-
LIO-SAM论文与代码总结
看了一些注释版的代码和博客,很多都很详细,但是有的看起来比较绕,或者对一些名词和定义的解释有歧义,不一定就说错了,但是仍然不方便自己理解,所以自己梳理一下,顺便记录。
目录
原文附带架构图
比起舍近求远去分析,还是多看看原版github的说明更合适。

没太多能赘述的,相比代码里绕圈,这个图的主线逻辑很清晰。唯一能介绍的就是有两个优化器,一个是后端优化,一个是imu优化。
消息流:

主线点云消息流:
cloud_info:串起原始点云到特征提取到最终激光里程计。

imu系:

imu_raw:imu原始数据,有两个接收点,一个是imu预积分用来预测位姿;另一个是点云去畸变,因为点云的时间密集度是激光里程计频率跟不上的,所以需要原始imu来预测姿态(这频率也不够,还有插值)。
/odometry/imu_incremental(odomTopic + "_incremental" 前缀可改):产生自imu预积分模块,是imu预积分推测的imu里程计,接收是TransformFusion模块,利用imu预积分结果作为高频增量(基准还是后端激光里程计)。
imu比较绕的点:
1.imu消息队列内部分opt和queue,其实这俩对立统一,一个是用来低频优化(以激光里程计频率为准),一个是用来高频预测(以imu频率为准),
2.imu预积分模块发出去的imu_incremental,又被同节点的fusion模块接到了。两个模块还都要接后端里程计,为什么不一次搞定?我个人的理解,两个模块接收的消息不完全一致,相似却不同,imu预积分接收的信息是后端优化后先融合了imu再推回来的,fusion模块接收的是纯的后端优化结果。两个模块为了达成不同目的,imu预积分模块可能希望这个位姿和imu本身的数据更相似,融合改变小一点,而fusion模块纯粹为了基于最精准的最新后端位姿去发布新的位姿。(只是个人想法)
激光里程计:
lio_sam/mapping/odometry_incremental:后端优化后的激光里程计,发布之前还融合过cloudInfo附带的原始imu,接收端imu预积分模块,用来融合优化imu,然后做imu预积分。
lio_sam/mapping/odometry:后端的激光里程计,接收端transformfusion基于此做高频推测,和_incremental的区别?区别是这里没加权融合过imu。两者区别imu那里提过一次
闭环因子:
gps和闭环因子,用来做因子图优化,属于可选数据
杂(可视化):
lio_sam/mapping/map_local:附近的所有关键帧的位姿(但是用点云形式存)
lio_sam/mapping/cloud_registered:当前帧的降采样的特征点
lio_sam/mapping/cloud_registered_raw:去畸变的点云cloudInfo.cloud_deskewed,基于优化后的位姿,转到世界坐标系。
lio_sam/mapping/path:全局轨迹,或者叫trajectory
lio_sam/imu/path:同样是轨迹,但是transformfution推测的局部path,起点是上一帧激光里程计。
名词解释:imu_incremental,imu里程计,就是位姿,“增量”不是增加的量——或者常说的diff或者δ,增量其实指的就是一种能累加的量。同理,odometry_incremental也都是累加变化的位姿。
优化器:
二处使用:imu预积分模块融合后端里程计,激光里程计与闭环优化。
坐标系和TF:
map是地图坐标系,固定,odom不动,和map一致,移动的是baselink,lidar_link和base_link不是依附关系。
TF
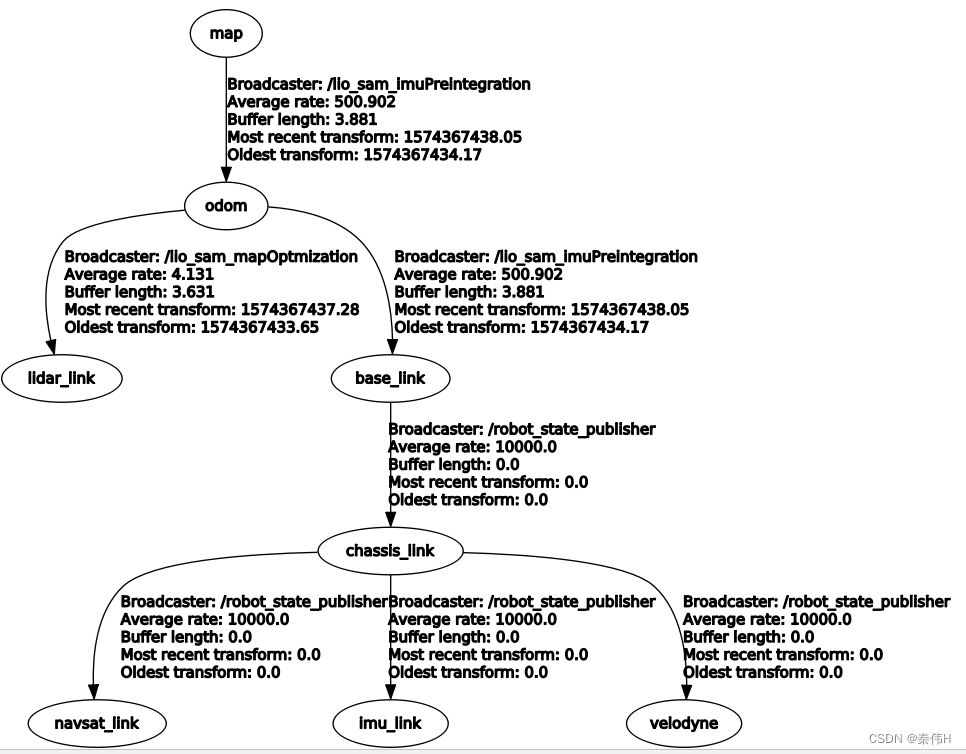
base_link:主要移动机构,数据来源是imu里程计,后端数据+积分推测,高频实时。
lidar_link:跟随base_link,数据来源是后端优化,更精准,与base_link没有刚性连接,相对位置跳变与滞后,比base_link,低频精准。
四大天王——5个源文件解读
工程一共1个yaml配置文件、1个头文件utility.h,4个cpp文件,1个头文件是定义公共的参数读取功能和坐标系变换,4个cpp都继承了这个头文件,每个cpp都是一个单独的node节点。
下面说一下4个cpp文件,希望能抽丝剥茧,把命名上的“绕”解开。
imageProjection.cpp
“入口”节点,说是入口,主要是lidar第一步要进入这里,至于imu,会复杂一些。

