-
竞赛选题 基于机器视觉的手势检测和识别算法
0 前言
🔥 优质竞赛项目系列,今天要分享的是
基于深度学习的手势检测与识别算法
该项目较为新颖,适合作为竞赛课题方向,学长非常推荐!
🧿 更多资料, 项目分享:
https://gitee.com/dancheng-senior/postgraduate
1 实现效果
废话不多说,先看看学长实现的效果吧






2 技术原理
2.1 手部检测
主流的手势分割方法主要分为静态手势分割和动态手势分割两大类方法。
-
静态手势分割方法: 单张图片利用手和背景的差异进行分割,
-
动态手势分割方法: 利用了视频帧序列的信息来分割。
2.1.1 基于肤色空间的手势检测方法
肤色是手和其他背景最明显的区分特征,手的颜色范围较统一并且有聚类性,基于肤色的分割方法还有处理速度快,对旋转、局部遮挡、姿势变换具有不变性,因此利用不同的颜色空间来进行手势分割是现在最常用的方法。
肤色分割的方法主要有以下几种:基于参数、非参数的显式肤色聚类方法。参数模型使用高斯颜色分布,非参数模型则是从训练数据中获得肤色直方图来对肤色区间进行估计。肤色聚类显式地在某个特定的颜色空间中定义了肤色的边界,广义上看是一种静态的肤色滤波器,如Khan根据检测到的脸部提出了一种自适应的肤色模型。
肤色是一种低级的特征,对计算的消耗很少,感知上均匀的颜色空间如CIELAB,CIELUV等已经被用于进行肤色检测。正交的颜色空间如,YCbCr,YCgCr,YIQ,YUV等也被用与肤色分割,如Julilian等使用YCrCb颜色空间,利用其中的CrCb分量来建立高斯模型进行分割。使用肤色分割的问题是误检率非常高,所以需要通过颜色校正,图像归一化等操作来降低外界的干扰,提高分割的准确率。
基于YCrCb颜色空间Cr, Cb范围筛选法手部检测,实现代码如下:
# 肤色检测之二: YCrCb中 140<=Cr<=175 100<=Cb<=120
img = cv2.imread(imname, cv2.IMREAD_COLOR)
ycrcb = cv2.cvtColor(img, cv2.COLOR_BGR2YCrCb) # 把图像转换到YUV色域
(y, cr, cb) = cv2.split(ycrcb) # 图像分割, 分别获取y, cr, br通道分量图像skin2 = np.zeros(cr.shape, dtype=np.uint8) # 根据源图像的大小创建一个全0的矩阵,用于保存图像数据 (x, y) = cr.shape # 获取源图像数据的长和宽 # 遍历图像, 判断Cr和Br通道的数值, 如果在指定范围中, 则置把新图像的点设为255,否则设为0 for i in range(0, x): for j in range(0, y): if (cr[i][j] > 140) and (cr[i][j] < 175) and (cb[i][j] > 100) and (cb[i][j] < 120): skin2[i][j] = 255 else: skin2[i][j] = 0 cv2.imshow(imname, img) cv2.imshow(imname + " Skin2 Cr+Cb", skin2)- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
检测效果:


2.1.2 基于运动的手势检测方法
基于运动的手势分割方法将运动的前景和静止的背景分割开,主要有背景差分法、帧间差分法、光流法等。
帧间差分选取视频流中前后相邻的帧进行差分,设定一定的阈值来区分前景和后景,从而提取目标物体。帧差法原理简单,计算方便且迅速,但是当前后景颜色相同时检测目标会不完整,静止目标则无法检测。
背景差分需要建立背景图,利用当前帧和背景图做差分,从而分离出前后景。背景差分在进行目标检测中使用较多。有基于单高斯模型,双高斯模型的背景差分,核密度估计法等。景差分能很好的提取完整的目标,但是受环境变化的影响比较大,因此需要建立稳定可靠的背景模型和有效的背景更新方法。
1, 读取摄像头
2, 背景减除
fgbg1 = cv.createBackgroundSubtractorMOG2(detectShadows=True)
fgbg2 = cv.createBackgroundSubtractorKNN(detectShadows=True)
# fgmask = fgbg1.apply(frame)
fgmask = fgbg2.apply(frame) # 两种方法
3, 将没帧图像转化为灰度图像 在高斯去噪 最后图像二值化
gray = cv.cvtColor(res, cv.COLOR_BGR2GRAY)
