-
VL-Adapter: 针对视觉和语言(Vision-and-Language)的参数高效迁移学习
VL-ADAPTER: Parameter-Efficient Transfer Learning for Vision-and-Language Tasks
22年发表在CVPR
UNC大学Abstract
将介绍VL-BART和VL-T5这两个模型(adapter-based parameter-efficient transfer learning techniques)
评估这俩模型通过一个统一的多任务设置。
对于image-test使用VQAv2、GQA、NLVR2和MSCOCO这四个数据集。
对于video-text使用TVQA、How2QA、TVC和YC2C这四个数据集。
把adapter-tuning(adapter、Hyperformer、Compacter)和fine-tuning和prompt-tuning 进行对比。
结果表明 adapter-tuning4.18%i-t任务和3.39%v-t任务可以达到fine-tuning整体模型的效果。Introduction
大模型预训练模型已经成了解决V&L任务的标准框架。
通常是vision encoders和language model的结合,然后经过fine-tuning去解决下游任务。
为了解决大模型tuning的难度提出来了很多 parameter-efficient training方法。
Adapter对于大模型进行一小部分的训练就可以达到full fine-tuning的效果。
即使adapter已经对文本分类和Image-text alignment(图像文本对齐)问题有了一些成功的效果,但是对于下游更有挑战的V&L问题如视觉/视频问答和图像/视频字幕等却没有人做。文章作者将做这个问题。
作者使用了CLIP一个image-text对求的模型作为视觉编码器(visual encoder)为了对于V&L模型做预训练。
为了告知模型的任务,将做一些 text prompts 例如:例如,vqa的“vqa:[Q]” VQA是Visual Question Answering(视觉问答)。
然后对模型插入一些Adapter以及其变体 Hyperformer和Compacter,进行parameter-efficient training。
作者对于这两个变体的解释是:Hyperformer通过超网络生成适配器的权重来提高适配器的效率,而Compacter通过利用Kronecker产品和适配器权重的低阶参数化来减少参数。
具体看这两个技术可以看论文中的引用。
作者说根据adapter的一些方法可以实现一些cross-task(跨任务)学习,可以进一步减少训练量。
对于作者所说的对于上述的技术进行在abstract的四个i-t任务和四个v-t任务中的表现:
Compactor的表现并不突出,因为去除了 low-rank approximation for trading performance。
Hyperformer比adapter高效,使用权重共享(weight-sharing)技术进行adapter训练可以实现与完全微调相同的性能,同时图像文本任务仅更新4.18%的整个参数(视频文本任务更新3.39%)。
对CLIP中的元素进行fine-tuning(进行调整训练的元素)和freezing(不进行训练更改的元素)进行了对比,后者的在表现和元素高效性方面平衡的更好。
在最佳的V&L模型上进行adapter最后的效果可以完美匹配甚至超过full fine-tuning的模型。
作者所说的工作总结 直接贴在这里了:
Our contributions could be summarized as: (1) the first
work benchmarking different types of parameter-efficient
training techniques (Adapter, Hyperformer and Compacter)
for diverse challenging downstream image-text and video text tasks; (2) empirical demonstration of adapters reaching the performance of full fine-tuning while updating only
3.39-4.18% of the parameters; (3) comprehensive analysis
on the design of freezing CLIP, impact of different architectural components, weight-sharing techniques, task-specific
prompts, and vision-language pretraining.(我们的贡献可以总结为:(1)首次针对不同类型的参数高效训练技术(Adapter、Hyperformer和Compacter),针对具有挑战性的下游图像文本和视频文本任务进行基准测试;(2) 经验证明,适配器在仅更新3.39-4.18%的参数的情况下达到了完全微调的性能;(3) 全面分析冷冻CLIP的设计、不同结构组件的影响、权重分配技术、任务特定提示和视觉语言预训练。
)Related Work
这篇文章的工作是基于以前模型和一些有效训练的工作基础上的,将介绍以前的文献以及技术上的异同。
