-
C++ 11:多线程相关问题
目录
一. 线程类thread
1.1 thread的一些接口函数
接口函数 实现功能 thread() noexcept 默认构造函数,创建空线程 template
thread thread(Fn&& fn, Args&& ...args)
通过指定函数和传给函数的参数,来创建线程,其中fn为线程函数,fn的返回类型应为void,如果希望向线程函数中传递引用x,应当使用std::ref(x)来传参。 thread(thread&& th) 移动构造函数(线程类thread禁止拷贝构造) thread& operator=(thread&& th) 移动赋值函数(线程类thread禁止拷贝赋值) void join() 阻塞等待线程 void detach() 分离线程 代码1.1通过创建子线程的方式,使用线程函数对main函数作用域中的变量count进行100次++操作,join线程后输出此时count的值。注意,要在线程函数内部控制外部的变量,就要传引用,而向线程函数串引用必须通过std::ref()传参。
运行代码输出结果为count = 100,表明引用传参成功。
代码1.1:创建线程并向线程函数传递引用类型参数
- #include <iostream>
- #include <thread>
- void add(int& x)
- {
- for (int i = 0; i < 100; ++i)
- {
- ++x;
- }
- }
- int main()
- {
- int count = 0;
- // 创建线程,线程函数为add
- // std::ref(add)传递引用
- std::thread th(add, std::ref(count));
- th.join();
- std::cout << "count = " << count << std::endl;
- return 0;
- }
如代码1.2所示,我们还可以将线程函数以lambda表达式的格式来传递,lambda表达式可以很方便的以值或引用的方式捕捉父作用域的变量。
代码1.2:以lambda表达式的方式传递线程函数
- #include <iostream>
- #include <thread>
- int main()
- {
- int count = 0;
- std::thread th([&]() {
- for(int i = 0; i < 100; ++i)
- {
- ++count;
- }
- });
- th.join();
- std::cout << "count = " << count << std::endl;
- return 0;
- }
2.2 通过thread创建多线程
只要在主线程中,通过thread构造函数创建多个线程类对象,并且执行特定的线程函数,就能够创建出多线程场景,为了方便控制,我们先创建std::vector
注意:thread对象只能支持移动赋值,不支持拷贝赋值!
代码2.3:通过thread类创建多线程
- #include <iostream>
- #include <thread>
- #include <string>
- #include <vector>
- #include <Windows.h>
- const int g_thread_num = 4; // 子线程数
- // 线程函数
- void threadRoutine(std::string name)
- {
- while (true)
- {
- std::cout << name << std::endl;
- Sleep(1);
- }
- }
- int main()
- {
- std::vector<std::thread> vth(4);
- // 通过移动赋值创建子线程,执行threadRoutine函数
- for (int i = 0; i < g_thread_num; ++i)
- {
- std::string name("Thread ");
- name += std::to_string(i + 1);
- vth[i] = std::thread(threadRoutine, name); // 移动赋值
- }
- // 线程等待
- for (int i = 0; i < g_thread_num; ++i)
- {
- vth[i].join();
- }
- return 0;
- }
二. this_thread
C++标准库内定义命名空间std::this_thread,表2.1为其中包含的四个多线程相关的函数。
函数名称 函数功能 void yield() noexcept 让出时间片,CPU资源让给其他线程 thread::id get_id() 获取当前线程的线程id void sleep_for(chrono::duration
