-
分布式系统第三讲:全局唯一ID实现方案
分布式系统第三讲:全局唯一ID实现方案
本文主要介绍常见的分布式ID生成方式,大致分类的话可以分为两类:一种是类DB型的,根据设置不同起始值和步长来实现趋势递增,需要考虑服务的容错性和可用性; 另一种是类snowflake型(白龙马、政采云),这种就是将64位划分为不同的段,每段代表不同的含义,基本就是时间戳、机器ID和序列数。这种方案就是需要考虑时钟回拨的问题以及做一些 buffer的缓冲设计提高性能。
文章目录
1、背景:为什么需要全局唯一ID?
传统的单体架构的时候,我们基本是单库然后业务单表的结构。每个业务表的ID一般我们都是从1增,通过AUTO_INCREMENT=1设置自增起始值,但是在分布式服务架构模式下分库分表的设计,使得多个库或多个表存储相同的业务数据。这种情况根据数据库的自增ID就会产生相同ID的情况,不能保证主键的唯一性。
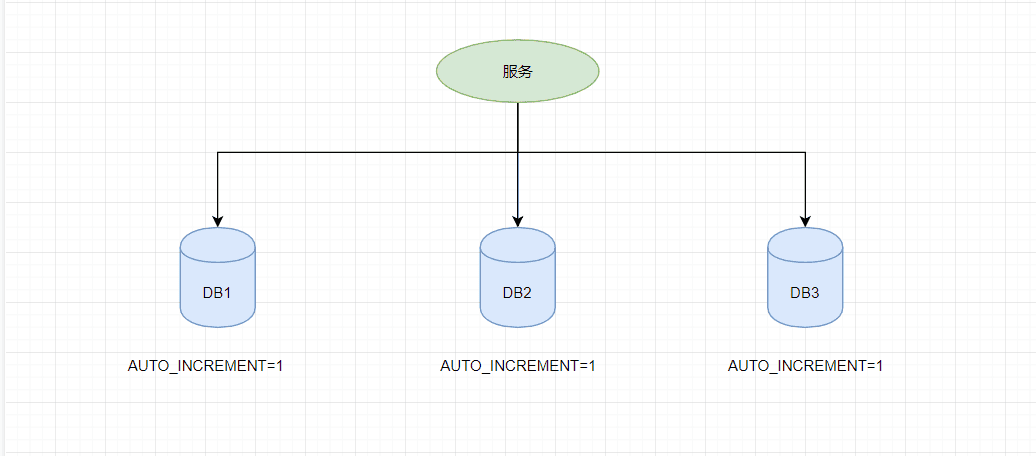
如上图,如果第一个订单存储在 DB1 上则订单 ID 为1,当一个新订单又入库了存储在 DB2 上订单 ID 也为1。我们系统的架构虽然是分布式的,但是在用户层应是无感知的,重复的订单主键显而易见是不被允许的。那么针对分布式系统如何做到主键唯一性呢?
项目中使用分库分表的场景?
1、商品表 数据量
-
商品主表 4亿一千万 数据容量:338.95GB 索引容量 275.09GB
分库分表键 主键id
-
商品属性表 分库键 item_id
-
商品详情表 分库键 item_id
-
商品sku表 11.3亿 数据容量:513.99GB 索引容量 381.02GB 分库键 item_id
-
商品扩展表 分库键 item_id
-
商品属性富文本表 分库键 item_id
2、审核库
3、操作日志库
2、UUID
UUID (Universally Unique Identifier),通用唯一识别码的缩写。UUID是由一组32位数的16进制数字所构成,所以UUID理论上的总数为16^32=2^128,约等于3.4 x 10^38。也就是说若每纳秒产生1兆个UUID,要花100亿年才会将所有UUID用完。生成的UUID是由 8-4-4-4-12格式的数据组成,其中32个字符和4个连字符’ - ',一般我们使用的时候会将连字符删除
uuid.toString().replaceAll("-","")。目前UUID的产生方式有5种版本,每个版本的算法不同,应用范围也不同。
基于时间的UUID- 版本1: 这个一般是通过当前时间,随机数,和本地Mac地址来计算出来,可以通过 org.apache.logging.log4j.core.util包中的 UuidUtil.getTimeBasedUuid()来使用或者其他包中工具。由于使用了MAC地址,因此能够确保唯一性,但是同时也暴露了MAC地址,私密性不够好。DCE安全的UUID- 版本2 DCE(Distributed Computing Environment)安全的UUID和基于时间的UUID算法相同,但会把时间戳的前4位置换为POSIX的UID或GID。这个版本的UUID在实际中较少用到。基于名字的UUID(MD5)- 版本3 基于名字的UUID通过计算名字和名字空间的MD5散列值得到。这个版本的UUID保证了:相同名字空间中不同名字生成的UUID的唯一性;不同名字空间中的UUID的唯一性;相同名字空间中相同名字的UUID重复生成是相同的。随机UUID- 版本4 根据随机数,或者伪随机数生成UUID。这种UUID产生重复的概率是可以计算出来的,但是重复的可能性可以忽略不计,因此该版本也是被经常使用的版本。JDK中使用的就是这个版本。基于名字的UUID(SHA1)- 版本5 和基于名字的UUID算法类似,只是散列值计算使用SHA1(Secure Hash Algorithm 1)算法。
我们 Java中 JDK自带的 UUID产生方式就是版本4根据随机数生成的 UUID 和版本3基于名字的 UUID,有兴趣的可以去看看它的源码。
public static void main(String[] args) { //获取一个版本4根据随机字节数组的UUID。 UUID uuid = UUID.randomUUID(); System.out.println(uuid.toString().replaceAll("-","")); //获取一个版本3(基于名称)根据指定的字节数组的UUID。 byte[] nbyte = {10, 20, 30}; UUID uuidFromBytes = UUID.nameUUIDFromBytes(nbyte); System.out.println(uuidFromBytes.toString().replaceAll("-","")); }- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
得到的UUID结果,
59f51e7ea5ca453bbfaf2c1579f09f1d 7f49b84d0bbc38e9a493718013baace6- 1
- 2
虽然 UUID 生成方便,本地生成没有网络消耗,但是使用起来也有一些缺点,
- 不易于存储:UUID太长,16字节128位,通常以36长度的字符串表示,很多场景不适用。
- 信息不安全:基于MAC地址生成UUID的算法可能会造成MAC地址泄露,暴露使用者的位置。
- 对MySQL索引不利:如果作为数据库主键,在InnoDB引擎下,UUID的无序性可能会引起数据位置频繁变动,严重影响性能,可以查阅 Mysql 索引原理 B+树的知识。
- MySQL第二讲:MySQL innoDB存储引擎中索引原理
- 车队订单生成批次id有用到
3、数据库生成
是不是一定要基于外界的条件才能满足分布式唯一ID的需求呢,我们能不能在我们分布式数据库的基础上获取我们需要的ID?
