-
few shot目标检测survey paper笔记(整体概念)
paper: Few-Shot Object Detection: A Comprehensive Survey (CVPR2021)
深度学习提高了目标检测的精度,但是它需要大量的训练数据。
对于训练数据集中没有见过的目标,是检测不了的,所以就限制了在实际中的应用。
如果想让模型去识别新的目标,就需要自己标注,这是既花时间又很枯燥的活,而且像医疗数据这种根本得不到大量的数据。
对比人类就不同了,小孩子看一眼一个物体就能很快认识它。
那么就引出了few shot目标检测(FSOD)。称作小样本目标检测。旨在通过少量标注的数据去训练一个已经预训练的模型,就能达到检测新目标的目的。大致思想如下
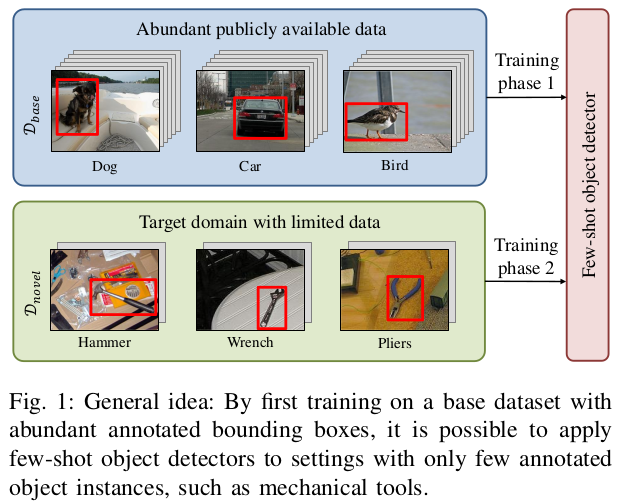
小样本目标检测的一些概念:

先给模型训练的base数据集和新标注的小样本数据集novel是不重叠的。
K-shot目标检测: C n o v e l C_{novel} Cnovel中每个类别只有K个标注的目标instances. 并不一定是K张图片(一张图片中可有多个目标)。
难度最大的是one-shot目标检测,也就是K=1.N-way目标检测:从N个类别中检测目标,N<=| C n o v e l C_{novel} Cnovel|
few-shot目标检测可以总结为N-way K-shot检测。
为什么要先用 D b a s e D_{base} Dbase训练然后再用 D n o v e l D_{novel} Dnovel,而不是直接用 D n o v e l D_{novel} Dnovel训练?因为只用 D n o v e l D_{novel} Dnovel训练会overfit, poor generalization.
那么把 D b a s e D_{base} Dbase和 D n o v e l D_{novel} Dnovel融合成一个数据集一起训练呢? D b a s e D_{base} Dbase数据集中的样本数远远多于小样本的 D n o v e l D_{novel} Dnovel,是很大程度的class imbalance, 结果就是训练时会偏向base数据集,造成小样本数据类别检测效果不好。基本上训练是分成3步的,
第1步,用classification数据(比如imageNet)先训练backbone, 得到初步的模型 M i n i t M_{init} Minit,
第2步,用 D b a s e D_{base} Dbase训练,得到模型 M b a s e M_{base} Mbase,
最后用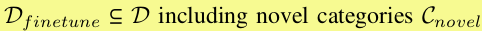 训练,得到
M
f
i
n
a
l
M_{final}
Mfinal
训练,得到
M
f
i
n
a
l
M_{final}
Mfinal
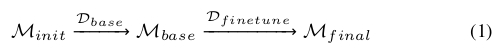
小样本数据训练的相关概念:
Few-Shot Learning and Classification:
最早用于分类任务,比目标检测任务要简单一些,它的一些ideas也可用于目标检测。Semi-Supervised Learning:
半监督学习,只有少量有标签的数据,大量没有标签的数据可用来学习合适的representations.
可用来提高few-shot learning中学习到的representations.Incremental Learning:
一般的深度学习会遇到严重的忘性,学习了新数据就忘了旧数据。
比如先用COCO数据集训练,再用航拍数据训练,然后就只能检测航拍数据,COCO数据竟检测不出来了。
增量学习旨在保留旧类别的performance.