订阅输入:imu原始数据、imu“里程计”(预积分得到)、原始点云
发布输出:主线数据cloud_info(用来提取特征点)、去畸变点云(rviz展示用)
3个订阅,只有一个值得说,imu和odom(没有真里程计,所以odom一般指imu或者激光里程计)订阅都是push到queue,没做逻辑触发,cloudHandler()是做逻辑触发的,主要逻辑和func都在这里
- void cloudHandler(const sensor_msgs::PointCloud2ConstPtr &laserCloudMsg)
- {
- if (!cachePointCloud(laserCloudMsg))
- return;
- if (!deskewInfo())
- return;
- projectPointCloud();
- cloudExtraction();
- publishClouds();
- resetParameters();
- }
cachePointCloud:一些关于厂商消息格式的判断和转换,保持cloudQueue至少有两帧点云再处理这个逻辑没看到任何作用(return一次会延后对数据的处理)
deskewInfo:确认有imu数据才能去畸变,只要有原始imu就算通过,odom算锦上添花不影响逻辑进行。这里边有利用imu的姿态预计算。
projectPointCloud:点云去运动畸变,用原始imu数据去除旋转畸变,odom去除移动畸变(慢速直接就不做处理)
cloudExtraction:叫extraction或者叫filter都行,主要就是处理边缘,因为每个点的曲率需要周边10个点,所以首尾5个点没用。
publishClouds:里边嵌套了一个发布publishCloud,子消息是给rviz看的,母消息cloud_info是主要数据,往下走流程。
resetParameters:重置所以只针对当前点云的临时数据。
重点:
imu原始消息和点云消息的“对齐”,首尾对齐直接是按时间戳找,中间的数据怎么对齐?因为点云和imu不是一个数量级!首先,所有imu利用惯性递推预计算出姿态和时间,然后,去畸变的时候deskewPoint()会去查询,找到当前点云时间上前后两个姿态数据,根据时间的远近做一个线性插值。
其他细节暂时不太需要说
featureExtraction.cpp
可能是最简单的node!

