-
Pandas 掉包侠刷题实战--条件筛选
本博文内容为力扣刷题过程的记录,所有题目来源于力扣。
题目链接:https://leetcode.cn/studyplan/30-days-of-pandas/
准备工作
先简单过下基础,了解一些常用的方法,
1. isin(values) 和 ~
isin(values)和~是 Pandas 中用于数据筛选和过滤的两个常用操作符,它们通常用于数据框(DataFrame)的列操作,以下是对它们的详细解释:isin(values):
isin()方法用于检查数据框的某一列中的每个元素是否包含在给定的values中,它返回一个布尔值的 Series,指示每个元素是否包含在values中。values可以是一个列表、集合或另一个 Series,用于比较数据框中的元素。- 常用语法如下:
df['column_name'].isin(values)- 1
- 返回的结果是一个布尔值的 Series,其中每个元素表示数据框中对应位置的元素是否包含在
values中。可以将这个 Series 用作数据框的索引来筛选包含特定值的行。
示例:
import pandas as pd data = {'Name': ['Alice', 'Bob', 'Charlie', 'David'], 'Age': [25, 30, 22, 35]} df = pd.DataFrame(data) # 筛选年龄在 [25, 30] 范围内的行 filtered_df = df[df['Age'].isin([25, 30])] print(filtered_df)- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
输出:
Name Age 0 Alice 25 1 Bob 30- 1
- 2
- 3
~(取反操作符):
~是 Python 中的取反操作符,在 Pandas 中,它可以用于取反一个布尔值的 Series。也就是说,它可以用于筛选出不满足某个条件的行。- 常用语法如下:
~condition- 1
condition是一个布尔值的 Series,表示要筛选的条件。 ~可以与其他筛选条件结合使用,例如,你可以使用&(与)和|(或)运算符来构建更复杂的条件。
示例:
import pandas as pd data = {'Name': ['Alice', 'Bob', 'Charlie', 'David'], 'Age': [25, 30, 22, 35]} df = pd.DataFrame(data) # 筛选年龄不在 [25, 30] 范围内的行 filtered_df = df[~df['Age'].isin([25, 30])] print(filtered_df)- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
输出:
Name Age 2 Charlie 22 3 David 35- 1
- 2
- 3
在上述示例中,
~操作符被用于筛选出年龄不在 [25, 30] 范围内的行。总之,
isin(values)是用于检查列中元素是否包含在给定值中的方法,而~操作符用于对布尔条件取反,用于筛选出不满足条件的行。这两种方法都是在 Pandas 中对数据进行筛选和过滤时非常有用的工具。
2. df.drop_duplicates()
df.drop_duplicates()用于删除 DataFrame 中的重复行。这个函数的详细解释如下:语法:
DataFrame.drop_duplicates(subset=None, keep='first', inplace=False)- 1
参数解释:
subset:可选参数,用于指定要检查重复行的列名列表。默认值为None,表示检查整个行是否重复。keep:可选参数,指定要保留哪个重复行的方式。有三个选项:'first':保留第一个出现的重复行(默认值)。'last':保留最后一个出现的重复行。False:删除所有重复行。
