-
X2-VLM: All-In-One Pre-trained Model For Vision-Language Tasks论文笔记
1. Motivation
- CLIP这一类方法只能进行图片级别的视觉和文本对齐;
- 也有一些方法利用预训练的目标检测器进行目标级别的视觉和文本对齐,但是只能编码目标内部的特征,无法有效表达多目标上下文关联;
- 本文致力于进行多粒度(objects, regions, and images)的视觉文本对齐预训练任务;
2. 模型结构
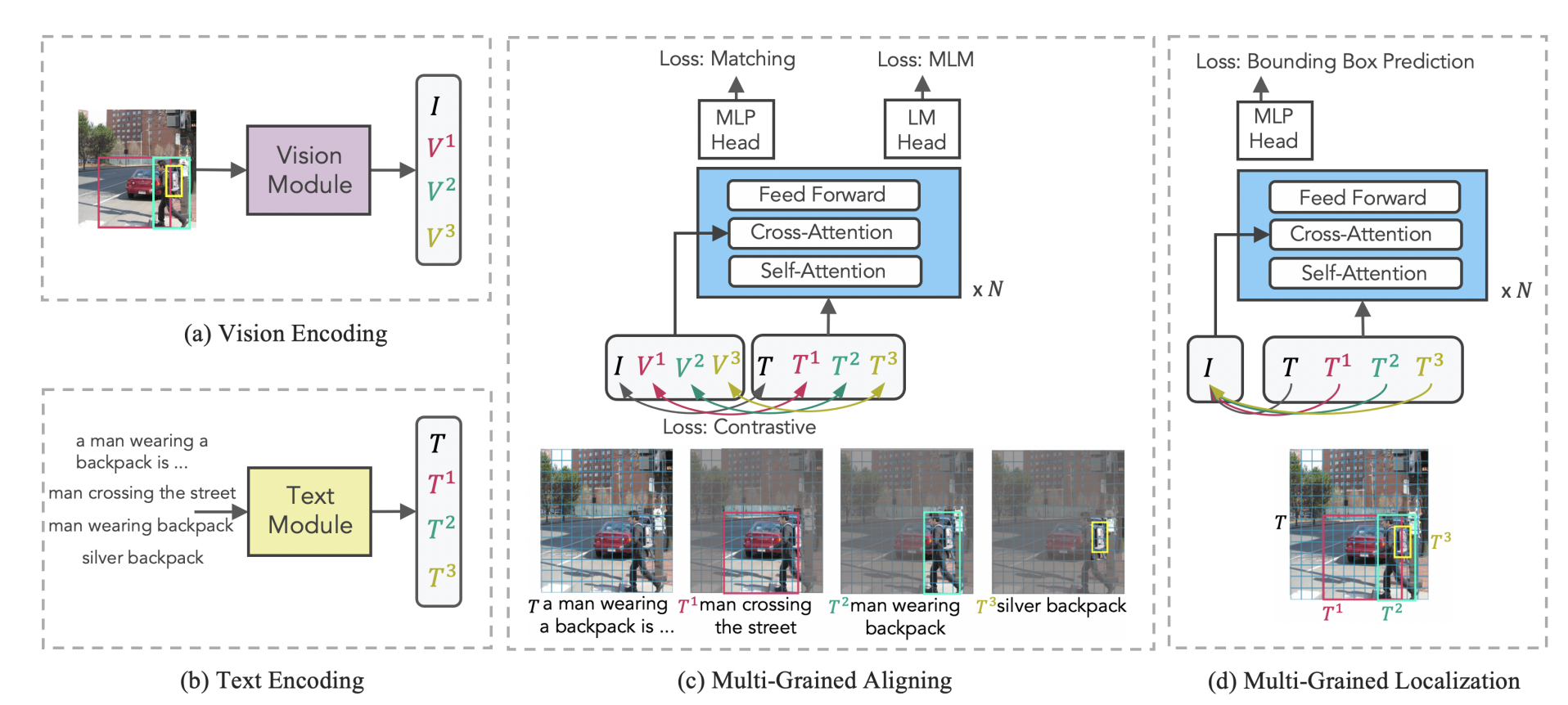
3. 损失函数
3.1 contrastive loss
- 文本特征和视觉特征之间的相似性定义:
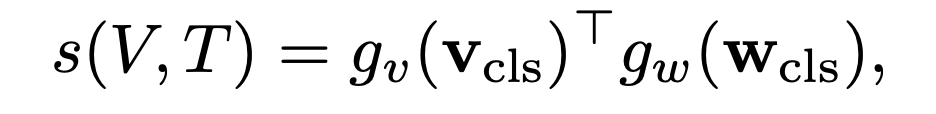
3. vision-to-text similarity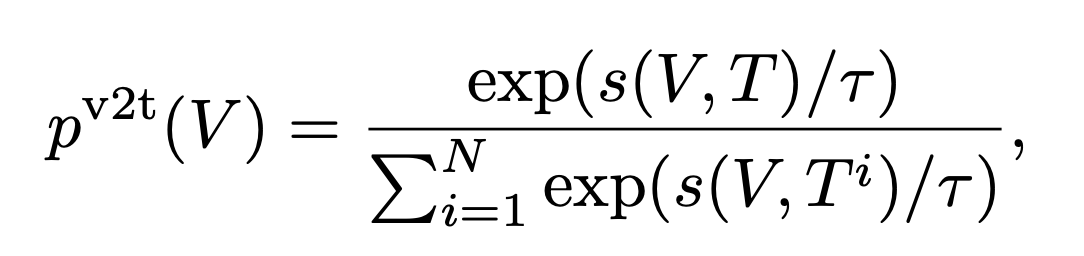
4. text-to-vision similarity
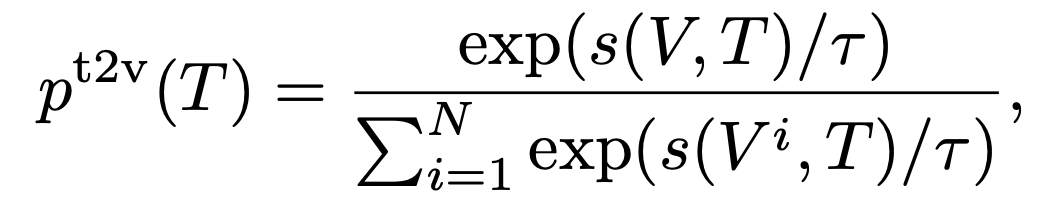
5. GT:one-hot
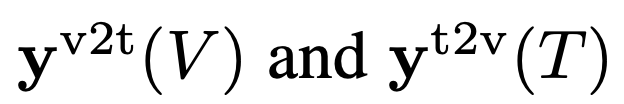
6. cross-entropy loss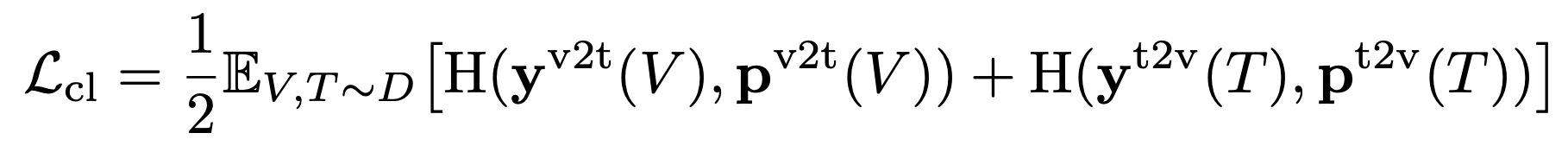
3.2 matching loss
