-
linux内核源码分析之物理内存
目录
随机访问存储器
1、静态RAM SRAM
用于CPU高速缓存的L1Cache,L2Cache,L3Cache 访问周期 1-30个时钟周期,容量小,价高。
2、动态RAM DRAM
主存,访问周期 50-200个时钟周期,造价便宜,容量大。内核以页为单位对物理内存进行管理,每页大小4K ,使用struct page结构体来进行管理
内核为内个物理页定义了一个索引编号PFN(Page Frame Number)page_to_pfn与pfn_to_page完成PFN与物理页page结构之间的相互转换
node,内核使用struct pglist_data 表示用于管理连续物理内存的node节点
通过 arch_pfn_to_nid 可以根据物理页的PFN定位到物理页所在的Node
通过 page_to_nid 可以根据物理页page定义到page所在node
物理架构
从 CPU 角度看物理内存架构
一致性内存访问 SMP
CPU通过总线访问内存,随着数量增加,总线带宽成为瓶颈
非一致性内存访问 NUMA
CPU访问本地内存更快,不通过总线。访问其他节点的内存,根据距离远近,速度不同。在NUMA架构下,可控制CPU如何请求内存分配策略
MPOL_BIND 必须在绑定的节点进行内存分配,如果内存不足,则进行 swap MPOL_INTERLEAVE 本地节点和远程节点均可允许分配内存 MPOL_PREFERRED 优先在指定节点分配内存,当指定节点内存不足时,选择离指定节点最近的节点分配内存 MPOL_LOCAL (默认) 优先在本地节点分配,当本地节点内存不足时,可以在远程节点分配内存 API接口
- #include
- long set_mempolicy(int mode, const unsigned long *nodemask,
- unsigned long maxnode);
查看NUMA相关信息
numactl -H 查看NUMA的配置
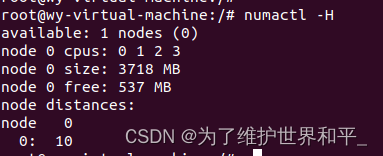
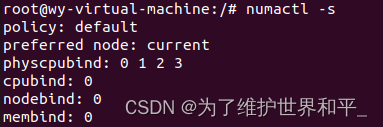
numactl -s查看NUMA的内存分配策略
numastat查看各个NUMA节点的内存访问命中率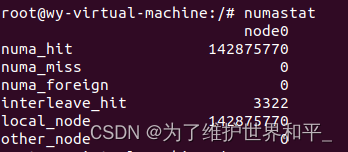
绑定NUMA节点
numactl 命令查看 ,指定应用程序运行在哪些CPU核心上,同时也可以绑定应用程序可以在哪些NUMA节点上分配内存。
numactl --membind=nodes --cpunodebind=nodes command
-membind 指定应用程序只能在哪些NUMA节点上分配内存,如果这些节点内存不足,则分配失败;
-cpunodebind 执行应用程序只能在哪些NUMA上运行-physcpubind将我们的应用程序绑定到具体的物理 CPU 上将进程 a.out绑定到 0~15 CPU 上执行
numactl --physcpubind= 0-15 ./a.out管理内存节点(node)
struct pglist_data 的全局数组node_data[] 来管理所有NUMA节点。
源码位置(arch/arm64/include/asm/mmzone.h)- #define CONFIG_NUMA
- extern struct pglist_data *node_data[];
- #define NODE_DATA(nid) (node_data[(nid)])
NODE_DATA(nid) 宏可以通过NUMA节点的node id 找到对应的struct pglist_data结构
- typedef struct pglist_data {
- // NUMA 节点id
- int node_id;
