-
动手学深度学习_个人笔记_李沐(更新中......)
序言
神经网络——本书中关注的DL模型的前身,被认为是过时的工具。
深度学习在近几年推动了CV、NLP和ASR等领域的快速发展。
关于本书
让DL平易近人,教会概念、背景和代码。
一种结合了代码、数学和HTML的媒介
测试深度学习(DL)的潜力带来了独特的挑战,因为任何一个应用都会将不同的学科结合在一起。应用DL需要同时了解:
(1)以特定方式提出问题的动机;
(2)给定建模方法的数学;
(3)将模型拟合数据的优化算 法;
(4)能够有效训练模型、克服数值计算缺陷并最大限度地利用现有硬件的工程方法。
同时教授表述问题所需的批判性思维技能、解决问题所需的数学知识,以及实现这些解决方案所需的软件工具,这是一个巨大的挑战。我们着手创建的资源可以:(1)每个人都可以免费获得;(2)提供足够的技术深度,为真正成为一名应用机 器学习科学家提供起步;(3)包括可运行的代码,向读者展示如何解决实践中的问题;(4)允许我们和社区 的快速更新;(5)由一个论坛作为补充,用于技术细节的互动讨论和回答问题。
这些目标经常是相互冲突的。公式、定理和引用最好用LaTeX来管理和布局。代码最好用Python描述。网⻚原生是HTML和JavaScript的。
此外,我们希望内容既可以作为可执行代码访问、作为纸质书访问,作为可下载的PDF访问,也可以作为网站在互联网上访问。目前还没有完全适合这些需求的工具和工作流程,所以我 们不得不自行组装。
我们在 16.5节中详细描述了我们的方法。我们选择GitHub来共享源代码并允许编辑,选择Jupyter记事本来混合代码、公式和文本,选择Sphinx作为渲染引擎来生成多个输出,并为论坛提供讨论。 虽然我们的体系尚不完善,但这些选择在相互冲突的问题之间提供了一个很好的妥协。我们相信,这可能是 第一本使用这种集成工作流程出版的书。在实践中学习
本书实践性强!一定要动手实践,体会训练model的满足感!
内容和结构
全书大致分为3个部分,图1中用不同颜色呈现
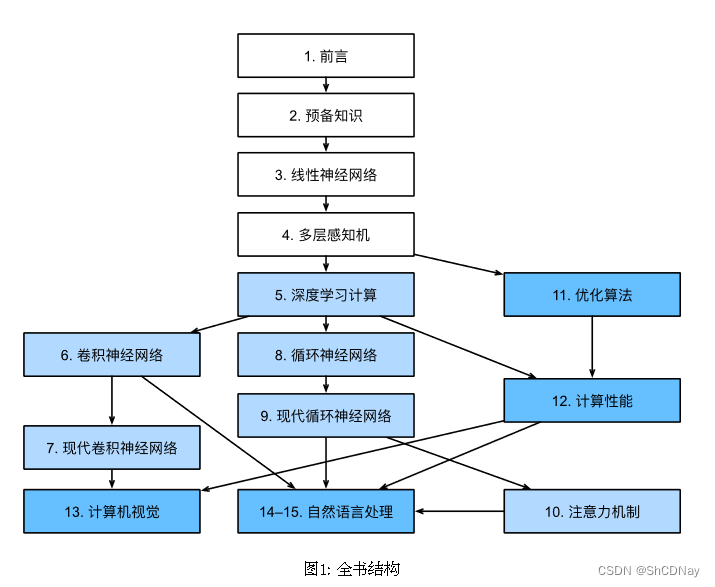
- 1 - 4节:基础知识和预备知识。
- 5 - 9节:集中讨论现代DL技术。
- 10节:介绍一类新的model,它采用注意力机制技术。
- 11 - 15节:讨论可伸缩性、效率和应用程序。
代码
本书中的大部分代码都是基于PyTorch的。PyTorch是一个开源的深度学习框架,在研究界非常受欢迎。本书中的所有代码都在最新版本的PyTorch下通过了测试。但是,由于深度学习的快速发展,一些在印刷版中代码可能在PyTorch的未来版本无法正常工作。但是,我们计划使在线版本保持最新。如果你遇到任何此类问题,请查看安装 (page 9) 以更新你的代码和运行时环境。
目标受众
本书面向学生(本科生或研究生)、工程师和研究人员,他们希望扎实掌握深度学习的实用技术。
论坛
discuss.d2l.ai
小结