由于分布式数据库的起始自增值一样所以才会有冲突的情况发生,那么我们将分布式系统中数据库的同一个业务表的自增ID设计成不一样的起始值,然后设置固定的步长,步长的值即为分库的数量或分表的数量。
以MySQL举例,利用给字段设置
auto_increment_increment和auto_increment_offset来保证ID自增。auto_increment_offset:表示自增长字段从那个数开始,他的取值范围是1 … 65535。auto_increment_increment:表示自增长字段每次递增的量,其默认值是1,取值范围是1 … 65535。
假设有三台机器,则DB1中order表的起始ID值为1,DB2中order表的起始值为2,DB3中order表的起始值为3,它们自增的步长都为3,则它们的ID生成范围如下图所示:
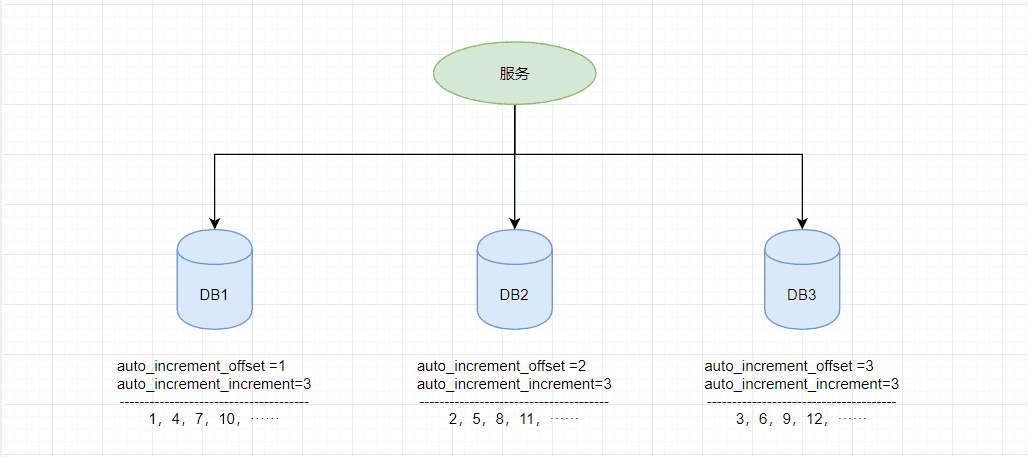
通过这种方式明显的优势就是依赖于数据库自身不需要其他资源,并且ID号单调自增,可以实现一些对ID有特殊要求的业务。
但是缺点也很明显,首先它强依赖DB,当DB异常时整个系统不可用。虽然配置主从复制可以尽可能的增加可用性,但是数据一致性在特殊情况下难以保证。主从切换时的不一致可能会导致重复发号。还有就是ID发号性能瓶颈限制在单台MySQL的读写性能。
使用场景
- 使用发号器生成账单编号
- 详见spring-boot-starter-sequence SDK,待整理
4、使用Redis实现
Redis实现分布式唯一ID主要是通过提供像
INCR和INCRBY这样的自增原子命令,由于Redis自身的单线程的特点所以能保证生成的 ID 肯定是唯一有序的。但是单机存在性能瓶颈,无法满足高并发的业务需求,所以可以采用集群的方式来实现。集群的方式又会涉及到和数据库集群同样的问题,所以也需要设置分段和步长来实现。
为了避免长期自增后数字过大可以通过与当前时间戳组合起来使用,另外为了保证并发和业务多线程的问题可以采用 Redis + Lua的方式进行编码,保证安全。
Redis 实现分布式全局唯一ID,它的性能比较高,生成的数据是有序的,对排序业务有利,但是同样它依赖于redis,需要系统引进redis组件,增加了系统的配置复杂性。
当然现在Redis的使用性很普遍,所以如果其他业务已经引进了Redis集群,则可以资源利用 考虑使用Redis来实现。
Action:Redis是单线程的吗?
常见面试题
5、雪花算法-Snowflake
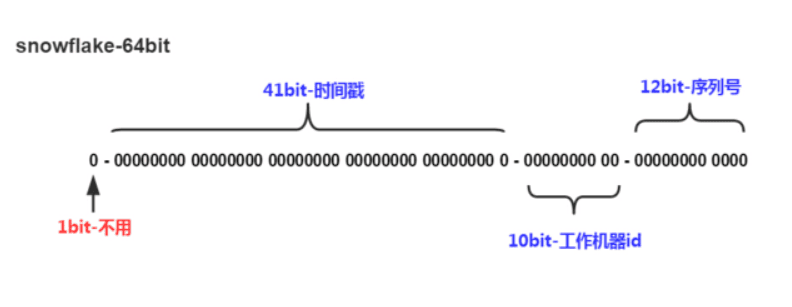
Snowflake,雪花算法是由Twitter开源的分布式ID生成算法,以划分命名空间的方式将 64-bit位分割成多个部分,每个部分代表不同的含义。而 Java中64bit的整数是Long类型,所以在 Java 中 SnowFlake 算法生成的 ID 就是 long 来存储的。
- 第1位占用1bit,其值始终是0,可看做是符号位不使用。
- 第2位开始的41位是时间戳,41-bit位可表示2^41个数,每个数代表毫秒,那么雪花算法可用的时间年限是
(1L<<41)/(1000L360024*365)=69 年的时间。 - 中间的10-bit位可表示机器数,即2^10 = 1024台机器,但是一般情况下我们不会部署这么台机器。如果我们对IDC(互联网数据中心)有需求,还可以将 10-bit 分 5-bit 给 IDC,分5-bit给工作机器。这样就可以表示32个IDC,每个IDC下可以有32台机器,具体的划分可以根据自身需求定义。
- 最后12-bit位是自增序列,可表示2^12 = 4096个数。
这样的划分之后相当于在一毫秒一个数据中心的一台机器上可产生4096个有序的不重复的ID。但是我们 IDC 和机器数肯定不止一个,所以毫秒内能生成的有序ID数是翻倍的。
Snowflake 的Twitter官方原版是用Scala写的,对Scala语言有研究的同学可以去阅读下,以下是 Java 版本的写法。
package com.jajian.demo.distribute; /** * Twitter_Snowflake
* SnowFlake的结构如下(每部分用-分开):
* 0 - 0000000000 0000000000 0000000000 0000000000 0 - 00000 - 00000 - 000000000000
* 1位标识,由于long基本类型在Java中是带符号的,最高位是符号位,正数是0,负数是1,所以id一般是正数,最高位是0
* 41位时间截(毫秒级),注意,41位时间截不是存储当前时间的时间截,而是存储时间截的差值(当前时间截 - 开始时间截) * 得到的值),这里的的开始时间截,一般是我们的id生成器开始使用的时间,由我们程序来指定的(如下下面程序IdWorker类的startTime属性)。41位的时间截,可以使用69年,年T = (1L << 41) / (1000L * 60 * 60 * 24 * 365) = 69
* 10位的数据机器位,可以部署在1024个节点,包括5位datacenterId和5位workerId
* 12位序列,毫秒内的计数,12位的计数顺序号支持每个节点每毫秒(同一机器,同一时间截)产生4096个ID序号
* 加起来刚好64位,为一个Long型。
