-
Python爬虫基础(二):使用xpath与jsonpath解析爬取的数据
系列文章索引
Python爬虫基础(一):urllib库的使用详解
Python爬虫基础(二):使用xpath与jsonpath解析爬取的数据
Python爬虫基础(三):使用Selenium动态加载网页
Python爬虫基础(四):使用更方便的requests库
Python爬虫基础(五):使用scrapy框架一、使用xpath解析html文件
1、浏览器安装xpath-healper
(1)谷歌浏览器安装(需要科学上网)
打开浏览器,添加扩展程序(谷歌浏览器需要科学上网,其他浏览器不需要):
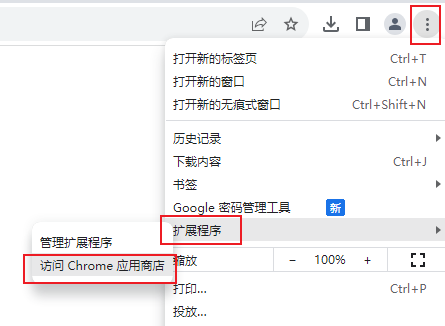
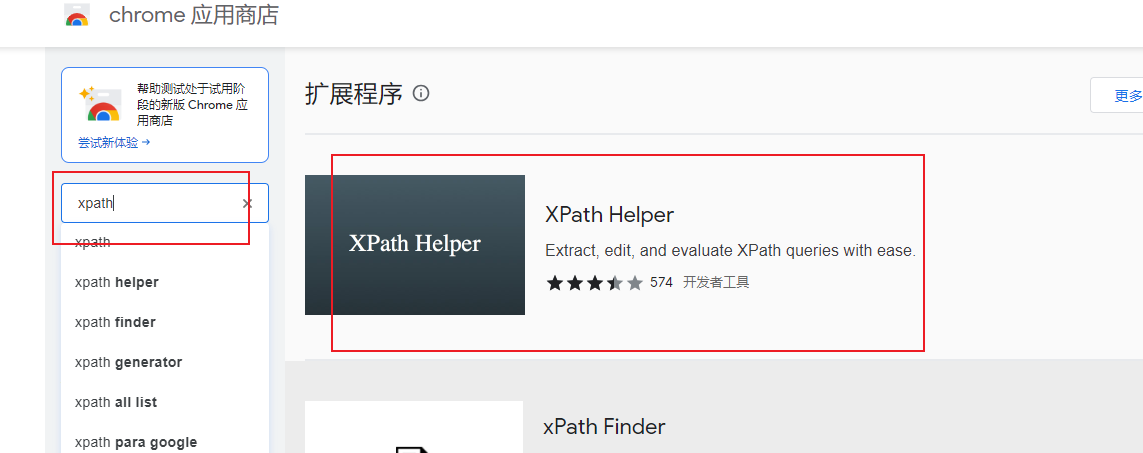
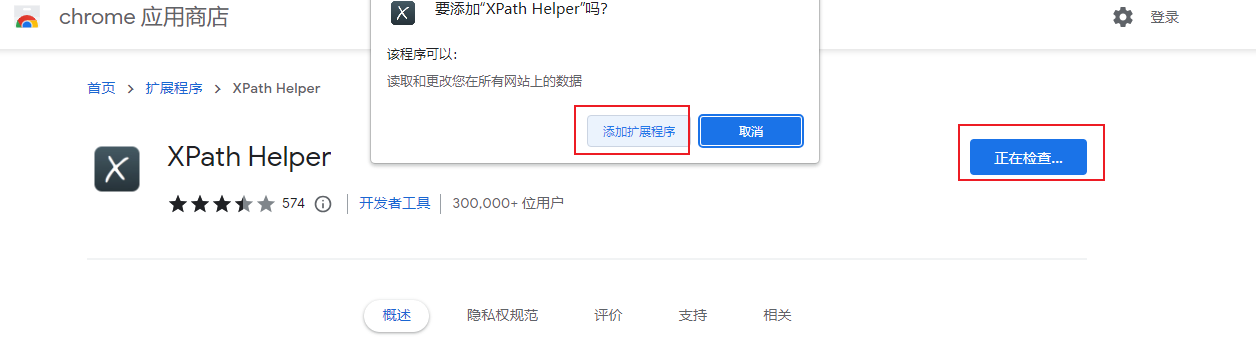
(2)验证
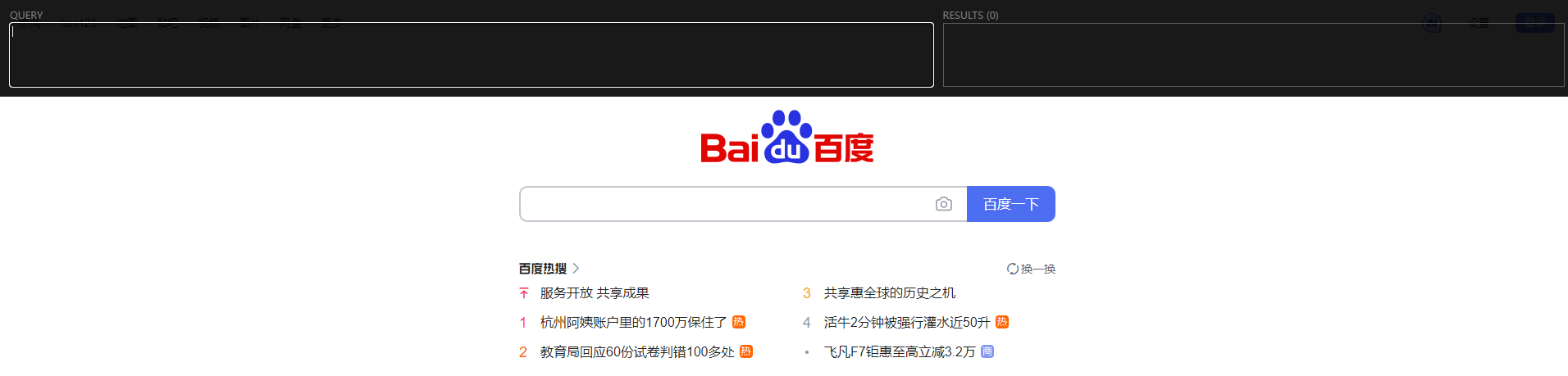
按下ctrl+shift+x,在浏览器上方出现小黑框,则说明安装成功了(没出来的话重启浏览器尝试一下)。
(3)使用文件安装(不需科学上网)
下载文件:https://download.csdn.net/download/A_art_xiang/88305675
下载之后,解压压缩包。
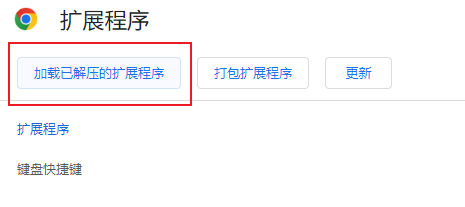
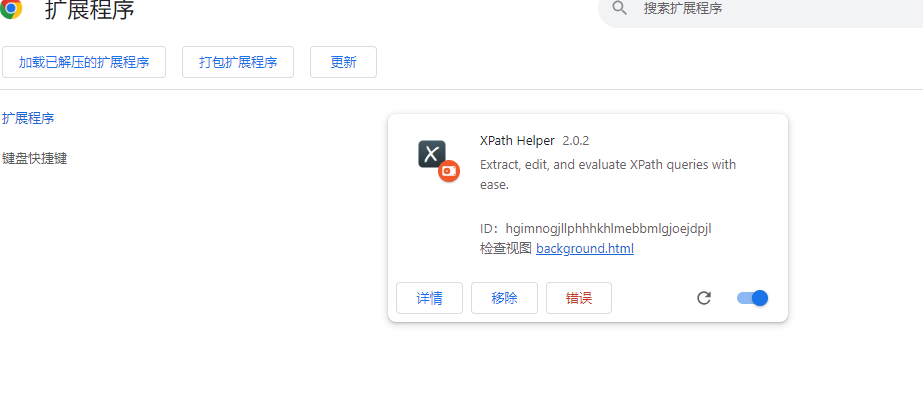
在谷歌浏览器中,管理扩展程序,打开开发者模式,点击加载已解压的扩展程序,选择解压后的文件夹,添加即可。
2、安装lxml库
# 进入到python安装目录的Scripts目录 d: cd D:\python\Scripts # 安装lxml库 pip install lxml -i https://pypi.douban.com/simple # 如果有报错的话,可以根据提示更新一下pip(一定要退出当前目录cd .. 不然安装失败) # python.exe -m pip install --upgrade pip- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
3、xpath基本语法
1.路径查询
//:查找所有子孙节点,不考虑层级关系
/ :找直接子节点2.谓词查询
//div[@id]
//div[@id=“maincontent”]3.属性查询
//@class
//@value4.模糊查询
//div[contains(@id, “he”)]
//div[starts‐with(@id, “he”)]5.内容查询
//div/h1/text()6.逻辑运算
//div[@id=“head” and @class=“s_down”]
//title | //price4、xpath解析本地文件实例
准备一个html测试文件:
DOCTYPE html> <html lang="en"> <head> <meta charset="UTF-8"/> <title>Titletitle> head> <body> <ul> <li id="l1" class="c1">北京li> <li id="l2">上海li> <li id="c3">深圳li> <li id="c4">武汉li> ul> <ul> <li>大连li> <li>锦州li> <li>沈阳li> ul> body> html>- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
from lxml import etree # xpath解析 # xpath解析本地文件,使用parse方法 tree = etree.parse('index.html') #tree.xpath('xpath路径') # 1.路径查询 # 查找ul下面的li (7个数据) li_list = tree.xpath('//body/ul/li') # 2.谓词查询 # 查找所有有id的属性的li标签 # text()获取标签中的内容 (结果:['北京', '上海', '深圳', '武汉']) li_list = tree.xpath('//ul/li[@id]/text()') # 找到id为l1的li标签 注意引号的问题 (结果:['北京']) li_list = tree.xpath('//ul/li[@id="l1"]/text()') # 3.属性查询 # 查找到id为l1的li标签的class的属性值 (结果:['c1']) li_list = tree.xpath('//ul/li[@id="l1"]/@class') # 4.模糊查询 # 查询id中包含l的li标签 (结果:['北京', '上海']) li_list = tree.xpath('//ul/li[contains(@id,"l")]/text()') # 查询id的值以l开头的li标签(结果:['深圳', '武汉']) li_list = tree.xpath('//ul/li[starts-with(@id,"c")]/text()') # 6.逻辑运算 #查询id为l1和class为c1的(结果:['北京']) li_list = tree.xpath('//ul/li[@id="l1" and @class="c1"]/text()') # 查询id为l1的内容和id为l2的内容 (结果:['北京', '上海']) li_list = tree.xpath('//ul/li[@id="l1"]/text() | //ul/li[@id="l2"]/text()') print(li_list) # 判断列表的长度 print(len(li_list))- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
5、实战:获取小说的标题与内容
我们查找到该小说的标题所在的标签:
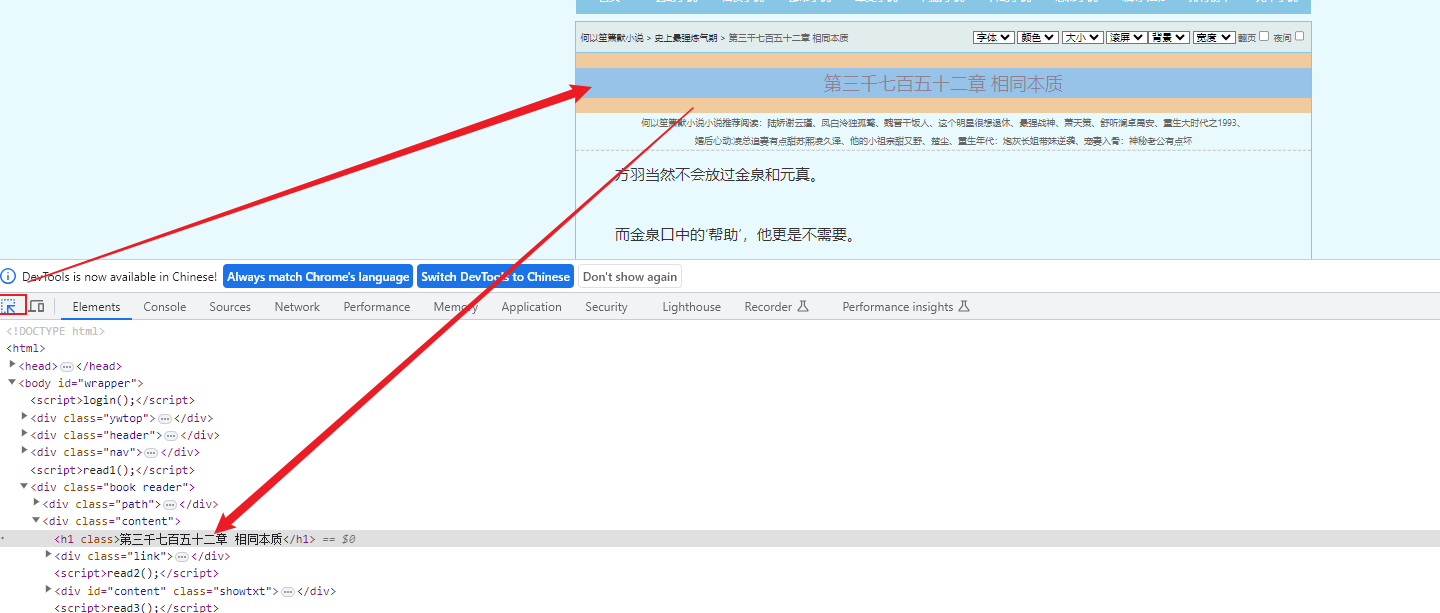
使用ctrl+shift+x打开我们之前安装的xpath-helper,可以进行验证:

同理,获取小说的内容。
编写代码,获取小说章节的标题与内容:
# (1) 获取网页的源码 # (2) 解析 解析的服务器响应的文件 etree.HTML # (3) 打印 import urllib.request # 获取小说文章 url = 'http://www.yetianlian.cc/yt4017/29601238.html' headers = { 'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/92.0.4515.159 Safari/537.36' } # 请求对象的定制 request = urllib.request.Request(url = url,headers = headers) # 模拟浏览器访问服务器 response = urllib.request.urlopen(request) # 获取网页源码 content = response.read().decode('utf-8') # 解析网页源码 来获取我们想要的数据 from lxml import etree # 解析服务器响应的文件 使用HTML方法 tree = etree.HTML(content) # 获取想要的数据 xpath的返回值是一个列表类型的数据 # 获取小说的标题 result = tree.xpath('//div[@class="content"]/h1/text()')[0] print(result) # 获取小说的内容 result = tree.xpath('//div[@id="content"]/text()') # 遍历内容 for res in result: print(res)- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
6、实战:下载站长素材图片

# (1) 请求对象的定制 # (2)获取网页的源码 # (3)下载 # 需求 下载的前十页的图片 import urllib.request from lxml import etree def create_request(page): if(page == 1): url = 'https://sc.chinaz.com/tupian/fengjing.html' else: url = 'https://sc.chinaz.com/tupian/fengjing_' + str(page) + '.html' headers = { 'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/92.0.4515.159 Safari/537.36', } request = urllib.request.Request(url = url, headers = headers) return request def get_content(request): response = urllib.request.urlopen(request) content = response.read().decode('utf-8') return content def down_load(content): # 下载图片 # urllib.request.urlretrieve('图片地址','文件的名字') tree = etree.HTML(content) # 获取图片的alt属性,作为图片名 name_list = tree.xpath('//div[@class="item"]/img/@alt') # 一般设计图片的网站都会进行懒加载 # 取src有可能取不到,可以取data-original,作为图片地址 src_list = tree.xpath('//div[@class="item"]/img/@data-original') # 判断目录是否存在 import os dir_path = './images/' # 使用os模块的`path.exists()`方法来检查目录是否存在 if not os.path.exists(dir_path): # 如果目录不存在,则使用os模块的`mkdir()`方法创建目录 os.mkdir(dir_path) for i in range(len(name_list)): name = name_list[i] src = src_list[i] url = 'https:' + src # 将图片保存到本地,需要手动创建images目录 urllib.request.urlretrieve(url=url,filename=dir_path + name + '.jpg') if __name__ == '__main__': start_page = int(input('请输入起始页码')) end_page = int(input('请输入结束页码')) for page in range(start_page,end_page+1): # (1) 请求对象的定制 request = create_request(page) # (2)获取网页的源码 content = get_content(request) # (3)下载 down_load(content)- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 61
- 62
- 63
- 64
- 65
- 66
- 67
二、使用JsonPath解析json本地文件
1、JsonPath基本介绍
JsonPath只能解析json文件,而不是像xpath既可以解析文件,也可以直接解析字符串。
所以说,想要使用JsonPath解析JSON,只能将爬取的json数据保存到本地之后,才能进行解析。
JsonPath用起来与xpath类似,也需要使用其特定的语法,以下是JSONPath语法元素和对应XPath元素的对比:
XPath JSONPath Description / $ 表示根元素 . @ 当前元素 / . or [] 子元素 … n/a 父元素 // … 递归下降,JSONPath是从E4X借鉴的。 * * 通配符,表示所有的元素 @ n/a 属性访问字符 [] [] 子元素操作符 | [,] 连接操作符在XPath 结果合并其它结点集合。JSONP允许name或者数组索引。 n/a [start:end :step] 数组分割操作从ES4借鉴。 [] ?() 应用过滤表示式 n/a () 脚本表达式,使用在脚本引擎下面。 () n/a Xpath分组 2、安装JsonPath