线程休眠特定时间 void sleep_until(chrono::time_points 线程休眠到指定时间 一般来说,极少使用sleep_until,而是使用sleep_for,sleep_for可以指定休眠时长的单位为:小时、分钟、秒、微秒、毫秒、纳秒等,图2.1为sleep_for支持的时长单位,代码2.1中演示了yield、sleep_for和get_id的使用方法。
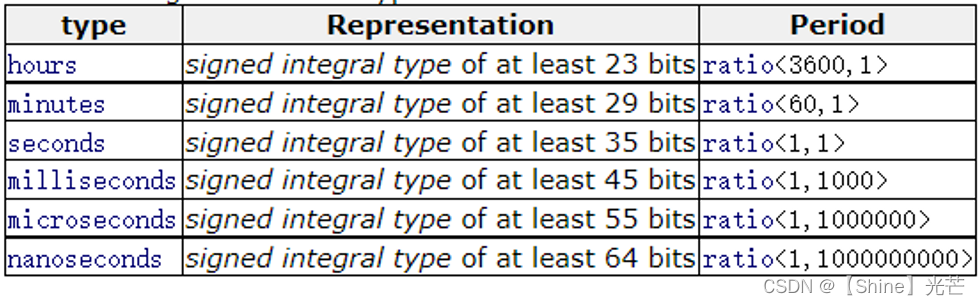
图2.1 sleep_for支持的时间单位 代码2.1:对this_thread中定义的函数的使用
- #include <iostream>
- #include <thread>
- #include <Windows.h>
- int main()
- {
- bool ready = false;
- std::thread th([&ready]() {
- // ready为false,该线程就让出时间片
- while (!ready)
- {
- std::this_thread::yield();
- }
- std::cout << "线程开始执行" << std::endl;
- // 线程休眠0.5秒(500微秒)
- std::this_thread::sleep_for(std::chrono::milliseconds(500));
- // 打印线程id
- std::cout << "Thread id: " << std::this_thread::get_id() << std::endl;
- });
- // 主线程先执行3秒,然后才更改ready为true,运行线程th获取时间片
- for (int i = 0; i < 3; ++i)
- {
- std::cout << "main thread" << std::endl;
- Sleep(1000);
- }
- ready = true;
- th.join();
- return 0;
- }
三. 互斥锁与原子操作
3.1 多线程中的加锁与解锁
加锁,是保证多线程场景下线程安全的一种手段,因为多个线程可能同时访问到临界资源,这就可能引发不可预料的结果。对访问临界资源的临界区代码加锁,就可以保证同一时刻只有一个线程的执行流进入临界区访问临界资源,从而保证线程安全。
代码3.1是一种典型的线程不安全的场景,共有4个线程对全局变量count执行++操作,每个线程执行10000次++,当四个线程都退出时,我们希望count的值变为40000,然而实际运行的结果确远小于40000,并且每次运行的结果各不相同,这就是由于多线程执行流同时访问临界资源而引发的线程不安全问题。加锁可以避免上面的问题。
代码3.1:多线程访问临界资源引发线程不安全问题
- #include <iostream>
- #include <thread>
- #include <vector>
- #include <Windows.h>
- int count = 0;
- int g_thread_num = 4;
- void add()
- {
- for (int i = 0; i < 10000; ++i)
- {
- ++count;
- }
- }
- int main()
- {
- std::vector<std::thread> vth(4);
- // 创建线程
- for (int i = 0; i < g_thread_num; ++i)
- {
- vth[i] = std::thread(add);
- }
- // 等待线程
- for (int i = 0; i < g_thread_num; ++i)
- {
- vth[i].join();
- }
- std::cout << "count = " << count << std::endl;
- return 0;
- }
3.1.1 mutex类
接口函数 功能 mutex() 默认构造函数 mutex(const mutex& mtx) = delete 禁止拷贝构造 void lock() 加锁 void unlock() 解锁 对于代码3.1,如果我们对访问临界资源的代码++count进行加锁操作,那么就限制了某一时刻只能有一个执行流执行++count操作,这样就保证了线程安全,运行结果一定是count = 40000。
代码3.2:对临界资源加锁
- #include <iostream>
- #include <thread>
- #include <vector>
- #include <mutex>
- int count = 0;
- int g_thread_num = 4;
- void add(std::mutex& mtx)
- {
- for (int i = 0; i < 10000; ++i)
- {
- mtx.lock(); // 加锁
- ++count;
- mtx.unlock(); // 解锁
- }
- }
- int main()
- {
- std::mutex mtx;
- std::vector<std::thread> vth(4);
- // 创建线程
- for (int i = 0; i < g_thread_num; ++i)
- {
