-
自动化测试(五):自动化测试框架的搭建和基于yaml热加载的测试用例的设计
该部分是对自动化测试专栏前四篇的一个补充,本次参考以下文章实现一个完整的谷歌翻译接口自动化测试:
[1]【python小脚本】Yaml配置文件动态加载
[2]【python做接口测试的学习记录day8——pytest自动化测试框架之热加载和断言封装】目标:框架封装完成后,不需要写python脚本,只需要增加yaml测试用例即可。
PS:该案例是在B站初步自学完1-24自己编的,练练手,比较简单,如果有错误地方请私聊更改。这个视频200集感觉是在翻来覆去得讲相同的东西,先学以致用练一练,后续会找更复杂的测试项目进行学习。
(更新中,每天抽空把这个项目推进一点)
1. 框架的搭建之文件组织架构
框架一:
可以根据项目的需求和规模进行适当的调整和扩展。pytest 允许非常灵活的组织方式,以适应各种项目。
api_frame/ │ ├── testcases/ │ ├── test_module1.py │ ├── test_module2.py │ ├── subdirectory/ │ │ ├── test_module3.py │ │ └── test_module4.py │ │ │ └── conftest.py │ ├── src/ │ ├── module1.py │ └── module2.py │ └── requirements.txt- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
-
项目根目录(api_frame/): 项目的顶层目录,通常包含项目的配置文件和测试脚本。
-
testcases/: 存放测试脚本的目录。测试脚本的文件名通常以 test_ 开头,以 .py 结尾。在示例中,有两个测试模块文件(test_module1.py 和 test_module2.py)以及一个子目录 subdirectory/,其中包含两个测试模块文件(test_module3.py 和 test_module4.py)。
-
conftest.py: 这是一个特殊的 pytest 配置文件,它可以包含一些全局的配置、夹具(fixtures)等,供所有测试模块使用。
-
src/: 存放项目的源代码的目录。通常,项目的源代码和测试代码分开存放,以保持项目的结构清晰。
-
requirements.txt: 存放项目的依赖关系的文本文件。通常,你可以使用 pip install -r requirements.txt 命令来安装项目所需的依赖包。
框架二:
一个典型的 API 测试框架的组织结构,它通常用于自动化测试和持续集成环境中,以确保 API 的稳定性和可靠性。框架提供了测试用例编写、数据管理、测试运行、报告生成等功能。
api_frame/ ├── commons/ │ ├── __init__.py │ ├── api.py │ ├── assert_utils.py │ ├── logger_utils.py │ ├── parametrize_utils.py │ ├── requests_utils.py │ └── yaml_utils.py │ ├── datas/ │ ├── __init__.py │ └── product_manage/ │ ├── hotloads/ │ ├── __init__.py │ ├── debug_xxx.py │ └── public.pem │ ├── testcases/ │ ├── product_manage/ │ ├── __init__.py │ │ ├── pm_get_token.yaml │ │ ├── pm_file_upload.yaml │ │ └── test_product_api.py │ │ │ ├── user_manage/ │ ├── __init__.py │ │ ├── um_base64.yaml │ │ ├── um_md5.yaml │ │ └── test_new_api.py │ └── __init__.py │ ├── reports/ │ ├── module1.py │ └── module2.py │ ├── venvs/ │ ├── conftest.py ├── config.yaml ├── run.py └── requirements.txt- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
-
commons/: 通常包含一些通用的工具和函数,以便在测试中重复使用。这些文件可能包括:
api.py:用于执行 API 请求和处理响应的封装。
assert_utils.py:包含自定义断言函数,用于验证 API 响应的内容。
logger_utils.py:用于记录测试日志和生成日志报告的工具。
parametrize_utils.py:包含用于参数化测试用例的工具。
requests_utils.py:封装了用于发送 HTTP 请求的工具。
yaml_utils.py:用于读取和解析 YAML 格式的配置文件。 -
datas/: 包含测试数据,用于测试用例。在你的结构中,子目录 product_manage/包含与产品管理相关的测试数据。
-