CLIP:用于多模态的网络,CLIP模型使用了一个共享的视觉-语言嵌入空间,其中图像和文本通过一个统一的编码器转换为嵌入向量。这个编码器是由一个图像模块和一个文本模块组成,它们共享参数,以便在两个模态之间建立联系。CLIP模型通过最大化正样本对(包含相似的图像和文本)的相似度,并最小化负样本对(包含不相似的图像和文本)的相似度来进行训练。这种对比学习的训练方式使得CLIP能够学习到图像和文本之间的语义对齐,使得在嵌入空间中具有相似语义的图像和文本靠近。CLIP模型在多个视觉和语言任务上表现出色,包括图像分类、图像生成描述、图像问答等。它的独特之处在于它能够在没有任何标注数据的情况下进行训练,并且具有较强的泛化能力,能够在不同任务上进行迁移学习。
我们的V&L模型是CLIP和BART(或T5)的组合。
下述Section5.2表示了adapter的重要性
讲了参数高效训练:(1)加参数训练(adapter)。(2)只更新模型的一小部分参数训练。(3)weight矩阵降秩训练。
本文针对(1)进行更下游的visual/video question answering, visual reasoning, and image/video captioning任务。即:
视觉/视频问答(Visual/VideoQuestionAnswering):这个任务旨在让计算机通过对图像或视频提出的问题进行回答。计算机需要理解问题的语义,并从图像或视频中提取相关信息来给出准确的答案。这个任务要求计算机具备对视觉和语言信息的联合理解能力。视觉推理(VisualReasoning):视觉推理任务要求计算机在处理视觉信息时进行逻辑推理和推断。这包括根据图像中的特定属性或关系回答问题,预测对象的位置、数量或状态等。视觉推理任务旨在培养计算机在视觉领域进行逻辑推理和推断的能力。
图像/视频描述(Image/VideoCaptioning):这个任务涉及到给定一张图像或一段视频,生成描述性的自然语言文本来准确表达其内容。计算机需要理解图像或视频的语义,并使用恰当的语言描述来表达场景、对象和动作等。
在这篇文章中,更新的点是,对于adapter-tuning之类的问题,加的adapter都是针对模型的训练,所以在针对不同模型的时候没有共享性,
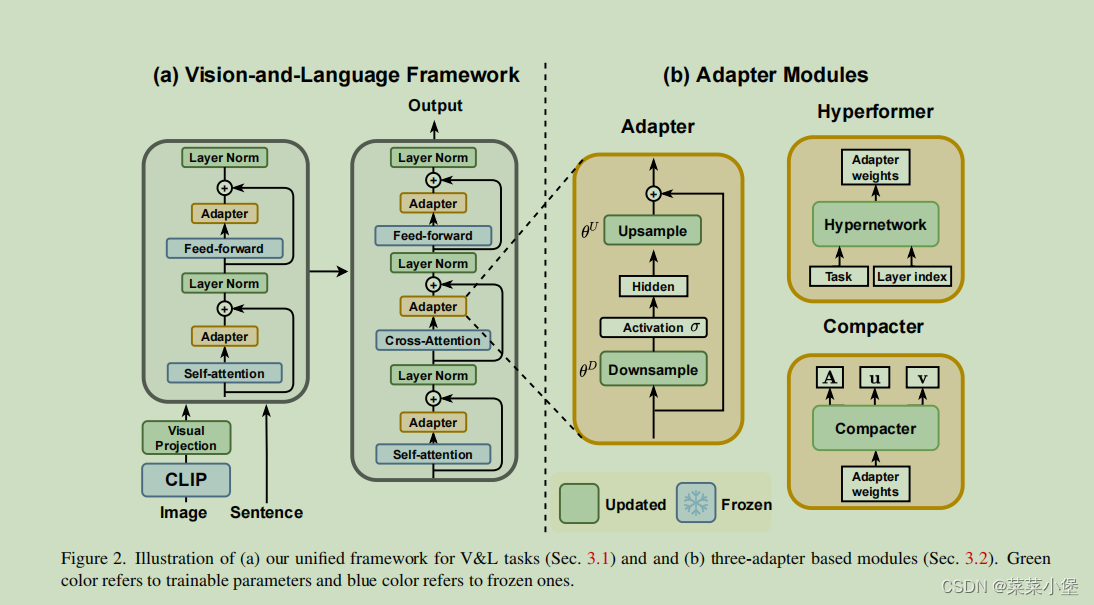
所以提出一个 plug-and-play(热插拔)的adapter进行可共享的adapter,减少可训练参数Methods
实验证明,vanilla adapter效果最好。We further demonstrate that sharing adapters across tasks can boost performance to match full fine-tuning results and further improve the parameter efficiency。(跨模型adapter的可行性)。
我们的V&L模型是CLIP和BART(T5)的组合,因此我们将我们的基础架构命名为CLIP-BART(CLIP-T5)。Unified Framework for V&L Tasks
用encoder-decoder模型作为我们的生成模型。
CLIP做视觉到语言的投影,并把生成的语言放到encoder-decoder模型中。
这里讲了个在V&L中统一用的交叉熵损失函数,没理解作者的意图。
对于后续的函数表达式做了描述。👆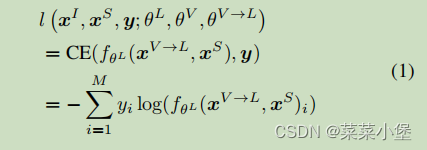
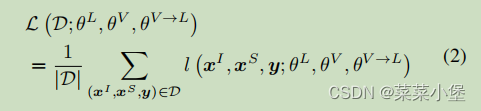
Adapter for V&L Models
d i d_i di和 d d d分别是input层和hidden层的变量个数。
θ D \theta^D θD是Downsample的weight变量。
θ U \theta^U θU是Upsample的weight变量。
adapter公式👇
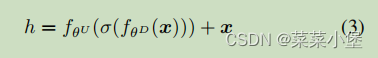
h = f θ U ( σ ( f θ U ( x ) ) ) + x h = f_{\theta^U}(\sigma(f_{\theta^U}(x)))+x h=fθU(σ(fθU(x)))+x
σ ( ) \sigma(~) σ( )是激活函数 作者用的是 G E L U GELU GELU激活函数Hyperformers
作者讲到了自己工作的部分:我们维护一个在任务上共享的超网络,以生成以任务和层索引为条件的适配器权重(adapters’ weights)。
N T N_T NT表示task 数量 N L N_L NL表示layer的数量
Hyperformer主要用于生成适配器中上采样层和下采样层的权重。
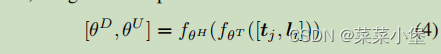
[·]表示concatenation(串联)
👇图是对👆图公式的解释,上图公式是表示task 的parameter(t)和layer的parameter(l)是怎么生成的。

Compacters
Compacter hence is introduced by [33] to solve the issues with the matrix decomposition and parameter sharing, and eventually, Compacter has been shown to have a better trade-off between performance and efficiency compared to adapters.