- For each visual concept in a mini-batch, we sample an in-batch hard negative text by following p v 2 t ( V ) p^{v2t}(V) pv2t(V). (与当前视觉特征越接近的文本越可能被采样)
- We also sample one hard negative visual concept for each text.
- put the pairs as inputs for the fusion module, and then we use xcls, the output [CLS] embedding of the fusion module, to predict the matching probability
p
m
a
t
c
h
p^{match}
pmatch , and the loss is:
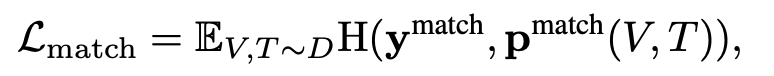
3.3 masked language modeling loss (MLM)

3.4 bbox loss

-
相关阅读:
新手入门丨一堆代码在报错,如何才能快速定位Bug?!
清华美院「后羿雕塑」像外国人,引全网争议.....
ORB-SLAM3算法学习—Frame构造—ORB特征提取和BRIEF描述子计算
「学习笔记」扫描线
Avalonia环境搭建
智能手表,不再只是手机品牌的“附属品”
Redis实现消息队列
探究WPF中文字模糊的问题:TextOptions的用法
包 类 包的作用域
Linux三级等保基本设置
- 原文地址:https://blog.csdn.net/xijuezhu8128/article/details/132809885