-
Paper: 利用RNN来提取恶意软件家族的API调用模式
论文

摘要
- 恶意软件家族分类是预测恶意软件特征的好方法,因为属于同一家族的恶意软件往往有相似的行为特征
- 恶意软件检测或分类方法分静态分析和动态分析两种:
- 静态分析基于恶意软件中包含的特定签名进行分析,优点是分析的范围覆盖了整个代码,并且可以在不执行恶意软件的情况进行;但恶意软件设计者可以通过多态和加密的方法躲避静态分析
- 动态分析基于恶意软件的行为进行分析,因此动态分析的结果可以用于检测或分类一些经过伪装的恶意软件变体。可以利用API调用序列来检测或分类恶意软件变体。
- 本文提出了一种利用RNN来提取恶意软件家族的API调用模式,进而实现对恶意软件进行检测与分类的方法。对9个恶意软件家族的787个恶意软件样本进行了实验,发现正确分类恶意软件的概率为71%,实验证明该方法是有效的。
Introduction
- 近年来,新的恶意软件及恶意软件的变体不断增加,而且其设计者们通过加密、多态等方法修改签名,尽可能避开检测。
- 虽然恶意软件的签名都不尽相同,但相同家族的恶意软件都有着相似的行为模式,因此,恶意软件的家族分类就成为了恶意软件分析的一个重要的预处理步骤。我们可以将一个未知的恶意软件分类到已知的恶意软件家族中,来预测该恶意软件的行为,这样会极大的缩短该恶意软件的分析时间。
- API信息常用于恶意软件家族分类,(包括API名,参数,返回值等),本文将API的名字作为序列数据,用于RNN模型的输入和输出。
- API调用序列是恶意软件家族分类的一个重要特征,用RNN对属于同一家族的恶意软件的API调用序列进行训练,可以提取出具有代表性的API调用模式,即针对每个恶意软件家族的整体的API调用序列。该总体调用序列(调用模式)可以作为恶意软件家族分类的特征。
方法
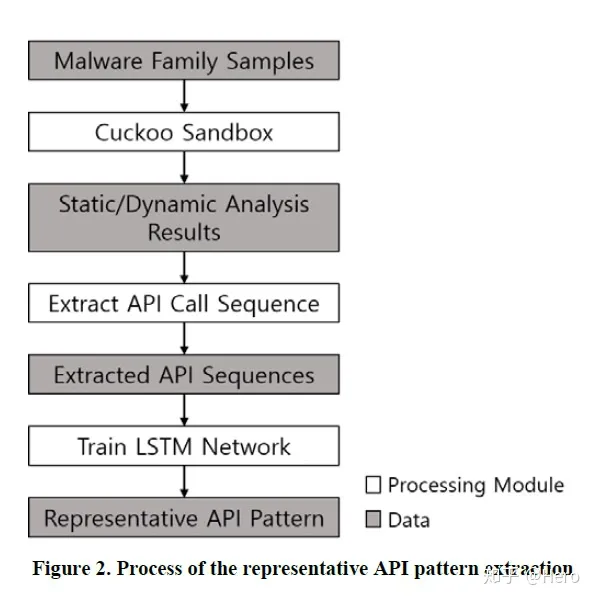
- 提取API调用序列
- 运行Cuckoo Sandbox(恶意软件动态分析框架),生成分析报告,提取出恶意软件运行过程中的API调用序列,将这些调用序列作为LSTM网络的输入。
- 训练LSTM网络
- LSTM网络包括3层,一层LSTM层,一层隐藏层,一层输出层。输入API调用序列,输出提取出的对应每个恶意软件家族的API调用模式。
实验
- 实验选取了来自VxHeaven的9个恶意软件家族共781个样本,其中70%是训练集,30%是测试集。
- 训练时,对于每个恶意软件家族,将该家族所有恶意软件的API调用序列concatenate到一起,训练LSTM网络,来得到每个恶意软件家族的API调用模式。
- 测试时,对于每一个样本看它的API调用序列符合(计算相似度,选相似度最大的)哪个家族的API调用模式,则该样本就是那个家族的恶意软件。
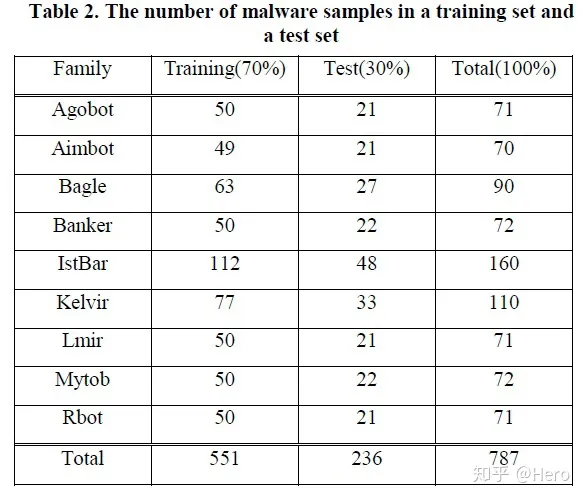
评估
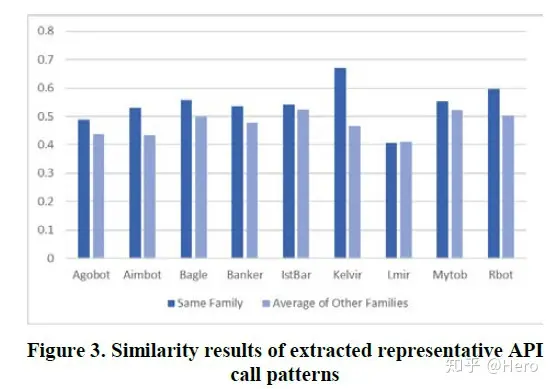
- 比较测试集恶意软件API调用序列和自己家族、或其他家族的API调用模式的相似度,发现相似度均不是太高,但与自己家族的相似度还是明显高于与其他家族相似度的。
- 比较从每个恶意软件家族中提取出的API调用模式与测试集恶意软件的API调用序列的相似性,选择与恶意软件相似度最高的前3个API调用模式,并将这三个恶意软件家族与正确答案进行比较。序列相似性度量采用Jaccard相似系数。测试集分类准确度如下。
