-
聚类-kmeans
聚类算法是无监督学习算法,指定将数据分成k个簇。然后通过每个点到各个簇的中心的欧氏距离来分类。
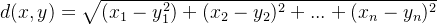
kmeans本身会陷入局部最小值的状况,二分kmeans可以解决这一点。
二分kmeans是遍历所有的簇,将其分成2个,比较哪一个分裂结果更好,用距离和来代表误差
例如现在只有一个簇A,第一轮分裂成A,A1,下一次比较A,A1两个分裂的结果哪个更换,比如A1更好,所以分裂结果为A,A1,A11。
- from __future__ import print_function
- from numpy import *
- # 从文本中构建矩阵,加载文本文件,然后处理
- def loadDataSet(fileName): # 通用函数,用来解析以 tab 键分隔的 floats(浮点数)
- dataSet = []
- fr = open(fileName)
- for line in fr.readlines():
- curLine = line.strip().split('\t')
- fltLine = map(float, curLine) # 映射所有的元素为 float(浮点数)类型
- dataSet.append(fltLine)
- return dataSet
- # 计算两个向量的欧式距离(可根据场景选择)
- def distEclud(vecA,vecB):
- return sqrt(sum(power(vecA-vecB,2))) # la.norm(vecA-vecB)
- # 为给定数据集构建一个包含 k 个随机质心的集合。随机质心必须要在整个数据集的边界之内,这可以通过找到数据集每一维的最小和最大值来完成。然后生成 0~1.0 之间的随机数并通过取值范围和最小值,以便确保随机点在数据的边界之内。
- def randCent(dataMat,k):
- n=shape(dataMat)[1] # 列的数量
- centroids=mat(zeros((k,n))) # 创建k个质心矩阵
- for j in range(n): # 创建随机簇质心,并且在每一维的边界内
- minJ=min(dataMat[:,j]) # 最小值
- rangeJ=float(max(dataMat[:,j])-minJ) # 范围=最大值-最小值
- centroids[:,j]=mat(minJ+rangeJ*random.rand(k,1)) # 随机生成
- return centroids
- # k-means 聚类算法
- # 该算法会创建k个质心,然后将每个点分配到最近的质心,再重新计算质心。
- # 这个过程重复数次,知道数据点的簇分配结果不再改变位置。
- # 运行结果(多次运行结果可能会不一样,可以试试,原因为随机质心的影响,但总的结果是对的, 因为数据足够相似,也可能会陷入局部最小值)
- def KMeans(dataMat,k,distMeas=distEclud,createCent=randCent):
- m=shape(dataMat)[0] # 行数
- clusterAssment=mat(zeros((m,2))) # 创建一个与dataMat 行数一样,但是有两列的矩阵,用来保存簇分配结果
- centroids=createCent(dataMat,k) # 创建质心,随机k个质心
- clusterChanged=True
- while clusterChanged:
- clusterChanged=False
- for i in range(m): # 循环每一个数据点并分配到最近的质心中去
- minDist=inf
- minIndex=-1
- for j in range(k):
- distJI=distMeas(centroids[j,:],dataMat[i,:]) # 计算数据点到质心的距离
- if distJI
- minDist=distJI
- minIndex=j
- if clusterAssment[i,0]!=minIndex: # 簇分配结果改变
- clusterChanged=True #簇改变
- clusterAssment[i,:]=minIndex,minDist**2 #更新簇分配结果为最小质心的index(索引),minDist(最小距离)的平方
- print(centroids)
- for cent in range(k): #更新质心
- ptsInClust=dataMat[nonzero(clusterAssment[:,0].A==cent)[0]] #获取该簇中所有点
- centroids[cent,:]=mean(ptsInClust,axis=0) # 将质心修改为簇中所有点的平均值,mean就是求平均值的
- return centroids,clusterAssment
- # 二分 KMeans 聚类算法, 基于 kMeans 基础之上的优化,以避免陷入局部最小值
- def biKMeans(dataMat,k,distMeas=distEclud):
- m=shape(dataMat)[0]
- clusterAssment=mat(zeros((m,2))) # 保存每个数据点的簇分配结果和平方误差
- centroid0=mean(dataMat,axis=0).tolist()[0] # 质心初始化为所有数据点的均值
- centList=[centroid0] # 初始化只有 1 个质心的 list
- for j in range(m): # 计算所有数据点到初始质心的距离平方误差
- clusterAssment[j,1]=distMeas(mat(centroid0),dataMat[j,:])**2
- while(len(centList)
- lowestSSE=inf
- for i in range(len(centList)): #对每一个质心
