-
Platypus:快速、廉价且强大的大模型
一系列经过微调和合并的模型,在 Open LLM 排行榜上名列前茅。他们是如何做到的呢?
近年来,模型参数爆炸到数量巨大(PaLM 为 540 B)。有人提出的问题是这个参数数量是否必要。
根据 OpenAI 的说法,随着模型的增长,性能也会提高。此外,还出现了突现属性(除非在一定规模内才能观察到的属性)。
这种观点受到了以下事实的挑战:实际上更多的数据,因此扩展受到最佳训练模型所需的令牌数量的限制。此外,甚至这些新兴属性也可能不存在。
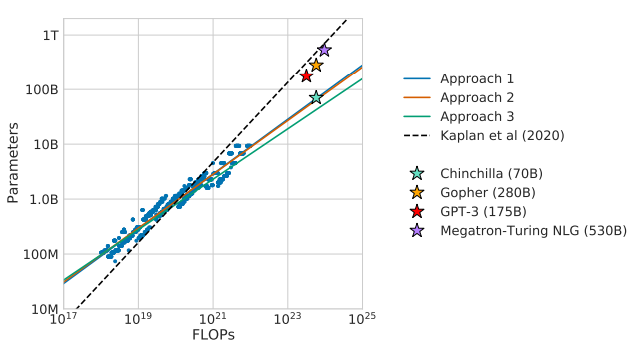
龙猫缩放定律,随着参数数量的增加,我们需要更多的数据来对其进行最佳训练。
其次,这些专有模型不能被科学界自由分析或使用。因此,首先是BLOOM,然后是META 的 LLaMA,社区已转向使用开源模型。LLaMA还表明,对数据的更多关注使得较小的模型能够与较大的模型竞争。
然而,另一方面,小模型不能像大模型一样具有泛化能力。然而,这导致人们寻找降低这些模型成本的技术,例如知识蒸馏(教师模型教授学生模型)。后来的方法试图通过提取数据集(从大型训练数据集开始,到较小但同时有效的数据集)来进一步降低成本。
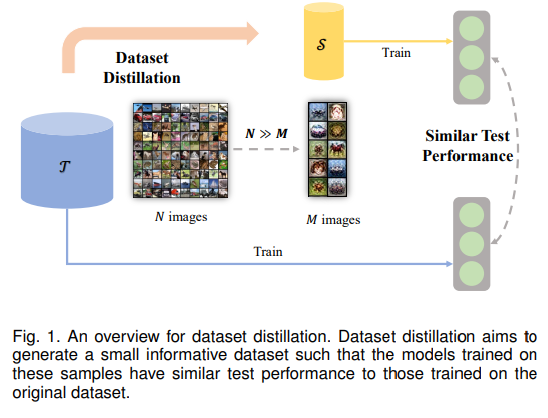
降低计算成本的另一个想法是混合专家,其中网络的各个部分根据输入被激活。例如,在开关变压器中,为每个示例(以及不同的令牌)选择不同的参数集。
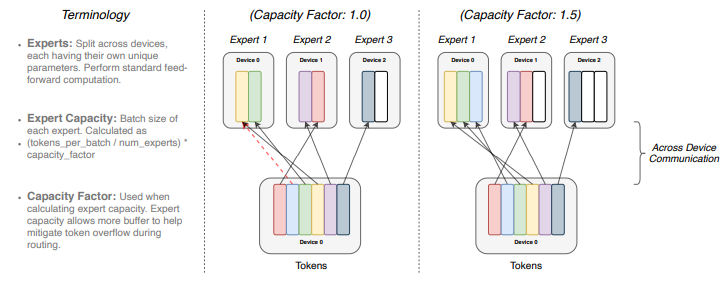
开关变压器。另一方面,在 LoRA 之前和 Quantized-LoRA 之后的最近几个月,已经开发出了用于微调大型语言模型(LLM) 的技术。这使得训练更加高效,并且在特定任务或领域出现了专门的模型(专用于编码、生物医学领域的模型)。
然而目前,训练模型是一个昂贵且耗时的过程。那么为什么不学习所有这些元素并将它们结合在一起呢?
Platypus :快速、廉价且强大