练习
安装
安装 Miniconda
以下是Miniconda的官方介绍:
Miniconda is a free minimal installer for conda. It is a small bootstrap version of Anaconda that includes only conda, Python, the packages they both depend on, and a small number of other useful packages (like pip, zlib, and a few others). If you need more packages, use the conda install command to install from thousands of packages available by default in Anaconda’s public repo, or from other channels, like conda-forge or bioconda.安装深度学习框架和d2l软件包
注意安装或下载相关包时,不要翻墙,否则将会被拒绝访问导致下载失败!
创建学习该书中的项目时,要为每一个项目安装对应环境,否则可能出现环境与项目不匹配而导致无法运行的情况出现。例如pip install d2l时,需要创建一个新环境:conda create -n customname python=3.8,注意customname是由个人以项目相关名称进行命名的。在运行书籍代码、更新深度学习框架或d2l软件包之前,请始终执行conda activate d2l以 激活运行时环境。要退出环境,请运行conda deactivate。
符号





1 前言
机器学习(ML)是一类强大的可以从经验中学习的技术,通常采用观测数据或与环境交互的形式。
本书将带领你开启ML之旅,并特别关注DL的基础知识。1.1 日常生活中的机器学习
dataset
parameter
model
模型族:通过操作参数而生成的所有不同程序(输入-输出映射)的集合。
learning algorithm:使用dataset来选择参数的元程序。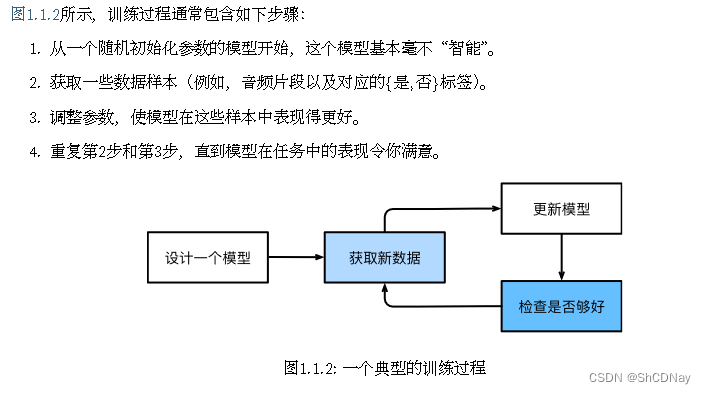
DL是ML的一个主要分支。1.2 关键组件