hotloads/: 这个目录包含一些热加载或配置文件,用于在运行时动态加载或修改测试框架的一些配置。例如,debug_xxx.py 可包含用于开启或关闭调试模式的代码。
-
testcases/: 存放测试用例的目录,按照模块或功能进行组织。结构中包含两个子目录 product_manage/ 和 user_manage/,每个子目录中包含了相应功能模块的测试用例。测试用例文件通常以 test_ 开头。
-
reports/: 包含测试报告生成的相关代码,用于记录测试结果并生成报告。module1.py 和 module2.py 包含与报告生成相关的代码。
-
conftest.py: pytest 配置文件,通常包含一些全局的配置和夹具(fixtures)定义,供所有测试用例共享。
-
config.yaml: 包含测试框架的配置信息,如基本 URL、认证信息等。
-
run.py: 用于运行测试的脚本,包含命令行参数解析和测试运行的逻辑。
-
requirements.txt: 存放项目的依赖关系的文本文件,通常使用
pip install -r requirements.txt命令来安装项目所需的依赖包。
(1)采用yaml作为测试用例并进行数据驱动,对yaml测试用例进行了规范和一致化 ,测试脚本与测试数据分离的设计的好处是:降低维护成本,迁移成本以及提高效率。
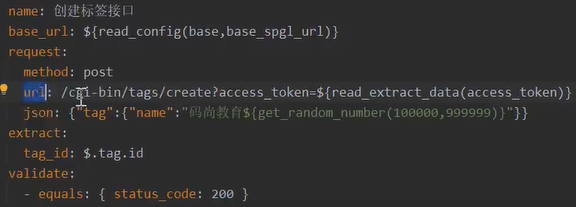
(2)传参方式丰富,可以以文件形式、json格式。内置md5、base64、签名加密算法。
(3)基于pytest框架的轻量级接口关联,通过对yaml文件进行动态配置,能够在yaml文件中extract:标记key-value,value可以用正则匹配、json提取方式进一步处理传入的参数。
(4)框架支持多种断言方式(相等,包含,数据库断言等)
(5)要支持多种环境切换2.基于爬虫的谷歌翻译接口自动化测试
在这里仅用一个很简单的基于爬虫的谷歌翻译接口练手。

2.1 第一步:梳理业务功能的调用链(接口间的依赖关系)
首先根据GoogleTranslate.py源码:
import json # 用于 JSON 数据处理 import requests # 用于发起 HTTP 请求 import random # 用于生成随机数 import re # 用于正则表达式处理 from urllib.parse import quote # 导入了 quote 函数,用于对 URL 进行编码,以防止特殊字符引起的问题。 import urllib3 # 用于处理 HTTP 请求和连接池管理。 import logging # 导入 logging 库,用于记录日志信息。 from Google_Tran.google_constant import LANGUAGES, DEFAULT_SERVICE_URLS log = logging.getLogger(__name__) # 创建一个名为 __name__ 的 logger 对象,用于记录与当前模块相关的日志。 log.addHandler(logging.NullHandler()) # 添加一个空的处理器,以确保不会产生未处理的日志消息。 urllib3.disable_warnings(urllib3.exceptions.InsecureRequestWarning) # 禁用 urllib3 库的不安全请求警告,在使用不安全的 HTTPS 时避免显示警告信息。 # 创建列表 URLS_SUFFIX,通过列表推导式从 DEFAULT_SERVICE_URLS 提取的 Google 翻译服务的 URL 后缀。每个 URL 后缀都对应不同的国家或地区。 URLS_SUFFIX = [re.search('translate.google.(.*)', url.strip()).group(1) for url in DEFAULT_SERVICE_URLS] # url.strip()字符串方法,去除字符串两侧的空格和换行符等空白字符。 # re.search('translate.google.(.*)', url.strip()):对经过 strip() 处理后的 URL 使用正则表达式进行搜索。 # 正则表达式 'translate.google.(.*)' 会匹配以 'translate.google.' 开头的字符串。 # . 表示匹配任意字符,而 * 表示匹配前面的字符(这里是 .)零次或多次。因此,.* 可以匹配任意长度的字符串。 # 如果匹配成功,re.search() 函数会返回一个匹配对象(match object),该对象包含了关于匹配内容的详细信息,例如匹配的字符串、匹配的位置等。 # 如果匹配失败,则返回 None,比如re.search('tran.google.(.*)', url.strip())就匹配不上 # 匹配对象.group() 方法以形式返回获取捕获的分组内容。(.*)就是匹配的分组 URL_SUFFIX_DEFAULT = 'com' class google_new_transError(Exception): """Exception that uses context to present a meaningful error message""" def __init__(self, msg=None, **kwargs): # 异常类的构造函数。