* SnowFlake的优点是,整体上按照时间自增排序,并且整个分布式系统内不会产生ID碰撞(由数据中心ID和机器ID作区分),并且效率较高,经测试,SnowFlake每秒能够产生26万ID左右。 */ public class SnowflakeDistributeId { // ==============================Fields=========================================== /** * 开始时间截 (2015-01-01) */ private final long twepoch = 1420041600000L; /** * 机器id所占的位数 */ private final long workerIdBits = 5L; /** * 数据标识id所占的位数 */ private final long datacenterIdBits = 5L; /** * 支持的最大机器id,结果是31 (这个移位算法可以很快的计算出几位二进制数所能表示的最大十进制数) */ private final long maxWorkerId = -1L ^ (-1L << workerIdBits); /** * 支持的最大数据标识id,结果是31 */ private final long maxDatacenterId = -1L ^ (-1L << datacenterIdBits); /** * 序列在id中占的位数 */ private final long sequenceBits = 12L; /** * 机器ID向左移12位 */ private final long workerIdShift = sequenceBits; /** * 数据标识id向左移17位(12+5) */ private final long datacenterIdShift = sequenceBits + workerIdBits; /** * 时间截向左移22位(5+5+12) */ private final long timestampLeftShift = sequenceBits + workerIdBits + datacenterIdBits; /** * 生成序列的掩码,这里为4095 (0b111111111111=0xfff=4095) */ private final long sequenceMask = -1L ^ (-1L << sequenceBits); /** * 工作机器ID(0~31) */ private long workerId; /** * 数据中心ID(0~31) */ private long datacenterId; /** * 毫秒内序列(0~4095) */ private long sequence = 0L; /** * 上次生成ID的时间截 */ private long lastTimestamp = -1L; //==============================Constructors===================================== /** * 构造函数 * * @param workerId 工作ID (0~31) * @param datacenterId 数据中心ID (0~31) */ public SnowflakeDistributeId(long workerId, long datacenterId) { if (workerId > maxWorkerId || workerId < 0) { throw new IllegalArgumentException(String.format("worker Id can't be greater than %d or less than 0", maxWorkerId)); } if (datacenterId > maxDatacenterId || datacenterId < 0) { throw new IllegalArgumentException(String.format("datacenter Id can't be greater than %d or less than 0", maxDatacenterId)); } this.workerId = workerId; this.datacenterId = datacenterId; } // ==============================Methods========================================== /** * 获得下一个ID (该方法是线程安全的) * * @return SnowflakeId */ public synchronized long nextId() { long timestamp = timeGen(); //如果当前时间小于上一次ID生成的时间戳,说明系统时钟回退过这个时候应当抛出异常 if (timestamp < lastTimestamp) { throw new RuntimeException( String.format("Clock moved backwards. Refusing to generate id for %d milliseconds", lastTimestamp - timestamp)); } //如果是同一时间生成的,则进行毫秒内序列 if (lastTimestamp == timestamp) { sequence = (sequence + 1) & sequenceMask; //毫秒内序列溢出 if (sequence == 0) { //阻塞到下一个毫秒,获得新的时间戳 timestamp = tilNextMillis(lastTimestamp); } } //时间戳改变,毫秒内序列重置 else { sequence = 0L; } //上次生成ID的时间截 lastTimestamp = timestamp; //移位并通过或运算拼到一起组成64位的ID return ((timestamp - twepoch) << timestampLeftShift) // | (datacenterId << datacenterIdShift) // | (workerId << workerIdShift) // | sequence; } /** * 阻塞到下一个毫秒,直到获得新的时间戳 * * @param lastTimestamp 上次生成ID的时间截 * @return 当前时间戳 */ protected long tilNextMillis(long lastTimestamp) { long timestamp = timeGen(); while (timestamp <= lastTimestamp) { timestamp = timeGen(); } return timestamp; } /** * 返回以毫秒为单位的当前时间 * * @return 当前时间(毫秒) */ protected long timeGen() { return System.currentTimeMillis(); } }- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 61
- 62
- 63
- 64
- 65
- 66
- 67
- 68
- 69
- 70
- 71
- 72
- 73
- 74
- 75
- 76
- 77
- 78
- 79
- 80
- 81
- 82
- 83
- 84
- 85
- 86
- 87
- 88
- 89
- 90
- 91
- 92
- 93
- 94
- 95
- 96
- 97
- 98
- 99
- 100
- 101
- 102
- 103
- 104
- 105
- 106
- 107
- 108
- 109
- 110
- 111
- 112
- 113
- 114
- 115
- 116
- 117
- 118
- 119
- 120
- 121
- 122
- 123
- 124
- 125
- 126
- 127
- 128
- 129
- 130
- 131
- 132
- 133
- 134
- 135
- 136
- 137
- 138
- 139
- 140
- 141
- 142
- 143
- 144
- 145
- 146
- 147
- 148
- 149
- 150
- 151
- 152
- 153
- 154
- 155
- 156
- 157
- 158
- 159
- 160
- 161
- 162
- 163
- 164
- 165
- 166
- 167
- 168
- 169
- 170
测试的代码如下
public static void main(String[] args) { SnowflakeDistributeId idWorker = new SnowflakeDistributeId(0, 0); for (int i = 0; i < 1000; i++) { long id = idWorker.nextId(); // System.out.println(Long.toBinaryString(id)); System.out.println(id); } }- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
雪花算法提供了一个很好的设计思想,雪花算法生成的ID是趋势递增,不依赖数据库等第三方系统,以服务的方式部署,稳定性更高,生成ID的性能也是非常高的,而且可以根据自身业务特性分配bit位,非常灵活。
但是雪花算法强依赖机器时钟,如果机器上时钟回拨,会导致发号重复或者服务会处于不可用状态。如果恰巧回退前生成过一些ID,而时间回退后,生成的ID就有可能重复。官方对于此并没有给出解决方案,而是简单的抛错处理,这样会造成在时间被追回之前的这段时间服务不可用。
很多其他类雪花算法也是在此思想上的设计然后改进规避它的缺陷,后面介绍的
百度 UidGenerator和美团分布式ID生成系统 Leaf中snowflake模式都是在 snowflake 的基础上演进出来的。使用场景
- 生成商品id
6、百度-UidGenerator
百度的
UidGenerator是百度开源基于Java语言实现的唯一ID生成器,是在雪花算法 snowflake 的基础上做了一些改进。UidGenerator以组件形式工作在应用项目中,支持自定义workerId位数和初始化策略,适用于docker等虚拟化环境下实例自动重启、漂移等场景。在实现上,UidGenerator 提供了两种生成唯一ID方式,分别是
DefaultUidGenerator和CachedUidGenerator,官方建议如果有性能考虑的话使用CachedUidGenerator方式实现。UidGenerator依然是以划分命名空间的方式将 64-bit位分割成多个部分,只不过它的默认划分方式有别于雪花算法 snowflake。它默认是由1-28-22-13的格式进行划分。可根据你的业务的情况和特点,自己调整各个字段占用的位数。- 第1位仍然占用1bit,其值始终是0。
- 第2位开始的28位是时间戳,28-bit位可表示2^28个数,这里不再是以毫秒而是以秒为单位,每个数代表秒则可用
(1L<<28)/ (360024365) ≈ 8.51年的时间。 - 中间的 workId (数据中心+工作机器,可以其他组成方式)则由 22-bit位组成,可表示 2^22 = 4194304个工作ID。
- 最后由13-bit位构成自增序列,可表示2^13 = 8192个数。

其中 workId (机器 id),最多可支持约420w次机器启动。内置实现为在启动时由数据库分配(表名为 WORKER_NODE),默认分配策略为用后即弃,后续可提供复用策略。
