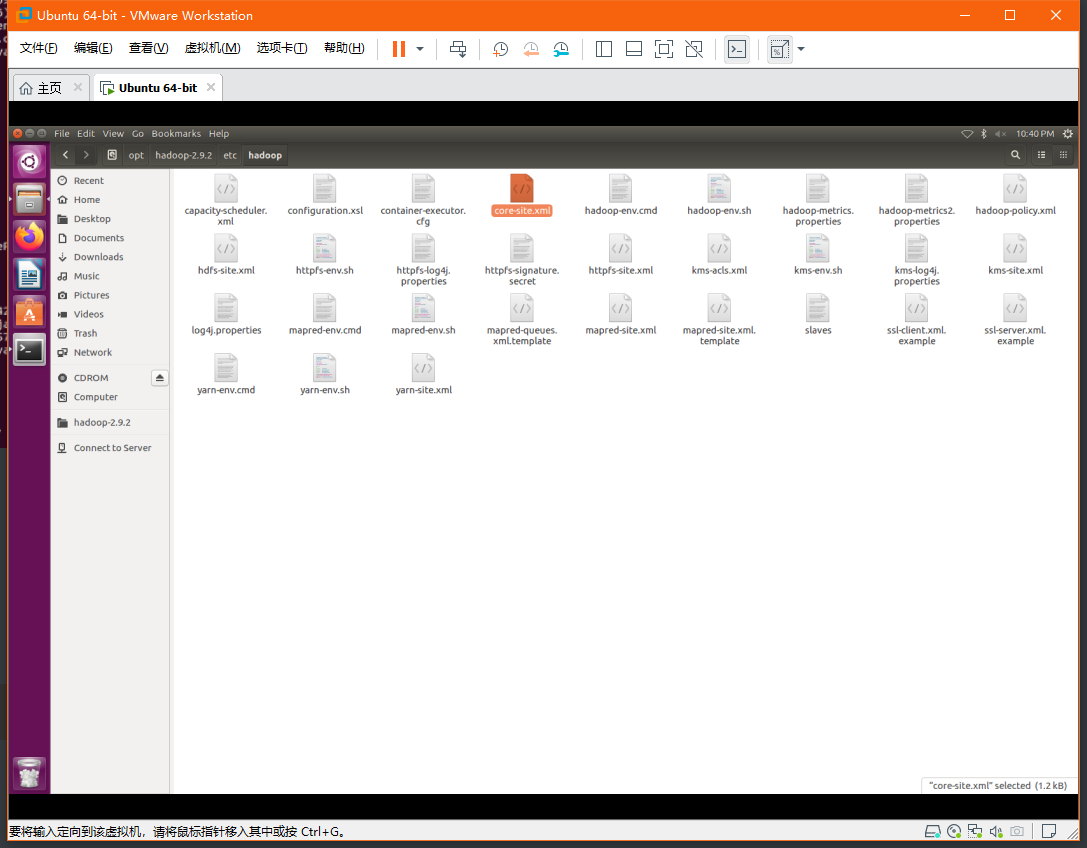
我的配置是将数据存储在/opt/hadoop-2.9.2/tmp下的
<configuration> <property> <name>fs.defaultFSname> <value>hdfs://master:8020value> property> <property> <name>hadoop.tmp.dirname> <value>/opt/hadoop-2.9.2/tmpvalue> property> <property> <name>io.file.buffer.sizename> <value>8192value> property> <property> <name>ha.zookeeper.quorumname> <value>master:2181value> property> configuration>- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18