它接受一个可选的 msg 参数和关键字参数 kwargs,这些参数将用于初始化异常对象。 self.tts = kwargs.pop('tts', None) # 将关键字参数 tts和response 的值存储在对象属性 self.tts、self.rsp 中。 self.rsp = kwargs.pop('response', None) if msg: self.msg = msg elif self.tts is not None: # 将根据 self.tts 和 self.rsp 推断 self.msg 的值。 self.msg = self.infer_msg(self.tts, self.rsp) else: self.msg = None super(google_new_transError, self).__init__(self.msg) def infer_msg(self, tts, rsp=None): cause = "Unknown" if rsp is None: # 如果 rsp 为 None,则返回一个错误消息,指示连接失败,可能的原因是超时。 premise = "Failed to connect" return "{}. Probable cause: {}".format(premise, "timeout") else: # 如果 rsp 不为 None,则获取响应的状态码和原因,并根据不同的状态码和条件返回相应的错误消息和原因。 status = rsp.status_code reason = rsp.reason premise = "{:d} ({}) from TTS API".format(status, reason) if status == 403: cause = "Bad token or upstream API changes" elif status == 200 and not tts.lang_check: cause = "No audio stream in response. Unsupported language '%s'" % self.tts.lang elif status >= 500: cause = "Uptream API error. Try again later." return "{}. Probable cause: {}".format(premise, cause) class google_translator: ''' You can use 108 language in target and source,details view LANGUAGES. Target language: like 'en'、'zh'、'th'... :param url_suffix: The source text(s) to be translated. Batch translation is supported via sequence input. The value should be one of the url_suffix listed in : `DEFAULT_SERVICE_URLS` :type url_suffix: UTF-8 :class:`str`; :class:`unicode`; string sequence (list, tuple, iterator, generator) :param text: The source text(s) to be translated. :type text: UTF-8 :class:`str`; :class:`unicode`; :param lang_tgt: The language to translate the source text into. The value should be one of the language codes listed in : `LANGUAGES` :type lang_tgt: :class:`str`; :class:`unicode` :param lang_src: The language of the source text. The value should be one of the language codes listed in :const:`googletrans.LANGUAGES` If a language is not specified, the system will attempt to identify the source language automatically. :type lang_src: :class:`str`; :class:`unicode` :param timeout: Timeout Will be used for every request. :type timeout: number or a double of numbers :param proxies: proxies Will be used for every request. :type proxies: class : dict; like: {'http': 'http:171.112.169.47:19934/', 'https': 'https:171.112.169.47:19934/'} ''' def __init__(self, url_suffix="com", timeout=5, proxies=None): # 构造函数初始化了翻译器对象。