-
Kafka消费者组重平衡(一)
概述
重平衡,也就是Rebalance, 就是让一个 Consumer Group 下所有的 Consumer 实例就如何消费订阅主题的所有分区达成共识的过程。在 Rebalance 过程中,所有 Consumer 实例共同参与,在协调者组件的帮助下,完成订阅主题分区的分配。
Kafka消费者重平衡时一个很重要的概念,本文主要从什么是消费组,什么消费者组协调器,重平衡有哪些影响,又该如何降低重平衡这几方面来总结。消费者组特点
从broker端读取消息的客户端,称为消费者;具有相同group.id的消费者,属于同一个消费组,即Consumer Group。概括就是:Consumer Group 是 Kafka 提供的可扩展且具有容错性的消费者机制
分区与消费者之间的对应关系,大致可以总结为以下几种:
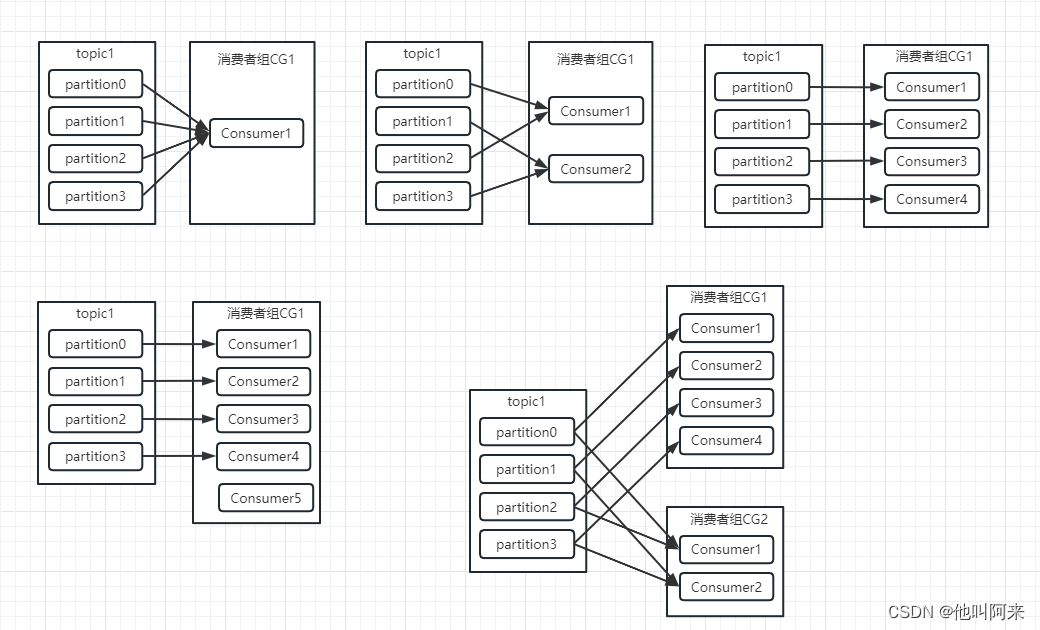
- Consumer Group 之间彼此独立,互不影响,它们能够订阅相同的一组主题而互不干涉
- Consumer Group 下可以有一个或多个 Consumer 实例。这里的实例可以是一个单独的进程,也可以是同一进程下的线程。在实际场景中,使用进程更为常见
- Group ID 是一个字符串,在一个 Kafka 集群中,它标识唯一的一个 Consumer Group
- Consumer Group 下所有实例订阅的主题的单个分区,只能分配给组内的某个 Consumer 实例消费。
针对Consumer Group,Kafka是怎么管理位移的呢?