- // 通过引用的方式,将互斥锁传递给线程函数
- vth[i] = std::thread(add, std::ref(mtx));
- }
- // 等待线程
- for (int i = 0; i < g_thread_num; ++i)
- {
- vth[i].join();
- }
- std::cout << "count = " << count << std::endl;
- return 0;
- }
3.1.2 lock_guard 类
原型:template
lock_guard { } 如果采用lock()、unlock()的加锁和解锁方式,在lock和unlock之间抛异常,或者忘记调用unlock解锁,那么都有可能出现锁无法释放,造成死锁、执行流阻塞的问题。而采用lock_guard则可以很好的避免上面的问题,lock_guard在构造的时候会自动加锁,在离开作用域的时候由编译器自动调用其析构函数解锁。
- lock_guard构造函数原型:explicit lock_guard(mutex_type& mtx)。
- lock_guard不允许拷贝构造:lock_guard(const lock_guard& lock) = delete。
代码3.3将代码3.2中的lock和unlock改为lock_guard的格式,来保证访问临界资源的安全性。
代码3.3:通过lock_guard实现加锁和解锁
- int count = 0;
- int g_thread_num = 4;
- void add(std::mutex& mtx)
- {
- for (int i = 0; i < 10000; ++i)
- {
- // 通过构造lock_guard类来加锁
- std::lock_guard<std::mutex> lock(mtx);
- ++count;
- } // 出作用域自动调用lock_guard的析构函数来解锁
- }
- int main()
- {
- std::mutex mtx;
- std::vector<std::thread> vth(4);
- // 创建线程
- for (int i = 0; i < g_thread_num; ++i)
- {
- // 通过引用的方式,将互斥锁传递给线程函数
- vth[i] = std::thread(add, std::ref(mtx));
- }
- // 等待线程
- for (int i = 0; i < g_thread_num; ++i)
- {
- vth[i].join();
- }
- std::cout << "count = " << count << std::endl;
- return 0;
- }
3.3 原子性操作
原理性操作的概念:某个操作只有两种状态,要么完成,要么还没开始,不存在完成一部分的中间状态。如果我们对临界资源访问或修改的操作是原子的,那么就是线程安全的。
C++内置atomic类,调用其接口函数,可以实现对指针或整型数据的原子性操作。
- 对于整型数据intergal,atomic可以原子的实现以下操作:+=、-=、&=、|=、^= 。
- 对于指针类型数据pointer,atomic可以原子的实现以下操作:+=、-= 。
- atomic还支持原子的实现operator++、operator--操作。
代码3.4在3.3的基础上继续进行修改,定义std::atomic
count = 0,这样线程函数中的++count就变为了原子性操作,也就保证了线程的安全性。如果线程函数中执行 count += val、count -= val等操作,也是线程安全的。 代码3.4:通过atomic实现原子性操作
- #include <iostream>
- #include <thread>
- #include <vector>
- #include <atomic>
- // 通过atmoic,让针对count的操作变为原子的
- std::atomic<int> count = 0;
- int g_thread_num = 4;
- void add()
- {
- for (int i = 0; i < 10000; ++i)
- {
- count++;
- }
- }
- int main()
- {
- std::vector<std::thread> vth(4);
- // 创建线程
- for (int i = 0; i < g_thread_num; ++i)
- {
- // 通过引用的方式,将互斥锁传递给线程函数
- vth[i] = std::thread(add);
- }
- // 等待线程
- for (int i = 0; i < g_thread_num; ++i)
- {
- vth[i].join();
- }
- std::cout << "count = " << count << std::endl;
- return 0;
- }
四. 条件变量
4.1 线程互斥的缺陷
