-
大数据课程L7——网站流量项目的操作步骤
文章作者邮箱:yugongshiye@sina.cn 地址:广东惠州
▲ 本章节目的
⚪ 了解网站流量项目的Spark与HBase整合;
⚪ 掌握网站流量项目的实时流业务处理;
一、 Spark 与 HBase 整合基础
1. 实现步骤:
1. 启动 IDEA。
2. 创建 Maven 工程,骨架选择 quickstart 。
3. IDEA 安装 Scala 插件。
file —> settings —> plugins
搜素 Scala 插件,安装即可,安装完成后重启。
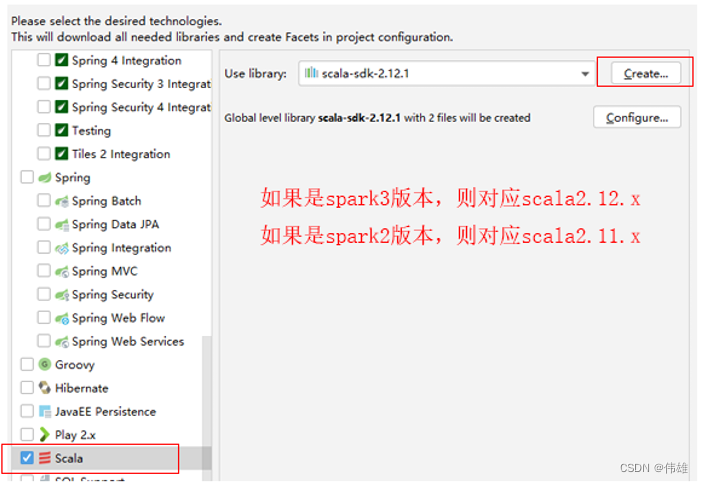
4. 为 fluxStreamingServer 工程添加 Scala sdk 。
工程上右键 —> add framework suppor
5. 创建一个 Scala 目录,使其成为 source root 。
6. 引入工程 pom,详见笔记。
7. 学习 Spark 与 HBase 整合基础。
8. 确定一下 Windows hosts 文件主机名与 ip 的映射是否正确。
9. 启动服务器。
10. 启动三台 zookeeper 集群。
11. 启动 Hadoop 。
12. 启动 HBase,进入01服务器 HBase 的 bin 目录, 执行如下指令:
sh start-hbase.sh
13. 执行如下指令进入 hbase客户端,建表。
sh hbase shell
二、实时流业务处理
1. 实现步骤:
1. 启动三台服务器。
2. 启动 zookeeper 集群。
3. 启动 Hadoop 。
4. 启动 Kafka 集群 。
5. 启动 flume 。
6. 整合 SparkStreaming 与 Kafka,完成代码编写。
7. 启动 SparkStreaming 。
8. 启动 tomcat,访问埋点服务器,测试 SparkStreaming 是否能够收到数据。
9. 启动 HBase。

-
相关阅读:
Python深度学习:融合网络 | LSTM网络和ResNet网络融合 | 含随机生成的训练数据集
vue中实现签名画板
Generative Adversarial Nets
MYSQL下载及安装完整教程
【Kubernetes】资源指标管道——部署Metrics Server
论文参考文献的引入要留意什么信息呢?
【教学类-12-03】20221106《连连看横版8*4(2套题目 适合中班))(中班主题《我们的城市》)
7、系统管理
mysql 连接不上,start the server错误,服务启动停止,怎么都连不上。
java“俄罗斯方块”
- 原文地址:https://blog.csdn.net/u013955758/article/details/132818716