d: cd D:\python\Scripts # 安装 pip install jsonpath -i https://pypi.douban.com/simple- 1
- 2
- 3
- 4
3、使用实例
{ "store": { "book": [ { "category": "修真", "author": "六道", "title": "坏蛋是怎样练成的", "price": 8.95 }, { "category": "修真", "author": "天蚕土豆", "title": "斗破苍穹", "price": 12.99 }, { "category": "修真", "author": "唐家三少", "title": "斗罗大陆", "isbn": "0-553-21311-3", "price": 8.99 }, { "category": "修真", "author": "南派三叔", "title": "星辰变", "isbn": "0-395-19395-8", "price": 22.99 } ], "bicycle": { "author": "老马", "color": "黑色", "price": 19.95 } } }- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
import json import jsonpath # 总体分两步:加载、解析 # obj = json.load(open('json文件', 'r', encoding='utf‐8')) # ret = jsonpath.jsonpath(obj, 'jsonpath语法') obj = json.load(open('_jsonpath.json','r',encoding='utf-8')) # 书店所有书的作者 # author_list = jsonpath.jsonpath(obj,'$.store.book[*].author') # print(author_list) # 所有的作者 # author_list = jsonpath.jsonpath(obj,'$..author') # print(author_list) # store下面的所有的元素 # tag_list = jsonpath.jsonpath(obj,'$.store.*') # print(tag_list) # store里面所有东西的price # price_list = jsonpath.jsonpath(obj,'$.store..price') # print(price_list) # 第三个书 # book = jsonpath.jsonpath(obj,'$..book[2]') # print(book) # 最后一本书 # book = jsonpath.jsonpath(obj,'$..book[(@.length-1)]') # print(book) # 前面的两本书 # book_list = jsonpath.jsonpath(obj,'$..book[0,1]') # book_list = jsonpath.jsonpath(obj,'$..book[:2]') # print(book_list) # 条件过滤需要在()的前面添加一个? # 过滤出所有的包含isbn的书。 # book_list = jsonpath.jsonpath(obj,'$..book[?(@.isbn)]') # print(book_list) # 哪本书超过了10块钱 book_list = jsonpath.jsonpath(obj,'$..book[?(@.price>10)]') print(book_list)- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
4、实战:解析淘票票下所有区域列表
鼠标移到地址的位置之后,会调用一个post请求,获取全国所有的地址。
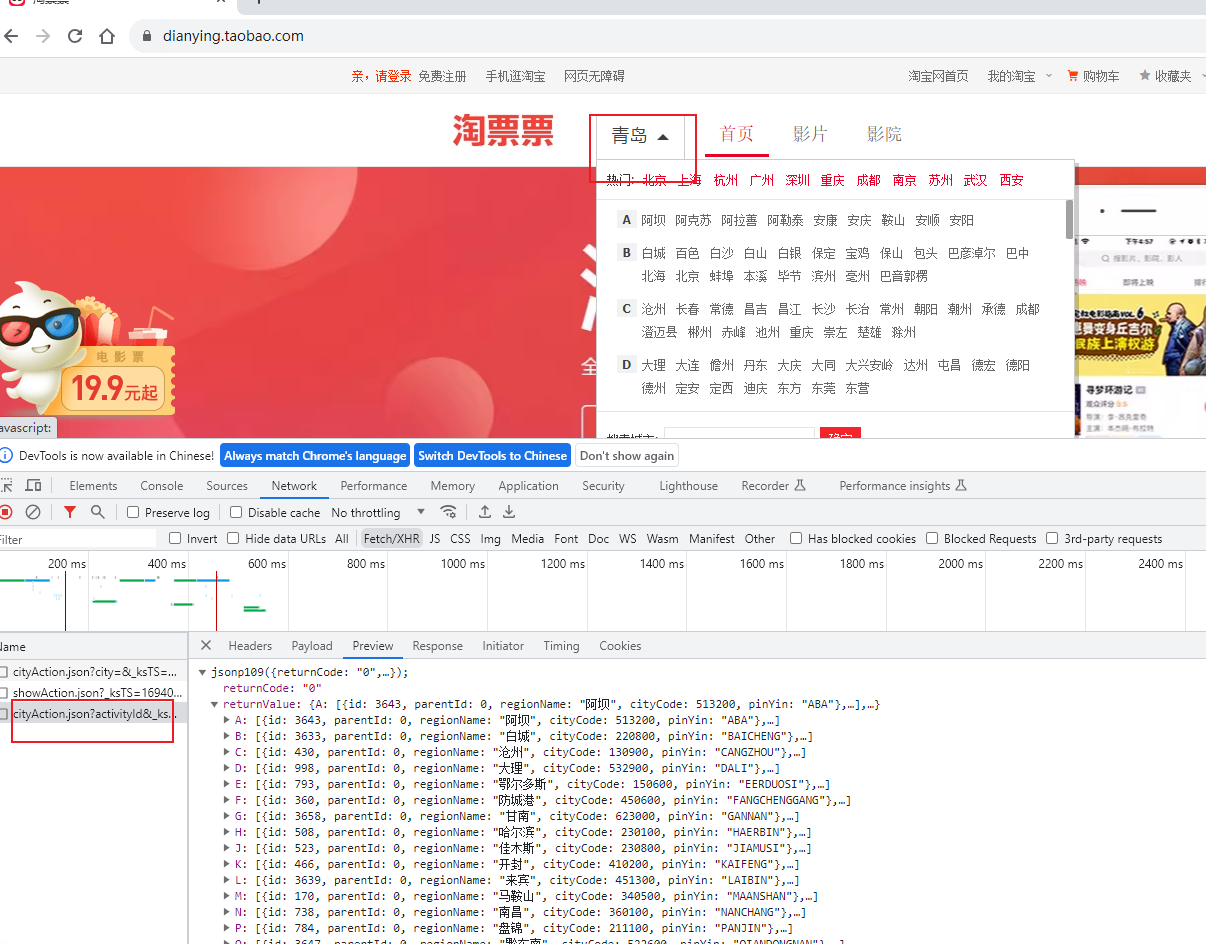
因为JsonPath只能解析本地文件,不能直接解析字符串,我们还需要将json存放到本地,才能解析。但是这个接口的返回信息,并不是一个json数据,所以需要进行特殊处理。
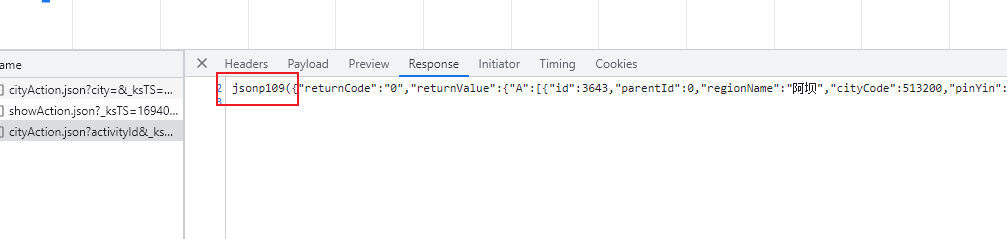
import urllib.request url = 'https://dianying.taobao.com/cityAction.json?activityId&_ksTS=1629789477003_137&jsoncallback=jsonp138&action=cityAction&n_s=new&event_submit_doGetAllRegion=true' headers = { 'referer': 'https://dianying.taobao.com/', } request = urllib.request.Request(url = url, headers = headers) response = urllib.request.urlopen(request) content = response.read().decode('utf-8') # split 切割,对结果进行处理,获取最终的json content = content.split('(')[1].split(')')[0] with open('tpp.json','w',encoding='utf-8')as fp: fp.write(content) import json import jsonpath obj = json.load(open('tpp.json','r',encoding='utf-8')) # 获取所有的城市中文名 city_list = jsonpath.jsonpath(obj,'$..regionName') print(city_list)- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
三、使用BeautifulSoup解析html文件
1、基本介绍
1.BeautifulSoup简称:
bs42.什么是BeatifulSoup?
BeautifulSoup,和lxml一样,是一个html的解析器,主要功能也是解析和提取数据3.优缺点?