如代码4.1所示,在多线程场景下,在线程函数中,仅仅是通过lock、unlock对临界区进行加锁和解锁,还要在临界区检查临界资源是否就绪,此时不加以其他限制,就可能存在这样的问题:(1). 单个函数频繁申请到锁,造成其他线程的饥饿问题。(2). 如果临界资源长时间不就绪,那么频繁的进行 加锁 -> 检测临界资源是否就绪 -> 解锁 操作,会造成线程资源的浪费。
为了解决代码4.1的问题,线程同步被引入,线程同步是指让多个线程按照特定的次序被调度以及访问临界资源,如果检测到临界资源不就绪,线程就挂起等待。通过控制条件变量的等待和唤醒,可以实现线程的同步。
代码4.1:存在缺陷的线程互斥代码
- #include <iostream>
- #include <thread>
- #include <mutex>
- #include <vector>
- #include <Windows.h>
- int count = 0;
- bool ready = false;
- const int g_thread_num = 4;
- void threadRoutine(std::mutex& mtx)
- {
- while (true)
- {
- // 通过lock_guard控制加锁解锁
- std::lock_guard<std::mutex> lock(mtx);
- if (ready) // 检查临界资源的就绪情况
- {
- ++count;
- std::cout << "[" << std::this_thread::get_id() << "]" << "count: " << count << std::endl;
- }
- std::this_thread::sleep_for(std::chrono::milliseconds(500));
- }
- }
- int main()
- {
- std::mutex mtx;
- std::vector<std::thread> vth(g_thread_num);
- // 创建线程
- for (int i = 0; i < g_thread_num; ++i)
- {
- vth[i] = std::thread(threadRoutine, std::ref(mtx));
- }
- Sleep(3000);
- ready = true; // 主线程休眠3s才让临界资源就绪
- // 等待线程
- for (int i = 0; i < g_thread_num; ++i)
- {
- vth[i].join();
- }
- return 0;
- }
4.2 condition_variable 实现线程同步
通过定义condition_variable对象,调用等待条件变量、唤醒条件变量等方法,可以控制线程按照指定顺序运行,同时避免频繁检查临界资源是否就绪造成线程资源的浪费。
表4.1 condition_variable的主要接口函数 函数原型 功能 conditional_variable( ) 默认构造函数 conditional_variable(const conditional_variable&) = delete 禁止拷贝构造 void wait(unique_lock & lck, predicate pred) 等待条件变量 void notify_one() 唤醒一个等待条件变量的线程 void notify_all() 唤醒等待条件变量的全部线程 其中,wait的底层实现为:while(!prev) { 等待条件变量... }
代码4.2创建了3个线程,通过检测主线程中定义的int ready的值,控制线程的等待条件变量和唤醒,来让线程运行的顺序为3、2、1,实现线程的同步。
代码4.2:通过条件变量控制线程运行的顺序
- #include <iostream>
- #include <thread>
- #include <mutex>
- #include <vector>
- #include <Windows.h>
- int main()
- {
- volatile int ready = 3;
- std::mutex mtx;
- std::condition_variable cv;
- // 线程1
- std::thread th1([&]() {
- while (true)
- {
- std::unique_lock<std::mutex> lock(mtx);
- // 检查临界资源是否就绪
- cv.wait(lock, [&ready]() { return ready == 1; });
- std::cout << "thread 1" << std::endl;
- ready = 3;
- std::this_thread::sleep_for(std::chrono::milliseconds(300));
- cv.notify_all(); // 唤醒一个线程
- }
- });
- std::thread th2([&]() {
- while (true)
- {
- std::unique_lock<std::mutex> lock(mtx);