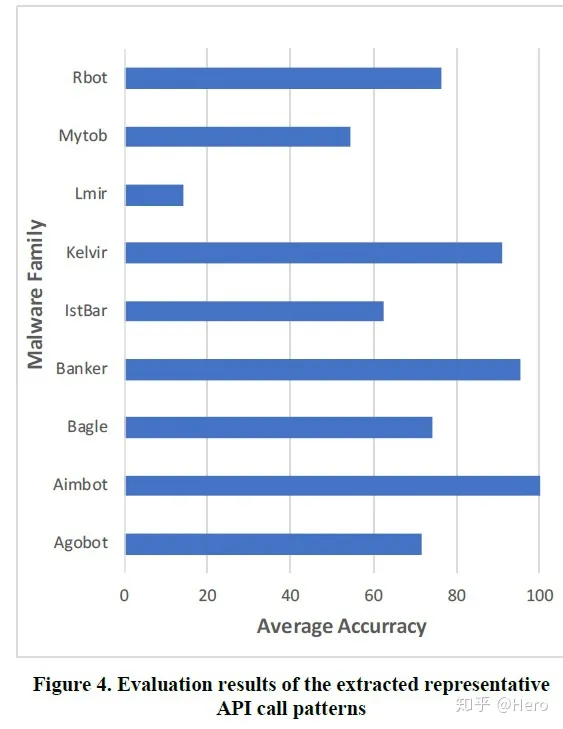
- 上图可见平均准确率达到了71%,只有一个家族(Lmir)在50%以下,原因可能是因为:
- Lmir家族只有27个独特的API调用,这在计算Jaccard相似度的时候会增大分母,导致无法正确的进行分类。
- 本文用的数据集的标注可能错误。
- 可见,总体来讲,利用家族的API调用模式和测试样本的API调用序列计算相似度的方式还是可以对测试样本进行分类的。
改进空间
- 使用比LSTM提取特征能力更强的神经网络
- 本文使用的数据集可能不准确
- 本文只考虑了API的类型和调用顺序,如果考虑API更多的语义信息效果会更好
结论
本论文将LSTM/RNN模型应用于提取恶意软件家族的API调用模式上,利用该调用模式与新的恶意软件的API调用序列计算相似度的方式可以对新的恶意软件分类。经实验验证,在VxHeaven上9个恶意软件家族共781个样本的数据集上可以达到71%的分类准确率。
参考文献
【1】Kwon I, Im E G. Extracting the representative api call patterns of malware families using recurrent neural network[C]//Proceedings of the International Conference on Research in Adaptive and Convergent Systems. 2017: 202-207.
补充:Jaccard相似系数(来自这里)
Jaccard相似系数用于比较有限样本集之间的相似性与差异性。Jaccard系数值越大,样本相似度越高,公式:
- 假设arr1 = [11, 2, 3, 8, 10, 0, 2, 0, 0, 2, 1, 0, 0, 2, 0, 0, 0, 0, 0, 0, 0] ,长度为21
- 假设arr2 = [9, 4, 4, 6, 6, 1, 3, 1, 0, 0, 4, 0, 0, 1, 1, 0, 0, 0, 0, 0, 0],长度为21
- 则arr1,arr2的公共部分arr_common = [3,0,0,0,1,0,0,0, 0, 0, 0, 0, 0, 0], 长度为14,那么arr1,arr2的Jaccard相似度为:14 / (21+21-14) = 0.5
-
相关阅读:
抖音阳哥:选品师项目究竟能不能算蓝海项目?
深度学习基础网络代码学习(pytorch)
redis如何保证接口的幂等性
python 端口快速扫描
【PyTorch】PyTorch模型定义
用Tinyproxy搭建自己的proxy server
hive 自定义函数、GenericUDF、GenericUDTF(自定义函数计算给定字符串的长度、将一个任意分割符的字符串切割成独立的单词)
Redis 内存优化神技,小内存保存大数据
mqtt使用方法
基于微信小程序的医院门诊体检预约管理系统设计与实现(源码+lw+部署文档+讲解等)
- 原文地址:https://blog.csdn.net/m0_69824302/article/details/132787369