缺点:效率没有lxml的效率高
优点:接口设计人性化,使用方便2、安装BeautifulSoup
d: cd D:\python\Scripts # 安装 pip install bs4 -i https://pypi.douban.com/simple- 1
- 2
- 3
- 4
3、基本使用
服务器响应的文件生成对象:
soup = BeautifulSoup(response.read().decode(), ‘lxml’)本地文件生成对象:
soup = BeautifulSoup(open(‘1.html’), ‘lxml’)
注意:默认打开文件的编码格式gbk所以需要指定打开编码格式1.根据标签名查找节点
soup.a 【注】只能找到第一个a
soup.a.name
soup.a.attrs2.函数
(1).find(返回一个对象)
find(‘a’):只找到第一个a标签
find(‘a’, title=‘名字’)
find(‘a’, class_=‘名字’)(2).find_all(返回一个列表)
find_all(‘a’) 查找到所有的a
find_all([‘a’, ‘span’]) 返回所有的a和span
find_all(‘a’, limit=2) 只找前两个a(3).select(根据选择器得到节点对象)【推荐】
1.element
eg:p
2…class
eg:.firstname
3.#id
eg:#firstname
4.属性选择器
[attribute]
eg:li = soup.select(‘li[class]’)
[attribute=value]
eg:li = soup.select(‘li[class=“hengheng1”]’)
5.层级选择器
element element
div p
element>element
div>p
element,element
div,p
eg:soup = soup.select(‘a,span’)4、使用实例
本地html文件:
DOCTYPE html> <html lang="en"> <head> <meta charset="UTF-8"> <title>Titletitle> head> <body> <div> <ul> <li id="l1">张三li> <li id="l2" class="a1">李四li> <li>王五li> <a href="" id="" class="a1">腾讯a> <span>嘿嘿嘿span> ul> div> <a href="" title="a2">百度a> <div id="d1"> <span> 哈哈哈 span> div> <p id="p1" class="p1">呵呵呵p> body> html>- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
from bs4 import BeautifulSoup # 通过解析本地文件 来将bs4的基础语法进行讲解 # 默认打开的文件的编码格式是gbk 所以在打开文件的时候需要指定编码 soup = BeautifulSoup(open('075_尚硅谷_爬虫_解析_bs4的基本使用.html',encoding='utf-8'),'lxml') # 根据标签名查找节点 # 找到的是第一个符合条件的数据,查找第一个a标签 结果:腾讯 print(soup.a) # 获取标签的属性和属性值 结果:{'href': '', 'id': '', 'class': ['a1']} print(soup.a.attrs) # bs4的一些函数 # (1)find # 返回的是第一个符合条件的数据 结果:腾讯 print(soup.find('a')) # 根据title的值来找到对应的标签对象 结果:百度 print(soup.find('a',title="a2")) # 根据class的值来找到对应的标签对象 注意的是class需要添加下划线 结果:腾讯 print(soup.find('a',class_="a1")) # (2)find_all # 返回的是一个列表 并且返回了所有的a标签 结果:[腾讯, 百度] print(soup.find_all('a')) # 如果想获取的是多个标签的数据 那么需要在find_all的参数中添加的是列表的数据 # 结果:a和span都返回了,是一个列表 print(soup.find_all(['a','span'])) # limit的作用是查找前几个数据 print(soup.find_all('li',limit=2)) # (3)select(推荐) # select方法返回的是一个列表 并且会返回多个数据 # 结果:返回所有的a标签 print(soup.select('a')) # 可以通过.