1.2.1 数据
独立同分布(independently and identically distributed, i.i.d)
样本有时也叫做数据点 (data point)或者数据实例(data instance),通常每个样本由一组称为特征(features,或协变量(covariates))的属性组成。机器学习模型会根据这些属性进行预测。在上面的监督学习问题中,要预测的是一个特殊的属 性,它被称为标签(label,或目标(target))。
当每个样本的特征类别数量都是相同的时候,其特征向量是固定⻓度的,这个⻓度被称为数据的维数(dimensionality)。固定⻓度的特征向量是一个方便的属性,它有助于我们量化学习大量样本。
然而,并不是所有的数据都可以用“固定⻓度”的向量表示。与传统机器学习方法相比,深度学习的一个主要优势是可以处理不同⻓度的数据。
一般来说,数据越多,工作就越容易。数据集的由小变大为现代深度学习的成功奠定基础。注意,仅仅拥有海量数据也不够,还需要正确的数据!
古语:“Garbage in, garbage out.”
ML模型具有inductive bias。
1.2.2 模型
深度学习与经典方法的区别主要在于:DL关注的功能强大的模型,这些模型由神经网络错综复杂的交织在一起,包含层层数据转换,因此被称为深度学习(deep learning)。
1.2.3 目标函数
机器学习中的“从经验中学习”,“学习”指自主提高model完成某些任务的效能。
objective function(目标函数):在ML中,需要定义模型的优劣程度的度量,这个度量在大多数情况是“可优化”的,称为目标函数。
损失函数(loss function,或cost function): 我们通常定义一个目标函数,并希望优化它到最低点。因为越低越好,所以这些函数有时被称为损失函数。
当任务在试图预测数值时,最常⻅的损失函数是平方误差(squared error),即预测值与实际值之差的平方。
通常将可用数据集分成两部分:训练数据集(training dataset)用于拟合模型参数,测试数据集(test dataset)用于评估拟合的模型。
overfitting:一个模型在训练集上表现良好,但不能推 广到测试集。
1.2.4 优化算法
一旦我们获得了一些数据源及其表示、一个模型和一个合适的损失函数,我们接下来就需要一种算法,它能 够搜索出最佳参数,以最小化损失函数。DL中,大多流行的优化算法通常基于一种基本方法‒梯度下降 (gradient descent)。
1.3 各种机器学习问题
下面是一些常⻅机器学习问题和应用,后续将不断引用前 面提到的概念,如数据、模型和训练技术。
Examples of supervised learning problems include classification and regression, and examples of supervised learning algorithms include logistic regression and random forest.
1.3.1 监督学习
监督学习(supervised learning)擅⻓在“给定输入特征”的情况下预测标签。每个“特征-标签”对都称为一 个样本(example)。
虽然监督学习只是几大类 机器学习问题之一,但是在工业中,大部分机器学习的成功应用都是监督学习。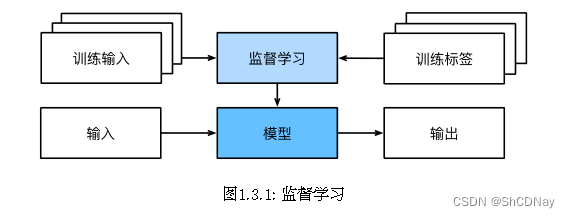
regression
回归(regression)是最简单的监督学习任务之一。当标签取任意数值(即实数集R)时,称之为回归问题。我们的目标是生成一个模型,它的预测非常接近实际标签值。
总而言之,判断回归问题的一个很好的经验 法则是,任何有关“多少”的问题很可能就是回归问题。
在本书大部分章节中,我们将关注最小化平方 误差损失函数。正如我们稍后将看到的,这种损失对应于我们的数据被高斯噪声破坏的假设。
分类(classification)
classification:预测样本属于哪个类别(category,正式称为类(class))
cross-entropy(交叉熵)
multiclass classification(多元分类)分类可能变得比二元分类、多元分类复杂得多。
层次分类(hierarchical classification): 宁愿错误地分入一个相关 的类别,也不愿错误地分入一个遥远的类别。
标记问题
学习预测不相互排斥的类别的问题称为多标签分类(multi-label classification)。
搜索
如今,搜索引擎使用ML和用户行为模型来获取网页相关性得分,很多学术会议也致力于这一主题。
推荐系统
另一类与搜索和排名相关的问题是推荐系统(recommender system),它的目标是向特定用戶进行“个性化” 推荐。
对于任何给定的用戶,推荐系统都可以检索得分最高的对象集,然后将其推荐 给用戶。以上只是简单的算法,而工业生产的推荐系统要先进得多,它会将详细的用戶活动和项目特征考虑在内。
序列学习
1.3.2 无监督学习
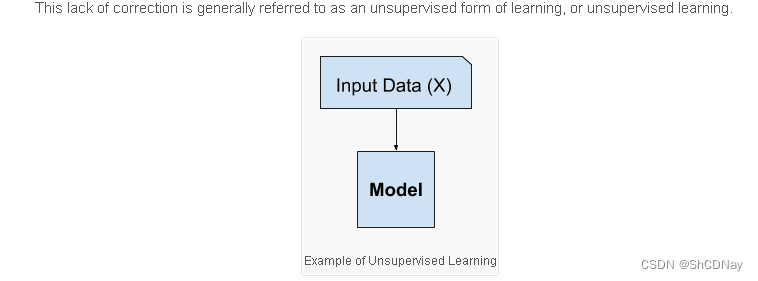