在最近发表的一篇文章中,Platypus 试图将这些元素结合在一起
具体来说:
- 他们发布了 open-platypus,这是一个精心策划的数据集,训练集和测试集之间既没有污染,也没有冗余。
- 冗余效应分析。
- 方法描述、代码和其他资源。
Open-platypus,人类数据集
作者决定对LLaMa-2作为基本模型进行微调。事实上,他们的动机是三个想法:模型在预训练中学习大部分知识,而对齐则使模型能够利用这些知识。基线模型尚未达到饱和,因此仍然可以进行训练。数据质量对于执行模型至关重要。
因此,作者的目标是最大限度地提高数据集的质量,同时最大限度地减少其大小,以提高计算效率。因此,作者采用开放数据集并筛选出优质示例(特别关注 STEM)。
作者选择了多达 11 个数据集,主要采用人类生成的问题(仅占大模型生成问题的 ∼10%)。
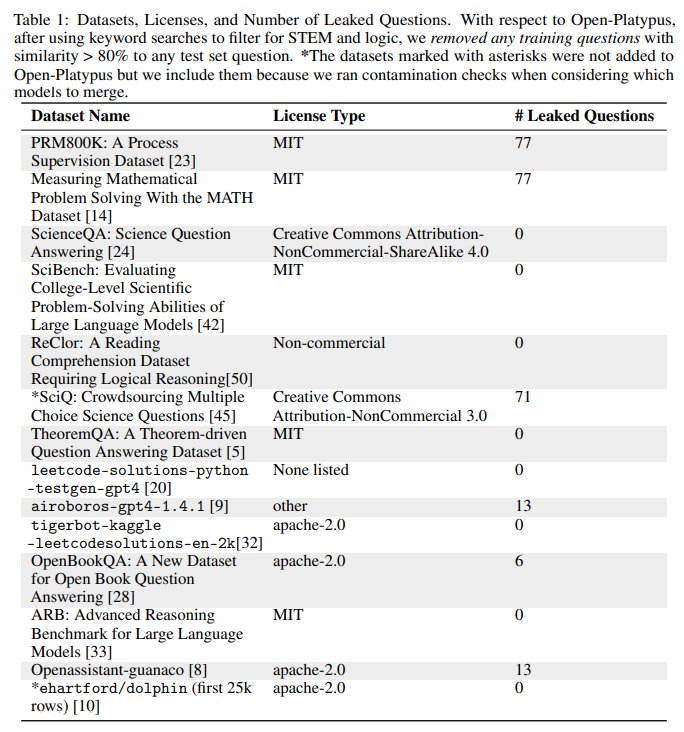
考虑到他们从不同的来源检索问题,作者检查并排除了相同或过于相似的问题。这是为了防止模型存储答案:
- 他们消除了重复的问题。
- 他们使用SentenceTransformers来嵌入问题,然后消除相似的问题(80%相似度余弦)
不要污染测试装置
作者注意确保基准数据集中的任何问题都不会泄漏到训练集中(最常见的错误之一)。
然而,这并不是一件容易的事,因为问题可能相似,并且有多种表达查询的方法。因此作者过滤掉了所有相似的查询。事实上,经过分析,他们发现了被视为潜在泄漏的问题,并将其分为三组:
- 重复。许多重复查询要么是精确的副本,要么是句子的重新排列或一些单词的添加。
- 灰色区域。不完全重复且属于常识范围的问题。这些问题需要由该领域的专家进行评估,因为它们包含同义词、非常相似的说明,或者被改写。
- 相似但又不同。这些问题具有很高的余弦相似度,但却有不同的答案。这是因为问题的结构发生了变化。

微调
作者使用低秩近似(LoRA),因为 QLoRA 出现较晚,但将来他们计划使用它。他们通过使用最先进的参数高效微调(PEFT)库进一步提高了训练效率。无论如何,他们声称他们能够使用单个 1 A100 80GB 对较小的 13B 模型进行 5 小时的微调。他们在选择参数时也特别小心。

另一个有趣的方法是,一旦经过训练,适配器就会与不同的模型合并。
每种情况的代码均已发布,可在此处获取
它还提供IPython Notebook和详细的在线文档。
结果:效果如何?