- // 检查临界资源是否就绪
- cv.wait(lock, [&ready]() { return ready == 2; });
- std::cout << "thread 2" << std::endl;
- ready = 1;
- std::this_thread::sleep_for(std::chrono::milliseconds(300));
- cv.notify_all(); // 唤醒一个线程
- }
- });
- std::thread th3([&]() {
- while (true)
- {
- std::unique_lock<std::mutex> lock(mtx);
- // 检查临界资源是否就绪
- cv.wait(lock, [&ready]() { return ready == 3; });
- std::cout << "thread 3" << std::endl;
- ready = 2;
- std::this_thread::sleep_for(std::chrono::milliseconds(300));
- cv.notify_all(); // 唤醒一个线程
- }
- });
- th1.join();
- th2.join();
- th3.join();
- return 0;
- }
五. 单例模式的线程安全问题
5.1 饿汉模式的线程安全问题
饿汉模式,是指在程序开始运行(进入到main函数)之前,就创建好单例对象,饿汉模式的优点和缺点如下:
- 优点:(1). 实现和调用较为方便 (2). 更容易保证线程安全 -- 主要针对单例类实例化时的线程安全问题,如果涉及到临界资源的访问,还是要通过加锁的方式保证线程安全
- 缺点:(1). 单例类实例化,延缓软件启动速度 (2). 存在多个单例类时无法确定实例化顺序。
我们可以认为,如果我们仅考虑单例类对象本身的实例化,饿汉模式是线程安全的。
代码5.1:饿汉模式实现单例类
- class singleton
- {
- public:
- static singleton _inst; // 唯一一个实例化对象
- // 禁止拷贝和赋值
- singleton(const singleton& st) = delete;
- singleton& operator=(const singleton& st) = delete;
- private:
- // 构造函数
- singleton(int s = 10) : _s(s)
- { }
- int _s;
- };
- singleton singleton::_inst; // 实例化唯一一个类对象
5.2 懒汉模式的线程安全问题
懒汉模式,就是第一次使用单例对象时才实例化,懒汉模式的优缺点如下:
- 优点:(1). 不延缓软件的启动速度 (2). 如果有多个单例对象可以控制实例化的顺序
- 缺点:(1). 设计复杂 (2). 保证线程安全相对困难
一般来说,懒汉模式的实现方法是在singleton中定义指向singleton堆区对象的指针_ptr,初值设为nullptr并提供GetInstance函数获取指向单例对象的指针,第一次调用GetInstance会检测到_ptr为空指针,此时会new出一个singleton对象,那么我们可能会写出代码5.2,这并不是线程安全的!
如果有两个线程同时进入 if(ptr == nullptr) 内部,那么new singleton就会被调用两次,引发线程不安全问题。
代码5.2:线程不安全的懒汉单例模式
- #include
- class singleton
- {
- public:
- static singleton* GetInstance(int s = 10)
- {
- // 线程不安全
- // 如果多个线程同时进入if内部,则会实例化出多份singleton对象
- if (_pinst == nullptr)
- {
- _pinst = new singleton(s);
- }
- return _pinst;
- }
- int get_s() { return _s; }
- private:
- singleton(int s) // 构造函数私有化
- : _s(s)
- { }
- int _s;
- // 指向单例对象的指针,初值设为nullptr
- // 第一次调用后改变为指向堆区singleton单例对象的指针
- static singleton* _pinst;
- };
为了确保线程安全,我们必须对临界区代码(访问singleton *_pinst的代码)进行加锁,这样,我们就会写出如代码5.3所示的懒汉模式单例类,这个单例类在构造的时候是线程安全的。但是,这样的代码依旧存在缺陷,单例对象在创建成功后_pinst的值永远为nullptr,此时判断_pinst==nullptr是否成立是线程安全的,在if(_pinst == nullptr) { ... } 前后加锁解锁,会造成不必要的资源浪费。
代码5.3:能保证线程安全,但存在缺陷的懒汉单例模式
- #include <iostream>
