-
Set和Map及哈希表介绍
常见集合
Set 和 Map 都是接口;底下有很多实现类;所谓接口就是用来定义规范的;虽然底层实现不同;但是实现这些公共的方法作用是相似效果。

传统查找方式:
1.直接遍历,时间复杂度为O(n),元素如果比较多效率会非常慢
2.二分查找,时间复杂度为 O(log n),但搜索前必须要求序列是有序的上述搜索方式效率低;不适对区间经常进行插入和删除操作的对象查找。相比于元素的查找方式;哈希集合使用的(Key-value的键值对;他是通过计算key的哈希值得到元素位置)
Map接口
Map是一个接口,该接口没有继承自Collection,存储的是

TreeMap和HashMap
共同点:
1:存储键值对:; 两者都用于存储键值对,通过键来检索值;所以我们在使用上区别不大
2: TreeMap 和 HashMap 都实现了 Map 接口,有相似的基本功能,如put、get、remove等。
3: Key不能重复;Value可以重复;key不能修改只能删除然后重新插入区别点:
1:底层实现;HashMap底层使用哈希表;TreeMap底层使用TreeMap。
2:HashMap不能保证元素顺序;TreeMap可以按照键的自然顺序或者自定义顺序进行遍历,Key必须要可比较。
3:HashMap插入和查找都是O(1)。TreeMap;插入和查找复杂度O(log n)。Map的遍历
1:把Key放入set里;然后遍历获取全部value
public static void main(String[] args) { Map<String,Integer> map = new HashMap<>(); map.put("aaa",1); map.put("bbb",2); map.put("ccc",3); Set<String> set = map.keySet(); for (String s : set) { System.out.println(s+" = "+map.get(s)); } }- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
2:使用Enrty然后获取里面的Key
public static void main(String[] args) { Map<String,Integer> map = new HashMap<>(); map.put("aaa",1); map.put("bbb",2); map.put("ccc",3); Set<Map.Entry<String, Integer>> entries = map.entrySet(); for (Map.Entry<String, Integer> entry : entries) { System.out.println(entry.getKey()+" = "+entry.getValue()); } }- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
Set接口

TreeSet和HashSet
共同点
1: TreeSet 和 HashSet 都实现了 Set 接口,因此都具有 Set 接口的基本特性
2: 都不允许集合中包含重复的元素。区别点
1:HashSet;底层使用HashMap。TreeSet底层使用红黑树
2:HashSet不能保证元素顺序;TreeSet可以按照元素的自然顺序或提供的比较器进行排序;Key必须要可比较。
3:HashSet插入、删除、查找时间复杂度O(1);TreeSet插入、删除、查找时间复杂度O(log n)。
Set遍历
1:迭代器
public static void main(String[] args) { Set<Integer> set = new HashSet<>(); set.add(1); set.add(2); set.add(3); Iterator<Integer> it = set.iterator(); while(it.hasNext()) { System.out.print(it.next()+" "); } }- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
2:for each循环
public static void main(String[] args) { Set<Integer> set = new HashSet<>(); set.add(1); set.add(2); set.add(3); for (Integer integer : set) { System.out.print(integer+" "); } }- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
LinkedHashSet
不难发现:使用HashSet和TreeSet不能保证按照我存入元素的顺序去排放我的元素;达到一个去重复效果。
比如:我有一个数组{1, 5 , 7, 9, 7 , 7 , 3};放入HashSet和TreeSet一个不能保证顺序;一个只能保证顺序升序或者降序。但是没法按{1, 5 , 7, 9, 7 , 7 , 3};的顺序放入。可以考虑使用 LinkedHashSet 代替 TreeSet。LinkedHashSet 是一个基于哈希表和链表实现的有序集合,它保留了元素插入的顺序,并且不允许重复元素。import java.util.LinkedHashSet; public class Main { public static void main(String[] args) { int[] array = {1, 5 , 7, 9, 7 , 7 , 3}; LinkedHashSet<Integer> set = new LinkedHashSet<>(); for (int num : array) { set.add(num); } System.out.println(set); // 输出结果:[1, 5, 7, 9, 3] } }- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
Set和Map常用方法使用
注意:set的add方法key重复则添加失败返回false;而map的putkey重复则是覆盖value
import java.sql.Connection; import java.util.*; public class UseHashMap { public static void main(String[] args) { TreeMap<String,Integer> treeMap=new TreeMap<>(); // HashMap- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
import java.util.HashSet; import java.util.Iterator; import java.util.Set; import java.util.TreeSet; public class UseHashSet { public static void main(String[] args) { TreeSet<Integer> set=new TreeSet<>(); // HashSetset=new HashSet<>(); set.add(1); set.add(2); System.out.println(set.contains(1)); Iterator<Integer> iterators=set.iterator(); while (iterators.hasNext()){ System.out.println(iterators.next()); } set.remove(1); set.add(1); set.add(2); System.out.println(set.size()); System.out.println(set.isEmpty()); Object[] objectArray = set.toArray(); int[] intArray = new int[objectArray.length]; for (int i = 0; i < objectArray.length; i++) { intArray[i] = (int) objectArray[i]; } //addAll;将一个实现Collection的接口的集合加入到set中;去重效果 //containsAll;判断实现Collection的接口的集合是否在set全部存在 } }- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
总结:

哈希表底层原理
什么是哈希表
哈希表:理想的搜索方法;不经过任何比较,一次直接从表中得到要搜索的元素。如果构造一种存储结构,通过某种函数hashFunc。使元素的存储位置与它的关键码之间能够建立一一映射的关系,那么在查找时通过该函数可以很快找到该元素。(数组遍历是O(N);二分查找是O(log N);搜索树是O(log N);而哈希表能达到O(1))
插入元素:根据待插入元素的关键码,以此函数计算出该元素的存储位置并按此位置进行存放
搜索元素:对元素的关键码进行同样的计算,把求得的函数值当做元素的存储位置,在结构中按此位置取元素比较,若关键码相等,则搜索成功哈希表是一种数据结构:上述方式为哈希(散列)方法,哈希方法中使用的转换函数称为哈希(散列)函数,构造出来的结构称为哈希表(Hash Table)
例如:数据集合{1,7,6,4,5,9};
哈希函数设置为:hash(key) = key % capacity;capacity为存储元素底层空间总的大小。

什么是哈希冲突
哈希冲突:不同关键字通过相同哈希函数计算出相同的哈希地址,该种现象称为哈希冲突或哈希碰撞。
例如:上面的例子2和12的位置相同(2%10=2;12%10=2)解决哈希冲突-函数设计
当我们试图将大量的数据映射到有限数量的哈希桶时;冲突是必然的;冲突没法解决;只能尽量降低冲突率
降低冲突:哈希函数设计要合理设计;需要以下设计原则
1:哈希函数的定义域必须包括需要存储的全部关键码,而如果散列表允许有m个地址时,其值域必须在0到m-1之间
2:哈希函数计算出来的地址能均匀分布在整个空间中
3:哈希函数应该比较简单
常见的哈希函数:
1.直接定制法–(常用)
取关键字的某个线性函数为散列地址:Hash(Key)= A*Key + B优点:简单、均匀
缺点:需要事先知道关键字的分布情况
使用场景:适合查找比较小且连续的情况面试题:字符串中第一个只出现一次字符
2.除留余数法–(常用)
设散列表中允许的地址数为m,取一个不大于m,但最接近或者等于m的质数p作为除数,按照哈希函数:Hash(key) = key% p(p<=m),将关键码转换成哈希地址解决哈希冲突-负载因子调节