inplace:可选参数,如果为True,则会在原始 DataFrame 上进行操作,而不创建一个新的 DataFrame。默认值为False,表示创建一个新的 DataFrame 并返回结果。
函数的作用:
drop_duplicates()函数的主要作用是识别并删除 DataFrame 中的重复行,从而使 DataFrame 中的数据变得唯一或去重。示例用法:
import pandas as pd data = {'A': [1, 2, 2, 3, 4], 'B': ['X', 'Y', 'Y', 'Z', 'Z']} df = pd.DataFrame(data) # 去除重复行,默认保留第一个出现的重复行 df_no_duplicates = df.drop_duplicates() # 显示去重后的 DataFrame print(df_no_duplicates)- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
输出:
A B 0 1 X 1 2 Y 3 3 Z 4 4 Z- 1
- 2
- 3
- 4
- 5
在上面的示例中,原始 DataFrame
df包含了一些重复的行。通过调用drop_duplicates()函数,我们得到了一个去重后的 DataFramedf_no_duplicates,其中只保留了第一个出现的重复行。需要注意的是,
drop_duplicates()函数默认返回一个新的 DataFrame,原始 DataFrame 不会被修改。如果要在原地修改原始 DataFrame,可以将inplace参数设置为True。
3. df.sort_values()
df.sort_values()是 Pandas 中用于对 DataFrame 进行排序的函数。它允许你按照指定的列或多个列的值对数据进行排序。下面是sort_values()函数的详细解释:语法:
DataFrame.sort_values(by, axis=0, ascending=True, inplace=False, ignore_index=False, key=None)- 1
参数解释:
by:要排序的列的名称或列名的列表。可以传递单个列名或多个列名的列表,以指定多个排序键。axis:指定排序的轴。默认为 0,表示按行排序。如果设置为 1,表示按列排序。ascending:控制排序顺序。默认为True,表示升序排序(从小到大)。如果设置为False,则表示降序排序(从大到小)。inplace:可选参数,如果为True,则会在原始 DataFrame 上进行排序操作,而不创建一个新的 DataFrame。默认为False,表示创建一个新的 DataFrame 并返回结果。ignore_index:可选参数,如果为True,则重新索引排序后的 DataFrame,以避免保留原始索引。默认为False。key:可选参数,一个用于自定义排序的函数。这个函数将应用于每个排序键,然后根据其返回值进行排序。
函数的作用:
sort_values()函数的主要作用是对 DataFrame 中的数据进行排序。你可以按照一个或多个列的值进行排序,以便更好地理解数据或为进一步分析做准备。示例用法:
import pandas as pd data = {'Name': ['Alice', 'Bob', 'Charlie', 'David'], 'Age': [25, 30, 22, 35], 'Salary': [50000, 60000, 55000, 70000]} df = pd.DataFrame(data) # 按照年龄升序排序 df_sorted_age = df.sort_values(by='Age', ascending=True) # 显示排序后的 DataFrame print(df_sorted_age)- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
输出:
Name Age Salary 2 Charlie 22 55000 0 Alice 25 50000 1 Bob 30 60000 3 David 35 70000- 1