DROP TABLE IF EXISTS WORKER_NODE; CREATE TABLE WORKER_NODE ( ID BIGINT NOT NULL AUTO_INCREMENT COMMENT 'auto increment id', HOST_NAME VARCHAR(64) NOT NULL COMMENT 'host name', PORT VARCHAR(64) NOT NULL COMMENT 'port', TYPE INT NOT NULL COMMENT 'node type: ACTUAL or CONTAINER', LAUNCH_DATE DATE NOT NULL COMMENT 'launch date', MODIFIED TIMESTAMP NOT NULL COMMENT 'modified time', CREATED TIMESTAMP NOT NULL COMMENT 'created time', PRIMARY KEY(ID) ) COMMENT='DB WorkerID Assigner for UID Generator',ENGINE = INNODB;- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
6.1、DefaultUidGenerator 实现
DefaultUidGenerator就是正常的根据时间戳和机器位还有序列号的生成方式,和雪花算法很相似,对于时钟回拨也只是抛异常处理。仅有一些不同,如以秒为为单位而不再是毫秒和支持Docker等虚拟化环境。protected synchronized long nextId() { long currentSecond = getCurrentSecond(); // Clock moved backwards, refuse to generate uid if (currentSecond < lastSecond) { long refusedSeconds = lastSecond - currentSecond; throw new UidGenerateException("Clock moved backwards. Refusing for %d seconds", refusedSeconds); } // At the same second, increase sequence if (currentSecond == lastSecond) { sequence = (sequence + 1) & bitsAllocator.getMaxSequence(); // Exceed the max sequence, we wait the next second to generate uid if (sequence == 0) { currentSecond = getNextSecond(lastSecond); } // At the different second, sequence restart from zero } else { sequence = 0L; } lastSecond = currentSecond; // Allocate bits for UID return bitsAllocator.allocate(currentSecond - epochSeconds, workerId, sequence); }- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
如果你要使用 DefaultUidGenerator 的实现方式的话,以上划分的占用位数可通过 spring 进行参数配置。
<bean id="defaultUidGenerator" class="com.baidu.fsg.uid.impl.DefaultUidGenerator" lazy-init="false"> <property name="workerIdAssigner" ref="disposableWorkerIdAssigner"/> <property name="timeBits" value="29"/> <property name="workerBits" value="21"/> <property name="seqBits" value="13"/> <property name="epochStr" value="2016-09-20"/> bean>- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
6.2、CachedUidGenerator 实现
而官方建议的性能较高的
CachedUidGenerator生成方式,是使用 RingBuffer 缓存生成的id。数组每个元素成为一个slot。RingBuffer容量,默认为Snowflake算法中sequence最大值(2^13 = 8192)。可通过 boostPower 配置进行扩容,以提高 RingBuffer 读写吞吐量。Tail指针、Cursor指针用于环形数组上读写slot:
- Tail指针 表示Producer生产的最大序号(此序号从0开始,持续递增)。Tail不能超过Cursor,即生产者不能覆盖未消费的slot。当Tail已赶上curosr,此时可通过 rejectedPutBufferHandler 指定PutRejectPolicy