接受可选参数: # url_suffix:指定翻译服务的 URL 后缀,默认为 "com"。 # timeout:指定请求超时时间,默认为 5 秒。 # proxies:指定代理服务器,用于请求。默认为 None。 self.proxies = proxies if url_suffix not in URLS_SUFFIX: self.url_suffix = URL_SUFFIX_DEFAULT else: self.url_suffix = url_suffix url_base = "https://translate.google.{}".format(self.url_suffix) self.url = url_base + "/_/TranslateWebserverUi/data/batchexecute" self.timeout = timeout def _package_rpc(self, text, lang_src='auto', lang_tgt='auto'): # 内部方法,用于将请求数据打包成合适的格式。 # 它接受源文本 text、源语言 lang_src(默认为 'auto')和目标语言 lang_tgt(默认为 'auto')。 # 返回打包后的请求数据。 GOOGLE_TTS_RPC = ["MkEWBc"] # Google 翻译服务使用的标识。 parameter = [[text.strip(), lang_src, lang_tgt, True], [1]] # 二维列表 parameter,其中包含两个子列表。 # 第一个子列表包含源文本 text、源语言 lang_src、目标语言 lang_tgt 和布尔值 True,第二个子列表只包含数字 1。 escaped_parameter = json.dumps(parameter, separators=(',', ':')) # 将 parameter 列表转换为 JSON 格式的字符串,使用 ',' 和 ':' 作为分隔符。 # JSON 支持两种基本结构: # 对象(Object):由一组键值对组成,键和值之间使用冒号 : 分隔,键值对之间使用逗号 , 分隔,整个对象使用花括号 {} 包围。 # 数组(Array):由一组值组成,值之间使用逗号 , 分隔,整个数组使用方括号 [] 包围。数组通常用于表示有序的数据集合,而对象则用于表示键值关系。 rpc = [[[random.choice(GOOGLE_TTS_RPC), escaped_parameter, None, "generic"]]] espaced_rpc = json.dumps(rpc, separators=(',', ':')) # text_urldecode = quote(text.strip()) freq_initial = "f.req={}&".format(quote(espaced_rpc)) # 使用 URL 编码对 espaced_rpc 进行编码,并将其插入到字符串 "f.req={}&" 中。 # quote() 函数不仅适用于 JSON 数据,它可以用于任何需要进行 URL 编码的字符串。 # JSON 格式的数据本质上确实是字符串,但它是一种具有特定结构的字符串表示方式,用于表示复杂的数据结构 # 它使用文本表示数据,以便在不同的编程语言和平台之间进行传递和解析。 freq = freq_initial return freq def translate(self, text, lang_tgt='auto', lang_src='auto', pronounce=False): # 如果没有找到对应的语言,就将源语言和目标语言都设为 'auto'。 try: lang = LANGUAGES[lang_src] except: lang_src = 'auto' try: lang = LANGUAGES[lang_tgt] except: lang_src = 'auto' # 将输入的文本转换为字符串格式,并进行长度检查。如果文本长度超过5000个字符,返回警告信息。 text = str(text) if len(text) >= 5000: return "Warning: Can only detect less than 5000 characters" if len(text) == 0: # 如果文本长度为0,直接返回空字符串。 return "" # 创建请求头(headers),包括 Referer、User-Agent 和 Content-Type 等信息。 headers = { "Referer": "http://translate.google.