-
Mysql中in和exists的区别 & not in、not exists、left join的相互转换
数据准备
-- 建表 CREATE TABLE `xin_stu_t_bak` ( `id` bigint NOT NULL COMMENT '主键', `relation_id` bigint DEFAULT NULL COMMENT '外键, 记录教师id', `student_name` varchar(30) DEFAULT NULL COMMENT '姓名', `student_age` bigint DEFAULT NULL COMMENT '年龄', `school` varchar(300) DEFAULT NULL COMMENT '学校', KEY `relationid` (`relation_id`) ) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4 COLLATE=utf8mb4_0900_ai_ci; CREATE TABLE `xin_teach_t_bak` ( `id` bigint NOT NULL COMMENT '主键', `teacher_name` varchar(30) DEFAULT NULL COMMENT '教师姓名', `teacher_age` bigint DEFAULT NULL COMMENT '教师年龄', `school` varchar(300) DEFAULT NULL COMMENT '学校', KEY `id` (`id`) ) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4 COLLATE=utf8mb4_0900_ai_ci; -- 加索引 create index id on xin_stu_t_bak(relation_id); create index id on xin_teach_t_bak(id); -- 添数据 INSERT INTO lelele.xin_stu_t_bak (id,relation_id,student_name,student_age,school) VALUES (1,NULL,'尤仁义1',11,'徐州中学'), (2,1,'尤仁义2',12,'徐州中学'), (3,NULL,'朱有理1',11,'徐州中学'), (4,2,'朱有理2',12,'徐州中学'), (5,2,'朱有理3',13,'徐州中学'), (6,3,'宋昆明1',11,'徐州中学'), (7,3,'宋昆明2',12,'徐州中学'), (8,14,'宋昆明3',13,'徐州中学'); INSERT INTO lelele.xin_teach_t_bak (id,teacher_name,teacher_age,school) VALUES (1,'王翠花1',31,'徐州中学'), (2,'王翠花2',31,'徐州中学'), (3,'王翠花3',33,'徐州中学'), (4,'王翠花4',34,'徐州中学'), (5,'王翠花5',35,'徐州中学'), (1,'王翠花1',31,'徐州中学'), (1,'王翠花1',31,'徐州中学'), (2,'王翠花2',31,'徐州中学'), (6,'王翠花6',31,'徐州中学'), (7,'王翠花7',31,'徐州中学'); INSERT INTO lelele.xin_teach_t_bak (id,teacher_name,teacher_age,school) VALUES (8,'王翠花8',33,'徐州中学'), (9,'王翠花9',34,'徐州中学'), (10,'王翠花10',35,'徐州中学'), (11,'王翠花11',31,'徐州中学'), (12,'王翠花12',31,'徐州中学'), (13,'王翠花13',31,'徐州中学');- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
1. in 介绍
1.1 in中数据量的限制
在oracle中,int中数据集的大小超过1000会报错;
在mysql中,超过1000不会报错,但也是有数据量限制的,应该是4mb,但不建议数据集超过1000,
因为in是可以走索引的,但in中数据量过大索引就会失效1.2 null值不参与in或not in,也就是说in and not in 并不是全量值,排除了null值
select * from xin_stu_t_bak a where a.relation_id in ( select id from xin_teach_t_bak b)

select * from xin_stu_t_bak a where a.relation_id not in ( select id from xin_teach_t_bak b)

