-
Redis——zset类型详解
概要
zset是有序集合,将zset中的members引入一个属性score,根据这个属性值来进行排序,其中members不可以重复,score可以重复(按照字典序排序),默认按照升序排序
有序集合中提供指定分数和元素范围查找,计算成员排名功能,一般用于排行榜系统
zset中的member和score并不是键值对的关系,而是pair,既可以通过member找到score,也可以通过score找到member

常用命令
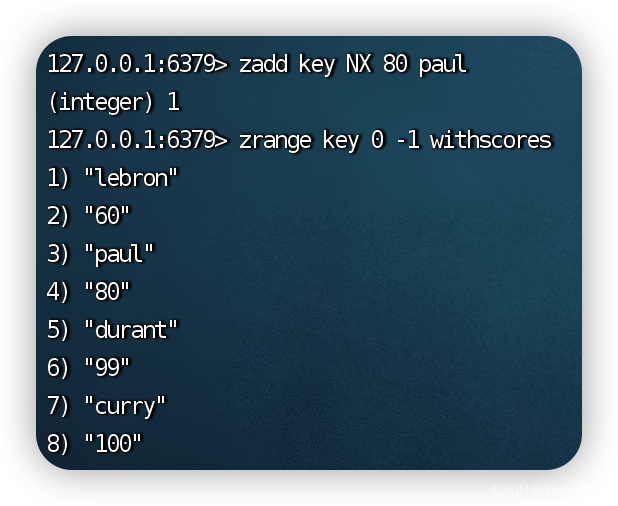
zadd
将元素和对应分数插入到有序集合中,时间复杂度O(logN),因为添加的元素要放到指定的位置上来保证有序,默认返回新增成功的元素个数

方括号中的内容是代表可选的选项选项 作用 XX 只更新已经存在的元素,不新插入元素 NX 只插入新的元素,不更新已经存在的元素 不加NX或XX 当前members不存在,则添加新元素,否则更新元素分数 LT 只更新已经存在的元素,并且新的分数比当前的分数小 GT 只更新已经存在的元素,并且新的分数比当前的分数大 CH 如果不添加CH选项,默认返回添加元素的个数,添加CH选项后,加上修改元素的个数 INCR 效果相同于ZINCRBY,将指定元素的score+=指定的值,返回值是更新后score的值 zrange
查看有序集合中指定下标范围的元素详情,从0开始,支持负数(-1就是最后一个元素)
时间复杂度O(log(N) + M),其中logN是根据下标找到边界值,M是遍历区间的开销

添加withscores,即可查看members对应的score示例

加入withscores:

修改操作:

NX选项:
添加不存在元素:
NX选项:
更新存在元素(不会生效):

XX选项:
更新存在元素的score:

XX选项:
更新不存在的元素的score(更新失败):

CH选项:

INCR操作:

zcard
获取指定key中元素个数,时间复杂度为O(1)

zcount
返回指定区间(前闭后闭)内的key中元素的个数,时间复杂度O(logN),(zset内部记录了每个元素的所在次序,logN的时间复杂度找到min和max,然后直接相减次序即可得到元素个数)
min和max支持使用浮点数,inf(无穷大),-inf(负无穷)

演示:

如果想要排除边界值可以加上括号

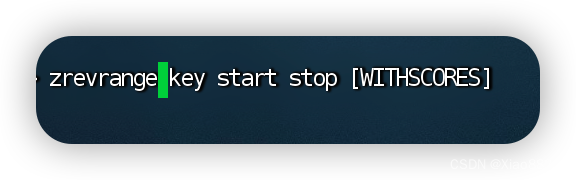
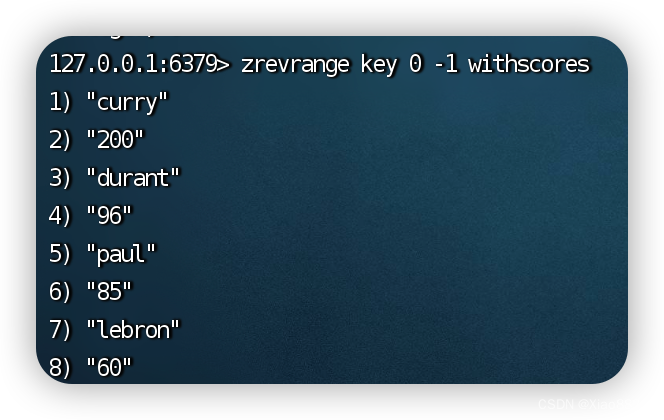
zrevrange
倒序获取指定范围内的元素
演示:
zrangebyscore
根据分数获取指定范围的元素,使用方法和zcount类似

演示:

zpopmax
删除并返回分数最高的count个元素
时间复杂度O(log(N) + M),N是有序集合中元素的个数,M是count的个数

演示:

如果存在score相同的多个元素,并且都是最大值,那么zpopmax仍然只删除其中的一个元素(按照字典序)

bzpopmax
阻塞版本的zpopmax,时间复杂度O(logN),如果传入多个key,只删除其中的一个

timeout是超时时间,表示最多阻塞多久,单位是秒,支持小数演示:
客户端a中的key有序集合中没有元素,进行bzpopmax命令,阻塞等待

客户端b插入元素:

此时,客户端a就可以拿到元素了

zpopmin
和zpopmax一致,删除有序集合中score最小的元素

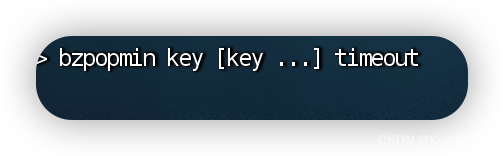
bzpopmin
和bzpopmax一致,阻塞删除有序集合中最小的元素
zrank
获取指定元素的排名,时间复杂度O(logN),member不存在返回nil

演示:

zrevrank
按照正序获取member排名

zscore
返回指定member的score,时间复杂度O(1)

zrem
删除有序集合中指定的member
时间复杂度O(log(N) * M),N是整个有序序列中元素的个数,M是要删除member的个数
返回删除成功的元素的个数

演示:

zremrangebyrank
根据指定排名范围删除member,前闭后闭,时间复杂度O(logN + M),N是整个集合的member个数,M是区间内的元素个数

演示:

zremrangebyscore
删除指定分数范围内的members,闭区间,可以使用(排除边界值,时间复杂度O(logN + M)

演示:

zincrby
自增指定的member对应的score,increment为指定自增大小,返回自增后score的大小,支持负数和小数

演示:

集合操作
操作 描述 zinter 获取两个集合的交集 zinterstore 获取两个集合的交集,将结果保存在另一个key中 zunion 获取两个集合的并集 zunionstore 获取两个集合的并集,将结果保存在另一个key中 zdiff 获取两个集合的差集 其中zinter, zunion, zdiff是Redis 6.2后支持的
zinterstore
语法格式:

参数名称 作用 destination 结果存储的集合名称 numkeys 几个有序集合参与运算 weights key所占的权重,可以写成小数,最后的总值就是score * 对应的权值 aggregate:sum,min,max 获取总和,最小值,最大值 之所以要有numkeys这个参数,是因为后面还有weight等若干参数,如果没有这个参数无法区分哪些是key哪些是参数
演示:

演示aggregate:

zinterstore的时间复杂度是O(N * K) + O(M * log(M))N是输入若干有序集合,里面最小的元素的个数
K是有几个有序集合参加运算
M是最终结果的有序集合的元素个数
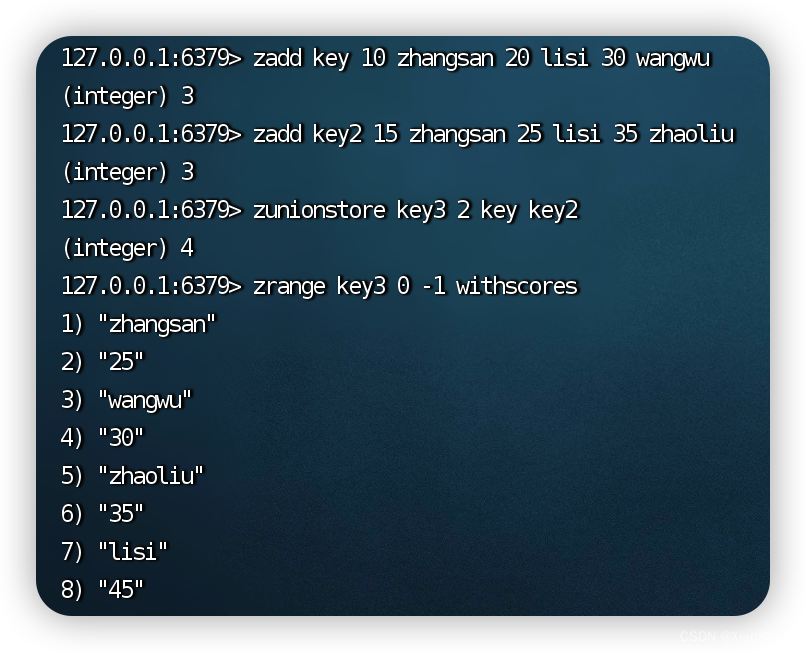
zunionstore
具体使用与参数和zinterstore类似

时间复杂度是O(N) + O(M * log(M))
N是全部元素的个数演示:

内部编码方式
情形 编码方式 有序集合中元素个数较少或单个元素提及较小 ziplist压缩列表 有序集合中元素个数较多或单个元素体积很大 skiplist跳表 
跳表是一种复杂的链表,里面的元素有多个指针,通过精妙的计算可以跳转到指定位置,查询元素的时间复杂度是O(log(N)),相比于树形结构,跳表更适合按照范围获取元素应用场景
由于Redis的有序列表中自带zrank等获取排名的操作,zincrby等修改score操作。并且根据score的变化,有序列表内部的排行也会变化,因此有序列表一般用来实现排行榜系统
并且,Redis中的zinterstore和zunionstore还支持权重,这对于需要权重来计算排名(例如微博)的场景非常方便
-
相关阅读:
力扣labuladong——一刷day06
红眼睛红外成像微型成像仪快速刷新与动态显示温度测量
docker基础
虚拟机扩容
Linux(八)——解压缩
GraphQL入门与开源的GraphQL引擎Hasura体验
【论文&模型讲解】多模态对话 Multimodal Dialogue Response Generation
改进YOLOv7 | 在 ELAN 模块中添加【Triplet】【SpatialGroupEnhance】【NAM】【S2】注意力机制 | 附详细结构图
【Linux】源码编译安装openssl
Vue3项目关于轮播图的封装应该怎么封装才是最简单的呢
- 原文地址:https://blog.csdn.net/m0_60867520/article/details/132805653