- Cursor指针 表示Consumer消费到的最小序号(序号序列与Producer序列相同)。Cursor不能超过Tail,即不能消费未生产的slot。当Cursor已赶上tail,此时可通过rejectedTakeBufferHandler指定 TakeRejectPolicy
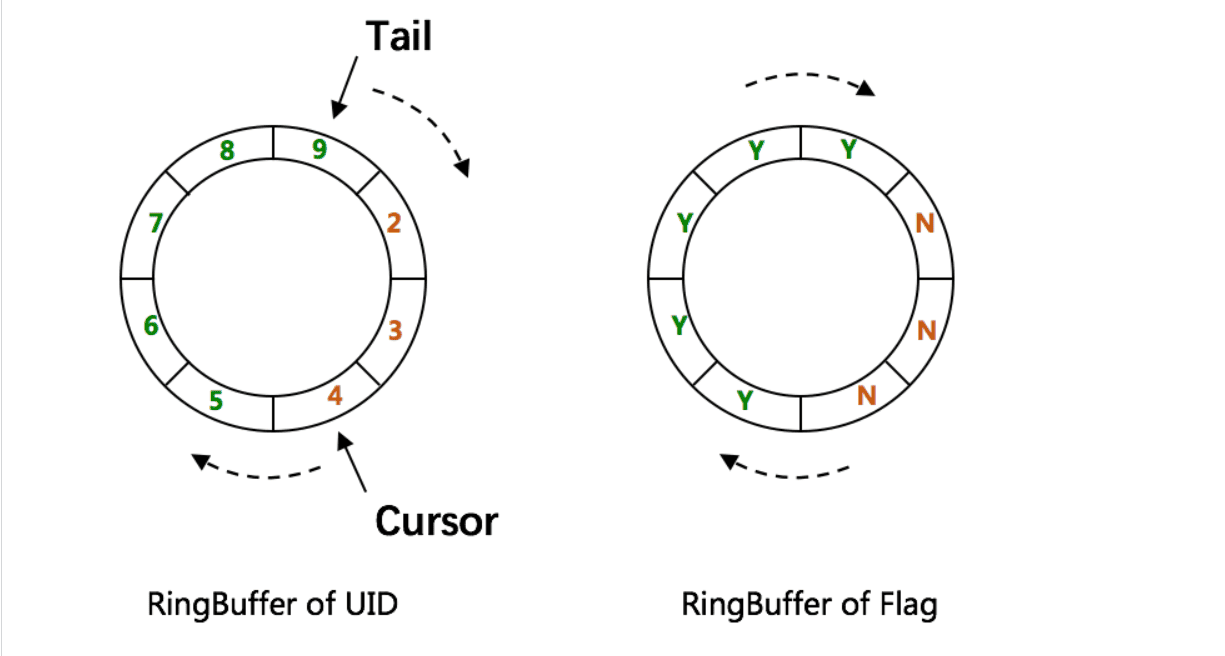
CachedUidGenerator采用了双RingBuffer,Uid-RingBuffer用于存储Uid、Flag-RingBuffer用于存储Uid状态(是否可填充、是否可消费)。
由于数组元素在内存中是连续分配的,可最大程度利用CPU cache以提升性能。但同时会带来「伪共享」FalseSharing问题,为此在Tail、Cursor指针、Flag-RingBuffer中采用了CacheLine 补齐方式。
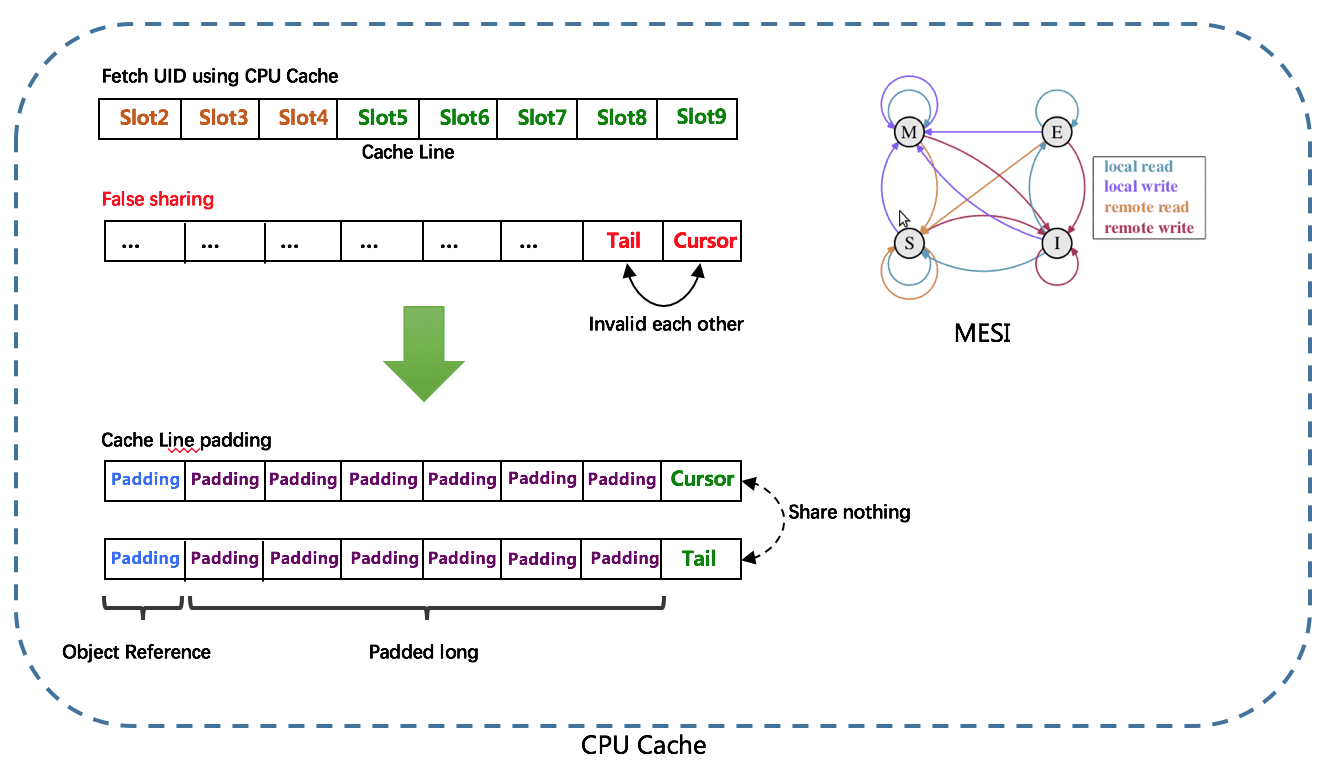
RingBuffer填充时机
- 初始化预填充 RingBuffer初始化时,预先填充满整个RingBuffer。
- 即时填充 Take消费时,即时检查剩余可用slot量(tail - cursor),如小于设定阈值,则补全空闲slots。阈值可通过paddingFactor来进行配置,请参考Quick Start中CachedUidGenerator配置。
- 周期填充 通过Schedule线程,定时补全空闲slots。可通过scheduleInterval配置,以应用定时填充功能,并指定Schedule时间间隔。
7、美团Leaf
Leaf是美团基础研发平台推出的一个分布式ID生成服务,名字取自德国哲学家、数学家莱布尼茨的著名的一句话:“There are no two identical leaves in the world”,世间不可能存在两片相同的叶子。
Leaf 也提供了两种ID生成的方式,分别是
Leaf-segment 数据库方案和Leaf-snowflake 方案。7.1、Leaf-segment 数据库方案
Leaf-segment 数据库方案,是在上文描述的在使用数据库的方案上,做了如下改变:
- 原方案每次获取ID都得读写一次数据库,造成数据库压力大。改为利用proxy server批量获取,每次获取一个segment(step决定大小)号段的值。用完之后再去数据库获取新的号段,可以大大的减轻数据库的压力。
- 各个业务不同的发号需求用
biz_tag字段来区分,每个biz-tag的ID获取相互隔离,互不影响。如果以后有性能需求需要对数据库扩容,不需要上述描述的复杂的扩容操作,只需要对biz_tag分库分表就行。
数据库表设计如下:
CREATE TABLE `leaf_alloc` ( `biz_tag` varchar(128) NOT NULL DEFAULT '' COMMENT '业务key', `max_id` bigint(20) NOT NULL DEFAULT '1' COMMENT '当前已经分配了的最大id', `step` int(11) NOT NULL COMMENT '初始步长,也是动态调整的最小步长', `description` varchar(256) DEFAULT NULL COMMENT '业务key的描述', `update_time` timestamp NOT NULL DEFAULT CURRENT_TIMESTAMP ON UPDATE CURRENT_TIMESTAMP COMMENT '更新时间', PRIMARY KEY (`biz_tag`) ) ENGINE=InnoDB;- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
原来获取ID每次都需要写数据库,现在只需要把step设置得足够大,比如1000。那么只有当1000个号被消耗完了之后才会去重新读写一次数据库。读写数据库的频率从1减小到了1/step,大致架构如下图所示:

同时Leaf-segment 为了解决 TP999(满足千分之九百九十九的网络请求所需要的最低耗时)数据波动大,当号段使用完之后还是会hang在更新数据库的I/O上,TP999 数据会出现偶尔的尖刺的问题,提供了双buffer优化。
简单的说就是,Leaf 取号段的时机是在号段消耗完的时候进行的,也就意味着号段临界点的ID下发时间取决于下一次从DB取回号段的时间,并且在这期间进来的请求也会因为DB号段没有取回来,导致线程阻塞。如果请求DB的网络和DB的性能稳定,这种情况对系统的影响是不大的,但是假如取DB的时候网络发生抖动,或者DB发生慢查询就会导致整个系统的响应时间变慢。
为了DB取号段的过程能够做到无阻塞,不需要在DB取号段的时候阻塞请求线程,即当号段消费到某个点时就异步的把下一个号段加载到内存中,而不需要等到号段用尽的时候才去更新号段。这样做就可以很大程度上的降低系统的 TP999 指标。详细实现如下图所示:
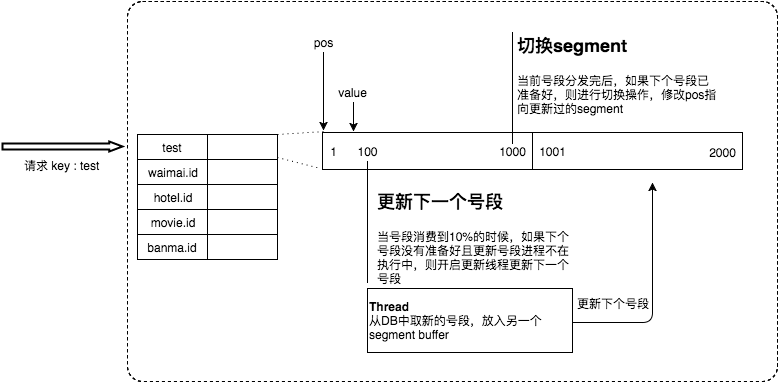
采用双buffer的方式,Leaf服务内部有两个号段缓存区segment。当前号段已下发10%时,如果下一个号段未更新,则另启一个更新线程去更新下一个号段。当前号段全部下发完后,如果下个号段准备好了则切换到下个号段为当前segment接着下发,循环往复。
- 每个biz-tag都有消费速度监控,通常推荐segment长度设置为服务高峰期发号QPS的600倍(10分钟),这样即使DB宕机,Leaf仍能持续发号10-20分钟不受影响。
- 每次请求来临时都会判断下个号段的状态,从而更新此号段,所以偶尔的网络抖动不会影响下个号段的更新。
对于这种方案依然存在一些问题,它仍然依赖 DB的稳定性,需要采用主从备份的方式提高 DB的可用性,还有 Leaf-segment方案生成的ID是趋势递增的,这样ID号是可被计算的,例如订单ID生成场景,通过订单id号相减就能大致计算出公司一天的订单量,这个是不能忍受的。