订阅输入:主线消息cloud_info
发布输出:(加了特征点的)主线数据cloud_info、单独的角点和平面点(rviz用)
initializationValue():值得说的是,点云的数据预设会影响这里容器的预留,多少线,每线多少点,需要用到。
laserCloudInfoHandler():
- void laserCloudInfoHandler(const lio_sam::cloud_infoConstPtr &msgIn)
- {
- cloudInfo = *msgIn; // new cloud info
- cloudHeader = msgIn->header; // new cloud header
- pcl::fromROSMsg(msgIn->cloud_deskewed, *extractedCloud); // new cloud for extraction
- calculateSmoothness(); //计算当前帧每个点的曲率
- markOccludedPoints(); //标记遮挡和平行(为什么后做遮挡的判断?)
- extractFeatures(); //这才开始提取特征
- //发布处理完的数据给下一part
- publishFeatureCloud();
- }
大体就和论文差不多,判断遮挡点,判断角点和平面点,不过计算方法简化。
重点:
特征点的“曲率”没有归一化,这样有一个不好的点(也可能有其他好处,但是至少有坏处),同样的曲率,远处的点比近处的点计算的“曲率”大很多,100米处的一个点,比周围平均深2米,得到的是100*10-102*10==20,再平方,等于400,而10米处一个点,比周围平均深0.2米,本来应该是同样的曲率,但是会得到0.2*10=2,再平方,等于4,看起来弯曲程度一样,但是近处的特征点会排序到后边,不被识别。可能算是作者的一种trick吧,他把360度的scan分成了6个区域,分别排序提取特征点,能减缓一下这种远近不均。
imuPreintegration.cpp
可能是这里最复杂的node,有两个模块,第一个fusion先不管(尤其是那套订阅,和imu预积分容易混淆),其实很独立,不影响主逻辑。