在kafka的位移这篇文章中,详细地介绍了Kafka对位移地管理,这里总结一下:
Consumer Group的位移存储主题中,
__consumer_offsets这个主题中的消息格式为KV对,key为[Group, Topic, Partition],value可以简单理解为记录了偏移量;这样的记录方式,使得broker端不需要关心group下有多少个消费者,新增消费者或者减少消费者发生重平衡时,都能准确地定位到对应地分区应该从哪个位置开始消费。什么是 Coordinator
协调者,在 Kafka 中对应的术语是 Coordinator,它专门为 Consumer Group 服务,负责为 Group 执行Rebalance 以及提供位移管理和组成员管理等。
Consumer 端应用程序在提交位移时,其实是向 Coordinator 所在的 Broker提交位移。同样地,当 Consumer 应用启动时,也是向 Coordinator 所在的 Broker 发送各种请求,然后由 Coordinator 负责执行消费者组的注册、成员管理记录等元数据管理操作。
Consumer Group 如何确定为它服务的Coordinator 在哪台 Broker 上呢?跟内部主题__consumer_offsets 有关。
Kafka 为某个 Consumer Group 确定 Coordinator 所在的 Broker 的算法有 2 个步骤。
第一步:确定该group的位移由
__consumer_offsets的哪个分区partitionId=Math.abs(groupId.hashCode() % offsetsTopicPartitionCount)- 1
第二步:找出partitionId对应的Leader副本所在的Broker,该Broker就是Coordinator
以上面的
test-group为例,先计算出要提交的分区号@Test void getCommitOffsetPartitionTest() { String groupId = "test-group"; System.out.println(Math.abs(groupId.hashCode() % 50)); }- 1
- 2
- 3
- 4
- 5
上面运行结果是12,也就是,位移主题的分区 12 负责保存这个 Group 的数据。有了分区号,根据步骤2找出这个分区的Leader副本所在的Broker 上就可以了。这个 Broker,就是我们要找的 Coordinator
重平衡影响
重平衡,也就是Rebalance, 就是让一个 Consumer Group 下所有的 Consumer 实例就如何消费订阅主题的所有分区达成共识的过程。在 Rebalance 过程中,所有 Consumer 实例共同参与,在协调者组件的帮助下,完成订阅主题分区的分配。
在项目稳定运行的过程中,最好的能够避免进行重平衡,在重平衡的过程中,整个kafka集群是不能对外提供消息消费的,在消息高峰期必定引起消息堆积,影响吞吐量。总结下来,重平衡只要有以下2个方面的影响:
- Rebalance 影响 Consumer 端 TPS,在Rebalance期间,Consumer会停下手头的事情,什么也不干。
- Rebalance 很慢。Rebalance时,Group下所有成员都会参与进来,如果 Group 下成员很多,Rebalance过程会消耗很长时间,这个期间,消息不能被消费
那么应该如何避免重平衡呢?
Rebalance发生的时机,主要有3个
- 组成员数量发生变化
- 订阅主题数量发生变化
- 订阅主题的分区数发生变化
在真实的业务场景中,大多是因为组成员的数量发生了变化引起Rebalance。
当启动一个配置有相同 group.id 值的Consumer 程序时,就会向这个Group 添加了一个新的 Consumer 实例。Coordinator 会接纳这个新实例,将其加入到组中,并重新分配分区。通常来说,增加Consumer 实例的操作都是计划内的,比如为了增加TPS。这个Rebalance是意料之中的。
而我们要规避的是“不必要的Rebalance”,重点主要讨论这个。
三个重要的参数
当 Consumer Group 完成 Rebalance 之后,每个 Consumer 实例都会定期地向Coordinator 发送心跳请求,表明它还存活着。如果某个 Consumer 实例不能及时地发送心跳请求,Coordinator 就会认为该 Consumer 已经“死”了,从而将其从 Group中移除,然后开启新一轮 Rebalance。
session.timeout.ms: 默认值10s,如果 Coordinator 在 10 秒之内没有收到 Group 下某 Consumer 实例的心跳,它就会认为这个 Consumer 实例已经挂了。这个参数决定了Consumer 存活性的时间间隔。heartbeat.interval.ms: 默认值3s,控制发送心跳请求频率的参数,每隔3s发送一次心跳。broker会在心跳请求的响应中返回是否需要开启重平衡。这个值设置得越小,Consumer 实例发送心跳请求的频率就越高。频繁地发送心跳请求会额外消耗带宽资源,但好处是能够更加快速地知晓当前是否开启Rebalance。max.poll.interval.ms: Consumer 端应用程序两次调用 poll 方法的最大时间间隔。它的默认值是 5 分钟,表示你的 Consumer 程序如果在 5分钟之内无法消费完 poll 方法返回的消息,那么 Consumer 会主动发起“离开组”的请求,Coordinator 也会开启新一轮 Rebalance。以个人经验,有两种常见的情况会出现Rebalance。
- Consumer服务器与Broker端出现网络通信波动或Consumer端出现了频繁的FullGC,这种情况都会导致心跳线程与Broker之间的通信
- Consumer端使用同步消费,poll下来的消息消费时间过长,也会引发Rebalance。
Rebalance是Kafka自我保护的机制,而出现Rebalance的两大诱因(消费者线程挂起、网络异常)都无法100%避免,那么我们就根据业务情况,合理的调优一下kafka的配置参数,从而减少rebalance出现的概率。
参数调整,可以参考阿里云文档:https://help.aliyun.com/document_detail/154454.html
-
相关阅读:
uniapp实现安卓端导出execl、打包excel为zip压缩文件、分享zip压缩文件到微信、qq
English语法_形容词/副词3级 - 比较级
【小嘟陪你刷题03】牛客网——Java专项练习
C#数据库操作
百度开放平台第三方代小程序开发,授权事件、消息与事件通知总结
Uboot启动学习笔记之四-uboot之初体验
勤于奋:国外LEAD找任务方法
Deep Learning-深度学习(二)
论文阅读 Dynamic Network Embedding by Modeling Triadic Closure Process
HTML+CSS+JS学习
- 原文地址:https://blog.csdn.net/weixin_42612223/article/details/132724897