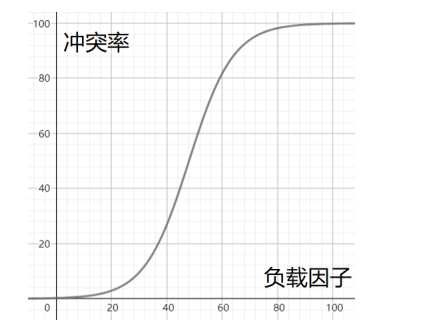
现在知道负载因子的重要性:如何调节负载因子;存的数越来越多,前面的填入表的个数是无法改变的(你不能说不给人家存)只能改变后面的表的长度解决哈希冲突-开放寻址法
开放寻址法:当发生哈希冲突时,如果哈希表未被装满,说明在哈希表中必然还有空位置,那么可以把key存放到冲突位置中的“下一个”空位置中去。那如何寻找下一个空位置呢?
例如:上面举的例子;如果现在需要插入元素44,先通过哈希函数计算哈希地址,下标为4,因此44理论上应该插在该位置,但是该位置已经放了值为4的元素,即发生哈希冲突。我们怎么找下一个空位置?
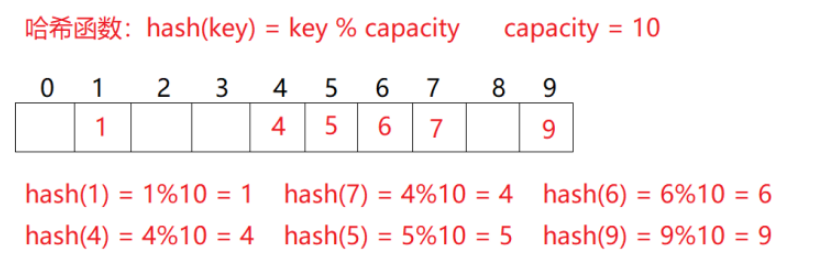
1.线性探测法;
从发生冲突的位置开始,依次向后探测,直到寻找到下一个空位置为止。找到8的位置为空;插入进去。
当我们使用这种方法处理哈希冲突时;不能随便删掉哈希表的已有元素;哪怕不用了也不能随便删除;因为直接删除掉,44查找起来可能会受影响。所以线性探测采用标记的伪删除法来删除一个元素。2.二次探测法;
线性探测的缺陷是产生冲突的数据堆积在一块,这与其找下一个空位置有关系,因为找空位置的方式就是挨着往后逐个去找,因此二次探测为了避免该问题,找下一个空位置的方法为:Hi=(H0+i^2)%m或者Hi=(H0- i ^2)%m;i为1,2,3……(i是第一次冲突,或者第二次冲突等等)
H0是通过散列函数Hash(x)对元素的关键码key进行计算得到的位置;m是表的大小。对于刚才要插入44,产生冲突,使用解决后的情况为:(4+1^2)%10元素个数为质数(质数能比较好降低冲突;避免一些规律性)且负载因子不超过0.5时,新的元素才一定能够插入,而且任何一个位置都不会被探查两次。插入时必须确保表的负载因子a不超过0.5,如果超出必须考虑增容。空间利用率比较低,这也是该方法的缺陷。
解决哈希冲突-链地址法
链地址法:将元素放在桶上;当位置冲突就在这个桶上建一个链表;连接这些冲突元素

总结:采用开放地址法处理哈希冲突的时候,其平均查找长度应当大于链地址法
冲突的地方;这里是一个链表;全部堆积在这里;jdk1.7之前采用头插法;jdk1.8使用尾插法。
这里使用单链表:优点是它相对简单且占用的额外内存较少。每个节点只需存储键、值和下一个节点的引用即可。然而,单链表的缺点是在查找特定键值对时需要遍历整个链表,这可能会导致查找操作的时间复杂度为 O(n),其中 n 是链表的长度。在极端情况下,如果哈希函数选择不当,链表可能会变得非常长,影响性能。哈希表的冲突率是不高的,冲突个数是可控的,也就是每个桶中的链表的长度是一个常数,所以,通常意义下,哈希表的插入/删除/查找时间复杂度是O(1)
哈希Map源码分析
属性
哈希映射(HashMap)的底层通常使用数组和链表(或红黑树)来实现。在 Java 8 及以后的版本中,数组个数大于64&&链表长度大于8,链表会被转换为红黑树,以提高检索性能。

有参构造方法
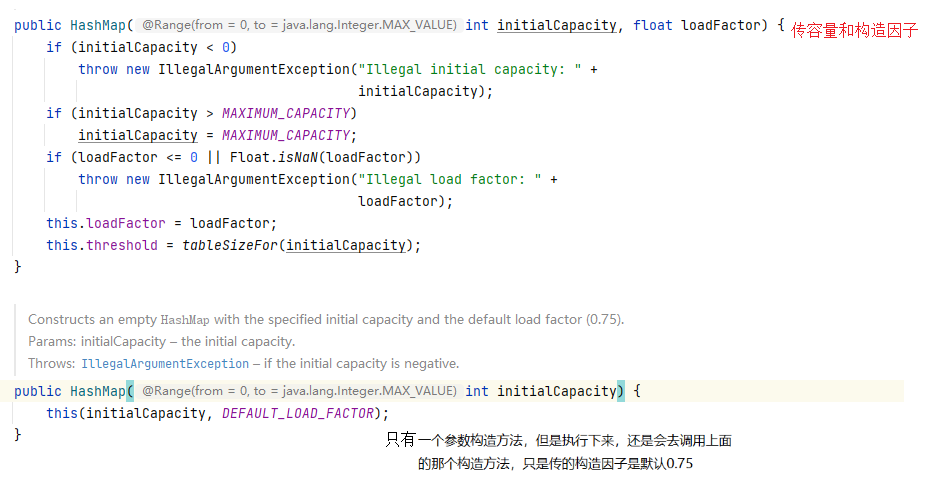

无参构造方法

默认容量是0;但是我们去put却能成功。在putVal(树化的代码也在在里面)完成的(大串代码,调用无参构造方法的时候,第一次pu’t才会开辟内存)
分配的内存是按2的次幂分配:例如你new的是19;实际分配的是32;往大的分;往小16放不下19个