- 2
- 3
- 4
- 5
在上面的示例中,我们首先创建了一个包含姓名、年龄和工资的 DataFrame。然后,我们使用
sort_values()函数按照年龄升序排序了数据。排序后的结果存储在df_sorted_age中,原始 DataFramedf保持不变。总之,
sort_values()是一个重要的 Pandas 函数,用于在数据分析和处理中对数据进行排序,以便更好地理解数据的特点和趋势。你可以根据需求指定排序键、排序顺序以及是否在原地修改数据。
4. df.rename()
df.rename()是 Pandas 中用于重命名 DataFrame 列名或索引的函数。它允许你修改 DataFrame 中的列名或索引标签,以便更好地符合你的需求。下面是df.rename()函数的详细解释:语法:
DataFrame.rename(mapper=None, index=None, columns=None, axis=None, copy=True, inplace=False, level=None)- 1
参数解释:
mapper:可选参数,用于指定新旧标签之间的映射关系。可以是一个字典,其中键是旧标签,值是新标签;也可以是一个函数,该函数接受旧标签并返回新标签。index:可选参数,用于重命名索引标签的字典或函数。columns:可选参数,用于重命名列名的字典或函数。axis:可选参数,用于指定重命名的轴。默认为None,表示不指定轴。如果设置为0或'index',则表示重命名索引标签;如果设置为1或'columns',则表示重命名列名。copy:可选参数,如果为True,则返回一个包含重命名后数据的副本,原始 DataFrame 不会被修改。如果为False,则在原地修改 DataFrame。默认为True。inplace:可选参数,如果为True,则在原始 DataFrame 上进行重命名操作,而不创建一个新的 DataFrame。默认为False。level:可选参数,用于指定在多层索引 DataFrame 中重命名的级别。
函数的作用:
df.rename()函数的主要作用是修改 DataFrame 的列名或索引标签,以便更好地反映数据的含义或符合分析的需要。这对于数据清理和准备非常有用。示例用法:
import pandas as pd data = {'A': [1, 2, 3], 'B': [4, 5, 6]} df = pd.DataFrame(data) # 重命名列名 df.rename(columns={'A': 'X', 'B': 'Y'}, inplace=True) # 显示重命名后的 DataFrame print(df)- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
输出:
X Y 0 1 4 1 2 5 2 3 6- 1
- 2
- 3
- 4
在上面的示例中,我们首先创建了一个包含两列的 DataFrame,然后使用
df.rename()函数将列名 “A” 和 “B” 重命名为 “X” 和 “Y”。inplace=True参数表示在原地修改 DataFrame。最后,我们打印出了重命名后的 DataFrame。总之,
df.rename()是一个有用的 Pandas 函数,用于在数据分析和处理过程中修改 DataFrame 的列名或索引标签,以便更好地表示数据的含义或满足分析需求。可以根据需要选择要重命名的列或索引,以及新的名称。
5. pd.merge()
pd.merge()是 Pandas 中用于合并(合并)两个 DataFrame 的方法,类似于 SQL 中的 JOIN 操作。这个方法非常有用,可以用于将不同的数据源按照某些关键列或索引合并在一起,以进行数据集成和分析。以下是.merge()方法的详细解释:语法:
pd.merge(left, right, how='inner', on=None, left_on=None, right_on=None, left_index=False, right_index=False, suffixes=('_x', '_y'))- 1