可以通过ub系统界面,直接删除tmp目录,也可以使用rm-f删除数据
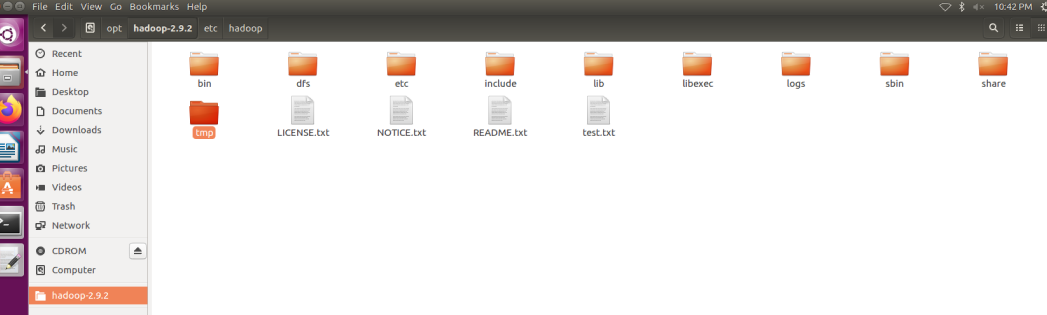
删除id文件
这里是个大坑,网上很多照抄的某人的,都没有提到删除找个id文件。找到hadoop的安装目录下的dfs目录下的data,其实是删除的data下的文件是hadoop更目录下的dfs下的文件,某些人抄着别人的博客,就抄成了删除从core-size.xml配置文件中的hdfs的数据data文件了。也是醉了严重误导了我这种小白,所以最好这两个data文件都删除,删除后执行下面的格式化删除后执行下面的格式化删除后执行下面的格式化

还有一种方式
找到tmp下的data下的一个文件中断 current下的VERSION
这个tmp就是我配置文件中设置的tmp,可以看上面core-size.xml中的 hadoop.tmp.dir的配置

然后找到hadoop安装目录下的dfs下的data下的一个VERSION

clusterID使两个的clusterID相同,就可以解决了,可以打开对比来看看,一致就没问题了

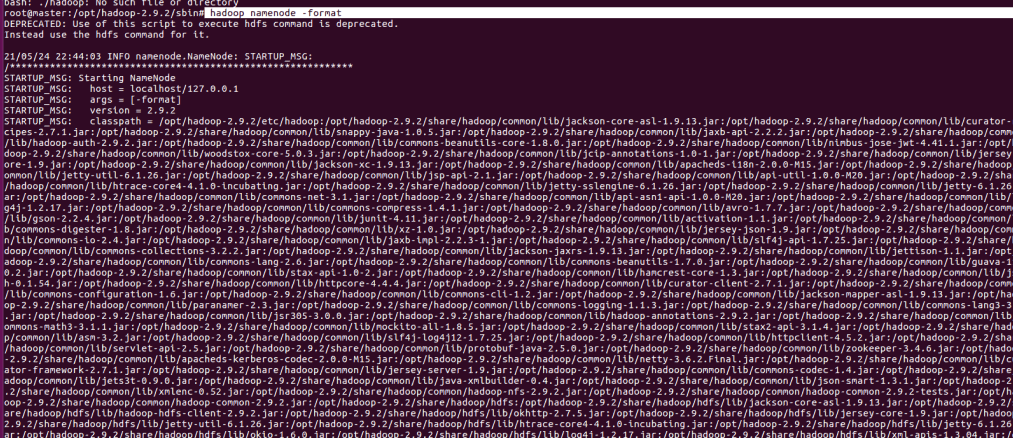
格式化Hadoop
我配置了全局变量的hadoop,所以可以直接输入hadoop的操作命令
hadoop namenode -format- 1
启动Hadoop集群
在hadoop的sbin目录下操作
./start-all.sh- 1
查看HDFS文件
查看一下hdfs更目录下有没有文件,因为删除了tmp目录,所以这里啥都没有
hadoop fs -ls /- 1
创建目录Input
重新创建一个目录input
hadoop fs -mkdir /input hadoop fs -ls /- 1
- 2

上传文件
hadoop fs -put ~/yxqzdata /input- 1

-
相关阅读:
Linux离线安装elasticsearch|header|kibna插件最详细
SQL常用脚本整理,建议收藏
Looper分析
如何高效且优雅地使用Redis
Java集合之Map
centos7安装tomcat9过程
正则核心知识点
设计模式之美——解耦
【区分vue2和vue3下的element UI Table 表格组件,分别详细介绍属性,事件,方法如何使用,并举例】
STM32中事件标志位与中断标志位
- 原文地址:https://blog.csdn.net/qq_40609008/article/details/132887105