- ptsInCurrCluster=dataMat[nonzero(clusterAssment[:,0].A==i)[0],:] # 获取当前簇i下的所有数据点
- centroidMat,splitClustAss=KMeans(ptsInCurrCluster,2,distMeas) # 将当前簇 i 进行二分 kMeans 处理
- sseSplit = sum(splitClustAss[:, 1]) # 将二分 kMeans 结果中的平方和的距离进行求和
- sseNotSplit =sum(clusterAssment[nonzero(clusterAssment[:,0].A!=i)[0],1]) # 将未参与二分 kMeans 分配结果中的平方和的距离进行求和
- print("sseSplit, and notSplit: ", sseSplit, sseNotSplit)
- if (sseSplit + sseNotSplit) < lowestSSE:
- bestCentToSplit = i
- bestNewCents = centroidMat
- bestClustAss = splitClustAss.copy()
- lowestSSE = sseSplit + sseNotSplit
- # 找出最好的簇分配结果
- bestClustAss[nonzero(bestClustAss[:, 0].A == 1)[0], 0] = len(centList) # 调用二分 kMeans 的结果,默认簇是 0,1. 当然也可以改成其它的数字
- bestClustAss[nonzero(bestClustAss[:, 0].A == 0)[0],0] = bestCentToSplit # 更新为最佳质心
- print('the bestCentToSplit is: ', bestCentToSplit)
- print('the len of bestClustAss is: ', len(bestClustAss))
- # 更新质心列表
- centList[bestCentToSplit] = bestNewCents[0, :].tolist()[0] # 更新原质心 list 中的第 i 个质心为使用二分 kMeans 后 bestNewCents 的第一个质心
- centList.append(bestNewCents[1, :].tolist()[0]) # 添加 bestNewCents 的第二个质心
- clusterAssment[nonzero(clusterAssment[:, 0].A == bestCentToSplit)[0], :] = bestClustAss # 重新分配最好簇下的数据(质心)以及SSE
- return mat(centList), clusterAssment
- def testBasicFunc():
- # 加载测试数据集
- dataMat = mat(loadDataSet('data/10.KMeans/testSet.txt'))
- # 测试 randCent() 函数是否正常运行。
- # 首先,先看一下矩阵中的最大值与最小值
- print('min(dataMat[:, 0])=', min(dataMat[:, 0]))
- print('min(dataMat[:, 1])=', min(dataMat[:, 1]))
- print('max(dataMat[:, 1])=', max(dataMat[:, 1]))
- print('max(dataMat[:, 0])=', max(dataMat[:, 0]))
- # 然后看看 randCent() 函数能否生成 min 到 max 之间的值
- print('randCent(dataMat, 2)=', randCent(dataMat, 2))
- # 最后测试一下距离计算方法
- print(' distEclud(dataMat[0], dataMat[1])=', distEclud(dataMat[0], dataMat[1]))
- def testKMeans():
- # 加载测试数据集
- dataMat = mat(loadDataSet('data/10.KMeans/testSet.txt'))
- # 该算法会创建k个质心,然后将每个点分配到最近的质心,再重新计算质心。
- # 这个过程重复数次,知道数据点的簇分配结果不再改变位置。
- # 运行结果(多次运行结果可能会不一样,可以试试,原因为随机质心的影响,但总的结果是对的, 因为数据足够相似)
- myCentroids, clustAssing = KMeans(dataMat, 4)
- print('centroids=', myCentroids)
- def testBiKMeans():
- # 加载测试数据集
- dataMat = mat(loadDataSet('data/10.KMeans/testSet2.txt'))
- centList, myNewAssments = biKMeans(dataMat, 3)
- print('centList=', centList)
- # 测试基础的函数
- testBasicFunc()
- # 测试 kMeans 函数
- testKMeans()
- # 测试二分 biKMeans 函数
- testBiKMeans()
-
相关阅读:
STM32物联网项目-PWM驱动蜂鸣器
PTA 甲级 1039 Course List for Student
c++图像的边缘检测
.NET跨平台框架选择之一 - Avalonia UI
javascript复习之旅 2.3 instanceof
【C++】“334. 队列检查”题目解析及所用vector相关用法总结
Java中的四种内部类
通过 Python 脚本支持 OC 代码重构实践(一):模块调用关系分析
解决GET请求中文乱码问题
Flink中的状态一致性
- 原文地址:https://blog.csdn.net/qq_36973725/article/details/132858569