{}/".format(self.url_suffix), # 浏览器向WEB 服务器表明自己是从哪个网页URL获得点击当前请求中的URL # 浏览器表明自己的身份 "User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) " "AppleWebKit/537.36 (KHTML, like Gecko) " "Chrome/115.0.0.0 Safari/537.36 Edg/115.0.1901.203", # WEB 服务器告诉浏览器自己响应的对象的类型。 "Content-Type": "application/x-www-form-urlencoded;charset=utf-8" } # 调用 _package_rpc 方法,生成请求数据。 freq = self._package_rpc(text, lang_src, lang_tgt) # 使用生成的请求数据创建一个待发送的 POST 请求对象。 # requests.request()本质是先创建Session对象然后创建Request对象 request = requests.Request(method='POST', url=self.url, data=freq, headers=headers, ) # 在 response 中构建了一个请求对象,但实际的请求发送是在接下来的 s.send(request=response.prepare(), ...) 这一步中进行的。 try: if self.proxies == None or type(self.proxies) != dict: self.proxies = {} with requests.Session() as s: # 使用 requests.Session 对象发送请求,并设置代理等信息。然后从响应中逐行解析数据。requests.session()本质也是Session对象 s.proxies = self.proxies r = s.send(request=request.prepare(), verify=False, timeout=self.timeout) # 发送请求后r即为响应内容 for line in r.iter_lines(chunk_size=1024): # 通过迭代方式逐行处理从服务器接收到的响应数据。r.iter_lines() 方法允许按照指定的块大小(chunk_size)进行数据分块,以防止一次性加载大量数据。 decoded_line = line.decode('utf-8') # 将每一行响应数据使用 UTF-8 编码进行解码,以获取可读的字符串内容。 if "MkEWBc" in decoded_line: # 在解析过程中,检查响应数据是否包含 "MkEWBc",这是一个请求标识。 try: # 找到 "MkEWBc"后,尝试对响应数据进行多层 JSON 解析,获取翻译结果和可能的发音信息。 # MkEWBc标识所在行包含了翻译文本信息和发音信息 response = json.loads(decoded_line) # decoded_line是str格式,转化成json列表或者字典按位置提取 response = json.loads(response[0][2]) # 提取的内容你那个仍然是str格式,需要继续转化成json列表或者字典按位置提取 response_ = list(response) response = response_[1][0] # 包含了翻译结果 # 根据解析的结果,构造翻译文本(translate_text)和发音信息(如果需要的话),最后返回相应的结果。 if len(response) == 1: if len(response[0]) > 5: sentences = response[0][5] else: ## only url sentences = response[0][0] if pronounce == False: return sentences elif pronounce == True: return [sentences, None, None] translate_text = "" for sentence in sentences: sentence = sentence[0] translate_text += sentence.strip() + ' ' translate_text = translate_text if pronounce == False: return translate_text elif pronounce == True: pronounce_src = (response_[0][0]) pronounce_tgt = (response_[1][0][0][1]) return [translate_text, pronounce_src, pronounce_tgt] elif len(response) == 2: sentences = [] for i in response: sentences.append(i[0]) if pronounce == False: return sentences elif pronounce == True: pronounce_src = (response_[0][0]) pronounce_tgt = (response_[1][0][0][1]) return [sentences, pronounce_src, pronounce_tgt] except Exception as e: raise e r.raise_for_status() except requests.exceptions.ConnectTimeout as e: raise e except requests.exceptions.HTTPError as e: # Request successful, bad response raise google_new_transError(tts=self, response=r) except requests.exceptions.RequestException as e: # Request failed raise google_new_transError(tts=self) def detect(self, text): text = str(text) if len(text) >= 5000: return log.debug("Warning: Can only detect less than 5000 characters") if len(text) == 0: return "" headers = { "Referer": "http://translate.google.{}/".format(self.url_suffix), # 浏览器向WEB 服务器表明自己是从哪个网页URL获得点击当前请求中的URL # 浏览器表明自己的身份 "User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) " "AppleWebKit/537.36 (KHTML, like Gecko) " "Chrome/115.0.0.0 Safari/537.36 Edg/115.0.1901.203", # WEB 服务器告诉浏览器自己响应的对象的类型。 "Content-Type": "application/x-www-form-urlencoded;charset=utf-8" } freq = self._package_rpc(text) response = requests.Request(method='POST', url=self.url, data=freq, headers=headers) try: if self.proxies == None or type(self.proxies) != dict: self.proxies = {} with requests.Session() as s: s.proxies = self.proxies r = s.send(request=response.prepare(), verify=False, timeout=self.timeout) for line in r.iter_lines(chunk_size=1024): decoded_line = line.decode('utf-8') if "MkEWBc" in decoded_line: # regex_str = r"\[\[\"wrb.fr\",\"MkEWBc\",\"\[\[(.*).*?,\[\[\[" try: response = json.loads(decoded_line) # decoded_line是str格式,转化成json列表或者字典按位置提取 response = json.loads(response[0][2]) # 提取的内容你那个仍然是str格式,需要继续转化成json列表或者字典按位置提取 response_ = list(response) detect_lang = response[0][2] except Exception: raise Exception # data_got = data_got.split('\\\"]')[0] return [detect_lang, LANGUAGES[detect_lang.lower()]] r.raise_for_status() except requests.exceptions.HTTPError as e: # Request successful, bad response log.debug(str(e)) raise google_new_transError(tts=self, response=r) except requests.exceptions.RequestException as e: # Request failed log.debug(str(e)) raise google_new_transError(tts=self) if __name__ == "__main__": translator = google_translator() translate_text = translator.translate('สวัสดีจีน', lang_tgt='en') detect_result = translator.detect('สวัสดีจีน') print() print("待翻译文本:", translate_text) print("输入文本的语言种类检测:", detect_result)- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 61