当不断有新的类别进来时,一些FSOD方法会引入增量学习。几种不同的目标检测:
一般目标检测:分类+目标框,类别有限,不在训练类别里面的就检测为背景。需要标注的数据集进行训练。
Cross-Domain目标检测:
先用大量标记数据训练,再用不同领域的少量数据训练。这乍一听不就是few-shot么。
其实不然,cross-domain前后虽然是不同的domain, 但前后类别是一样的,比如先用合成数据训练,再用真实数据训练;
few-shot是引入新的类别。Zero-shot目标检测:
是few-shot的极端情况,标注数据为0 (K=0)。
zero-shot常和语义word embedding一起,语义上相似类别的目标在embedding空间会有相似的feature。
zero-shot对于检测常用的物体是可以的,但是如果你提供一个特殊的标签,或者想区分非常相近的目标是有问题的。Weakly Supervised目标检测:
弱化标注,训练数据仅包含image-level的标签。
比如在图像的某个地方是不是存在某种类别的目标。这种标注比画框标注简单,常可通过关键字搜索获得。
弱监督的难点再于训练时没有任何定位信息的情况下检测到所有目标。
虽然说在标注上难度有所下降,但是仍然需要大量的图片,在很难获得图片(比如医疗图像)时仍然是有困难的。几种Learning Techniques:
Transfer Learning(迁移学习):
和few-shot的区别是,新的类别数据不必要是小数据。
因此,如果用迁移学习做小样本训练,需要结合小样本学习。Metric Learning(度量学习):
学习一个embedding, 可以理解为一个特征向量。相似的目标特征会相似,有较小的距离. 不相似的目标距离就远。
为了学习到有较低类内距离和较高类间距离的L2特征,一般会用到triplet loss或者它的拓展。
这些特征的推广性还不错,模型可以encode新类别的目标,不需要重新训练。
在模型推理阶段,模型会提取新目标的embedding,然后类别会分到最相近的特征embedding类别中。
不过,上面只提到了分类,对于目标检测,还需要把目标的位置信息融合进去。Meta Learning(元学习):
也叫“学会学习”,以推广到新的任务和新的数据。
对于小样本few-shot来说,元学习需要学会如何区分出训练时不固定的类别,
所以需要学习如何最有效地获取需要的信息,以便在只有少量样本时也能学到有效信息。小样本目标检测方法分类
paper中将FSOD分为两类,meta learning和transfer learning.
其中meta learning又分为single-branch和dual-branch.
dual-branch: 2个input, query和support image.
single-branch: 类似于一般的检测模型,但是在训练新的类别或者用metric learning时,会压缩需要学习的参数的数量。一些dual-branch结构和迁移学习会结合metric learning的idea,所以为了不至于混淆,paper不把metric learning单独当作一个类别。
而是通过训练策略和结构把SOTA方法进行区分。下面的图是survey中涉及到的方法,可以看出小样本目标检测这个领域还很新,大部分方法都是近几年才提出来,
其中多数用了transfer learning和dual-branch meta learning.

数据集方面,很多用的都是VOC, COCO数据集。
evaluate的时候,用的是K-shot, N-way方式,即有N个类别,每个类别K个标注的目标。VOC数据集
VOC数据集包含20个类别的标注,VOC07+12训练集用于训练,VOC07的测试集用于测试。
在小样本目标检测中,常用3个类别分割集,每个集中有15个base类别和5个novel类别。
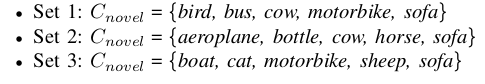
每个类别的样本个数K设为1,2,3,5,10.
验证的环节用AP50.
虽然样本数量是限定的,但是具体用什么样的样本并不是固定的。所以不同的方法用的是不同的目标。
最近有文献提出需要重新审视evaluate过程,要随机用不同的类别,30次跑的结果做平均。
而且提出不能只在novel集上评估,还要考虑到base数据集的准确度有没有下降。COCO数据集
比VOC更有挑战性,有80个类别,其中包括VOC的20个类别。
在小样本目标检测中,通常把20个VOC类别当作novel, 剩下的60个类别当作base.
样本数设在10和30. 但是,一些方法就聚焦在极少样本上(每个类别1~3 shot)
evaluation用COCO的标准方法,AP50~95. 还有AP50, AP75, AP small, medium, large.
有的方法也用到了recall。同样,COCO数据集也遇到了在不同的目标上做K-shot评估的问题,目标没有统一。
评价标准存在的偏离
目标检测包含了分类和定位两个任务,但是,一些few-shot方法偏离了这个标准,它们创造了一个新的task, one-shot场景,这有什么问题呢?这暗示移除了分类这个任务,是一个1-way训练,检测器只需要预测图片是否包含这个目标,定位在哪里,并没有分类任务。因此建议用N-way设置。
还有一种偏离了主题的评估,PNSD和FKSOD中已经用COCO训练了ResNet, 然后又用COCO数据集里的类别作为novel类别,事实上novel类别已经不novel了。 -
相关阅读:
Python青少年等级考试实操题(二级)
AI生成内容(AIGC)技术:革新创作与挑战未来
网络技术二十二:NAT&PPP
Linux系统编程(七):线程同步
MMSeg搭建自己的网络
gcc: error: : No such file or directory
QT error: undefined reference to `__imp__ZN12QSqlDatabase7driversEv‘报错
数据结构与算法 | 深搜(DFS)与广搜(BFS)
数商云采购系统解决方案 | 建筑工程行业采购管理之招标业务场景应用
YOLOWeeds: 用于棉花生产系统中多类杂草检测的 YOLO 目标检测器的新基准
- 原文地址:https://blog.csdn.net/level_code/article/details/132808285