作者决定利用HuggingFace 排行榜来比较他们的模型的结果。作者指出,他们的模型在 8 月份达到了排行榜的第一名:
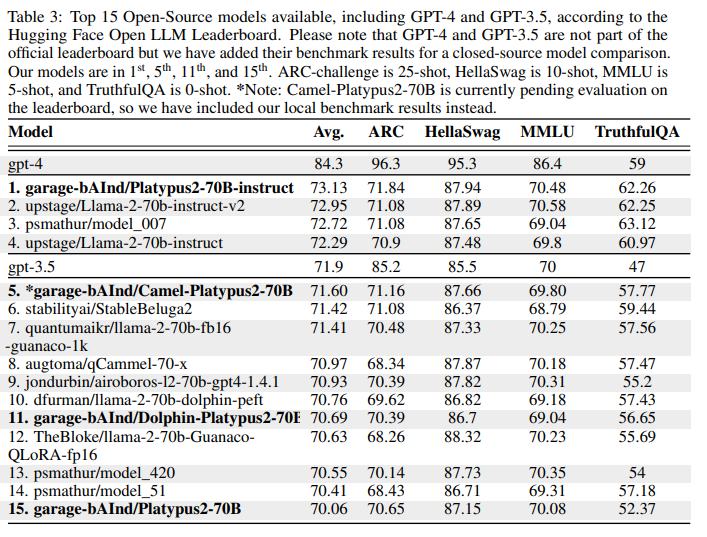
作者指出,他们的方法提高了基本模型 ( LLaMA2 ) 在不同基准上的性能。此外,特别是对于较小的模型,合并会产生有趣的结果(根据作者的说法,合并会导致模型访问它不知道的信息)。因此合并可以被认为是一种提高模型性能的低成本策略。当然,这种技术也有局限性:它的效果更好取决于领域,事实上在代数中它的影响较小。因此,必须对模型和应用程序域进行仔细选择来完成合并。
作者还指出,该模型是开源模型中的第一个。
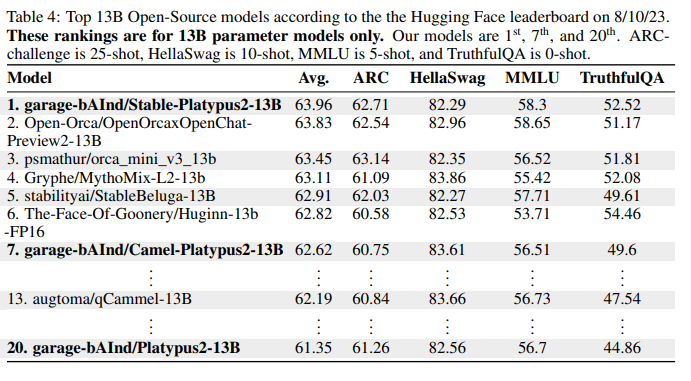
事实上,Playtypus最近在 HuggingFace 排行榜上被超越。事实证明它的性能相当可观。

局限性

当然,该模型并非没有局限性。其中一些源自LLaMA2,因为该模型在此基本模型上进行了微调。事实上,它与持续学习不相容,并且可能产生幻觉,并产生偏见和有害内容。
LLaMA2主要是在英语文本上训练的模型,因此其对其他语言的熟练程度较少。后来的研究表明,大模型可用于恶意目的(传播错误信息或探究敏感话题)。对于鸭嘴兽来说也是如此。
尽管 Platypus 已经接受过 STEM 领域的培训,但在处理其主要专业领域之外的主题时,它可能会遇到困难。
最后,虽然作者已经小心翼翼地避免污染,但可能仍然存在未被过滤掉的问题
结论
训练模型很昂贵,但从排行榜上可以看出,小型模型可以在某些任务中取得成功。LoRA 和其他技术的使用使获得大模型的机会更加平民化。这项工作进一步展示了领域专家如何成为一种可行的方法、如何合并适配器以及如何获取高质量的数据集。
-
相关阅读:
转换罗马数字
java项目-第152期ssm远程诊断系统-java毕业设计_计算机毕业设计
node nrm切换镜像源
【linux命令讲解大全】017.格式化C语言源文件的工具:indent命令
【springboot】9、Rest风格请求及视图解析
MongoDB - 入门指南
23年上半年上午题复习
Codeforces 353D 思维
如何恢复u盘删除文件?2023最新分享四种方法恢复文件
“程序包com.sun.tools.javac.util不存在” 问题解决
- 原文地址:https://blog.csdn.net/qq_41929396/article/details/132804476