为什么要以2的次方扩容:符号&是按位与的计算,这是位运算,计算机能直接运算,特别高效,按位与&的计算方法是,只有当对应位置的数据都为1时,运算结果也为1。
1:因为扩容之后;哈希表需要对元素重新哈希分配位置;计算新位置的方法是将元素的哈希值与 newLength-1 进行按位与运算。
2:当冲突发生;如果容量不是2的幂次方;使用开放寻址法等解决冲突的方法时,计算下一个可用的槽位会变得复杂。而容量为2的幂次方,可以通过位运算(按位与)来快速定位下一个可用的槽位,简化了冲突处理的过程。
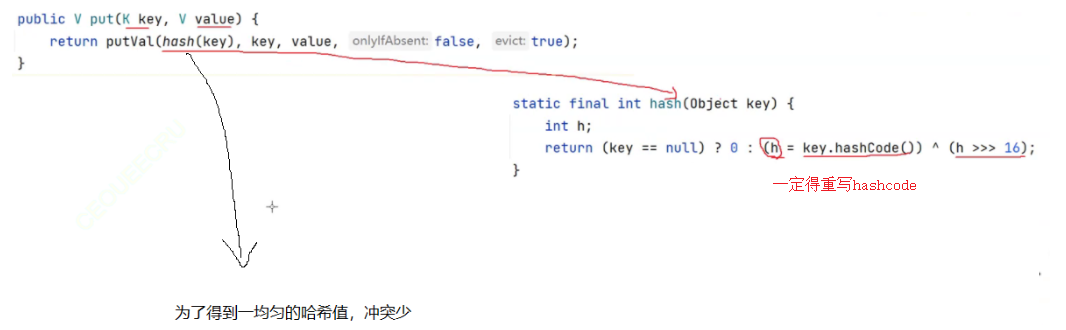
3:哈希表中的元素通过哈希函数被散列到不同的槽位上。当哈希表容量为2的幂次方时,通过位运算限制哈希值的范围,可以使元素在新哈希表中的分布更加均匀。能够通过哈希值的每一位来决定元素的新位置,从而减少了碰撞的可能性。为什么哈希table不能插入null而哈希map可以?
因为场景;哈希table是以用于多线程;哈希map用于单线程。假设我现在获取一个key;得到的结果的null。我不知道到底是插入null;还是根本没有这个key的值。单线程下我可以通过containskey判断这个key是否存在。
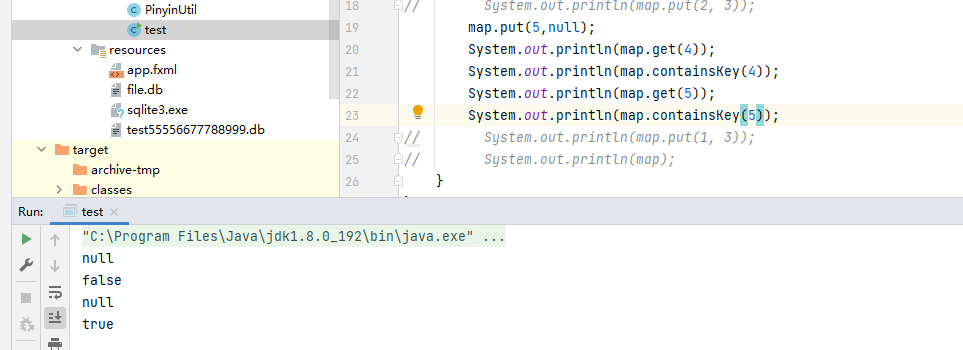
而多线程下:假设你还没有存任何的(key,null);得到的结果应该是false;多线程下:你这个判断containskey执行前;可能有别的线程往这里插入一个(key,null)。这样子判断的结果变成true。 -
相关阅读:
循序渐进介绍基于CommunityToolkit.Mvvm 和HandyControl的WPF应用端开发(2)
IDEA settings设置技巧,最常用快捷键,让你的编译器用更加得心应手
K8S安装过程二:安装Keepalived服务
探究ChatGPT与GPT-4的缺陷不足,揭示大预言LLM模型的局限性——没有完美的工具
工业互联网数据监测预警解决方案
高效的开发流程搭建,kaggle提交流程示范
【C++】超详细入门——lambda表达式
W801学习笔记十四:掌机系统——菜单——尝试打造自己的UI
苏嘉杭高速公路收费站升级改造(苏州地区)配电室综合监控系统的设计与应用
【广州华锐互动】人造卫星VR互动科普软件带你探索宇宙世界
- 原文地址:https://blog.csdn.net/m0_64254651/article/details/132760186