- // 指向 NUMA 节点内管理所有物理页 page 的数组
- struct page *node_mem_map;
- // NUMA 节点内第一个物理页的 pfn
- unsigned long node_start_pfn;
- // NUMA 节点内所有可用的物理页个数(不包含内存空洞)
- unsigned long node_present_pages;
- // NUMA 节点内所有的物理页个数(包含内存空洞)
- unsigned long node_spanned_pages;
- // 保证多进程可以并发安全的访问 NUMA 节点
- spinlock_t node_size_lock;
- }
node节点以及page数据结构之间关系
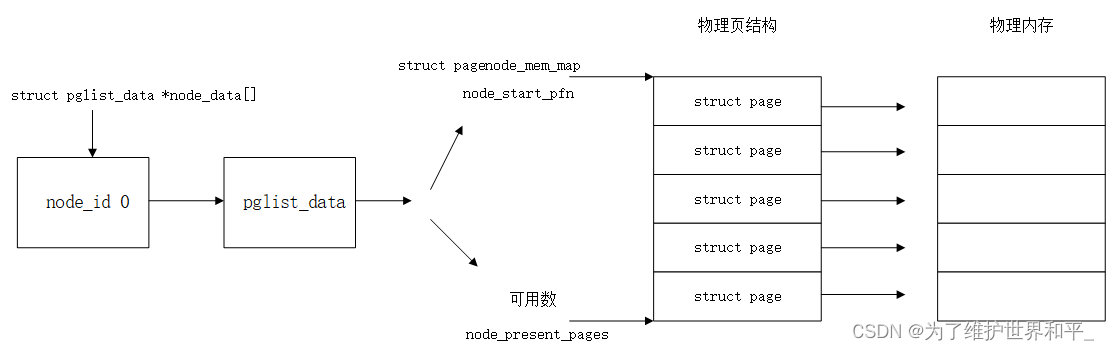
- node_mem_map 中包含了 NUMA节点内的所有的物理内存页
- node_start_pfn 指向 NUMA 节点内第一个物理页的 PFN
- node_present_pages 用于统计 NUMA 节点内所有真正可用的物理页面数量
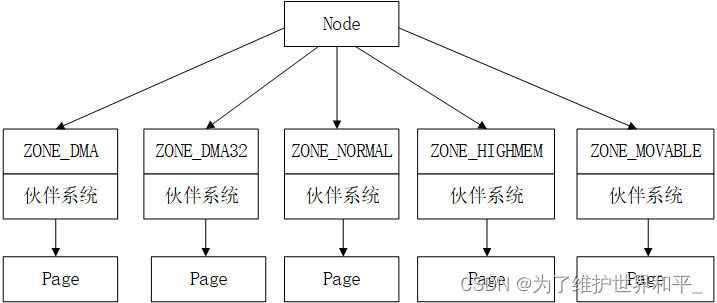
物理内存划分(zone)
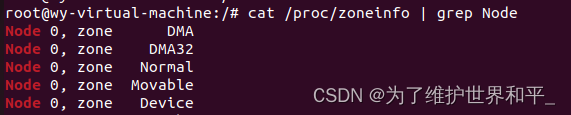
物理内存区域的功能不同,物理内存划分为
- ZONE_DMA DMA 时的内存分配
- ZONE_DMA32 该区域只在 64 位系统中起作用
- ZONE_NORMAL 物理页都可以直接映射到内核中的虚拟内存,线性映射,可直接访问
- ZONE_HIGHMEM 这些物理页需要动态映射进内核虚拟内存空间中
- ZONE_MOVABLE 是内核定义的一个虚拟内存区域,防止内存碎片和支持内存的热插拔
- ZONE_DEVICE 支持热插拔设备而分配的非易失性内存( Non Volatile Memory ),也可用于内核崩溃时保存相关的调试信息
- struct zone {
- // 防止并发访问该内存区域
- spinlock_t lock;
- // 内存区域名称:Normal ,DMA,HighMem
- const char *name;
- // 指向该内存区域所属的 NUMA 节点
- struct pglist_data *zone_pgdat;
- // 属于该内存区域中的第一个物理页 PFN
- unsigned long zone_start_pfn;
- // 该内存区域中所有的物理页个数(包含内存空洞)
- unsigned long spanned_pages;
- // 该内存区域所有可用的物理页个数(不包含内存空洞)
- unsigned long present_pages;
- // 被伙伴系统所管理的物理页数
- atomic_long_t managed_pages;
- // 伙伴系统的核心数据结构
- struct free_area free_area[MAX_ORDER];
- // 该内存区域内存使用的统计信息
- atomic_long_t vm_stat[NR_VM_ZONE_STAT_ITEMS];
- } ____cacheline_internodealigned_in_smp;
伙伴系统有个特点,所分配的物理内存页都是物理上连续的,并且只能分配2的整数幂个页(阶)
node ->zone->page物理内存页(page)
page(页)是linux内核管理物理内存的最小单位
alloc_page
alloc_pagesget_free_pages
get_zeroed_pagefree_page
分配的节点 gfp
#define ___GFP_DMA 0x01u
#define ___GFP_HIGHMEM 0x02u
#define ___GFP_DMA32 0x04u