select * from xin_stu_t_bak a

从此处可以看出,in和not in 加在一起并不是全量的值,排除了null值
1.3 in的执行逻辑
- 当前的in子查询是B表驱动A表
- mysql先将B表的数据一把查出来至于内存中
- 遍历B表的数据,再去查A表(每次遍历都是一次连接交互,这里会耗资源)
- 假设B有100000条记录,A有10条记录,会交互100000次数据库;再假设B有10条记录,A有100000记录,只会发生10次交互。
结论: in是先进行子查询,再与外面的数据进行循环遍历,属于子查询的结果集驱动外面的结果集,
当in子查询的结果集较小时,就形成了小表驱动大表,而两张表的驱动就是一张表的行数据去循环关联另一张表,
关联次数越少越好,所以小表去查询大表,次数更少,性能更高
in()适合B表比A表数据小的情况2. exists介绍
2.1 exists + not exists 是全量数据
select * from xin_stu_t_bak a where exists ( select 1 from xin_teach_t_bak b where a.relation_id = b.id)
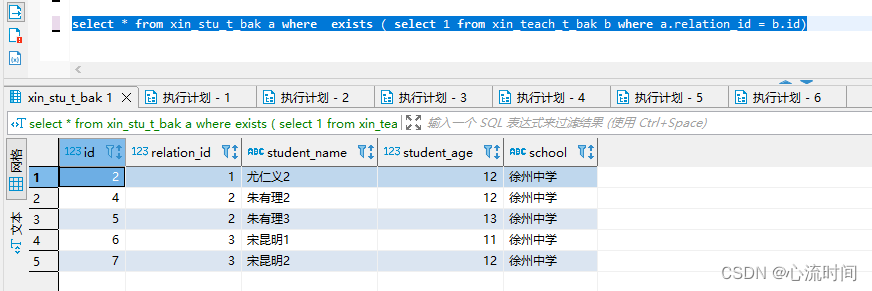
select * from xin_stu_t_bak a where not exists ( select 1 from xin_teach_t_bak b where a.relation_id = b.id)
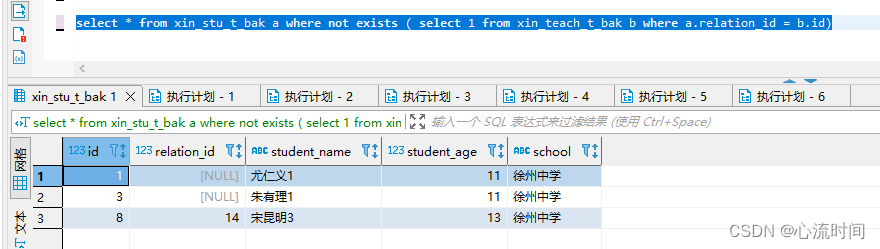
exist + not exists 是全量数据,这点与in不同
2.2 exists的执行逻辑
- 当前exists查询是A表驱动B表
- 与in不同,exists将A的纪录数查询到内存,因此A表的记录数决定了数据库的交互次数
- 假设A有10000条记录,B有10条记录,数据库交互次数为10000;假设A有10条,B有10000条,数据库交互次数为10。
结论:exists理论上就是boolean值,关联后查询到有值则是true数据留下,关联后查询没有值则是false数据舍弃;
exists适合B表数据量大,A表数据量小的情况,与in相反3. 小表驱动大表的好处
我们来看下面两个循环:
for (int i = 0; i<10000; i++){ for(int j = 0; j<10; j++){ } }- 1
- 2
- 3
- 4
- 5
- 6
for (int i = 0; i<10; i++){ for(int j = 0; j<10000; j++){ } }- 1
- 2
- 3
- 4
- 5
- 6
在java中,我们都知道上述的两个循环的时间复杂度都是一样的;
但在数据库中则是有区别的,
首先第一层循环,数据库只做一次交互一把将数据查出到缓存中,
而第二层循环的数据库交互次数决定于第一层循环数据量的大小。
对于数据库而言,交互次数越多越耗费资源,一次交互涉及了“连接-查找-断开”这些操作,是相当耗费资源的。
使用in时,B表驱动A
使用exists时,A表驱动B
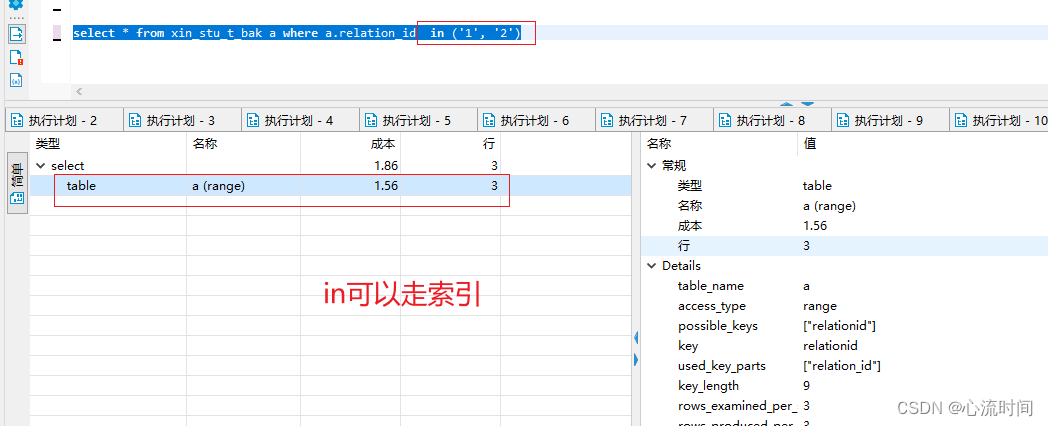
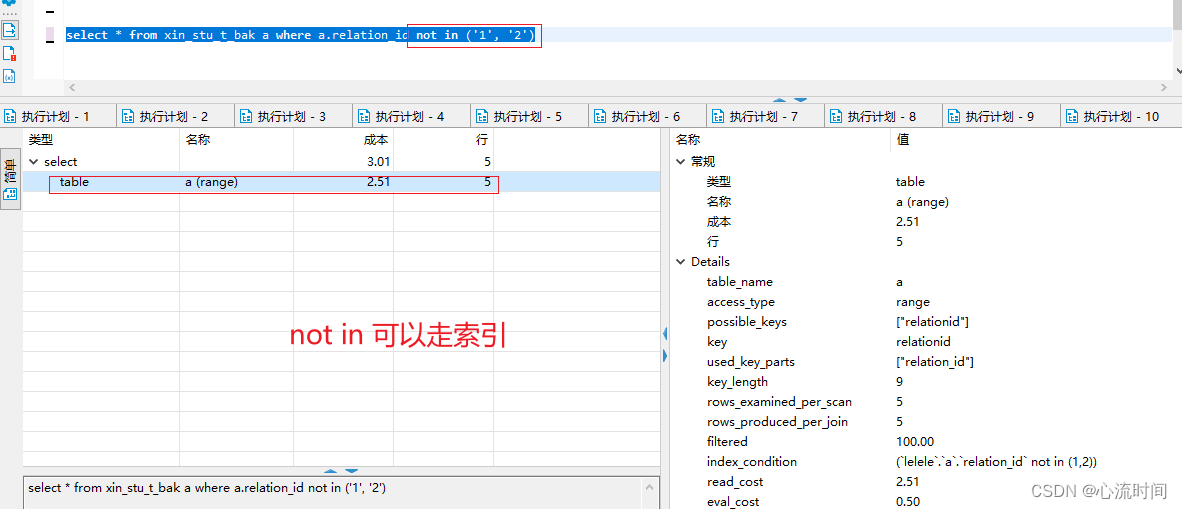
所以我们写sql时应当遵循“小表驱动大表“的原则4. in、not in、exists、not exists是否可以走索引(都可以)
in可以走索引,但数据量过大时就不走索引了
not in、exist、not exists也都可以走索引- in
select * from xin_stu_t_bak a where a.relation_id in ( select id from xin_teach_t_bak b where a.relation_id = b.id)