- 62
- 63
- 64
- 65
- 66
- 67
- 68
- 69
- 70
- 71
- 72
- 73
- 74
- 75
- 76
- 77
- 78
- 79
- 80
- 81
- 82
- 83
- 84
- 85
- 86
- 87
- 88
- 89
- 90
- 91
- 92
- 93
- 94
- 95
- 96
- 97
- 98
- 99
- 100
- 101
- 102
- 103
- 104
- 105
- 106
- 107
- 108
- 109
- 110
- 111
- 112
- 113
- 114
- 115
- 116
- 117
- 118
- 119
- 120
- 121
- 122
- 123
- 124
- 125
- 126
- 127
- 128
- 129
- 130
- 131
- 132
- 133
- 134
- 135
- 136
- 137
- 138
- 139
- 140
- 141
- 142
- 143
- 144
- 145
- 146
- 147
- 148
- 149
- 150
- 151
- 152
- 153
- 154
- 155
- 156
- 157
- 158
- 159
- 160
- 161
- 162
- 163
- 164
- 165
- 166
- 167
- 168
- 169
- 170
- 171
- 172
- 173
- 174
- 175
- 176
- 177
- 178
- 179
- 180
- 181
- 182
- 183
- 184
- 185
- 186
- 187
- 188
- 189
- 190
- 191
- 192
- 193
- 194
- 195
- 196
- 197
- 198
- 199
- 200
- 201
- 202
- 203
- 204
- 205
- 206
- 207
- 208
- 209
- 210
- 211
- 212
- 213
- 214
- 215
- 216
- 217
- 218
- 219
- 220
- 221
- 222
- 223
- 224
- 225
- 226
- 227
- 228
- 229
- 230
- 231
- 232
- 233
- 234
- 235
- 236
- 237
- 238
- 239
- 240
- 241
- 242
- 243
- 244
- 245
- 246
- 247
- 248
- 249
- 250
- 251
- 252
- 253
- 254
- 255
- 256
- 257
- 258
- 259
- 260
- 261
- 262
- 263
- 264
- 265
- 266
- 267
- 268
- 269
- 270
- 271
- 272
- 273
- 274
- 275
- 276
- 277
- 278
- 279
- 280
- 281
- 282
- 283
- 284
- 285
- 286
- 287
- 288
- 289
- 290
- 291
- 292
- 293
- 294
- 295
- 296
- 297
- 298
- 299
- 300
自定义测试需求:
(1)翻译功能
(2)语言检测功能
(3)性能测试指标TPS(Transaction per Second),每秒事务数反应出一个系统的处理能力。
(4)响应时间RT
(5)多接口组合进行压测基于爬虫的谷歌翻译接口业务接口逻辑很简单:
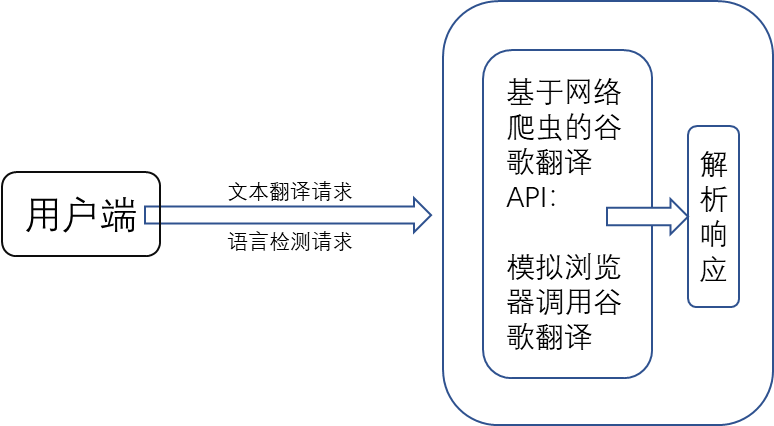
PS:如果是电商平台这种完整的应用,其搜索接口就会涉及到前端交互、大数据平台交互、后端搜索系统在数据库和索引平台之间的搜索、搜索系统和第三方推荐系统之间的交互等,上下游调用链是及其复杂的。基于爬虫的谷歌翻译接口仅需要调用谷歌翻译和解析响应,无需和其他系统或者平台交互,业务功能的调用链很简单。2.2 第二步:框架的搭建
框架设计:
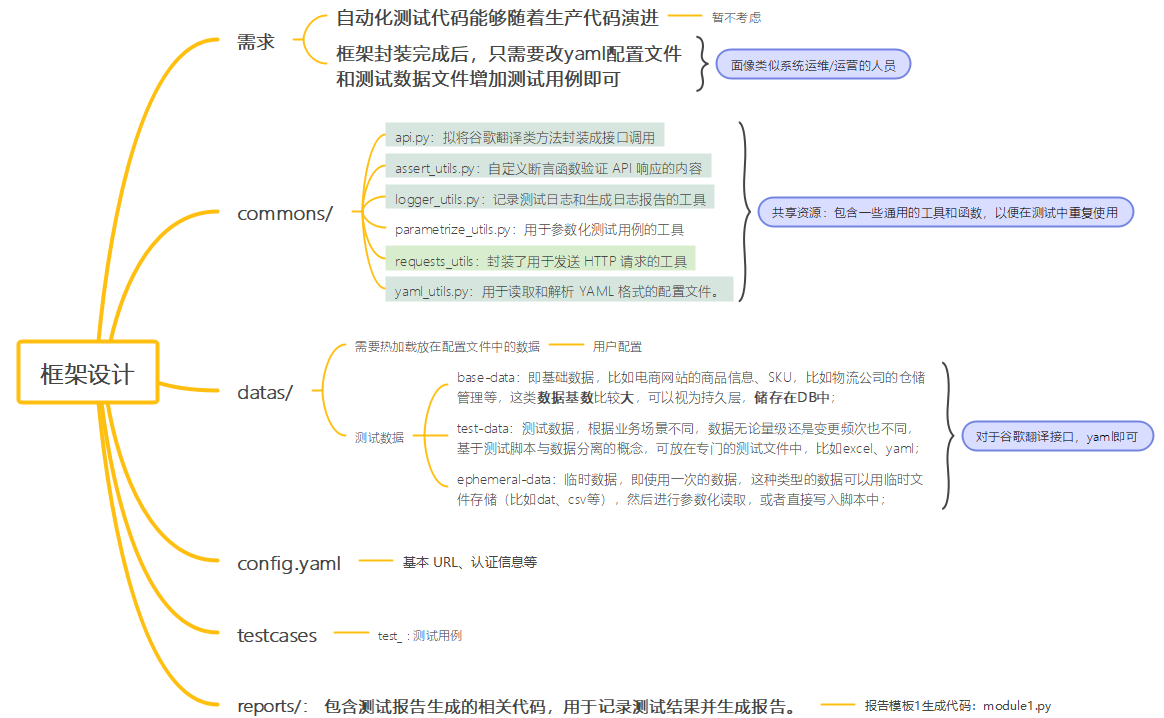
框架组织图:
框架决策记录:略。 -
相关阅读:
顶顶通呼叫中心中间件-添加自定义变量到CDR方法(mod_cti基于FreeSWITCH)
【24年物联网华为杯】赛题分析与初步计划
【Spring 学习系列】Bean 的生命周期之初始化与销毁
基于 Apache Hudi 和 Apache Spark Sql 的近实时数仓架构分享
在ubuntu用wine安装微信 并解决无法输入文字的问题 ubuntu完美安装微信
分子动力学模拟算法框架
【python】函数重构
【联通】数据编排技术在联通的应用
SSM+科技馆预约系统 毕业设计-附源码182154
模型的网页我可以正常访问(不知道是不是挂了梯子的原因)但是pycharm里就报错无法访问
- 原文地址:https://blog.csdn.net/a_beatiful_knife/article/details/132623344