7.2、Leaf-snowflake方案
Leaf-snowflake方案完全沿用 snowflake 方案的bit位设计,对于workerID的分配引入了Zookeeper持久顺序节点的特性自动对snowflake节点配置 wokerID。避免了服务规模较大时,动手配置成本太高的问题。
Leaf-snowflake是按照下面几个步骤启动的:
- 启动Leaf-snowflake服务,连接Zookeeper,在leaf_forever父节点下检查自己是否已经注册过(是否有该顺序子节点)。
- 如果有注册过直接取回自己的workerID(zk顺序节点生成的int类型ID号),启动服务。
- 如果没有注册过,就在该父节点下面创建一个持久顺序节点,创建成功后取回顺序号当做自己的workerID号,启动服务。
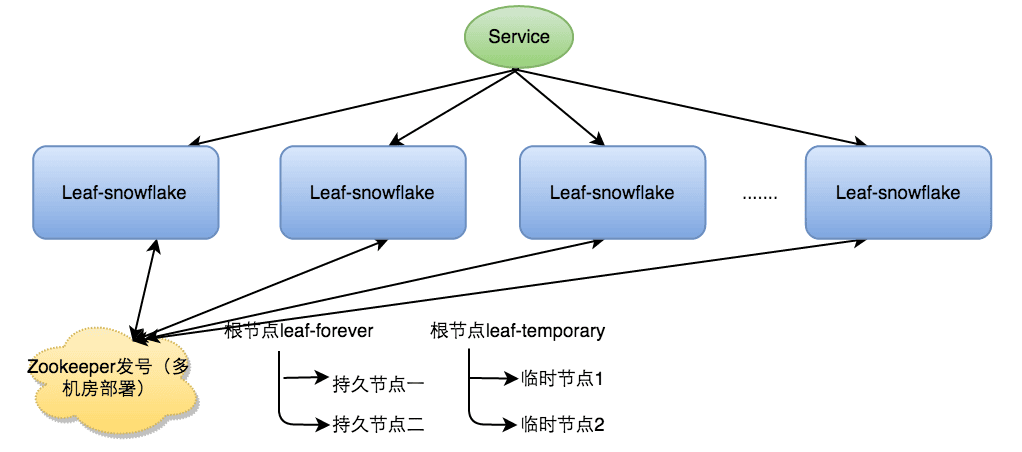
为了减少对 Zookeeper的依赖性,会在本机文件系统上缓存一个workerID文件。当ZooKeeper出现问题,恰好机器出现问题需要重启时,能保证服务能够正常启动。
上文阐述过在类 snowflake算法上都存在时钟回拨的问题,Leaf-snowflake在解决时钟回拨的问题上是通过校验自身系统时间与
leaf_forever/${self}节点记录时间做比较然后启动报警的措施。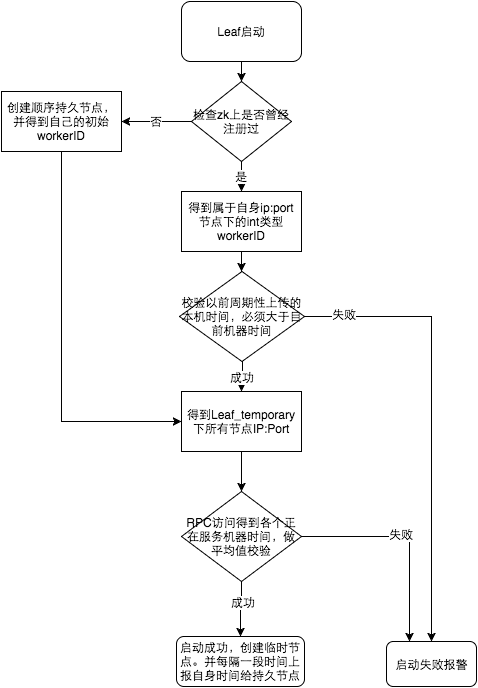
美团官方建议是由于强依赖时钟,对时间的要求比较敏感,在机器工作时NTP同步也会造成秒级别的回退,建议可以直接关闭NTP同步。要么在时钟回拨的时候直接不提供服务直接返回ERROR_CODE,等时钟追上即可。或者做一层重试,然后上报报警系统,更或者是发现有时钟回拨之后自动摘除本身节点并报警。
在性能上官方提供的数据目前 Leaf 的性能在4C8G 的机器上QPS能压测到近5w/s,TP999 1ms。
8、Mist 薄雾算法
最近有个号称超过snowflake 587倍的ID生成算法,可以参看这里, 如下内容摘自 GitHub中项目README
薄雾算法是不同于 snowflake 的全局唯一 ID 生成算法。相比 snowflake ,薄雾算法具有更高的数值上限和更长的使用期限。
现在薄雾算法拥有比雪花算法更高的性能!
8.1、考量了什么业务场景和要求呢?
用到全局唯一 ID 的场景不少,这里引用美团 Leaf 的场景介绍:
在复杂分布式系统中,往往需要对大量的数据和消息进行唯一标识。如在美团点评的金融、支付、餐饮、酒店、猫眼电影等产品的系统中,数据日渐增长,对数据分库分表后需要有一个唯一 ID 来标识一条数据或消息,数据库的自增 ID 显然不能满足需求;特别一点的如订单、骑手、优惠券也都需要有唯一 ID 做标识。此时一个能够生成全局唯一ID 的系统是非常必要的。
引用微信 seqsvr 的场景介绍:
微信在立项之初,就已确立了利用数据版本号实现终端与后台的数据增量同步机制,确保发消息时消息可靠送达对方手机。
爬虫数据服务的场景介绍:
数据来源各不相同,且并发极大的情况下难以生成统一的数据编号,同时数据编号又将作为爬虫下游整个链路的溯源依据,在爬虫业务链路中十分重要。
这里参考美团 Leaf 的要求:
1、全局唯一性:不能出现重复的 ID 号,既然是唯一标识,这是最基本的要求;
2、趋势递增:在 MySQL InnoDB 引擎中使用的是聚集索引,由于多数 RDBMS 使用 B-tree 的数据结构来存储索引数据,在主键的选择上面我们应该尽量使用有序的主键保证写入性能;
3、单调递增:保证下一个 ID 一定大于上一个 ID,例如事务版本号、IM 增量消息、排序等特殊需求;
4、信息安全:如果 ID 是连续的,恶意用户的爬取工作就非常容易做了,直接按照顺序下载指定 URL 即可;如果是订单号就更危险了,竞对可以直接知道我们一天的单量。所以在一些应用场景下,需要 ID 无规则、不规则;
可以用“全局不重复,不可猜测且呈递增态势”这句话来概括描述要求。
8.2、薄雾算法的设计思路是怎么样的?
薄雾算法采用了与 snowflake 相同的位数——64,在考量业务场景和要求后并没有沿用 1-41-10-12 的占位,而是采用了 1-47-8-8 的占位。即:
* 1 2 48 56 64 * +------+-----------------------------------------------------+----------+----------+ * retain | increas | salt | salt | * +------+-----------------------------------------------------+----------+----------+ * 0 | 0000000000 0000000000 0000000000 0000000000 0000000 | 00000000 | 00000000 | * +------+-----------------------------------------------------+------------+--------+- 1
- 2
- 3
- 4
- 5
- 6
- 第一段为最高位,占 1 位,保持为 0,使得值永远为正数;
- 第二段放置自增数,占 47 位,自增数在高位能保证结果值呈递增态势,遂低位可以为所欲为;
- 第三段放置随机因子一,占 8 位,上限数值 255,使结果值不可预测;
- 第四段放置随机因子二,占 8 位,上限数值 255,使结果值不可预测;
8.3、薄雾算法生成的数值是什么样的?