先看预积分模块IMUPreintegration
订阅输入:激光里程计("lio_sam/mapping/odometry_incremental")
发布输出:imu里程计(odomTopic + "_incremental")
乱的点来了,首先各topic命名就看起来有点乱,而且采用了有的topic写死,有的topic配置,有的是半配置+半写死。
imuHandler():主要是暂存imu原始数据,也顺带作为“高频位姿发布”触发器,负责预测里程计位姿(这个预测再经过融合会给rviz)
odometryHandler():
核心触发点就是激光雷达里程计,触发对imu预积分结果的修正,因为认为是真值。
本函数看起来较长,其实是一些初始化和重置逻辑堆的。核心数据PVB其实是放成员变量缓存了,优化器本身主要存方差。初始化和重置大同小异,先略过,说正常更新。
正常更新时,当激光雷达里程计到达,取上次优化和当前激光雷达时间戳之间的时间段,之前只接收未处理的原始imu数据队列imuQueOpt做imu预积分(预积分器imuIntegratorOpt_自动做),然后把imu预积分结果preint_imu提出来。
gtsam优化部分:
- // add imu factor to graph
- const gtsam::PreintegratedImuMeasurements& preint_imu = dynamic_cast<const gtsam::PreintegratedImuMeasurements&>(*imuIntegratorOpt_);
- gtsam::ImuFactor imu_factor(X(key - 1), V(key - 1), X(key), V(key), B(key - 1), preint_imu);
- graphFactors.add(imu_factor);
- // add imu bias between factor
- graphFactors.add(gtsam::BetweenFactor
- gtsam::noiseModel::Diagonal::Sigmas(sqrt(imuIntegratorOpt_->deltaTij()) * noiseModelBetweenBias)));
- // add pose factor
- gtsam::Pose3 curPose = lidarPose.compose(lidar2Imu);
- gtsam::PriorFactor
- graphFactors.add(pose_factor);
- // insert predicted values
- gtsam::NavState propState_ = imuIntegratorOpt_->predict(prevState_, prevBias_);
- graphValues.insert(X(key), propState_.pose());
- graphValues.insert(V(key), propState_.v());
- graphValues.insert(B(key), prevBias_);
- // optimize
- optimizer.update(graphFactors, graphValues);
- optimizer.update();
- graphFactors.resize(0);
- graphValues.clear();
- // Overwrite the beginning of the preintegration for the next step.
- gtsam::Values result = optimizer.calculateEstimate();
- prevPose_ = result.at
- prevVel_ = result.at
- prevState_ = gtsam::NavState(prevPose_, prevVel_);
- prevBias_ = result.at
- // Reset the optimization preintegration object.
- imuIntegratorOpt_->resetIntegrationAndSetBias(prevBias_);
PVB三个状态量,分为当前帧和前一帧,PV初始值由预积分得出,P约束由激光里程计给出,B前后根据imu预设bias传播。进行优化。把优化结果X(key)、V(key)、B(key)提取出来,等下一轮优化。
重点:预积分器的优化和后端的优化还是有些区别的,尤其是专门的因子,值得留意。
注意:prevState_打包了prevPose_和prevVel_,作为预积分器预测的基准。
imuhandler:
利用之前预积分优化得到的结果,结合imu原始数据,填补激光里程计未到达的空白,发布预测。
关于两个imu管道imuQueOpt和imuQueImu:
其实都是原始imu数据,只不过为了操作方便(需要pop_front),所以分了两个,一个用来根据激光雷达里程计修正bias,一个用来发布高频预测,弥补激光雷达里程计数据真空期),在opt那边优化后,后者也需要pop掉同步之前的数据,然后用来预测之后的位姿,所以两者是对立统一的。
TransformFusion
订阅imu预积分预测,结合激光里程计,注意,这个输出都是给rviz用的,点云去畸变用的是“融合前”的odomTopic + _incremental,而不是融合后的
订阅输入:"lio_sam/mapping/odometry"、odomTopic + "_incremental"
发布输出:odomTopic
lidarOdometryHandler:缓存激光里程计
imuOdometryHandler:根据imu里程计消息,以上一帧lidar为基准推测位姿,,发布此段path
mapOptmization.cpp
订阅输入:主线cloud_info
发布输出:imu里程计odomTopic、"lio_sam/imu/path"(rviz展示用)
主要流程不复杂,优化分两步:
1.数据处理,预估位姿,scan-to-map匹配
2.关键帧筛选,加入闭环因子(gps和闭环都认为是一种“闭环”,至少共享bool判定),进行因子图优化,优化位姿。
单纯说数据流程和过程不复杂(不展开数学部分),主流程都在点云cloud_info句柄里:
位姿预测transformTobeMapped,基于kdtree和上一帧位姿cloudKeyPoses3D->back()的局部地图的抽取,基于kdtree的点到线的匹配搜索和优化,后续保存和发布。
- void laserCloudInfoHandler(const lio_sam::cloud_infoConstPtr &msgIn)
- {
- // extract time stamp
- timeLaserInfoStamp = msgIn->header.stamp;
- timeLaserInfoCur = msgIn->header.stamp.toSec();
- // extract info and feature cloud
- cloudInfo = *msgIn;
- pcl::fromROSMsg(msgIn->cloud_corner, *laserCloudCornerLast); //角点,转换到pcl类型,缓存到对象
- pcl::fromROSMsg(msgIn->cloud_surface, *laserCloudSurfLast);
- std::lock_guard
- static double timeLastProcessing = -1;
- if (timeLaserInfoCur - timeLastProcessing >= mappingProcessInterval) //0.15秒最小间隔,不是所有数据都处理
- {
- timeLastProcessing = timeLaserInfoCur;
- updateInitialGuess();
- extractSurroundingKeyFrames(); //降采样相邻关键帧集合,提取一个局部map用来匹配
- downsampleCurrentScan(); //降采样角点和平面点
- scan2MapOptimization(); //
- saveKeyFramesAndFactor(); //进行因子图优化
- correctPoses(); //优化后的结果去修正外部的数据
- publishOdometry();
- publishFrames();
- }
- }
优化过程:用之前抽取的局部map建立kdtree,然后让当前scan去搜索最近邻,优化点和线的关系(实际代码的方法和论文略有区别),优化后更新维护最新位姿transformTobeMapped。
- void scan2MapOptimization()
- {
- if (cloudKeyPoses3D->points.empty()) //全局关键帧是否为空
- return;
- if (laserCloudCornerLastDSNum > edgeFeatureMinValidNum && laserCloudSurfLastDSNum > surfFeatureMinValidNum)
- {
- kdtreeCornerFromMap->setInputCloud(laserCloudCornerFromMapDS);
- kdtreeSurfFromMap->setInputCloud(laserCloudSurfFromMapDS);
- for (int iterCount = 0; iterCount < 30; iterCount++) //迭代30次,里边含了4个接口
- {
- laserCloudOri->clear();
- coeffSel->clear();
- cornerOptimization(); //角点优化
- surfOptimization();
- combineOptimizationCoeffs();
- if (LMOptimization(iterCount) == true)
- break;
- }
- transformUpdate();
- }
- else
- {
- ROS_WARN("Not enough features! Only %d edge and %d planar features available.", laserCloudCornerLastDSNum, laserCloudSurfLastDSNum);
- }
- }
这套代码可以优化的点:
1.重定位功能
如果有gnss信息,用gnss赋初值,直接ndt+icp定位,失败再重试。
gnss可以多收集一段,推测运动方向,估计出yaw,会更好一些,只有xyz估计没有yaw的话,ndt还是不太容易成功。
2.特征提取的方式我觉得曲率计算和排序提取那边如果算力足,可能有更好的方式。
-
相关阅读:
WordPress主题开发(四)之—— 模板文件
5-1传输层-传输层提供的服务
软考高级系统架构设计师系列论文三十:论SOA面向服务架构技术的应用
免费office安装工具箱(可安装任意版本)
【VRP】基于常春藤算法IVY求解带时间窗的车辆路径问题TWVRP,最短距离附Matlab代码
常见的MySQL语句类型及其基础用法
FS2115D SOT23-6 低噪声3.3V升压IC电荷泵 DC/DC 转换器
xgboost early_stop_rounds是如何生效的?
运动控制:编码器滤波
集合和集合框架
- 原文地址:https://blog.csdn.net/huqinweI987/article/details/132670524