引入了Compacter来解决矩阵分解和参数共享的问题,最终,与适配器相比,Compacter在性能和效率之间具有更好的折中。

先介绍了PHM层的变量。

然后介绍了LPHM的用法,就是对于矩阵进行降秩然后进行变量计算,但是作者说这种做法会验证影响V&L任务的性能。Shared-Weight Adapters
作者定义了
Θ = { Θ D , Θ U } \Theta=\{\Theta^D,\Theta^U\} Θ={ΘD,ΘU}是模型中所有插入适配器模块权重的集合。
Θ D o r Θ U \Theta^Dor\Theta^U ΘDorΘU是仅包括适配器中的上下采样层的子集。
适配器是独立训练的,
{ Θ i D , Θ i U } \{\Theta^D_i,\Theta^U_i\} {ΘiD,ΘiU}是unique对于 i t h 个 t a s k i^th个task ith个task
但是为了适配器可以学习交叉任务,使适配器的部分权重to be shareable。
做法是:
让 Θ i D = Θ j D \Theta^D_i=\Theta^D_j ΘiD=ΘjD,然后对 Θ i U \Theta^U_i ΘiU继续进行第 i t h 个 t a s k i^th个task ith个task继续进行训练 ( i ≠ j ) (i \neq j) (i=j)。
xpng)Where to Add Adapter
因为目标是在V&L模型中有效的进行parameters的update。所以会把adapter同时插入visual和language组件中。
作者实验发现,整体fine-tuning整个模型的效果不会比只update language model好。在权衡过后,freezing CLIP的参数(不tuning),效果会较好,所以不在CLIP中添加adapter。Multi-task Adapter Variants
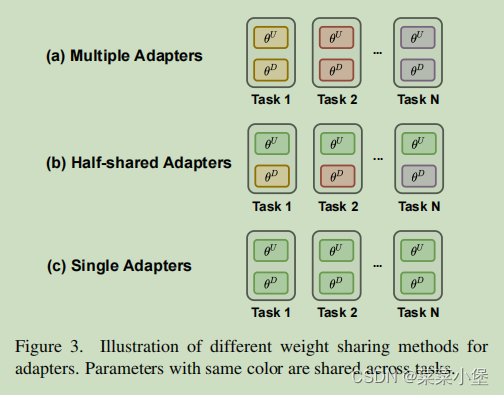
Single Adapter:全局共享训练。
Half-shared Adapters:部分共享训练。
Multiple Adapters:针对(单独)训练。

讲述了上述三个adapter的工作,最后说了下Hyperformer是为了多任务进行信息共享的。作者update了模型中的1.14%的parameters并且 正则化了0.04% parameters。对于模型的output层进行了freeze,虽然占据了语言模型的30%的参数,但是update他不会有性能的提升。
dataset
所使用的数据库就是Introduce中所说的数据库,最后作者使用CLIP-BART和CLIP-T5来表示这两种V&L架构。
Training and Evaluation
作者先对模型进行了广泛的超参数搜索。
用AdamW训练模型, 训练细节见👇图。
Result and Analysis
其中单个方法(single)对多个任务使用相同的prompt/low-rank weights,而多个方法(Multiple)对每个任务分别使用一个prompt/low-rank weights。
这些可以看上面的Shared-weight adapter。
The prompts 只加到encoder里,加在decoder里没有提升。
Single Adapter Performing the Best:信息共享有利于低资源任务。后续的分析可以在论文中看到不再赘述。在V&L中最佳效果是Single Adapter,还证明了Single Adapter和CLIP-ViL配合效果良好。
-
相关阅读:
Linux 文本处理命令 - umask
Nginx优化——VTS监控模块
「专升本信息技术」计算机基础知识单选题集(02)
Mybatis按年月日时分秒查询,MySQL年月日时分秒查询
计算机毕业设计Java家装行业门店订单管理系统(源码+系统+mysql数据库+lw文档)
低代码热潮下的冷思考:为何我们不能盲目追随
景联文科技:深度探究自动驾驶重要方向——车路协同
数据结构(C语言版)概念、数据类型、线性表
[Elastic-Job2.1.5源码]-11-基于Zookeeper分布式锁实现选举作业主节点原理
虚拟机双网卡设置(外网+内网)
- 原文地址:https://blog.csdn.net/yusude123456/article/details/132830386