参数解释:
left:要合并的左侧 DataFrame。right:要合并的右侧 DataFrame。how:合并的方式,可以是以下几种之一:'inner':内连接,只保留两个 DataFrame 中共有的行。'left':左连接,保留左侧 DataFrame 中的所有行,右侧 DataFrame 中没有匹配的用 NaN 填充。'right':右连接,保留右侧 DataFrame 中的所有行,左侧 DataFrame 中没有匹配的用 NaN 填充。'outer':外连接,保留两个 DataFrame 中的所有行,没有匹配的用 NaN 填充。
on:用于指定连接的列名,这是最常用的连接方式。如果两个 DataFrame 中的列名相同,可以使用这个参数,否则可以使用left_on和right_on来分别指定左侧和右侧的连接列。left_on:用于指定左侧 DataFrame 中用于连接的列名。right_on:用于指定右侧 DataFrame 中用于连接的列名。left_index和right_index:如果为True,则使用左侧或右侧 DataFrame 的索引作为连接键,而不使用列名。suffixes:如果左侧和右侧 DataFrame 中有重名的列,可以用suffixes参数来指定添加到重名列名后的后缀。
函数的作用:
.merge()方法用于将两个 DataFrame 按照指定的条件合并在一起,以便进行数据集成和分析。可以根据不同的连接方式(内连接、左连接、右连接、外连接)将两个数据集合并,使得不同数据源的信息可以关联在一起。示例用法:
import pandas as pd # 创建两个示例 DataFrame left_data = {'ID': [1, 2, 3], 'Name': ['Alice', 'Bob', 'Charlie']} right_data = {'ID': [2, 3, 4], 'Age': [25, 30, 22]} left_df = pd.DataFrame(left_data) right_df = pd.DataFrame(right_data) # 使用 merge 进行内连接 merged_df = pd.merge(left_df, right_df, on='ID', how='inner') print(merged_df)- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
输出:
ID Name Age 0 2 Bob 25 1 3 Charlie 30- 1
- 2
- 3
在上述示例中,我们首先创建了两个示例 DataFrame(
left_df和right_df),然后使用.merge()方法进行了内连接,连接键是 “ID” 列。合并后的结果包含了两个 DataFrame 共有的行。总之,
.merge()方法是 Pandas 中用于合并两个 DataFrame 的重要工具,允许你根据不同的连接方式将数据集成在一起,以便进行数据分析和处理。你可以根据需要指定连接键、连接方式和其他参数来执行不同类型的合并操作。
题目-条件筛选
1. 大的国家


这题没啥说的,直接写,个人习惯是先写出
SQL,再根据SQL写成pandas形式。SQL
select name, population, area from world where population >=25000000 or area >=3000000- 1
- 2
- 3
- 4
- 5
python
import pandas as pd def big_countries(world: pd.DataFrame) -> pd.DataFrame: df = world[(world["area"]>=3000000) | (world["population"]>=25000000)] return df[["name","population","area"]]- 1
- 2
- 3
- 4
- 5
- 6
2. 可回收且低脂的产品