blur = cv.GaussianBlur(gray, (11, 11), 0)
ret, binary = cv.threshold(blur, 0, 255, cv.THRESH_BINARY | cv.THRESH_OTSU)
4, 选取手部的 ROI 区域 绘制轮廓
gesture = dst[50:600, 400:700]
contours, heriachy = cv.findContours(gesture, cv.RETR_EXTERNAL, cv.CHAIN_APPROX_SIMPLE) # 获取轮廓本身
for i, contour in enumerate(contours): # 获取轮廓
cv.drawContours(frame, contours, i, (0, 0, 255), -1) # 绘制轮廓
print(i)
2.1.3 基于边缘的手势检测方法
基于边缘的手势分割方法利用边缘检测算子在图像中计算出图像的轮廓,常用来进行边缘检测的一阶算子有(Roberts算子,Prewitt算子,Sobel算子,Canny算子等),二阶算子则有(Marr-
Hildreth算子,Laplacian算子等),这些算子在图像中找到手的边缘。但是边缘检测对噪声比较敏感,因此精确度往往不高。边缘检测代码示例:
import numpy as np
from PIL import Image
import matplotlib.pyplot as plt
import matplotlib.cm as cm
import scipy.signal as signal # 导入sicpy的signal模块# Laplace算子 suanzi1 = np.array([[0, 1, 0], [1,-4, 1], [0, 1, 0]]) # Laplace扩展算子 suanzi2 = np.array([[1, 1, 1], [1,-8, 1], [1, 1, 1]]) # 打开图像并转化成灰度图像 image = Image.open("pika.jpg").convert("L") image_array = np.array(image) # 利用signal的convolve计算卷积 image_suanzi1 = signal.convolve2d(image_array,suanzi1,mode="same") image_suanzi2 = signal.convolve2d(image_array,suanzi2,mode="same") # 将卷积结果转化成0~255 image_suanzi1 = (image_suanzi1/float(image_suanzi1.max()))*255 image_suanzi2 = (image_suanzi2/float(image_suanzi2.max()))*255 # 为了使看清边缘检测结果,将大于灰度平均值的灰度变成255(白色) image_suanzi1[image_suanzi1>image_suanzi1.mean()] = 255 image_suanzi2[image_suanzi2>image_suanzi2.mean()] = 255 # 显示图像 plt.subplot(2,1,1) plt.imshow(image_array,cmap=cm.gray) plt.axis("off") plt.subplot(2,2,3) plt.imshow(image_suanzi1,cmap=cm.gray) plt.axis("off") plt.subplot(2,2,4) plt.imshow(image_suanzi2,cmap=cm.gray) plt.axis("off") plt.show()- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
2.1.4 基于模板的手势检测方法
基于模版的手势分割方法需要建立手势模版数据库,数据库记录了不同手势不同场景下的手势模版。计算某个图像块和数据库中各个手势的距离,然后使用滑动窗遍历整幅图像进行相同的计算,从而在图像正确的位置找到数据库中的最佳匹配。模版匹配对环境和噪声鲁棒,但是数据库需要涵盖各种手型、大小、位置、角度的手势,并且因为需要遍历整个图像进行相同的计算,实时性较差。
2.1.5 基于机器学习的手势检测方法
贝叶斯网络,聚类分析,高斯分类器等等也被用来做基于肤色的分割。随机森林是一种集成的分类器,易于训练并且准确率较高,被用在分割和手势识别上。建立肤色分类的模型,并且使用随机森林对像素进行分类,发现随机森林得到的分割结果比上述的方法都要准确.