#define ___GFP_MOVABLE 0x08u如果最高级内存区域不足时, 按照ZONE_HIGHMEM->ZONE_NORMAL->ZONE_DMA 依次降级申请。
内存分配行为
- GFP_ATOMIC 表示内存必须是原子的,最高优先级。任何情况下都不许睡眠,如果空闲内存不足则从紧急内存中分配。
适用于中断程序,以及持有自旋锁的进程上下文中。
- GFP_KERNEL 常用,内核分配内存可能阻塞睡眠,可以允许内核置换出一些不活跃的内存页到磁盘中。
适用于安全调度的进程上下文中。
- GFP_NOIO和GFP_NOFS 分别禁止内核在分配内存时进行磁盘IO和文件系统IO操作。
- GFP_USER 用于映射到用户空间的内存分配,通常这些内存可以被内核或者硬件直接访问,如硬件设备会将Buffer直接映射到用户空间中。
- GFP_DMA和GFP_DMA32 表示需要从NODE_DMA和NODE_DMA32内存区域申请适用于DMA的内存。
- GFP_HIGHUSER 给用户空间分配高端内存,因为在用户虚拟内存空间中,都是通过页表来访问非直接映射的高端内存区域,所有用户空间一般使用的是高端内存区ZONE_HIGHMEM
内存分配ALLOC*标志
- #define ALLOC_WMARK_MIN WMARK_MIN
- #define ALLOC_WMARK_LOW WMARK_LOW
- #define ALLOC_WMARK_HIGH WMARK_HIGH
- #define ALLOC_NO_WATERMARKS 0x04 /* don't check watermarks at all */
- #define ALLOC_HARDER 0x10 /* try to alloc harder */
- #define ALLOC_HIGH 0x20 /* __GFP_HIGH set */
- #define ALLOC_CPUSET 0x40 /* check for correct cpuset */
- #define ALLOC_KSWAPD 0x800 /* allow waking of kswapd, __GFP_KSWAPD_RECLAIM set */
- ALLOC_NO_WATERMARKS 表示在内存分配过程中,不考虑上述三个水位线的影响
- ALLOC_WMARK_HIGH ,表示当前物理内存区域zone中剩余内存页的数量至少要达到WMARK_HIGI水位线才能分配内存
- ALLOC_WMARK_LOW ,ALLOC_WMARK_MIN 表示当前物理内存区域zone中剩余内存页的数量至少要达到WMARK_LOW或者MIN才能分配。
- ALLOC_HARDER 表示分配内存时,放宽分配规则,就是降低WMARK_MIN水位线,努力使内存分配最大可能成功
- ALLOC_HIGH 需要设置__GFP_HIGH 才有效,表内存请求是最高优先级,表不允许失败,如果内存不足才紧急预留内存中分配。
- ALLOC_CPUSET 表示内存只能在当前进程所允许的CPU关联的NUMA节点中进行分配。比如cgroup限制进程只能在某些特定的CPU上运行,那么进程所发起的内存分配请求,只能在这些特定的NUMA节点中进行。
- ALLOC_KSWAPD表示允许唤醒NUMA节点中的KSWAPD进程,异步进行内存回收。内核为每个NUMA节点分配一个kswapd进程用于回收不经常使用的页面。
页面阈值
WMARK_MIN(页最小阈值), WMARK_LOW (页低阈值),WMARK_HIGH(页高阈值)。
- 当物理内存剩余容量高于_watermark[WMARK_HIGH]时,说明此物理内存充足
- 当剩余内存在WMARK_LOW,WMARK_HIGH]时,说明内存有消耗,能满足分配需求;