- #include <mutex>
- class singleton
- {
- public:
- static singleton* GetInstance(int s = 10)
- {
- // 如果单例类已经创建,频繁加锁解锁会造成资源浪费
- _mtx.lock(); // 加锁
- if (_pinst == nullptr)
- {
- _pinst = new singleton(s);
- }
- _mtx.unlock();
- return _pinst;
- }
- int get_s() { return _s; }
- private:
- singleton(int s) // 构造函数私有化
- : _s(s)
- { }
- int _s;
- // 指向单例对象的指针,初值设为nullptr
- // 第一次调用后改变为指向堆区singleton单例对象的指针
- static singleton* _pinst;
- static std::mutex _mtx; // 互斥锁
- };
- singleton* singleton::_pinst = nullptr; // 静态成员初值设为空
- std::mutex singleton::_mtx; // 互斥锁初始化
代码5.4在5.3的基础上进一步修改,在GetInstance函数的执行流进入到了if(_pinst == nulptr) { ... }内部时,才进行加锁解锁,并在if内部加锁与解锁之间再次判断_pinst==nullptr是否成立,如果依旧成立,说明确实没有singleton对象被实例化出来,此时再new单例对象,并返回指向堆区单例对象的指针。
这样版的GetInstance函数内部执行双层if判断_pinst == nullptr是否成立,外层判断是为了保证有一个单例对象被创建出来,内层判断前后要进行加锁和解锁操作,为了确保在由多个执行流进入外层if的情况下不出现线程安全问题。
代码5.4:双重 if(_pinst == nullptr) 判断实现线程安全的懒汉单例模式
- #include <iostream>
- #include <mutex>
- class singleton
- {
- public:
- static singleton* GetInstance(int s = 10)
- {
- // 外层if确保有一个单例对象被实例化出来
- if (_pinst == nullptr)
- {
- // 内层if判断确保多执行流进入外层if时
- // 不会出现实例化出多个singleton对象的问题,以确保线程安全
- _mtx.lock();
- if (_pinst == nullptr)
- {
- _pinst = new singleton(s);
- }
- _mtx.unlock();
- }
- // 双层if判断,可以防止在GetInstance频繁被调用的场景下
- // 每次都进行加锁和解锁,造成线程资源的浪费
- return _pinst;
- }
- int get_s() { return _s; }
- private:
- singleton(int s) // 构造函数私有化
- : _s(s)
- { }
- int _s;
- // 指向单例对象的指针,初值设为nullptr
- // 第一次调用后改变为指向堆区singleton单例对象的指针
- static singleton* _pinst;
- static std::mutex _mtx; // 互斥锁
- };
- singleton* singleton::_pinst = nullptr; // 静态成员初值设为空
- std::mutex singleton::_mtx; // 互斥锁初始化
六. 智能指针的线程安全问题
以最常用的智能指针shared_ptr为例,shared_ptr允许多个RAII对象指向同一份资源,通过底层的引用计数器,来保证在没有shared_ptr对象指向内部资源时相关的资源可以被析构。
智能指针shared_ptr底层的引用计数器为共享资源,对于拷贝构造、赋值等需要访问引用计数器的相关操作,如不加锁,会引发线程不安全问题。代码6.1为线程安全版本的shared_ptr模拟实现,在使用引用计数器的时候,都会进行加锁和解锁处理。
注意:C++标准库中提供的shared_ptr保证拷贝构造和赋值是线程安全的,但是对于其所指向资源的访问和修改,需要用户自行加锁来保证线程安全。
代码6.2:线程安全的shared_ptr模拟实现
- #include <iostream>
- #include <mutex>
- #include <vector>
- namespace zhang
- {
- template<class T>
- class shared_ptr
- {
- public:
- // 构造函数
- shared_ptr(T* ptr = nullptr)
- : _ptr(ptr)
- , _pcount(new int(1))