3 手部识别
毫无疑问,深度学习做图像识别在准确度上拥有天然的优势,对手势的识别使用深度学习卷积网络算法效果是非常优秀的。
3.1 SSD网络
SSD网络是2016年提出的卷积神经网络,其在物体检测上取得了很好的效果。SSD网络和FCN网络一样,最终的预测结果利用了不同尺度的特征图信息,在不同尺度的特征图上进行检测,大的特征图可以检测小物体,小特征图检测大物体,使用金字塔结构的特征图,从而实现多尺度的检测。网络会对每个检测到物体的检测框进行打分,得到框中物体所属的类别,并且调整边框的比例和位置以适应对象的形状。
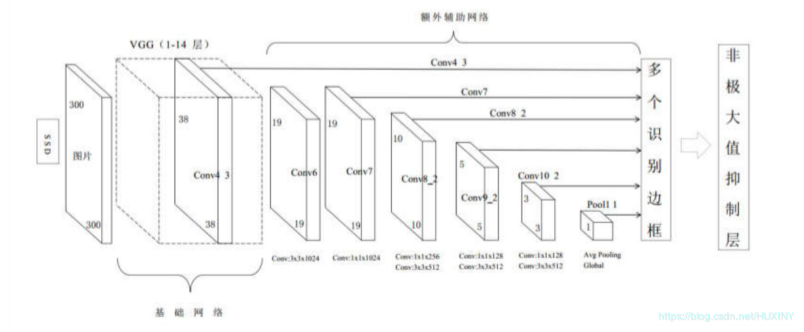
3.2 数据集
我们实验室自己采集的数据集:
数据集包含了48个手势视频,这些视频是由谷歌眼镜拍摄的,视频中以第一人称视角拍摄了室内室外的多人互动。数据集中包含4个类别的手势:自己的左右手,其他人的左右手。数据集中包含了高质量、像素级别标注的分割数据集和检测框标注数据集,视频中手不受到任何约束,包括了搭积木,下棋,猜谜等活动。

需要数据集的同学可以联系学长获取
3.3 最终改进的网络结构
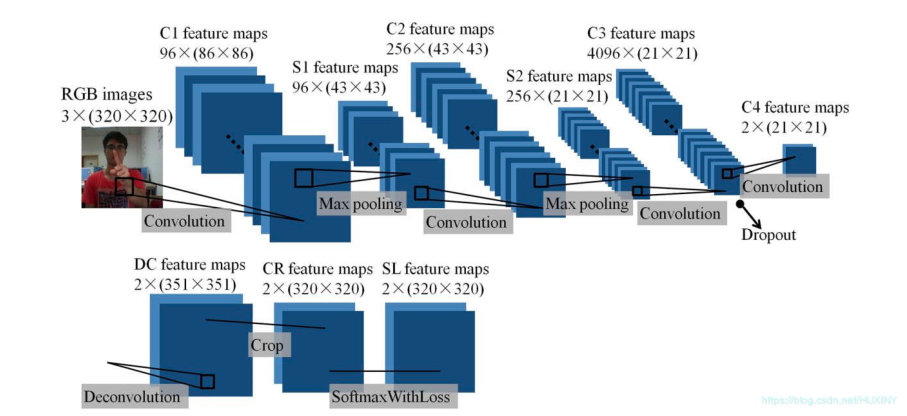

最后整体实现效果还是不错的:
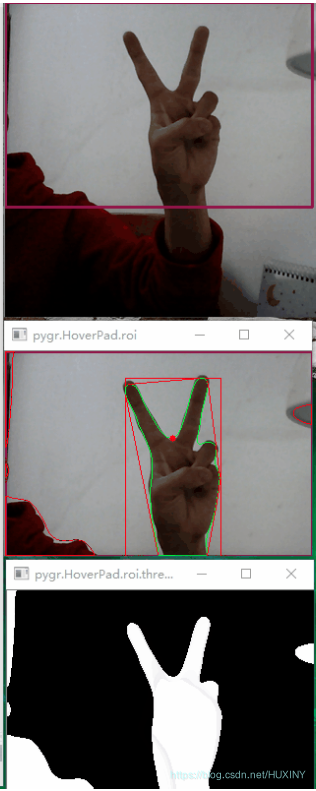
4 最后
🧿 更多资料, 项目分享:
-
-
相关阅读:
arduino - 用 arduino zero 开发板来学习理解arduino软件编程细节
LVS+Keepalived群集
贪心算法之背包问题
Go语言学习——map
06c++呵呵老师【FPS实现游戏角色】
[山东科技大学OJ]1169 Problem I: 统计单词数
Arthas简介和安装
红队专题-Cobalt strike 4.x - Beacon重构
Mysql语句分析、存储引擎、索引优化等详情
曲线救国|基于函数计算FC3.0部署AI数字绘画stable-diffusion
- 原文地址:https://blog.csdn.net/laafeer/article/details/132859126