- 当剩余内存在WMARK_MIN,WMARK_LOW时,说明内存有压力,但能满足进程此时的内存分配要求,当给进程分配好后,会唤醒kswapd进程开始回收内存,直到剩余内存在WMARK_HIGI之上。
- 当剩余内存低于 WMARK_MIN时,说明此时的内存容量已经非常危险,直接回收内存;
内存紧张时
- 产生 OOM,将 OOM 优先级最高的进程干掉
- 内存回收,将不经常使用到的内存回收
- 内存规整,将可迁移的物理页面进行迁移规整,消除内存碎片。
文件页:物理内存页中的数据来自磁盘文件,当对文件读取时候,内核会根据局部性原理将读取磁盘数据缓存在page cache中,cacha page就是存放的文件页。再次读取时,从cache中读。
回收时,直接回收即可,再次读取时,从磁盘重新读取。但,文件页修改还没来得及回写到磁盘,此时的文件页是脏页,不能进行回收,需要将脏页回写到磁盘才能回收。
匿名页:背后没有一个磁盘作为数据源,数据时通过进程运行过程中产生,比如动态分配的堆内存。
回收时,都需要将匿名页中的数据先保存在磁盘中,然后再回收。当进程再次访问这块内存时,重新把数据从磁盘空间读到内存,这块磁盘空间是可以单独是swap分区或者是一个特殊的swap文件。匿名页的回收机制就是常看到的swap机制。
内核回收的是文件页还是匿名页
cat /proc/sys/vm/swappiness命令查看,swappiness 选项的取值范围为 0 到 100,默认为 60。
swappiness 用于表示 Swap 机制的积极程度,
数值越大,Swap 的积极程度越高,内核越倾向于回收匿名页。
数值越小,Swap 的积极程度越低。内核就越倾向于回收文件页。
内存分配流程
快速路径分配
get_page_from_freelist
慢速路径分配
__alloc_pages_slowpath
慢速路径初始化参数
retry_cpuset:
调整内存分配策略alloc_flags,采用更加激进方式
内存分配主要在允许的CPU相关联的NUMA节点上
内存水位线下调至WMARK_LOW
唤醒所有kswapd进程进行异步内存回收
触发直接内存整理direct_compact获取更多内存
retry:
进一步调整内存分配aloc_flags,使用更加激进的内存分配手段
在内存分配时忽略水位线
直接触发内存回收direct_reclaim
再次触发直接内存整理direct_compact
OOM机制
nopage:
以上仍然不能分配,如果设置__GFP_NOFAIL不允许失败,则不停重试以上分配过程
fail:
分配失败,输出经过信息。
got_pg
内存分配成功,返回新申请的内存块
return page;
direct_compact:
在页面回收时,把可移动的聚在一起,不可以移动的聚在一起,去碎片化,然后进行成块回收。
学习链接:
参考
https://course.0voice.com/v1/course/intro?courseId=2&agentId=0
-
相关阅读:
【三维重建】MobileR2L:轻量化移动端三维重建(CVPR2023)
vivado跑完发邮件
vue-cli创建项目的步骤
正则表达式验证和跨域postmessage
时间工具类-- LocalDateTimeUtil详解
Linux之history、tab、alias、命令执行顺序、管道符以及exit
[附源码]计算机毕业设计JAVA火车票预订系统2022
C++控制不同进制输出(二进制,八进制,十进制,十六进制)各种进制之间的转换
简单易懂的C++类的友元教程(friend)。全局函数做类友元,一个类做另一个类的友元,一个类中某个成员函数做友元。过程中顺序很重要哦。最后附有完整实现代码
100天精通Python(爬虫篇)——第47天:selenium自动化操作浏览器
- 原文地址:https://blog.csdn.net/WANGYONGZIXUE/article/details/132818238