代表class 我们把这种操作叫做类选择器 # 选择所有class为a1的标签 print(soup.select('.a1')) # 选择id为l1的标签 print(soup.select('#l1')) # 属性选择器---通过属性来寻找对应的标签 # 查找到li标签中有id的标签 print(soup.select('li[id]')) # 查找到li标签中id为l2的标签 print(soup.select('li[id="l2"]')) # 层级选择器 # 后代选择器 # 找到的是div下面的li,不限层级 print(soup.select('div li')) # 子代选择器 # 某标签的第一级子标签,注意是第一个子级 # 注意:很多的计算机编程语言中 如果不加空格不会输出内容 但是在bs4中 不会报错 会显示内容 print(soup.select('div > ul > li')) # 找到a标签和li标签的所有的对象,相当于find_all print(soup.select('a,li')) # 获取节点信息 # 获取节点内容 obj = soup.select('#d1')[0] # 如果标签对象中 只有内容 那么string和get_text()都可以使用 # 如果标签对象中 除了内容还有标签 那么string就获取不到数据 而get_text()是可以获取数据 # 我们一般情况下 推荐使用get_text() print(obj.string) # 获取标签的内容 print(obj.get_text()) # 节点的属性 obj = soup.select('#p1')[0] # name是标签的名字 : p print(obj.name) # 将属性值作为一个字典返回 结果:{'id': 'p1', 'class': ['p1']} print(obj.attrs) # 获取节点的属性 obj = soup.select('#p1')[0] # 获取class属性,结果:p1 print(obj.attrs.get('class')) # 也可以获取class属性,结果:p1 print(obj.get('class')) # 同样可以获取class属性 print(obj['class'])- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 61
- 62
- 63
- 64
- 65
- 66
- 67
- 68
- 69
- 70
- 71
- 72
- 73
- 74
- 75
- 76
- 77
- 78
- 79
- 80
- 81
- 82
- 83
- 84
- 85
- 86
- 87
- 88
- 89
- 90
- 91
- 92
- 93
- 94
5、实战:获取星巴克中产品名
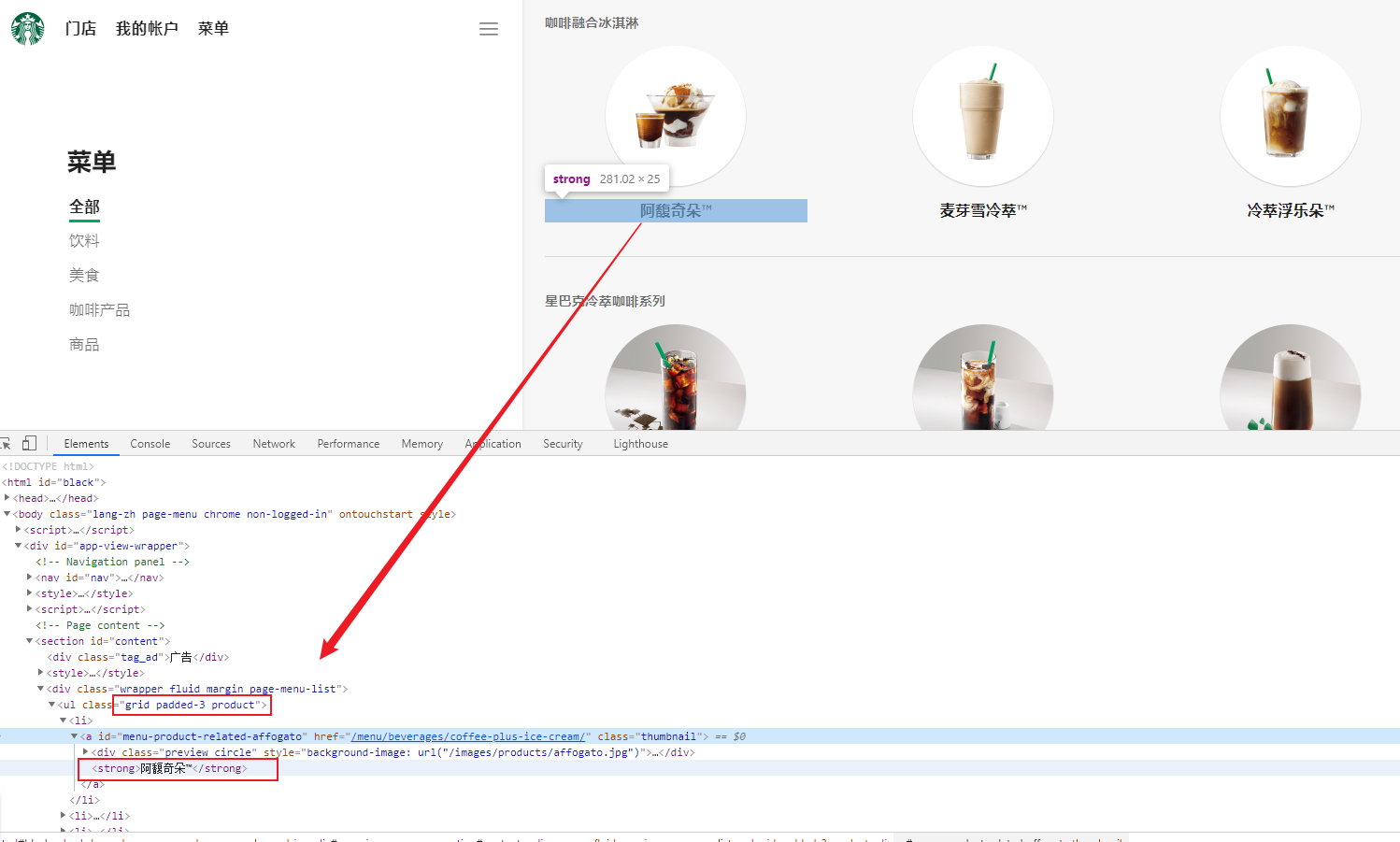
import urllib.request url = 'https://www.starbucks.com.cn/menu/' response = urllib.request.urlopen(url) content = response.read().decode('utf-8') from bs4 import BeautifulSoup soup = BeautifulSoup(content,'lxml') # 用xpath的话,就是://ul[@class="grid padded-3 product"]//strong/text() name_list = soup.select('ul[class="grid padded-3 product"] strong') for name in name_list: print(name.get_text())- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
-
相关阅读:
Python也可以实现Excel中的“Vlookup”函数
STM32创建工程步骤
聊一下Glove
Himall商城Web帮助类获得请求客户端的操作系统名称、判断是否是浏览器请求、是否是移动设备请求、判断是否是搜索引擎爬虫请求
元数据简析:定义及管理
响应10毫米内的请求如何处理
Python实战:读取MATLAB文件数据(.mat文件)
spring-初识spring
自动从Android上拉取指定文件
腾讯云轻量数据库测评和轻量数据库配置价格表
- 原文地址:https://blog.csdn.net/A_art_xiang/article/details/132708736