select * from xin_stu_t_bak a where a.relation_id in (‘1’, ‘2’)
- not in
select * from xin_stu_t_bak a where a.relation_id not in (‘1’, ‘2’)
- exists
select * from xin_stu_t_bak a where exists ( select 1 from xin_teach_t_bak b where a.relation_id = b.id)

- not exists
select * from xin_stu_t_bak a where not exists ( select 1 from xin_teach_t_bak b where a.relation_id = b.id)
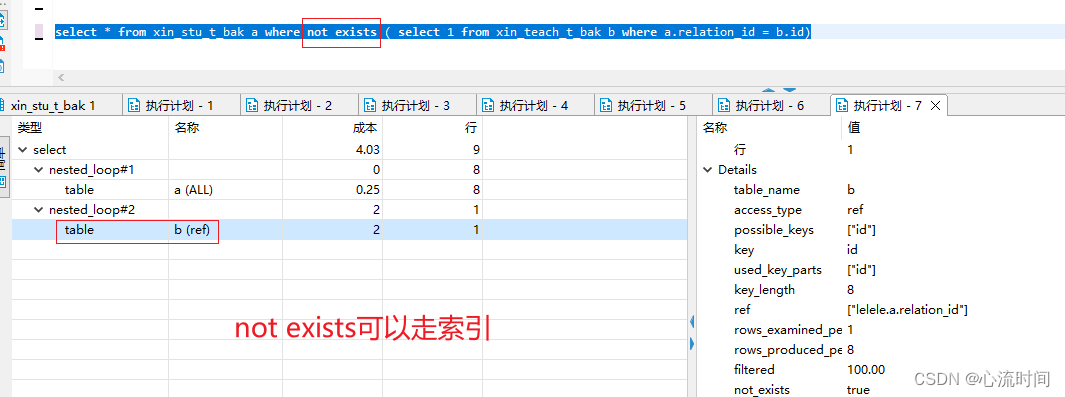
5. not in、 not exists、left join语句相互转换(必须在表关联时,否则并不等同)
5.1 not in
select * from xin_stu_t_bak a where a.relation_id not in ( select id from xin_teach_t_bak b where a.relation_id = b.id)

5.2 not exists
select * from xin_stu_t_bak a where not exists ( select 1 from xin_teach_t_bak b where a.relation_id = b.id)
5.3 left join + is null
select a.* from xin_stu_t_bak a left join xin_teach_t_bak b on a.relation_id = b.id where b.id is null;

-
相关阅读:
内衣洗衣机便宜好用的牌子有哪些?四款公认好用洗内裤机推荐
线程退出学习
在Windows上使用nginx具体步骤
Haskell Stack编译cannot encode character ‘8226‘ 错误 (Win10)
【Java 进阶篇】HTML DOM样式控制详解
迭代器 Iterator
速码!!!BGP最全学习笔记:BGP选路原则实验配置
ubuntu20.04 jammy 安装ros2
Educational Codeforces Round 135 (Rated for Div. 2) E. Red-Black Pepper(贪心+数论)
MySqL速成教程笔记系列九
- 原文地址:https://blog.csdn.net/weixin_43024834/article/details/132777220