- , _pmtx(new std::mutex)
- { }
- // 拷贝构造函数
- shared_ptr(const shared_ptr& sp)
- : _ptr(sp._ptr)
- , _pcount(sp._pcount)
- , _pmtx(sp._pmtx)
- {
- AddCount(); // 引用计数+1函数
- }
- // 赋值函数
- shared_ptr& operator=(const shared_ptr& sp)
- {
- // 排除自赋值
- if (sp._ptr != _ptr)
- {
- Release(); // 资源释放函数
- _pcount = sp._pcount;
- _ptr = sp._ptr;
- _pmtx = sp._pmtx;
- AddCount();
- }
- return *this;
- }
- // 析构函数
- ~shared_ptr()
- {
- Release();
- }
- T& operator*()
- {
- return *_ptr;
- }
- T* operator->()
- {
- return &(*_ptr);
- }
- private:
- void AddCount()
- {
- _pmtx->lock(); // 加锁
- ++(*_pcount);
- _pmtx->unlock();
- }
- void Release()
- {
- bool flag = false; // 标识是否还有智能指针指向资源
- _pmtx->lock();
- if (--(*_pcount) == 0)
- {
- delete _ptr;
- delete _pcount;
- flag = true;
- }
- _pmtx->unlock();
- if (flag) delete _pmtx;
- }
- T* _ptr;
- int* _pcount;
- std::mutex* _pmtx;
- };
- }
- int main()
- {
- zhang::shared_ptr<int> sp1(new int(2));
- zhang::shared_ptr<int> sp2(new int(4));
- std::cout << *sp1 << std::endl;
- std::cout << *sp2 << std::endl;
- sp2 = sp1;
- std::cout << *sp2 << std::endl;
- std::vector<std::thread> vth(10000);
- for (int i = 0; i < 10000; ++i)
- {
- vth[i] = std::thread([&]() {
- zhang::shared_ptr<int> sp(sp1);
- // std::cout << *sp << std::endl;
- });
- }
- for (int i = 0; i < 10000; ++i)
- {
- vth[i].join();
- }
- return 0;
- }
七. 总结
- C++ 11标准库提供thread类,通过创建thread类对象,可以创建多线程,thread不能支持拷贝构造和拷贝赋值,但可以支持移动构造和移动赋值。
- std::this_thread中提供了让出时间片、获取线程id以及线程休眠的相关接口。
- 多线程访问临界资源的场景下,需要加锁以保证临界资源的安全性,C++标准库提供mutex类,可以实现加锁和解锁。同时为了避免加锁和解锁之间因为异常安全性问题导致执行流没有运行到解锁的位置,C++标准库又提供了lock_guard类,lock_guard在构造阶段会加锁,在析构时会自动解锁。
- 通过控制多线程对同一个条件变量的等待和唤醒,可以实现线程间的同步执行。
- 用饿汉模式实现单例,一般可以保证线程安全。懒汉模式在获取单例对象的GetInstance函数中,需要使用双层if来判断,在保证线程安全的同时避免不必要的资源浪费。
- shared_ptr底层的引用计数器属于共享资源,在拷贝构造和赋值函数中,需要加锁以保证线程安全,C++标准库中提供的shared_ptr可以保证拷贝构造和赋值函数的线程安全,但是在访问指向的资源时,需要用户自行加锁解锁以保证线程安全。
-
相关阅读:
JVM(十) —— 运行时数据区之方法区(一)
被圈粉的微信小程序纯UI组件colorUi
nodeJs如何搭建http2 localhost环境?
第四篇章:运行时数据区——共享空间
MYSQL常用命令
(几何) 凸包问题
Linux驱动实践:带你一步一步编译内核驱动程序
uniapp:幸运大转盘demo
DecimalFormat的使用讲解数字格式化和demo(java小数控制,金额返回相关处理)
java-net-php-python-java机场航班调度管理系统计算机毕业设计程序
- 原文地址:https://blog.csdn.net/weixin_43908419/article/details/132736941