薄雾自增数为 1~10 的运行结果类似如下:
171671 250611 263582 355598 427749 482010 581550 644278 698636 762474- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
根据运行结果可知,薄雾算法能够满足“全局不重复,不可猜测且呈递增态势”的场景要求。
8.4、薄雾算法 mist 和雪花算法 snowflake 有何区别?
snowflake 是由 Twitter 公司提出的一种全局唯一 ID 生成算法,它具有“递增态势、不依赖数据库、高性能”等特点,自 snowflake 推出以来备受欢迎,算法被应用于大大小小公司的服务中。snowflake 高位为时间戳的二进制,遂完全受到时间戳的影响,倘若时间回拨(当前服务器时间回到之前的某一时刻),那么 snowflake 有极大概率生成与之前同一时刻的重复 ID,这直接影响整个业务。
snowflake 受时间戳影响,使用上限不超过 70 年。
薄雾算法 Mist 由书籍《Python3 反爬虫原理与绕过实战》的作者韦世东综合 百度 UidGenerator、 美团 Leaf 和 微信序列号生成器 seqsvr 中介绍的技术点,同时考虑高性能分布式序列号生成器架构后设计的一款“递增态势、不依赖数据库、高性能且不受时间回拨影响”的全局唯一序列号生成算法。
薄雾算法不受时间戳影响,受到数值大小影响。薄雾算法高位数值上限计算方式为
int64(1<<47 - 1),上限数值140737488355327百万亿级,假设每天消耗 10 亿,薄雾算法能使用 385+ 年。8.5、为什么薄雾算法不受时间回拨影响?
snowflake 受时间回拨影响的根本原因是高位采用时间戳的二进制值,而薄雾算法的高位是按序递增的数值。结果值的大小由高位决定,遂薄雾算法不受时间回拨影响。
8.6、为什么说薄雾算法的结果值不可预测?
考虑到“不可预测”的要求,薄雾算法的中间位是 8 位随机值,且末 8 位是也是随机值,两组随机值大大增加了预测难度,因此称为结果值不可预测。
中间位和末位随机值的开闭区间都是 [0, 255],理论上随机值可以出现
256 * 256种组合。8.7、当程序重启,薄雾算法的值会重复吗?
snowflake 受时间回拨影响,一旦时间回拨就有极大概率生成重复的 ID。薄雾算法中的高位是按序递增的数值,程序重启会造成按序递增数值回到初始值,但由于中间位和末尾随机值的影响,因此不是必定生成(有大概率生成)重复 ID,但递增态势必定受到影响。
8.8、薄雾算法的值会重复,那我要它干嘛?
1、无论是什么样的全局唯一 ID 生成算法,都会有优点和缺点。在实际的应用当中,没有人会将全局唯一 ID 生成算法完全托付给程序,而是会用数据库存储关键值或者所有生成的值。全局唯一 ID 生成算法大多都采用分布式架构或者主备架构提供发号服务,这时候就不用担心它的重复问题;
2、生成性能比雪花算法高太多倍;
3、代码少且简单,在大型应用中,单功能越简单越好;
8.9、是否提供薄雾算法的工程实践或者架构实践?
是的,作者的另一个项目 Medis 是薄雾算法与 Redis 的结合,实现了“全局不重复”,你再也不用担心程序重启带来的问题。
8.10、薄雾算法的分布式架构,推荐 CP 还是 AP?
CAP 是分布式架构中最重要的理论,C 指的是一致性、A 指的是可用性、P 指的是分区容错性。CAP 当中,C 和 A 是互相冲突的,且 P 一定存在,遂我们必须在 CP 和 AP 中选择。实际上这跟具体的业务需求有关,但是对于全局唯一 ID 发号服务来说,大多数时候可用性比一致性更重要,也就是选择 AP 会多过选择 CP。至于你怎么选,还是得结合具体的业务场景考虑。
1、薄雾算法的性能测试
采用 Golnag(1.14) 自带的 Benchmark 进行测试,测试机硬件环境如下:
内存 16 GB 2133 MHz LPDDR3 处理器 2.3 GHz 双核Intel Core i5 操作系统 macOS Catalina 机器 MacBook Pro (13-inch, 2017, Two Thunderbolt 3 ports)- 1
- 2
- 3
- 4
进行了多轮测试,随机取 3 轮测试结果。以此计算平均值,得
单次执行时间 346 ns/op。以下是随机 3 轮测试的结果:goos: darwin goarch: amd64 pkg: mist BenchmarkMain-4 3507442 339 ns/op PASS ok mist 1.345s goos: darwin goarch: amd64 pkg: mist BenchmarkMain-4 3488708 338 ns/op PASS ok mist 1.382s goos: darwin goarch: amd64 pkg: mist BenchmarkMain-4 3434936 360 ns/op PASS ok mist 1.394s- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
9、总结
以上基本列出了所有常用的分布式ID生成方式,其实大致分类的话可以分为两类:
- 一种是类DB型的,根据设置不同起始值和步长来实现趋势递增,需要考虑服务的容错性和可用性。
- 另一种是类snowflake型,这种就是将64位划分为不同的段,每段代表不同的涵义,基本就是时间戳、机器ID和序列数。这种方案就是需要考虑时钟回拨的问题以及做一些 buffer的缓冲设计提高性能。
而且可通过将三者(时间戳,机器ID,序列数)划分不同的位数来改变使用寿命和并发数。
例如对于并发数要求不高、期望长期使用的应用,可增加时间戳位数,减少序列数的位数. 例如配置成
{"workerBits":23,"timeBits":31,"seqBits":9}时, 可支持28个节点以整体并发量14400 UID/s的速度持续运行68年。对于节点重启频率频繁、期望长期使用的应用, 可增加工作机器位数和时间戳位数, 减少序列数位数. 例如配置成
{"workerBits":27,"timeBits":30,"seqBits":6}时, 可支持37个节点以整体并发量2400 UID/s的速度持续运行34年。10、参考文章
-
-
相关阅读:
Maven
解密Spring中的Bean实例化:推断构造方法(上)
面试说:聊聊JavaScript中的数据类型
全国的科技创新情况数据分享,涵盖2020-2022年三年情况
Python学习路线
Spring Cloud Alibaba系列之nacos:(4)配置管理
mescroll 在uni-app 运行的下拉刷新和上拉加载的组件
基于SSM开发网上书店商城购物系统
ListableBeanFactory学习
氨基/羧基修饰/偶联/接枝/功能化铋纳米球 NH2/COOH-Bi nanosphere
- 原文地址:https://blog.csdn.net/qq_28959087/article/details/131512946