Examples of unsupervised learning problems include clustering and generative modeling, and examples of unsupervised learning algorithms are K-means and Generative Adversarial Networks.无监督学习可以回答的问题:
- 聚类(clustering)问题
- 主成分分析(principal component analysis)问题
- 因果关系(causality)和概率图模型(probabilistic graphical models)问题
- 生成对抗性网络(generative adversarial networks):为我们提供一种合成数据的方法,甚至像图像和 音频这样复杂的结构化数据。
1.3.3 与环境互动
离线学习(offline learning):所有学习都是在算法与环境断开后进行的。
对于监督学习,从环境中收集数据 的过程类似于 图1.3.6。
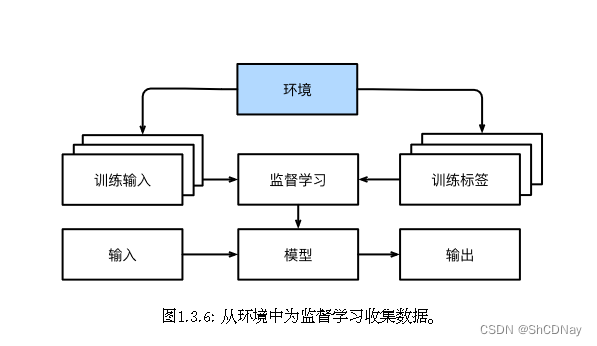
分布偏移(distribution shift)的问题
1.3.4 强化学习
如果你对使用机器学习开发与环境交互并采取行动感兴趣,那么你最终可能会专注于强化学习(reinforcement learning)。这可能包括应用到机器人、对话系统,甚至开发视频游戏的人工智能(AI)。深度强化学习(deep reinforcement learning)将深度学习应用于强化学习的问题,是非常热⻔的研究领域。
请注意,强化学习的目标是产生一个好的策略(policy)。强化学习agent选择的“动作”受策略控制,即一个从环境观察映射到行动的功能。
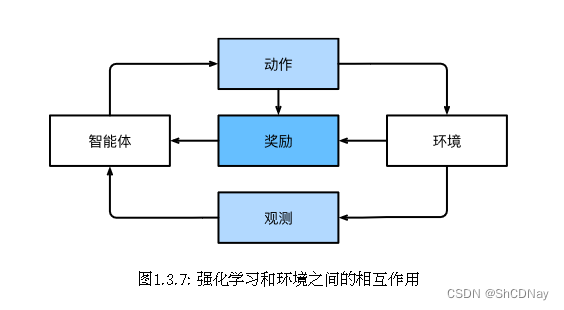
当环境可被完全观察到时,我们将强化学习问题称为⻢尔可夫决策过程(markov decision process)。当状态 不依赖于之前的操作时,我们称该问题为上下文赌博机(contextual bandit problem)。当没有状态,只有一 组最初未知回报的可用动作时,这个问题就是经典的多臂赌博机(multi-armed bandit problem)。
1.4 起源
神经网络(neural networks)的得名源于生物灵感。其核心是当今大多数网络中都可以找到的几个关键原则:
- 线性和非线性处理单元的交替,通常称为层(layers)。
- 使用链式规则(也称为反向传播(backpropagation))一次性调整网络中的全部参数。
1.5 深度学习之路
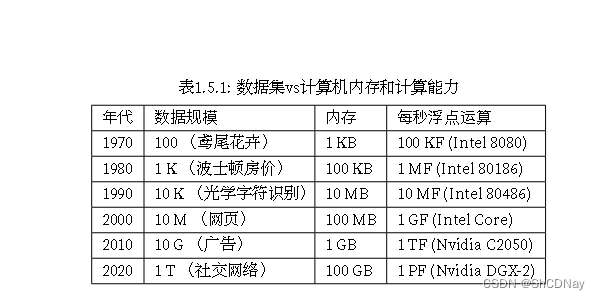
RAM没有跟上数据增长的步伐,同时算力的增⻓速度已经超过了现有数据的增⻓速度。这意味着统计模型需要提高内存效率(这通常是通过添加非线性来实现的),同时由于计算预算的增加, 能够花费更多时间来优化这些参数。因此,机器学习和统计的关注点从(广义的)线性模型和核方法转移到了 深度神经网络。这也造就了许多深度学习的中流砥柱,如多层感知机 [McCulloch & Pitts, 1943] 、卷积神经网 络 [LeCun et al., 1998] 、⻓短期记忆网络 [Graves & Schmidhuber, 2005] 和Q学习 [Watkins & Dayan, 1992] , 在相对休眠了相当⻓一段时间之后,在过去十年中被“重新发现”。
系统研究人员构建更好的工具”和“统计建模人员构建更好的神经网络”之间的分工大大简化了工作。例 如,在2014年,对于卡内基梅隆大学机器学习博士生来说,训练线性回归模型曾经是一个不容易的作业问题。 而现在,这项任务只需不到10行代码就能完成,这让每个程序员轻易掌握了它。
1.6 成功案例
- 智能助理,如苹果的Siri、亚⻢逊的Alexa和谷歌助手。
- 数字助理的一个关键要素是准确识别语音的能力。
- 物体识别同样也取得了⻓足的进步。
- 游戏曾经是人类智慧的堡垒。
- 人工智能进步的另一个迹象是自动驾驶汽⻋和卡⻋的出现。
同样,上面的列表仅仅触及了机器学习对实际应用的影响之处的皮毛。例如,机器人学、物流、计算生物学、 粒子物理学和天文学最近取得的一些突破性进展至少部分归功于机器学习。因此,机器学习正在成为工程师 和科学家必备的工具。
AI的伦理问题。
1.7 特点
到目前为止,我们已经广泛地讨论了机器学习,它既是人工智能的一个分支,也是人工智能的一种方法。虽 然深度学习是机器学习的一个子集,但令人眼花缭乱的算法和应用程序集让人很难评估深度学习的具体成分 是什么。这就像试图确定披萨所需的配料一样困难,因为几乎每种成分都是可以替代的。
深度学习是“深度”的,模型 学习了许多“层”的转换,每一层提供一个层次的表示。由于表示学习(representation learning)目的是寻 找表示本身,因此深度学习可以称为“多级表示学习”。最后,深度学习社区引以为豪的是,他们跨越学术界和企业界共享工具,发布了许多优秀的算法库、统计模 型和经过训练的开源神经网络。正是本着这种精神,本书免费分发和使用。我们努力降低每个人了解深度学习的⻔槛,我们希望我们的读者能从中受益。
1.8 小结