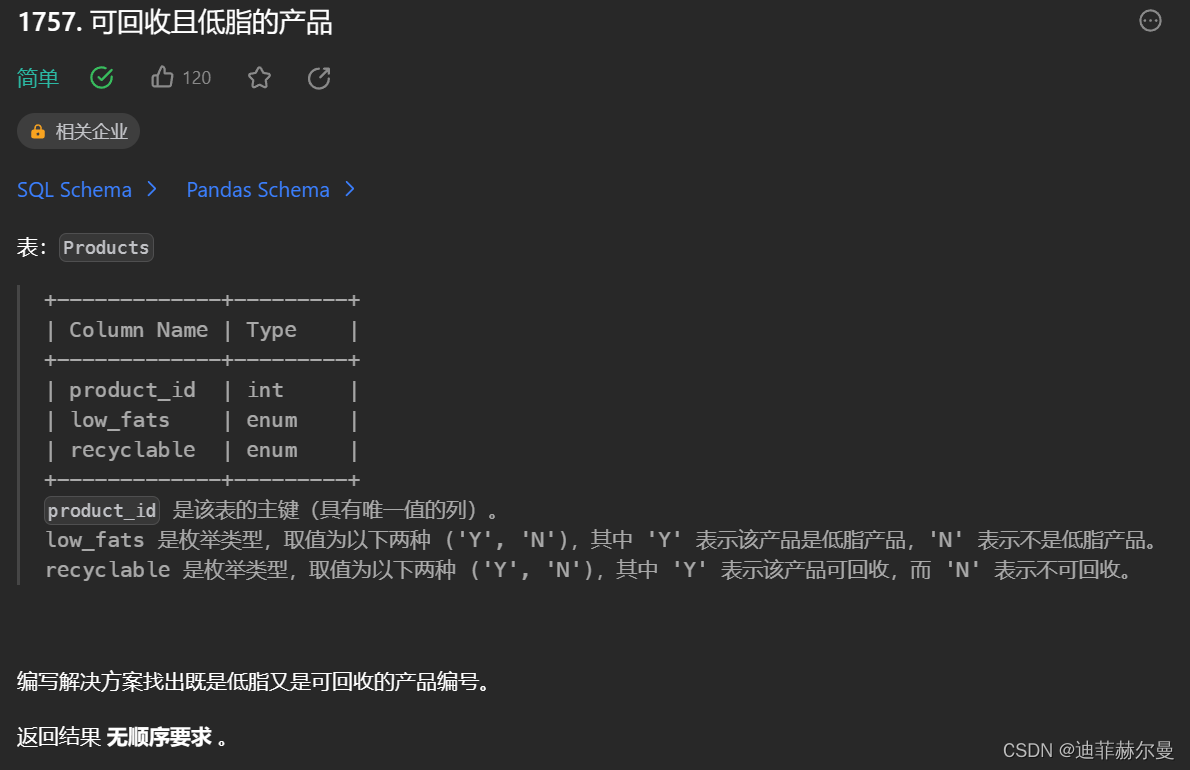

也没啥说的,和上一道题一样,
SQL
select product_id from products where low_fats = "Y" and recyclable = "Y"- 1
- 2
- 3
- 4
- 5
- 6
Python
import pandas as pd def find_products(products: pd.DataFrame) -> pd.DataFrame: df = products[(products["low_fats"] == "Y") & (products["recyclable"] == "Y")] return df[["product_id"]]- 1
- 2
- 3
- 4
- 5
3. 从不订购的客户


涉及到
~,isin()和rename()方法,上文已给出解析SQL
select customers.name as 'Customers' from customers where customers.id not in ( select customerid from orders );- 1
- 2
- 3
- 4
- 5
- 6
python
import pandas as pd def find_customers(customers: pd.DataFrame, orders: pd.DataFrame) -> pd.DataFrame: df = customers[~customers["id"].isin(orders["customerId"])] df = df[["name"]].rename(columns={"name":"Customers"}) return df- 1
- 2
- 3
- 4
- 5
- 6
- 7
4. 文章浏览 I
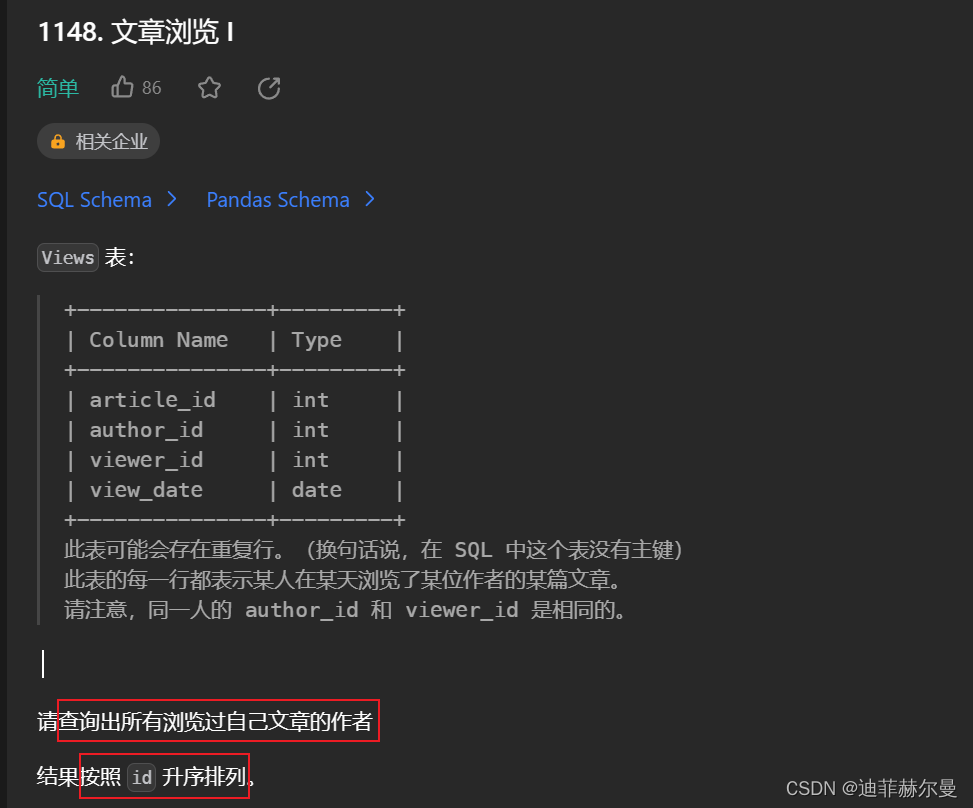

条件比较多,一步一步写,第一步筛选author_id等于viewer_id,随后就根据上文的几个方法直接带入既可,
注意事项就是语法格式,还有inplace=True这个东西,不要忘了!SQL
select distinct author_id as id from Views where author_id = viewer_id order by id- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
python
import pandas as pd def article_views(views: pd.DataFrame) -> pd.DataFrame: df = views[views["viewer_id"] == views["author_id"]] df.drop_duplicates(subset=["author_id"], inplace=True) df.rename(columns={"author_id":"id"}, inplace=True) df.sort_values(by=["id"],inplace=True) return df[["id"]]- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
-
相关阅读:
Day30、列表、表格与表单
JVM参数配置
郑州大学编译原理实验二语法分析器JAVA
Android音频——音量调节
【目标检测】Generalized Focal Loss V2
JavaScript基础语法(类型转换)
多进程单线程多端口TCPUDP三层协议转发
基于若依ruoyi-nbcio增加flowable流程待办消息的提醒,并提供右上角的红字数字提醒(七)
嵌入式学习笔记(27)uart stdio的移植
python爬虫:JavaScript 混淆、逆向技术
- 原文地址:https://blog.csdn.net/weixin_43694096/article/details/132795613