1.9 练习
2 预备知识
tensor(张量)
2.1 数据操作
2.1.1 入⻔


注意,通过改变张量的形状, 张量的大小不会改变。
2.1.2 运算符
我们的兴趣不仅限于读取数据和写入数据。我们想在这些数据上执行数学运算,其中最简单且最有用的操作 是按元素(elementwise)运算。它们将标准标量运算符应用于数组的每个元素。
2.1.3 广播机制(broadcasting mechanism)
这种机制的工作方式如 下:首先,通过适当复制元素来扩展一个或两个数组,以便在转换之后,两个张量具有相同的形状。其次,对 生成的数组执行按元素操作。
2.1.4 索引和切片
就像在任何其他Python数组中一样,张量中的元素可以通过索引访问。与任何Python数组一样:第一个元素 的索引是0,最后一个元素索引是-1;可以指定范围以包含第一个元素和最后一个之前的元素。
2.1.5 节省内存

2.1.6 转换为其他Python对象
2.1.7 小结
深度学习存储和操作数据的主要接口是张量(n维数组)。它提供了各种功能,包括基本数学运算、广 播、索引、切片、内存节省和转换其他Python对象。
2.1.8 练习
2.2 数据预处理
注意编程实践。
2.2.1 读取数据集
2.2.2 处理缺失值
2.2.3 转换为张量格式
2.2.4 小结
- pandas软件包是Python中常用的数据分析工具,pandas可以与张量兼容。
- 用pandas处理缺失的数据时,我们可根据情况选择用插值法和删除法。
2.3 线性代数
2.3.1 标量(scalar)
表达式c = 5 / 9 (f - 32),符号c和f 称为变量(variable),它们表示未知的标量值。
2.3.2 向量
⻓度、维度和形状


2.3.3 矩阵

2.3.4 张量

2.3.5 张量算法的基本性质

将张量乘以或加上一个标量不会改变张量的形状,其中张量的每个元素都将与标量相加或相乘。
2.3.6 降维

2.3.7 点积(Dot Product)
3 线性神经网络
4 多层感知机
5 深度学习计算
6 卷积神经网络
7 现代卷积神经网络
8 循环神经网络
9 现代循环神经网络
10 注意力机制
11 优化算法
12 计算性能
13 计算机视觉
14 自然语言处理:预训练
15 自然语言处理:应用
16 附录:深度学习工具
Bibliography
-
相关阅读:
前端从H5调起微信扫码兼容问题、安卓可以调起,但是在IOS系统config方法报invalid signature签名错误的问题
springboot集成Logback 日志写入数据库
SpringMVC【文件上传(原生方式上传、上传多文件、异步上传、跨服务器上传 ) 】(五)-全面详解(学习总结---从入门到深化)
代码随想录算法训练营第五十三天| 309.最佳买卖股票时机含冷冻期 、714.买卖股票的最佳时机含手续费
C++学习记录1
单片机编程原则
Day815.数据库参数设置优化 -Java 性能调优实战
网络安全课题以及学术方向总结
LQ0203 排它平方数【枚举+进制】
社区分享|中南民族大学基于JumpServer构建规范、便利的运维安全体系
- 原文地址:https://blog.csdn.net/Sjoqwdk/article/details/132839766